
AWS リ・インベント2023 ショーン・ナンディ氏プレゼンテーション

https://www.linkedin.com/in/shaownnandi/
5:15から
皆さん、ご参加いただきありがとうございます。
今日は、ジェネレーティブAIを使って体験を刷新している3人の素晴らしいお客様か
はじめに
皆さん、お時間がありましたら、私の9つの無料イベントにご参加いただきありがとうございます。今日は、ジェネレーティブAIを使って体験を刷新している3人の素晴らしいお客様からお話を伺います。皆さんはアレクサの話を聞いたと思います。家庭で何らかのAIを使っている人はどれくらいいるでしょうか?だからすごいと思ったんです。ほとんどの人が。AIは世界を席巻していますが、今日は、あなたの製品や体験にどのようにジェネレーティブAIを組み込むことができるか、あなたのフレームワークを確立する手助けをするためにここに来ました。

人工知能から始めよう
。
AIは、お気に入りのストリーミング・ネットワークで何を見るかをキュレーションすることで、私たちの日常生活を助けてくれている。
創薬を加速させ、スマートサーモスタットのようなものまで可能にしている。これらはすべて、人間の能力を増強するものだ。
機械学習は、人間が他人を真似てパターンに従って学習するのと似ている。
例えば、放射線科医が医療画像を見て、彼らが何を見ていたかを推測することを想像してみてほしい。
そしてすべてのモデルは、表示されているものを正確に説明するために、人間によって注釈が付けられた1000枚もの画像で訓練されている。
一方、ディープラーニングは機械学習とは異なる。
機械学習では、人間の脳を模倣したニューラルネットワークに基づくディープ・ラーニング・モデルのループに人間が入る必要がある。
ディープラーニングモデルは、人間の脳を模倣することで、複雑なパターンを素早く理解し、時間をかけてその能力を向上させることができる。
ディープラーニングは、その名の通り、会話や画像、動画、音楽など、新しいコンテンツのアイデアを生み出す。
このコンテンツは最終的に、FMの音として知られる独自の基礎モデルから作られる。FMのサウンドはユニークで、インターネット・スケールのデータで学習される。FMを特別なものにしているのは、多くのパラメータを含んでいるため、より多くのタスクを形成できることだ。そのため、複雑な概念を学習することができるのです。お客様からは、ジェネレーティブAIとFMを今日活用し、明日に備えるにはどうしたらいいかという質問がありました

ジェネレーティブAIの応用について考えてみよう
amazon.comにアクセスして商品を見る理由のひとつは、1000件ものレビューを見るためです。しかし、ある商品に対するレビューがすべて表示された場合、それらをどのように解析すればよいのでしょうか?私たちは最近、ジェットAIベースのレビュー要約をモバイルアプリに導入しました。
レビューから重要なポイントを要約することで、顧客が買い物をする時間を大幅に短縮することができます。
ライターのブロックを考える。それが問題だ。コーダーのブロックはどうだろう?
AIはすでに今日、コーダーがより速く開発する手助けをしています。
Amazon code Whispererは、私たちのAIコーディング・コンパニオンです。私のチームは、生産性に課題を抱えるエンジニアたちとテストを行った。そして、コードウィスパーを使用する開発者は、57%速くタスクを完了し、27%成功する可能性が高いことがわかりました。
重要なのは、テクノロジーそのものではなく、それをどのように人材スキルや能力、そして最も重要なビジョンと組み合わせるかということなのです。

さて、生成AIが驚異的なオートスケールを駆動していることはご存じのとおりです。それは信じられないほどの量の出力を生成し、それをどのように保存し管理するかが重要なのです。
AWSは、毎秒テラバイトのスループットと数百万IOPs(input/output/second)を持つ最大30,000のアクセラレータをサポートするAWSウルトラ・クラスタを構築する顧客を持っており、私はサイズとモデル・パラメータの1,600倍の増加を見てきました,なので、最適化されたインフラは、これらのモデルをホストするトレーニングに不可欠なのです。このようなモデルをホストするためには、最適化されたインフラストラクチャーが非常に重要になります

生成AIは信じられないほどのパワーと責任感をチームにもたらします。
人間の能力を代替するのではなく、補強する方法であり、人間のイノベーションと創造性を加速させます。
世界経済フォーラムでは、2027年までにジェネレーティブAIによって260万種類の新たな仕事が創出されると予想しています。
我々はトレーニングが必要であり、人々を訓練する必要がある。アマゾンは新しいAI Readyプログラムを発表し、2025年までに全世界で200万人にAIスキルを無料で提供することを計画しています。
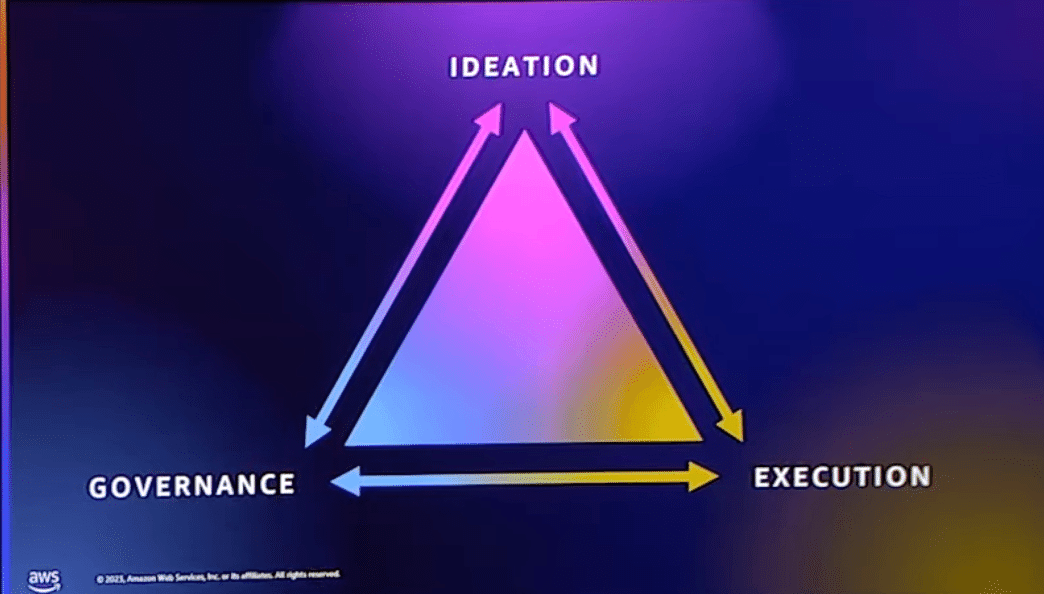
さて、この旅を簡単にするために、自然な緊張感を持つ3つの分野をご紹介し、それについてお客様からお話を伺います。
アイデア
適切なユースケース、適切なアイデアをどのように特定し、選び出し、前へ出すのか?どうやって優先順位をつけるのか?
実行
そのアイデアをどのようにして製品やサービスにするのか。どのようなツールを使うのか?
ガバナンス(企業管理)
顧客や業界にとって適切な場所にいることを確認するために、適切なリスクのバランスをどのようにとるのか?

アイデア出しから始める?
どのようにして適切なユースケースを選ぶのか?それがあなたのビジネスにとって最も大きなチャンスとなるのだろうか?まず、観客のアーティストたち(私たちの多くがそうだ)に対する解決策ではなく、その機会に惚れ込むことだ。私もです。ところで。私たちは素晴らしい技術を見て、それを使いたいと思う。まずは一歩引いて、100万枚の紙切れの下で溺れている問題を解決することで、自分自身に問いかける必要がある。請求書の山はないだろうか?もしかしたら、ここ2、3年でたくさんの新しい従業員を雇ったのかもしれない。あなたが達成しようとしている結果は何ですか?

アマゾンでは、顧客から逆算することが有効だと考えています。この場合は、あなたが特定した問題や機会です。成果志向のマインドセットを持つために必要なことは、成功がどのようなものかを知り、それを定義することです。例えば、コールセンター業務において。顧客の待ち時間を35%減らしたいのか、あるいは、従業員が顧客の質問に85%の確率で答え、スーパーバイザーへの引き継ぎや長い待ち時間が発生しないようにしたいのか?
過去にできたことに縛られてはいけない。
新しい扉を開く目の間に、既成概念にとらわれない発想が必要なんです。今日お聞かせする製品のいくつかをご覧ください。

生成AIで不可能が可能になった。
私たちの顧客が構築しているものの中には、ジェネレーティブAI以前には可能だとさえ思えなかったものもあります
クラウドは10数年前、反復的な実験を行う能力を解放してくれたが、まだそれほど年月が経っていないです。今、クラウドの考え方は、AIを生み出すために拡大することができるのです。何度も反復的な実験をして良い環境があります。そしてあなたには、実験を繰り返すだけのパワーがあるのです。
最近、ある顧客とのアイデア出しセッションで、300のユースケースを思いついた日は、とても刺激的でした。
彼らは、私たちが圧倒されたような日ではありませんでした。あんなに大きなチームを持っているのに、資金を調達する必要もないし、時間もない。
どうやって始めればいいんだ?
普通だったら冷酷に優先順位をつけ、ビジネス価値と実現可能性について考える必要がありますよね。
顧客体験を向上させ、収益を上げる商品の機会について考え始めることとかです。これらすべてをあなたのビジネスにどのように適用しますか?
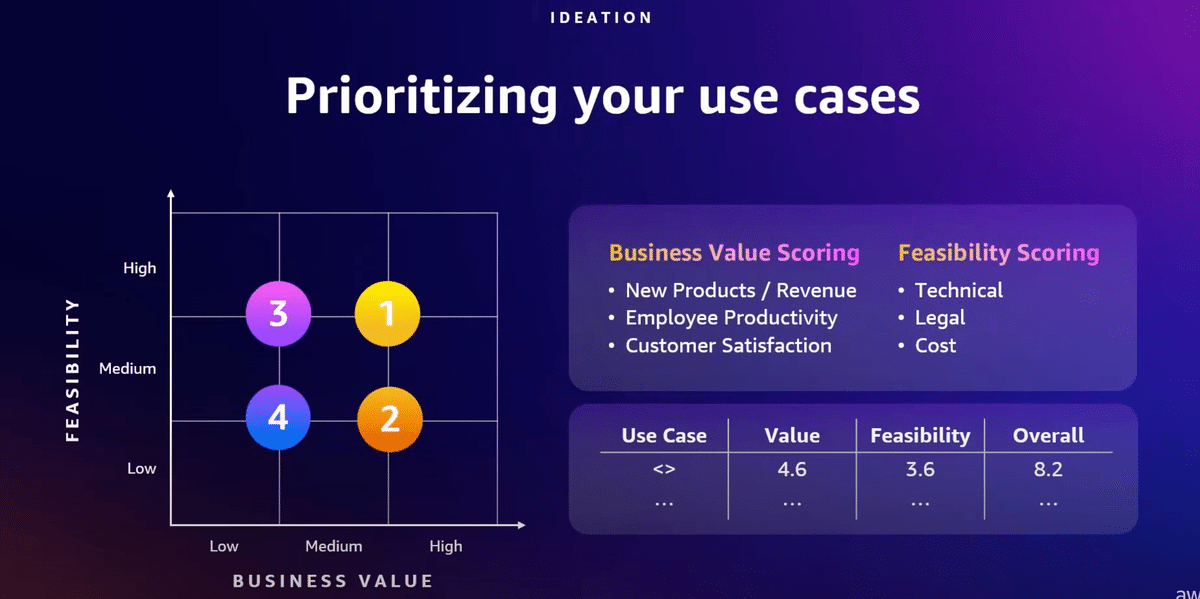
画面上のチャートは、ビジネス上の価値が高い右上の隅に到達するために使用できるメンタル・モデルです。ある種のスコアリングモデルを導入していいます。ご覧ください。

顧客の中でとてもうまくいっている一つの事例がIntuit社です
今朝の基調講演で、みなさんすでにお聞きになっていると思いますけれども、1億人の顧客のために生成AIプラットフォームを構築したということです。、彼らはトップダウンで、AIについて進めていました。
テクノロジーフューチャーズ研究開発チームは、「すべての花は咲く 選んだものを維持して、幅広い学習と実験を奨励しましょう」という信念を持っています。
彼らは、ベストプラクティスを共有し、ビジネスに沿った最も価値のあるユースケースに優先順位をつけることができるミッションベースのチームを立ち上げています。
彼らはGen AIを搭載したFinTechアプリケーション向けに、製品およびサービス全体で大規模に迅速なイノベーションを推進しています
データ基盤を正しく構築することは非常に重要です。データは重要で、AIは膨大な量のデータを生み出しています。例えば、Meadows llamaのモデルは2兆以上のトークン、350百万のWikipediaに相当するデータ量でトレーニングされました
または私たちの企業にとって、生成AIについて最も興味深い点の一つは、データを利用し、独自の競争上の優位性を実現するために収益化する能力があるということです。しかし、まずはその基盤を正しく築く必要がありますね?

そのすべてのデータを保存し維持できるようにすることが重要です。すべてのケースは重要ですから、考慮すべきことがたくさんあります。これは写真を撮るのに良いスライドかもしれません。全てを詳細に説明するには時間がかかりますが、まず多様なデータセットを使用していることを確認することから始めます。データセットがクラウドにあれば、アクセス可能にしたい場合は比較的容易にアクセスできます。それにより、モデルはより多くのパターンを認識し、より創造的で高品質な結果を生成できるようになります。また、ポートフォリオにベクターデータベースを持つことも重要です。これにより、大規模にベクターを保存し検索することが可能となり、ファウンデーションモデルに不可欠な検索拡張生成をサポートします。Amazonは複数のベクターデータベースソリューションを提供しており、Amazon Bedrockの新しいナレッジベースの使用も検討してください。最後に、トレードオフとコストを評価する必要があります。すべてのデータはどこかに保存されなければなりません。S3、インテリジェントティアリング、グレイシャーなどのサービスに対して、どの要素を繰り返し活用し、どの出力を長期間保存するかを考える必要があります。
それでは、実行について話しましょう
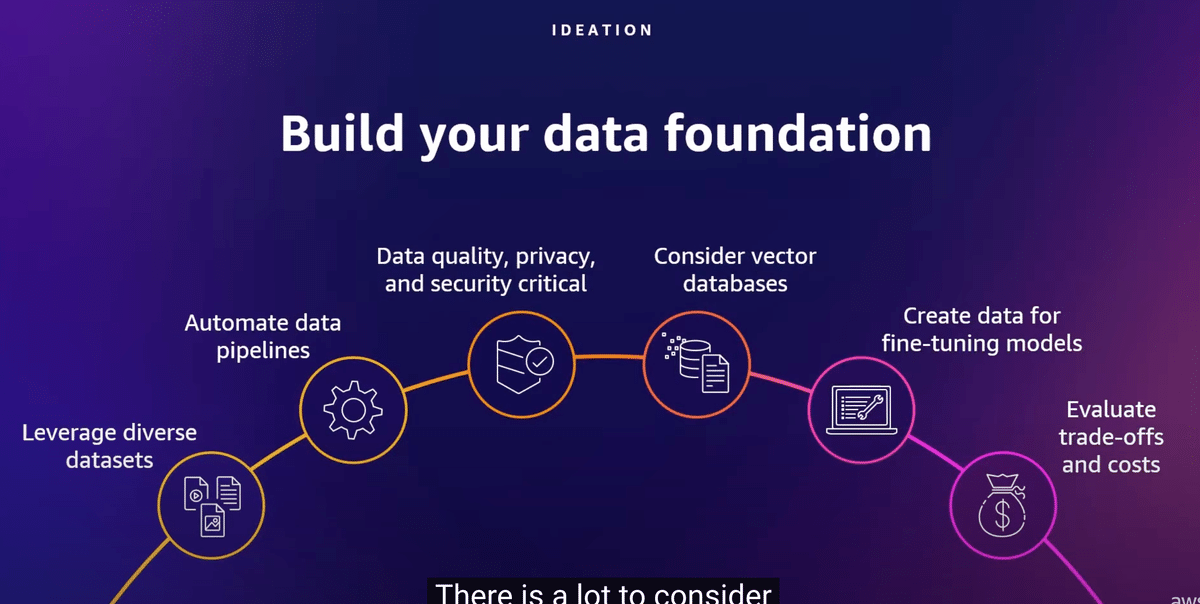
このスライドを写真に撮っておくといいでしょう。
すべてを説明するつもりはないので、時間がかかります。しかし、多様なデータセットを使っていることを確認することから始めよう。データセットはクラウド上にあり、おそらく比較的アクセスしやすいでしょう。そうすれば、モデルはより多くのパターンを理解し、より創造的で質の高い結果を生み出すことができる。あなたのポートフォリオにベクターデータベースがあることを確認したい。これにより、ベクターを大規模に保存し、照会することができ、基礎モデルにとって重要な検索拡張生成をサポートします。Amazonは複数のベクトルDVDを用意しており、Amazon bedrock用の新しい知識ベースの利用も検討しています。最後に、トレードオフとコストを評価する必要があります。これらのデータはすべてどこかに移動しなければなりません。s3、intelligent tearing、glacierのようなサービスのために長期保存したいアウトプットの中で、どの要素を繰り返し活用するかを考える必要がある。

実行について考えるとき、適切な仕事には適切なツールが必要です。顧客に話を聞くと、セキュリティとプライバシー、スケールと価格性能、そして最も重要なのは、自社のビジネスに関連するソリューションが必要だと言われます。私たちは選択肢と柔軟性を重視しています。おそらくアダムスの基調講演でご覧になったスタックに見覚えがあると思います。

私たちはジェネレーティブAIを3つのレイヤーすべてで見ています。
1.1番下は、基礎モデルのトレーニングと推論に最適なインフラがある。
(Infrastructure for FM training and inference)
2.中央は基礎モデルをトレーニングし、構築するためのBedrockを提供します。(Build with FMs)
3.上部は、基礎モデルを使用するアプリケーションです。
(Apprications that leverage FMs)
ユーザは、つまり、どのように動作するかを考える必要がないのです。
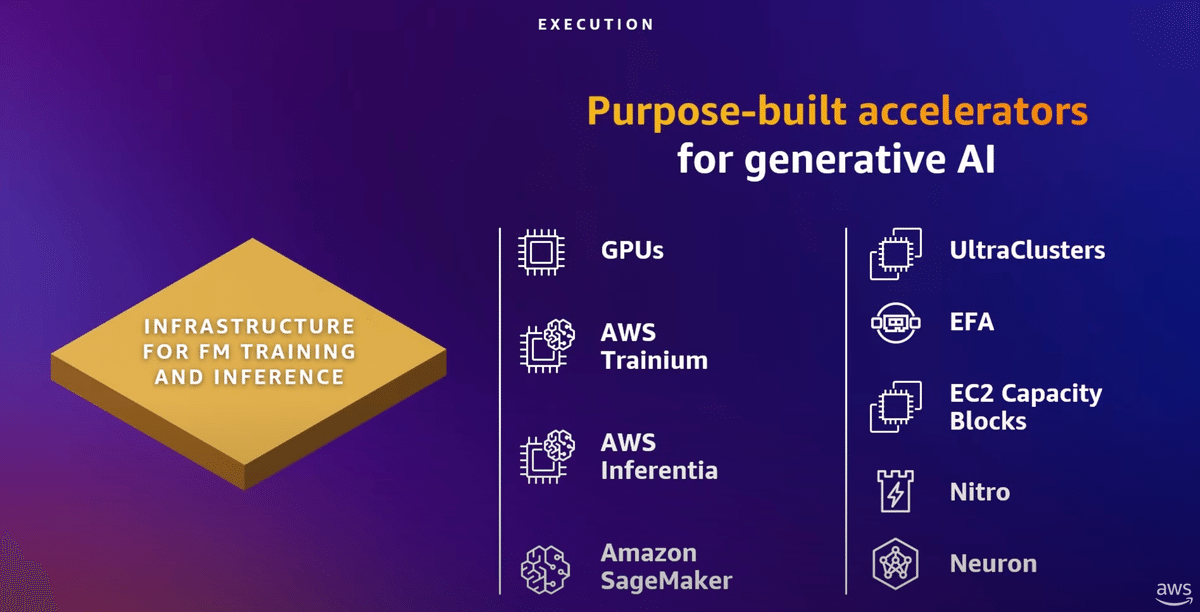
1.Infrastructure for FM training and inference
インフラストラクチャーのスタックの一番下には、トレーニングと推論という2つの主要なタイプのワークロードがあります。
FM(Foundation Model)は数千億のパラメータを含むことができます
例えば、現存する最大のモデルであるファルコン、180億パラメータモデルは、Amazon Sage Makerで4000のGPUと3.5兆のトークンを用いてトレーニングされました。さらに、Sage Maker Hyper Pollachiのような新しいサービスがトレーニングをより容易にしています
昨日、NvidiaのジェンセンCEOとアダムスの基調講演で、Nvidia社とのパートナーシップと、AWSの顧客がNvidia社の最新かつ最高のGPUにアクセスできるようにする方法について話が出ましたね。過去5年間、我々はまた、独自のGPUに投資してきたのです。
GPUとは「Graphics Processing Unit」の略で、日本語では「グラフィックス処理装置」と呼ばれます。もともとはコンピュータの画像やビデオ処理を専門に行うために設計されましたが、現在ではその高い計算能力を生かして、ゲーム、3Dグラフィックス、複雑な数学計算、深層学習、AIの分野などでも広く使用されています。GPUは多数のコアを持っているため、複数の計算を同時に並行して行うことができ、特に大量のデータを扱う処理に適しています
Jensen Huang(ジェンセン・フアン)は、NVIDIA Corporation(エヌビディア コーポレーション)の共同創設者であり、CEO(最高経営責任者)です。NVIDIAはグラフィックス処理ユニット(GPU)の開発で特に有名で、ゲーム業界、プロフェッショナルグラフィックス、データセンター、人工知能(AI)技術など幅広い分野でその製品が使用されています。フアンは1993年にNVIDIAを共同創設し、以来、会社の指導的な役割を担っています。彼のリーダーシップの下、NVIDIAはGPU市場のパイオニアとして、またAIやディープラーニングの分野でも重要な役割を果たす企業へと成長しました。
昨日、アダムはトレーニング・イン・ツーを発表しました。これは従来の4倍の速さでトレーニングが可能で、トレーニング作業に理想的です。推論に関しては、以前の世代よりも70%低コストで提供されるインフェレンシャルを提供しています。このパフォーマンスを最大化しコストをコントロールする能力が、Anthropic、Stability AI、Grammarlyのような先導的なAIスタートアップや、AutodeskやAirbnbのような企業がAWSを利用している理由です。スタックの中心に行くと、Amazon Bedrockについてです。これは、高性能なファウンデーションモデルの選択肢を提供する、完全に管理されたサーバーレスサービスです。トップのFMで実験し、自社のデータでカスタマイズし、保険請求の処理から在庫管理までのビジネスタスクを実行するためにBedrockエージェントを使用することができ、コードを一切書かずにこれらを行うことができます。インフラストラクチャの管理について心配する必要はありません
Python開発における「推論」(Inference)とは、機械学習やディープラーニングモデルを使用して、新たなデータや入力に対して予測や判定を行うプロセスを指します。

2.Build with FMs
スタックの中央に進むと、Amazon Bedrockについてです。これは高性能なファウンデーションモデルの選択肢を提供する完全に管理されたサーバーレスサービスです。トップのFMで実験し、それらを自社のデータでカスタマイズし、Bedrockエージェントを使用して、保険請求の処理から在庫管理までのビジネスタスクをコードを一切書かずに実行することができます。インフラストラクチャの管理について心配する必要はなく、BedrockはGDPRおよびHIPAAのコンプライアンスをサポートしています。その本当の力は、単一のAPIであるということです。これにより、ファウンデーションモデル間で簡単に切り替え、実験し、最小限の再作業でアップグレードや革新を行うことができます。始めたモデルに縛られることはありません。
そして今朝スワミから聞いたように、Bedrock独占で、私たちはAmazon Titanファミリーのモデルを持っており、高性能なイメージ、マルチモーダル、テキストモデルの選択肢を含んでいます
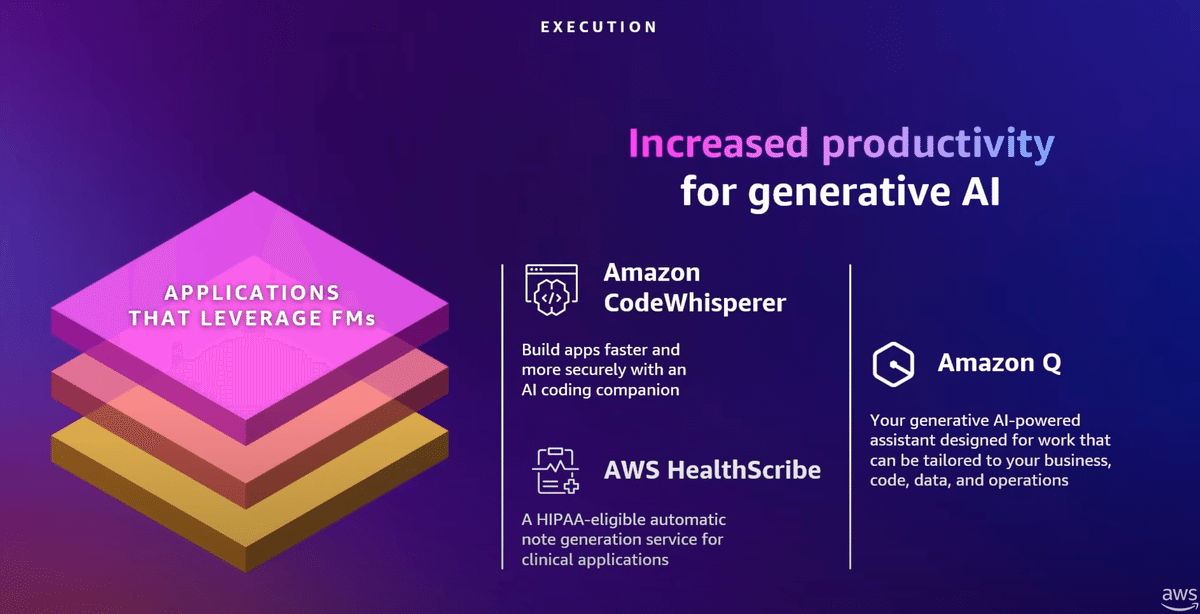
3.Apprications that leverage FMs
スタックの最上層において、私たちは、顧客が彼らの顧客を支援するのを助けるための顧客を構築しています
Amazon Code Whispererはコーディングを合理化し、AWS Health Scribeは医療における臨床効率を向上させ、医者と患者の会話から自動的に診断を行います。これは始まりに過ぎません。
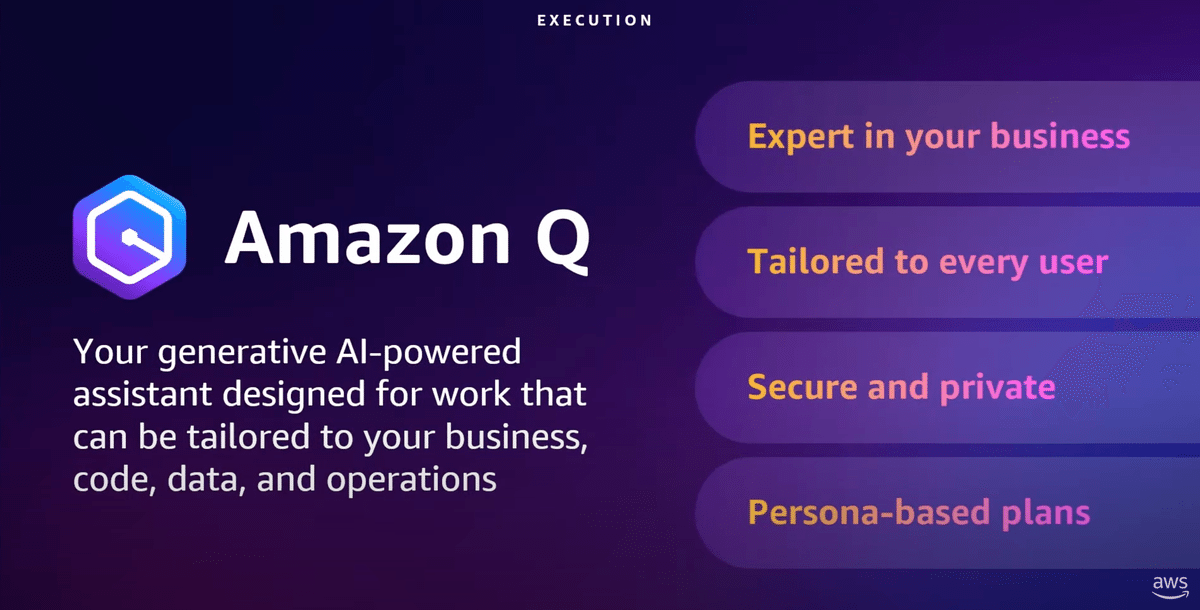
昨日、Amazon Qを発表しました。Amazon Qはゲームチェンジャーです。これは、企業向けに設計されたアシスタントで、初日から企業のビジネスに合わせてカスタマイズされます。
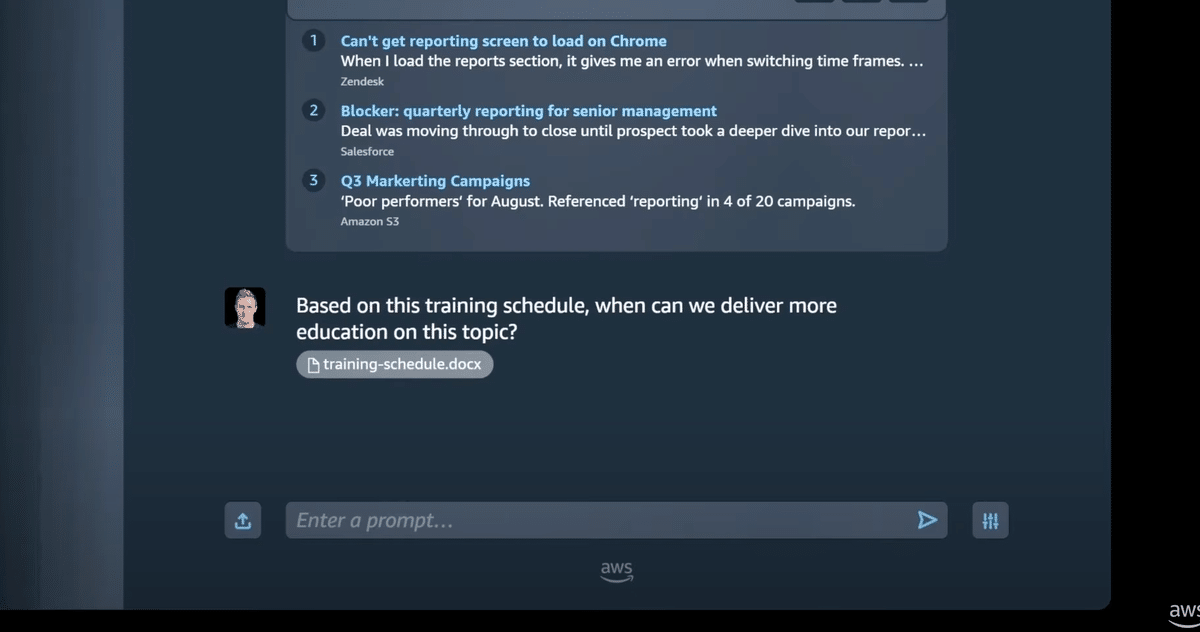
Qに接続させる企業データを使用し、
マットがQとチャットして、質問だけでなく自分のデータを追加し、
Qがリアルタイムでインサイトを返すのを見ることができます。

ビジネスデータ、情報、システムに接続し、ビジネスに関連する会話、コンテンツの生成、アクションを行うことができます。Qはマスの役割と、アクセスできるシステムを理解します。マットがレビューするためのJIRAチケットを実際に作成するQを見ることができます。Amazon Qは、最初から厳格な企業のセキュリティおよびプライバシー要件を満たすように設計されています。

さて、リスクのバランスをどうとるか?ガバナンスについて話そう。
すべてのFMモデルには幻覚のリスクがありますよ。
ただ、ガードレールと、専門家をどのようにループに入れるかを考えなければならない。
リスクの低い適切なユースケースを選び、適切なデータがモデルをトレーニングしていることを確認するのですね。
例えば、財務チームをサポートするために生成AIを使用する場合、問題を特定するためのアイデアを導き出したいでしょう。
でも従業員や顧客が有害なコンテンツを見ないようにしたい。
もちろん、知的財産権所有者のことも考えなければならないのです。

企業データ
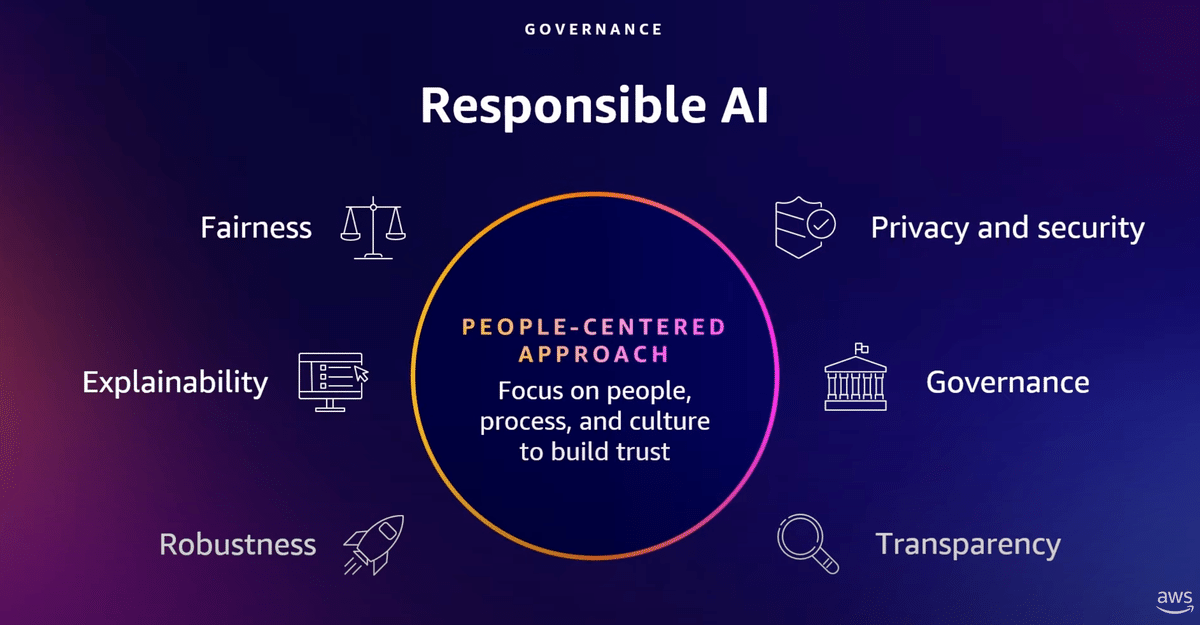
責任あるAIプログラムを実施するための最初の行動を開始します。
透明性、公平性、説明責任、プライバシーの原則に従うことです。
責任あるAIプログラムには、考慮すべき多くの属性があります。
これらはすべて人間の監視が必要であり、AIは人間の判断を補強するものであって、それに取って代わるものではないのです。
そのためには、機能横断的なチームを結成する必要があります。

このガードレールズ・オン・ベッドロックは、あらゆる基礎モデルに適用可能で、ベッドロックによってサポートされる微調整されたモデルやエージェントにも利用できます。これにより、AIの使用に際して、より安全で責任あるフレームワークを提供することが可能になります。
有害なコンテンツフィルタリングの設定であれ、責任あるAIポリシーに従うことであれ、短い自然言語ディスカッションで拒否されたトピックを定義し、禁止することであれ、一度でも行えば、そのユースケースでBedrockを使用するすべてのモデルに適用され、近々、機密性の高いPII情報やFMの応答を再編集できるようになります。
素晴らしい。
この記事が気に入ったらサポートをしてみませんか?