
Python初心者が東京23区の合計特殊出生率を予測してみた

はじめに
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
40代2児の母、文系出身の私ですが、一念発起してAidemyのオンラインAI学習サービス6ヵ月コースを受講しデータ分析を学んできました。
受講中早い段階から、「成果物には東京の合計特殊出生率を予測してみよう」と妄想していたので、なんとか形になっていると幸いです。
本記事の概要
この記事では、東京23区に限定して2025年の合計特殊出生率を予測するモデルを紹介します。
日本全体や、東京都全体での合計特殊出生率はニュースで聞いたことがあるよという方、23区在住で自分の区ってどうなの?と気になっていた方、グラフを見るだけでも楽しめると思います。
23区限定にしているので、東京市部や島部の情報は含まれていません。
開発環境
Google Colaboratory
Python3
Windows
データ参照元
基本的に東京都公式ページから取得したデータに基づいて作成しています。
東京23区別の合計特殊出生率:https://www.hokeniryo.metro.tokyo.lg.jp/kiban/chosa_tokei/jinkodotaitokei/kushityosonbetsu.html
ファイル形式:CSV
ファイル名:合計特殊出生率(平成5年~令和4年)04goukei
相関がありそうと予測したデータ:
国勢調査 国勢調査 東京都区市町村町丁別報告 令和2年国勢調査 東京都区市町村町丁別報告|東京都の統計 (tokyo.lg.jp)
作成したプログラム
大きく3つ、プログラムを作成しました。
2002年から2022年までの23区別合計特殊出生率推移をグラフで表し、直近最も出生率が高い区、最も低い区、23区平均値をハイライト
合計特殊出生率と相関があるのでは?と予測した23区別65歳以下単身世帯率との相関分析
本題の2025年合計特殊出生率予測モデル
まずは1つ目について、グラフはこちら。
2002年から2017年にかけて、実は大半の区で出生率が上昇していました。その後は急激に下がっていきます。大きく影響しているイベントは新型コロナウィルス感染症の流行と思われます。
そんな中で直近最も出生率が高かったのは中央区(赤線)。1.31という23区平均(黄色線)の1.04を大きく上回りました。一方、2016年をピークに出生率が激減したのは板橋区(青線)。2022年の値は中野区と並んで0.92に留まります。

このグラフの描写のために作成したプログラムがこちら。
1つ目ともあって、データの読み込みからかなり苦戦しました。
Google Colaboratoryのデータ保存先やCSV形式への加工に慣れてようやくグラフ作成までたどり着きました。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as np
# データの読み込み
df_birth_rate = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/df_tokyo_23.csv', encoding="shift-jis")
# CSVファイルの列名を確認
print(df_birth_rate.columns)
# 2022年のデータを抽出
df_2022 = df_birth_rate[df_birth_rate['Year'] == 2022]
# 2022年の合計特殊出生率が最も高い区と最も低い区を特定
highest_birth_rate_district = df_2022.sort_values(by='Birth_Rate', ascending=False).iloc[0,0]
lowest_birth_rate_district = df_2022.sort_values(by='Birth_Rate', ascending=True).iloc[0,0]
# グラフの設定
plt.figure(figsize=(15,10))
# 各区のデータをプロット
for city in df_birth_rate["City"].unique():
city_data = df_birth_rate[df_birth_rate["City"] == city]
if city == highest_birth_rate_district:
color = 'red' # 最も高い出生率の区は赤色
elif city == lowest_birth_rate_district:
color = 'blue' # 最も低い出生率の区は青色
elif city == "Average":
color = 'yellow' #23区平均の出生率は黄色
else:
color = 'grey' # それ以外の区はグレー
plt.plot(city_data['Year'], city_data['Birth_Rate'], label=city, color=color)
# グラフのタイトルと軸ラベルを英語に設定
plt.title('Transition of Total Fertility Rate by District in Tokyo for 2022')
plt.xlabel('Year')
plt.ylabel('Total Fertility Rate')
# 凡例を表示
plt.legend()
plt.show()
2つ目のプログラムは、合計特殊出生率と相関があるデータなのではないか?と取得した23区別の婚姻数推移データを使った相関分析です。
データを結合し、相関係数を計算してみたのですが、
相関係数: 0.01236543129322613
相関係数は1に近いほど、2つの変数は正の相関があると言われます。 すなわち、1つの変数が増加すると、もう1つの変数も増加する傾向があります。 相関係数が-1に近いほど、2つの変数は負の相関があると言われます。 すなわち、1つの変数が増加すると、もう1つの変数が減少する傾向があります。
この値はむしろゼロに近いので、残念ながら出生率との相関があるとはいえないものでした。
import pandas as pd
# 出生率のデータを読み込み
df_birth_rate = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/df_tokyo_23.csv')
# 婚姻数のデータを読み込み
df_marriage = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/04koninrikon_tokyo_23.csv')
# データを結合
df_combined = pd.merge(df_birth_rate, df_marriage, on=['Year', 'City'])
# 相関係数を計算
correlation = df_combined['Birth_Rate'].corr(df_combined['Marriage_Count'])
print(f'相関係数: {correlation}')ここで諦めきれず、もう1つ探してきたのが国勢調査の「世帯の家族類型(13区分)別一般世帯数というデータ。
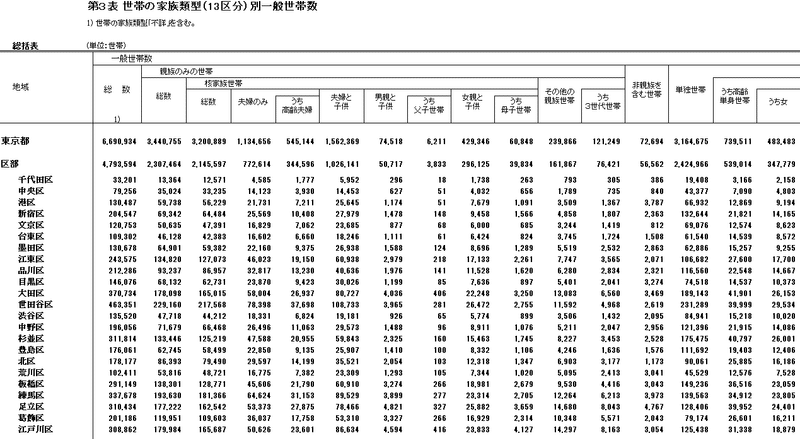
23区別の単独世帯の数が記載されています。その内訳として高齢単身世帯が分類できたので、それを除いた独身世帯を総世帯数で割った「65歳以下独身世帯率」を求めてみました。
それと出生率との相関分析がこちら。
相関係数: -0.39331605696780764
先ほどの婚姻数よりは負の相関係数が高くなりました。独身世帯率が低い区ほど出生率は上がる、と言えなくもない、といったところでしょうか。
import pandas as pd
# 出生率のデータを読み込み
df_birth_rate = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/df_tokyo_23.csv')
# 65歳以下の単身世帯率データをよみこみ
df_marriage = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/households_05_20.csv')
# データを結合
df_combined = pd.merge(df_birth_rate, df_marriage, on=['Year', 'City'])
# 相関係数を計算
correlation = df_combined['Birth_Rate'].corr(df_combined['under65ratio'])
print(f'相関係数: {correlation}')そして最後3つ目のプログラムで、いよいよ出生率の予測を行っています。
大まかに、先ほどの独身(単身)世帯率データを出生率の特徴量として使い、SVM(サポートベクターマシン)モデルで2025年の出生率を予測しています。
import pandas as pd
import numpy as np
from sklearn.svm import SVR
import matplotlib.pyplot as plt
# 出生率のデータを読み込み
df_birth_rate = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/df_tokyo_23.csv')
# 65歳以下の単身世帯率データを読み込み
df_single_household = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/households_05_20.csv')
# データの結合
df_combined = pd.merge(df_birth_rate, df_single_household, on=['City', 'Year'])
# 23区別にデータを分割し、モデルを作成
districts = df_combined['City'].unique()
colors = plt.cm.rainbow(np.linspace(0, 1, len(districts)))
models = {}
predictions = {}
predictions_list = {}
# グラフのスタイル設定
plt.style.use('seaborn-darkgrid')
# 凡例の位置を調整
plt.figure(figsize=(15, 10))
for district, color in zip(districts, colors):
# 各区のデータを取得
district_data = df_combined[df_combined['City'] == district]
# 特徴量として年と65歳以下の単身世帯率を使用
X_district = district_data[['Year', 'under65ratio']].values
y_district = district_data['Birth_Rate'].values
# サポートベクターマシンモデルを作成し、訓練
model = SVR(kernel='rbf')
model.fit(X_district, y_district)
models[district] = model
# 予測を行う
future_years = np.array([[2020, district_data['under65ratio'].iloc[-1]],
[2025, district_data['under65ratio'].iloc[-1]]])
predictions[district] = model.predict(future_years)
# 既存データと予測値をプロット
plt.plot(district_data['Year'], y_district, color=color, label=district, linestyle='-', linewidth=2)
plt.plot(future_years[:, 0], predictions[district], color=color, label=f'{district} prediction', linestyle='--', linewidth=2)
# 予測値をリストで保存
predictions_list[district] = predictions[district]
# 凡例を表示
plt.legend(loc='upper left', bbox_to_anchor=(1, 1))
plt.xlabel('Year')
plt.ylabel('Birth Rate')
plt.title('Predicted Birth Rates for Tokyo 23 Districts with SVM')
plt.show()
# 予測値のリストを表示
for district in predictions_list:
print(f'{district}: {predictions_list[district]}')
今後の活用
現在はITコンサル企業に勤務しているものの、自らプログラムを作るような機会は皆無だったので、この6か月間で非常に多くのことを学ぶことができました。さらに成果物作成によって、分析に足るデータにたどり着く重要性をヒシヒシと感じました。すぐ今の業務に生かせる機会が来るかはまだ不明瞭ですが、これを機にキャリアの幅を広げていきたいと思います。
おわりに
6か月前、Pythonを全く知らない状態で受講を始め、途中何度やっても理解が追い付かないコースもあったりしましたが、そんな私でも最終成果物までたどり着くことができました。ここで終わりではなく、学んだことを日々使いこなしていく、さらに発展して学んでいく、というサイクルに繋げて行けるよう継続して頑張りたいと思います。
この記事が気に入ったらサポートをしてみませんか?