
LINEで会話投稿WhisperとChatGPTを使った文字起こし・要約アプリの作成方法

こんにちは、ITエンジニアの皆さん。今回は、whisperとChatgGPTを使った音声文字起こし・要約アプリを作ってみました。
このアプリは、LINEを介して音声を投稿することで、文字起こしと要約を取得できます。Pythonでコードを書いています。
@vain_vox と作りました。この記事はChat-GPT と作っています。
こんな感じで動きます。
LINEで音声を送ったらそのまま議事録貸してくれるアプリ1時間とかでできちゃったwww pic.twitter.com/7WOvTseCMs
— 🫥🫥わんわん@AI司会者tender (@wanwanlands) March 5, 2023
概要
このアプリは、whisperとGPT-4を利用して、音声の文字起こしと要約を提供します。
ユーザーは、LINEで音声を投稿すると、自動的に音声を解析して、テキストデータと要約データを生成します。
ユーザーは、LINE上で結果を受け取ることができます。
音声をLINEで投稿するだけで、いつでもどこでも文字起こしや要約ができるため、簡単に使えるかなと思って作りました。
実装方法
Pythonで実装しました。
全体像
まず、LINEから音声ファイルを受け取るところの設定を行います。
次に、whisperとGPT-4を使って音声の文字起こしと要約を行うコードを作ります。
次に、LINE Messaging APIをメッセージを送り返すコードを作ります。

LINE設定
Messaging APIを使う必要があるので、こちらの公式に従って、LINEアカウント作成やデベロッパー登録を済ませてください。
こんな感じでアカウントができたら成功です。

webサーバ設置
データを受け取ったり、返したりするための簡単なサーバをDockerで立ち上げます。
ここは、ぶっちゃけなんでも大丈夫です。
例えばうちではこのようにしています。
下記のソースを全て保存して
# Dockerfile
FROM python:3.9.4-alpine
## プロキシサーバを使う場合
# コンテナ内での作業場所を /usr/src/app とする
WORKDIR /usr/src/app
# Python に関する環境変数
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
# 時刻を日本に合わせる
RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
ENV LANGUAGE ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
# pip を更新したうえで必要なパッケージをインストールする
RUN pip install --upgrade pip==21.0.1
COPY requirements.txt .
RUN pip install -r requirements.txt# compose.yaml
version: '3.8'
services:
bottle:
build: ./
container_name: mybottle
command: >
bash -c '
python /usr/src/app/server.py'
volumes:
- ./:/usr/src/app/
ports:
- 8080:8080
tty: true#requirements.txt
bottle==0.12.25
certifi==2022.12.7
line-bot-sdk==2.4.1
openai==0.27.0
packaging==23.0
requests==2.28.1
urllib3==1.26.14#server.py
import openai
from bottle import route, request, run
from linebot import LineBotApi
import json
from linebot.models import TextSendMessage
from linebot.exceptions import LineBotApiError
@route('/test', method='GET')
def test():
print("hello world")
@route('/webhook', method='POST')
def webhook():
print('hello-world')
run(host='0.0.0.0', port=8080, debug=True)下記のようにコマンドを打ちます
# dockerビルドを行なってください。
docker compose build
docker compose up -d
hello worldが出たら成功

外部からアクセスができるようにするためにngrokをインストールしてください。
設定完了したら下記のコマンドで起動させます
~/ngrok http 0.0.0.0:8080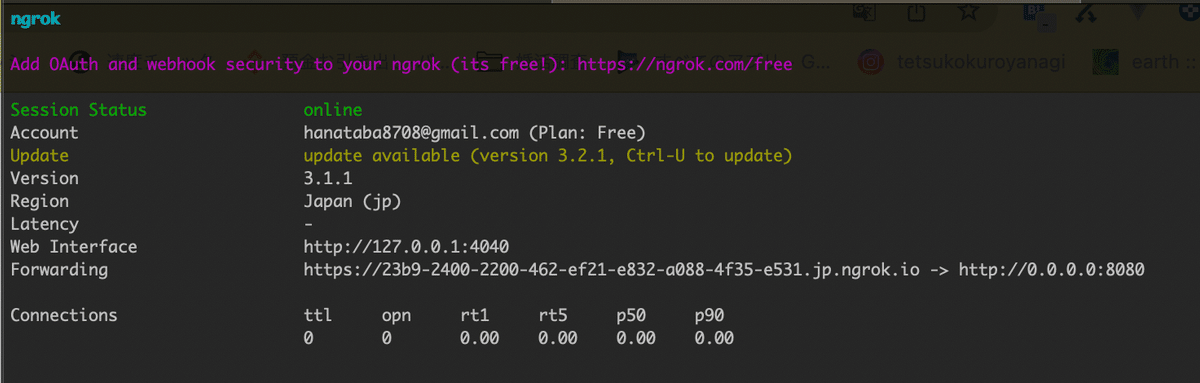
外部からアクセスできたら成功

メッセージを受け取る
LINEから来たメッセージを受け取る必要があるので、メッセージ(Webhook)受信の設定を行います。
こちらの記事を読んで設定を行なってください。
こちらに移動して



LINEで返信するためのkeyを取得
webhookの下にあるチャンネルアクセストークンを取得する

open ai api key取得
WhisperやChatGPTなどを利用するためには、OpenAIのAPIキーが必要です。APIキーを取得するためには、以下の手順を行います。
手順はどんどん変わっていくので適時対応してください。
GPT-4のapiはwaitlist なので依頼する
プログラム作成
結構適当なコードなので冗長ですが下記のようにserver.pyを書き換えてください。
server.py
import openai
from bottle import route, request, run
from linebot import LineBotApi
import json
from linebot.models import TextSendMessage
from linebot.exceptions import LineBotApiError
lineChannelAccessToken = "チャネルアクセストークン"
openaiApiKey = "OpenAIのキー"
@route('/test', method='GET')
def test():
return ("hello world")
@route('/webhook', method='POST')
def webhook():
openai.api_key = openaiApiKey
with open("/usr/src/app/api.text", 'w') as fd:
contentType = request.get_header('Content-Type')
message_id = request.json["events"][0]["message"]["id"]
replyToken = request.json["events"][0]["replyToken"]
user_id = request.json["events"][0]["source"]['userId']
line_bot_api = LineBotApi(lineChannelAccessToken)
try:
print('try')
line_bot_api.push_message(user_id, TextSendMessage(text='認識結果と要約を返します。\n*長い文章の場合は2000字で区切ります。'))
except LineBotApiError as e:
print('failed')
message_content = line_bot_api.get_message_content(message_id)
with open("/usr/src/app/voice.m4a", 'wb') as fd:
for chunk in message_content.iter_content():
fd.write(chunk)
with open("/usr/src/app/voice.m4a", "rb") as voice:
transcription = openai.Audio.transcribe("whisper-1",voice)
t_text = transcription.text + "\n"
split_texts = [t_text[x:x+2000] for x in range(0, len(t_text), 2000)]
reply_message = '要約結果:(文章が長い場合は内容を分割します)\n'
i = 1
for split_text in split_texts:
reply_message = reply_message + '\n**要約' + str(i) + '回目*****'
message = "この文を箇条書きで要約してください。「{}」".format(split_text)
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": message}]
)
print(completion.choices[0].message.content)
reply_message = reply_message + completion.choices[0].message.content + "\n"
recognition_message = '//音声認識結果' + str(i) + '分割目////\n'
recognition_message = recognition_message + split_text
recognition_message = recognition_message + '/////////'
i = i+1
try:
print('try')
line_bot_api.push_message(user_id, TextSendMessage(text=recognition_message))
except LineBotApiError as e:
print('failed')
try:
print('try')
line_bot_api.push_message(user_id, TextSendMessage(text=reply_message))
except LineBotApiError as e:
print('failed')
print(e)
return (transcription.text)
run(host='0.0.0.0', port=8080, debug=True)リスタート
docker compose restart
使ってみる
こんな感じで動くようになりました。
LINEで音声を送ったらそのまま議事録貸してくれるアプリ1時間とかでできちゃったwww pic.twitter.com/7WOvTseCMs
— 🫥🫥わんわん@AI司会者tender (@wanwanlands) March 5, 2023
まとめ
WhisperとChatGPTを使った音声文字起こし・要約アプリをPythonで実装してみました。
LINEを介して簡単に利用することができるため、楽に利用できます。
次はSlack向を作ろうと思っていますー
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?