
Sentence BERT論文-和訳

記事概要
今回の記事では、Sentence BERTと呼ばれるNLPのブレイクスルーと言われ久しいBERTの文章ベクトル化タスクを改良したモデルについて簡単な解説とその和訳を記載しています。
Sentence-BERTとは
上記で述べた通りBERTの文章ベクトル化にフォーカスを当てて改良(Fine tuning)したものとなります。
主に何ができるかと言うと、文章同士の類似度を文章ベクトルから計算して分類やcosine類似度のタスクをこなせます。
Sentence-BERT何がすごい?
簡単言いますと精度と計算効率が素晴らしいです。
精度
Sentence-BERTは文字通りBERTをベースに構築されておりより細かく言うと事前学習されたBERTモデルにプーリング層を追加することで高精度の文埋め込みの精度を獲得しました。
上図のネットワーク図がその形となっています。

2文(SeteneceA, B)入力することで上図(左)ではクラスを分類し、上図(右)ではcosine類似度を計算します。
計算効率
計算効率は以下論文の和訳から抜粋しました。
10,000文のコレクションの中から最も類似した文のペアを見つけるための複雑さは、BERTでは65時間であったものが、10,000文の文の埋め込みの計算(SBERTでは5秒程度)とcosine類似度の計算(0.01秒程度)にまで短縮された。
通常のBERTだと65時間これをSBERTでは5秒まで効率化することができました。
ハードウェアを固定し文埋め込みタスクのパフォーマンス比較についてこちらも論文内になりますが
ハードウェア構成
・Intel i7-5820K CPU @ 3.30GHz
・Nvidia Tesla V100 GPUCUDA 9.2
・cuDNN
比較したモデルは下記になります
・Avg. GloVe Embeddings
・InferSent
・Universal Sentence Encoder
・SBERT-base
・SBERT-base smart batching
結果は表7に示されています。
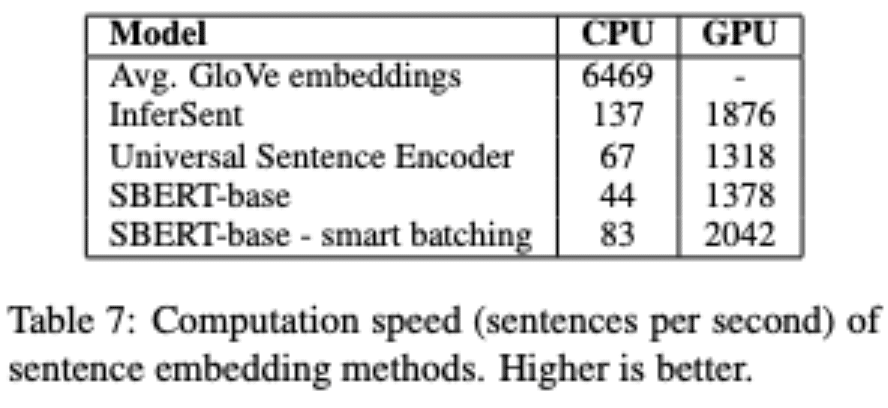
文埋め込み/秒の単位で数値が大きいほどより多くの文埋め込みを処理できるようになっています。
CPU上では、単純なネットワークアーキテクチャのInferSentはSBERTよりも約65%高速である。
InferSentは単一のBiLSTM層を使用しているのに対し、BERTは12個の積層されたトランスフォーマー層を使用しています。
しかし、トランスフォーマーネットワークの利点は、GPU上での計算効率です。
そこでは、スマートバッチングを用いたSBERTは、InferSentよりも約9%、Universal Sentence Encoderよりも約55%高速である。
スマートバッチングは、CPUで89%、GPUで48%の高速化を達成しています。
Sentence BERTは何に使えるか
確かにSentence BERTでは高精度かつ高効率に文章ベクトル化が行えることが分かりました。
では、それができると何使えるのか多分こちらが最も関心の対象となると思います。
代表的なものをいくつかあげておきます。
・チャットボット
・問い合わせサイトへの質疑応答システム
・類似文章検索
どれも以前から存在するものですがより高精度で高効率でそして柔軟な対応が可能となることが期待できます。
Varealでの取り組み
Varealでは、最新論文や技術の実証/導入だけでなくPoC、機械学習を含むシステム構築、運用までサポートすることが可能です。
ご興味をお持ちいただけましたら是非御問い合わせください。
ちなみに、現在はSentence BERTを用いた質疑応答システムの研究開発を中心としてNLP周りに取り組んでおります。
それ以外にも、顔認証システムや表形式データへの機械学習システム構築/運用、データサイエンスの基本である統計のセミナーや経営者の方に向けた機械学習活用セミナーも行っております。
ライオン株式会社様 パーソナライズされたレコメンドAIの開発
論文の和訳
以下、Sentence-BERTの現論文の和訳となります。
拙い和訳のためご容赦ください。
こちらがSentence BERTの原論文になります
https://arxiv.org/abs/1908.10084
Apatch v2に基づきを和訳を作成しております。
概要
BERTおよびRoBERTaは意味的テキスト類似度(STS)のような文の意味類似の回帰文ペアタスクのSoTAです。
どちらのネットワークもペアの文を入力する必要があり膨大な計算のオーバーヘッドが発生します。
10,000 文のコレクションの中から最も類似したペアを見つけるには、BERT を使用して約 5,000 万回の推論計算(~65 時間)を必要とします。
BERTの構造は、BERTは意味的な類似性検索だけでなく、クラスタリングのような教師なしタスクにも適していません。
この論文では、cosine-類似度を用いて比較可能な意味的に意味のある文埋め込みを導出するために、Siameseとトリプレットのネットワーク構造を使用して事前訓練されたBERTネットワークの改良版であるSentence-BERT(SBERT)を提示する。
これにより、BERT/RoBERTaでは65時間かかっていた最も類似したペアを見つけるための時間が、SBERTでは約5秒に短縮され、BERTの精度は維持される。
1 導入
本論文では、意味のある文の埋め込みを実現するために、Siameseネットワークとトリプレットネットワークを用いたBERTネットワークの改良版であるSentence-BERT(SBERT)を紹介する。
これにより、これまでBERTには適用できなかった特定の新しいタスクにBERTを使用することが可能になる。
これらのタスクには、大規模な意味論的類似性比較、クラスタリング、意味検索による情報検索などが含まれます。
BERTは、様々な文分類と文ペア回帰タスクにおいて、新しい最先端の性能を実現しました。
BERTはクロスエンコーダーを使用しており、2つの文がトランスフォーマーネットワークに渡され、目標値が予測される。
しかし、この設定は、可能な組み合わせが多すぎるため、様々なペア回帰タスクには不向きである。
10,000文の中から最も類似度の高いペアを見つけるには、BERTでは、n-(n-1)/2 = 49,995,000回の推論計算を必要とします。
同様に、Quora の 4,000 万以上の質問のうち、新しい質問に対して最も類似しているのはどれかを見つけることは、BERT を用いたペアワイズ比較としてモデル化することができますが、1 つのクエリに答えるには、50 時間以上を必要とします。
クラスタリングやセマンティック検索を行うための一般的な方法は、各文を意味的に類似した文が近くなるようにベクトル空間にマッピングすることである。 研究者たちは、特定の文をBERTに入力し、固定サイズの文の埋め込みを導出することを始めている。 最も一般的に使用されているアプローチは、BERT出力層(BERT embeddingsとして知られている)を平均化するか、または最初のトークン([CLS]トークン)の出力を使用することである。 我々が示すように、この一般的な方法では、かなり悪い文埋め込みが得られ、多くの場合、GloVe文埋め込みの平均よりも悪いことがある(Pennington et al., 2014)。
この問題を解決するために、私たちはSBERTを開発しました。
cosine類似度やマンハッタン/ユークリッド距離のような類似度尺度を用いることで、文の類似度が非常に高い文を見つけることができる。
これらの類似度測定は、最新のハードウェア上で非常に効率的に実行でき、SBERTを意味的類似度検索にもクラスタリングにも使用できるようになります。
10,000文のコレクションの中から最も類似した文のペアを見つけるための複雑さは、BERTでは65時間であったものが、10,000文の文の埋め込みの計算(SBERTでは5秒程度)とcosine類似度の計算(0.01秒程度)にまで短縮された。
我々は、NLIデータ上でSBERTを微調整し、InferSent(Conneauら、2017)やUniversal Sentence Encoder(Cerら、2018)のような他の最先端の文埋め込み手法を大幅に上回る文埋め込みを作成した。
7つの意味的文章類似性(STS)タスクにおいて、SBERTは、InferSentと比較して11.7ポイント、Universal Sentence Encoderと比較して5.5ポイントの改善を達成した。
文埋め込みの評価ツールキットであるSentEval(Con-neau and Kiela, 2018)では、それぞれ2.1点と2.6点の改善を達成している。
SBERT は、特定のタスクに適応させることができる。
本論文は以下のように構成されている。
第3節ではSBERTを紹介し、第4節ではSBERTを一般的なSTSタスクと並列引数ファセット類似性(AFS)コーパス(Misra et al., 2016)で評価する。
第5節では、SentEval上でSBERTを評価する。
第6節では、SBERTの設計面のいくつかをテストするためにアブレーション研究を行う。
第7節では、SBERT文埋め込みの計算効率を、他の最新の文埋め込み手法と比較する。
2 関連作業
最初にBERTを紹介し、次に最先端の文埋め込み法について述べる。
トランスフォーマーネットワーク(Vaswaniら、2017)は、質問応答、文のクラス分け、回帰文ペアを含む様々なNLPタスクのための新しい最先端の結果を設定した。
回帰文ペアのためのBERTの入力は、特別な[SEP]トークンで区切られた2つの文から構成される。
12 層(ベースモデル)または 24 層(ラージモデル)にわたるMultiHead-Attentionが適用され、出力は、最終ラベルを除去するために単純な回帰関数に渡される。
このセットアップを使用して、BERTは、SemanticTextual Semilarity(STS)ベンチマーク(Cer et al. RoBERTa (Liu et al.,2019)は、BERTの性能が、事前学習プロセスへの小さな適応によってさらに改善されることを示した。
我々は、XLNet(Yangら、2019)も試験したが、一般的にBERTよりも悪い結果をもたらした。
BERT ネットワーク構造の大きな欠点は、独立した文の埋め込みが計算されないことであり、これは BERT から文の埋め込みを除去することを困難にする。
この限界を回避するために、研究者は、単一文をBERTに通し、その後、出力を平均化するか(平均語の埋め込みに似ている)、または特殊なCLStokenの出力を使用することによって、固定サイズのベクトルを導出する(例えば、Mayら(2019)。これら2つのオプションは、ポピュラーなサービスリポジトリ3でも提供されています。
これらの方法が有用な文の埋め込みにつながるかどうかは、今のところ評価されていない。
文の埋め込みはよく研究されている分野であり,数多くの手法が提案されている。
Skip-Thought(Kiros et al., 2015)はエンコーダ・デコーダアーキテクチャーを訓練して周囲の文を予測する。
InferSent(Conneau et al., 2017)はStanford Natural Language Inferencedataset(Bowman et al., 2015)とMulti-Genre NLI dataset(Williams et al., 2018)のラベルデータを使用している。
Conneauらは、InferSentがSkipThoughtのような教師なし手法を一貫して凌駕することを示した。
Universal SentenceEncoder (Cer et al., 2018)は、変換ネットワークを訓練し、SNLI上での訓練で教師なし学習を強化する。
Hillら(2016)は、文埋め込みを訓練するタスクがその品質に大きく影響することを示した。
以前の研究(Conneau et al., 2017; Cer et al., 2018)では、SNLIデータセットが文埋め込み学習に適していることを発見しました。
Yang et al. (2018)は、Redditからの会話を学習する方法として、siamese DANとsiamese transformer net-worksを用いた方法を発表しており、STSbenchmarkデータセットで良い結果が得られました。
Humeau et al. (2019)は、BERTからのクロスエンコーダーのランタイムオーバーヘッドに対処し、Attentionを使用してm文脈ベクトルと事前に計算された候補埋め込みの間でスコアを計算する方法(ポリエンコーダー)を提示している。
しかし、ポリエンコーダーは、スコア関数が対称的ではなく、計算オーバーヘッドが大きすぎるため、クラスタリングのような用途では、O(n^2)スコア計算を必要とするという欠点がある。
これまでのニューラル文埋め込み法では、ランダムな初期化から学習を開始していた。
この論文では、事前に訓練されたBERTとRoBERTaネットワークを使用し、有用な文の埋め込みを得るためにそれを微調整するだけである。
これにより、必要な訓練時間が大幅に短縮される。SBERTは20分未満で調整でき、同等の文埋め込み方法よりも優れた結果を得ることができる。
3 モデル
SBERTは、固定サイズの文埋め込みを導出するために、BERT / RoBERTaの出力にプーリング操作を追加する。
我々は、3 つのプーリング戦略を実験する。
CLS-トークンの出力を使用し、すべての出力ベクトルの平均を計算し(MEAN-戦略)、出力ベクトルの最大オーバータイムを計算する(MAX-戦略)。デフォルトの設定はMEANとしている。
BERT / RoBERTaを微調整するために、我々は、生成された文の埋め込みが意味的に意味があり、cosine類似度と比較できるように重みを更新するためにsiameseおよびtripletネットワーク(Schroffら、2015)を作成する。
ネットワークの構造は利用可能な学習データに依存する. 以下の構造と目的関数を用いて実験を行います。
分類目的関数
文の組込み量uandvwitdsと要素間の差|u-v|を連結し、これに学習可能な重み
![]()
を乗算しま
![]()
は文の埋め込みの次元であり,ラベルの数である.クロスエントロピー損失を最適化する。 この構造を図1に示します

回帰目的関数
2つの文の埋め込み間の余弦類似度を計算します(Figure2)。 目的関数には、平均二乗誤差損失を用いています。
トリプレット目的関数
アンカーセンテンスa、正のセンテンスp、負のセンテンスnが与えられると、トリプレット損失は、ネットワークをチューニングします。
数学的には、次のような損失関数を微分する。
![]()
sxはa/n/p,||・||aの距離メトリックとマージンεのための文の埋め込みです。
マージンεはspがsnよりもsaに少なくとも近いことを保証するものである。
指標としては、ユークリッド距離を用い、実験では1とした。
3.1 訓練の詳細
我々は、SNLI(Bowman et al., 2015)とMulti-Genere NLI(Williams et al., 2018)のデータセットを組み合わせてSBERTを訓練する。
SNLIは、contradiction, eintailment,neutralというラベルで注釈された57万組の文ペアの集合体である。
MultiNLIは43万組の文対を含み、話し言葉と書き言葉の幅広いジャンルをカバーしている。
我々は、1つのエポックについて、3way softmax 分類器目的関数を用いてSBERTを微調整した。
バッチサイズは16、学習率2e-5のAdamオプティマイザ、学習データの10%以上を線形学習率でウォームアップさせ、デフォルトのプーリング戦略はMEANを設定した。
4 評価 (意味的テキスト相似性)
我々は、一般的な意味的テキスト相似性(STS)タスクに対するSBERTの性能を評価する。最新の手法は、文の埋め込みを類似度スコアにマッピングする(複雑な)回帰関数を学習することが多い。
しかし、これらの回帰関数はペアワイズで動作するため、文のコレクションが一定のサイズに達すると、組み合わせが爆発的に増大するため、スケーラブルではないことが多い。
我々は、負のマンハッタン距離と負のユークリッド距離を類似度の尺度として用いて実験を行ったが、すべてのアプローチの結果はほぼ同じであった。
4.1 教師なしSTS
我々は、STS 固有のトレーニングデータを使用せずに、STS のための SBERT の性能を評価する。
STSタスク2012-2016(Agirre et al., 2012,2013,2014,2015,2016)、STSベンチマーク(Ceret al., 2017)、およびSICK-Relatednessデータセット(Marelli et al., 2014)を使用する。
これらのデータセットは、文のペアの意味的関連性について0から5の間のラベルを提供する。
Reimers et al.,2016で、ピアソン相関がSTSに適していないことを示した。
その代わりに、文の埋め込みのcosine類似度と金ラベルの間のスピアマン順位相関を計算する。
他の文埋め込み法と同様に、cosine類似度を用いて類似度を計算しています。結果を表に示す。

結果は、BERT の出力を直接使用すると、かなり低い性能になることを示しています。
BERT 埋め込みを平均化すると、平均相関はわずか 54.81 であり、CLS-token 出力を使用すると、平均相関は 29.19 にしかなりません。
どちらも、平均的なGloVe埋め込みを計算するよりも悪い結果となっています。
このようにして得られたネットワーク構造と微調整機構を用いることで、相関関係が大幅に改善され、InferSentとUniversal Sentence Encoderの両方を大幅に凌駕することができました。
SBERT が Universal Sentence Encoder よりも性能が劣る唯一のデータセットは SICK-R である。
Universal Sentence Encoder は、ニュース、質問回答ページ、討論フォーラムを含む様々なデータセットで訓練されたが、これは SICK-R のデータにより適しているように思われる。
対照的に、SBERTはWikipedia(BERT経由)とNLIデータのみで事前学習された。
RoBERTaは、いくつかの教師付きタスクのパーフォーマンスを向上させることができたが、文の埋め込み生成に関しては、SBERTとSRoBERTaの間にわずかな差しか見られなかった。
4.2 教師ありSTS
STSベンチマーク(STSb) (Cer et al., 2017)は、教師付きSTSシステムを評価するための一般的なデータセットである。
データには、captions,news,forumsの3つのカテゴリから8,628文ペアが含まれている。
データは、訓練(5,749)、開発(1,500)、テスト(1,379)に分けられている。 BERTは、両方の文をネットワークに渡し、出力に単純回帰法を使用することで、このデータセットの新しいSoTAとなりました。
我々は、回帰目的関数を用いてSBERTを微調整するために訓練セットを使用した。
予測時には、文の埋め込みの間のcosine類似度を計算する。
すべてのシステムは、分散に対抗するために10個のランダムシードを用いて学習した(Reimers and Gurevych, 2018)。
結果を表2に示す。
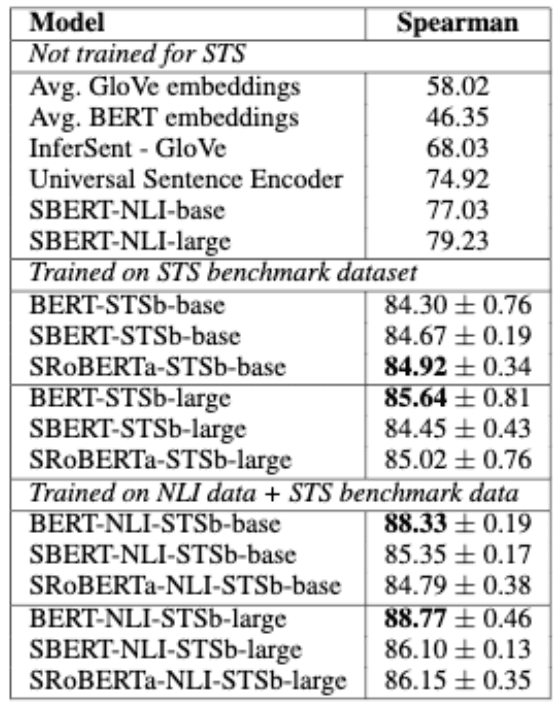
我々は2つのセットアップを用いて訓練を行った。
STSb上での訓練のみ、およびNLI上で最初に訓練を行い、その後STSb上で訓練を行う。
その結果,後者の方が1-2ポイントの改善が見られた。
この2段階のアプローチは、特にBERTクロスエンコーダーに大きな影響を与え、性能が3-4ポイント改善された。
BERT と RoBERTa の間には大きな違いは見られませんでした。
4.3 引数ファセットの類似性
我々は、Misraら(2016)によるArgument Facet Sim-ilarity (AFS)コーパス上でSBERTを評価する。
AFSコーパスは、銃規制、同性婚、死刑という3つの論争的なトピックに関するソーシャルメディアの対話から得られた6,000個の文面的な引数ペアをアノテーションしたものである。
データは、0(「異なるトピック」)から5(「完全に等しい」)までのスケールでアノテーションされた。
AFSコーパスの類似性の概念は、SemEvalのSTSデータセットの類似性の概念とはかなり異なっています。
STSのデータは通常、記述的なものであるのに対し、AFSのデータは対話からの論証的な引用文である。
似ているとみなされるためには、議論は似たような主張をするだけでなく、似たような推論をしなければなりません。
さらに、AFSでは、文間の語彙的なギャップが非常に大きくなっている。
したがって、単純な教師なし手法と最新のSTSシステムは、このデータセットではパフォーマンスが悪い(Reimers et al., 2019)。
このデータセットについて、2つのシナリオでSBERTを評価する。
1) Misraらによって提案されたように、10倍のクロスバリデーションを用いてSBERTを評価する。
この評価セットアップの欠点は、アプローチが異なるトピッ クスにどの程度一般化するかが明らかでないことである。
そこで、2)我々は、クロストピックセットアップでSBERTを評価する。
2つのトピックが訓練に使用され、残されたトピックでアプローチが評価される。
3つのトピックすべてについてこれを繰り返し、結果を平均化する。
SBERT は、回帰目的関数を用いて微調整される。
類似度スコアは、文埋め込みに基づいてcosine類似度を用いて計算される。
また、Misra et al.の結果と比較できるように、ピアソン相関を提供している。
しかし、ピアソン相関にはいくつかの深刻な欠点があり、STSシステムの比較には避けるべきであることを示した(Reimers et al., 2016)。
結果を表3に示します。
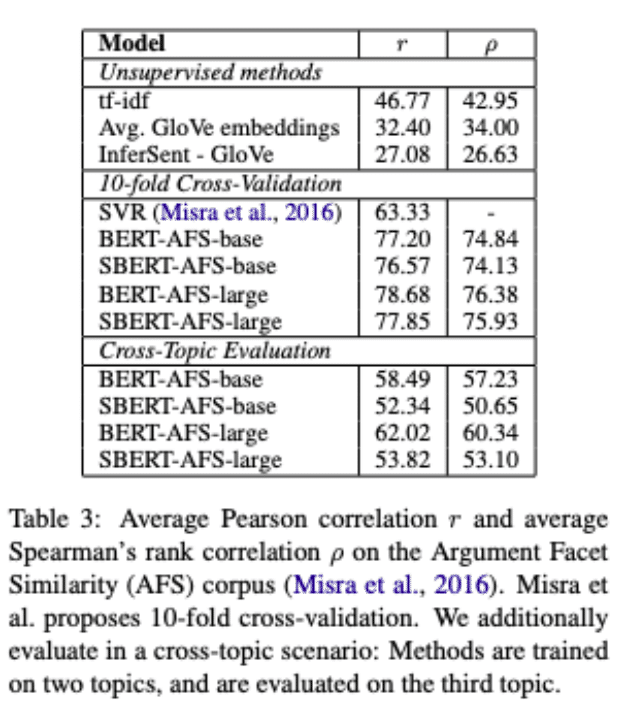
tf-idf, averageGloVe embeddings, InferSentのような教師なしの手法は、このデータセットでは低いスコアでかなり悪い性能を発揮します。
10倍の交差検証セットアップでSBERTを訓練すると、BERTとほぼ同等の性能が得られる。
しかし、クロストピック評価では、SBERTの性能が約7ポイントのスピアマン相関によって低下することがわかった。
類似とみなされるためには、議論は同じ主張に対処し、同じ推論を提供しなければならない。
BERTは、両方の文を直接比較するために注意を使うことができます(例えば、単語ごとの比較)が、SBERTは、類似した主張と理由を持つ引数が近いように、非テーマからベクトル空間に個々の文をマッピングしなければなりません。
これは、BERTと同等に動作するように訓練するためには、2つのトピック以上のものを再要求するように見える、非常に困難な課題である。
4.4 Wikipedia Sections Distinction
Dorら(2018)はWikipediaを利用して、テーマに沿って細かく分類された訓練、dev、テストセットを作成しています。
文の埋め込み方法を説明します。
ウィキペディアの記事は、特定の側面に焦点を当てて別のセクションに分けられている。
Dorらは、同じセクションにある文章は、異なるセクションにある文章よりもテーマ的に近いと仮定しています。
彼らはこれを利用して、弱くラベル付けされたトリプレット文の大規模なデータセットを作成しています。
アンカーとポジティブな例は同じセクションから来ていて、ネガティブな例は同じ記事の別のセクションから来ています。
例えば、Alice Arnoldの記事から:
アンカー: アーノルドは1988年にBBCラジオドラマカンパニーに入社しました。
ポジティブ: アーノルドは2012年5月にメディアの注目を集めた。
ネガティブ: BaldingとArnoldは熱心なアマチュアゴルファーである。
我々は、Dor et al.のデータセットを使用し、Triplet Objectiveを使用し、約180万個のトレーニングで1エポック分のSBERTを訓練し、222,957個のテストでそれを評価する。テストトリプレットは以下のものである。
Wikipediaの記事の明確なセットを使用しています。評価指標としては、正の例が負の例よりもアンカーに近いか?
結果を表4に示す。
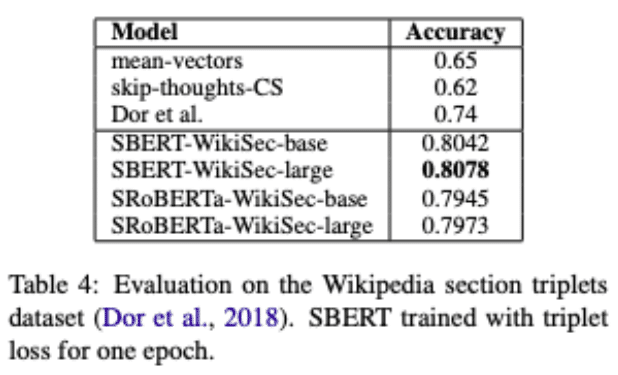
Dorらは、このデータセットのための文の埋め込みを導出するために、トリプレット損失を持つBiLSTMアーキテクチャを微調整した。
表が示すように、SBERTは明らかにDorらによるBiLSTMアプローチよりも優れている。
5 評価-SentEval
SentEval(Conneau and Kiela, 2018)は、文埋め込みの品質を評価するための一般的なツールキットです。文の埋め込みは、ロジスティック回帰分類器の特徴量として使用されます。
ロジスティック回帰分類器は、10倍のクロスバリデーションセットアップで様々なタスクで訓練され、 予測精度はテストフォールドに対して計算されます。
SBERT文埋め込みの目的は、他のタスクへの伝達学習に利用することではない。
ここでは、Devlin et al. (2018)が新しいタスクのために説明したようなBERTの微調整は、BERTネットワークの全層を更新するので、より適切な方法であると考える。
しかし、SentEvalは、様々なタスクのための文埋め込みの品質について参考にすることができる。
以下の7つのSentEval転送タスクについて、SBERT文埋め込みを他の文埋め込み手法と比較する。
・MR: 映画レビューのセンチメント予測スニペットを5つのスタートスケールで(PangとLee.2005).
・CR: 顧客の商品レビューのセンチメント予測(Hu and Liu, 2004).
・SUBJ: 文章の主観予測映画のレビューやプロットの概要から(Pang and Lee, 2004)。
・MPQA. ニュースワイヤーからのフレーズレベルの意見極性分類 (Wiebe et al., 2005)。
・SST: Stanford Sentiment Treebank with binary labels (Socher et al., 2013)
・TREC. TRECからの細かい質問型分類 (Li and Roth, 2002)
・MRPC。並列ニュースソースからのMicrosoft Research Paraphrase Corpus (Dlan et al.2004).
結果は表 5 に示すとおりである。SBERT は、7 つのタスクのうち 5 つのタスクで最高のパフォーマンスを達成することができます。
平均性能は、ユニバーサルセンテンスエンコーダーと同様に、InferSentと比較して約2%ポイント上昇している。
転送学習がSBERTの目的ではないにもかかわらず、このタスクでは、他の最先端の文埋め込み方法よりも優れている。

SBERTからの文の埋め込みは、センチメント情報をよく捉えているように見える。
我々は、SentEvalを用いて、InferSentやUniversal Sentence Encoderと比較し、すべてのセンチメントタスク(MR、CR、SST)において大きな改善が見られることを確認した。
SBERTがUniversal Sentence Encoderよりも有意に悪いデータセットは、TRECデータセットだけである。
Universal Sentence Encoder は、質問応答データに対して事前に訓練されており、これは TREC データセットの質問タイプ分類タスクにとって有益であるように思われます。
平均 BERT 埋め込みまたは BERT ネットワークからの CLStoken 出力の使用は、様々な STS タスクに対して悪い結果を達成し(表 1)、平均 GloVe 埋め込みよりも悪い結果となった。
しかし、SentEval については、平均的な BERT 埋め込みと BERT CLS-token 出力は、まともな結果を達成し(表 5)、平均的な GloVe 埋め込みよりも優れている。
その理由は、設定の違いにあります。
STSタスクでは、文埋め込み間の類似度を推定するために余弦類似度を使用しました。
cosine-similarityは、すべての次元を等しく扱います。
対照的に、SentEvalは、文の埋め込みにロジスティック回帰分類器をフィットさせます。
これにより、特定の寸法が分類結果に与える影響が大きくなったり小さくなったりすることができます。
我々は、平均的な BERT 埋め込み/BERT からの CLS-token 出力は、コサイン相似性や Manhatten/ユークリッド距離で使用することができない文の埋め込みを返すと結論づけている。
転送学習では、これらは、InferSentやUniversal Sentence Encoderよりもわずかに悪い結果をもたらします。しかし、NLIデータセット上でsiameseネットワーク構造を用いて説明した微調整セットアップを使用すると、SentEvalツールキットのための新しい最先端を達成する文埋め込みが得られます。
6 アブレーション研究
SBERT文埋め込みの品質について強い実証結果を示した。
このセクションでは、それらの相対的な重要性をよりよく理解するために、SBERTのさまざまな側面のアブレーション研究を行う。
異なるプーリング戦略(MEAN、MAX、CLS)を評価した。
分類目的関数については、異なる連結方法を評価した。各可能な構成について、10種類のランダム・シードを用いてSBERTを訓練し、性能を平均化する。
目的関数(分類と回帰)は,注釈付きデータセットに依存する。
分類目的関数については、SNLI および Multi-NLI データセット上で SBERTbase を訓練する。
回帰目的関数については、STSベンチマークデータセットの訓練セットで訓練する。
パフォーマンスは、STSベンチマークデータセットの開発スプリットで測定されます。
結果を表6に示す。

NLIデータ上で分類目的関数を用いて学習した場合、プーリング戦略の影響はかなり小さいです。
コンカチネーションモードの影響ははるかに大きくなります。
InferSent (Conneau et al., 2017) と Universal Sentence Encoder (Cer et al., 2018) は、どちらも softmax 分類器の入力として (u, v, |u – v|, u ∗ v) を使用しています。
しかし,我々のアーキテクチャでは,要素ごとの u ∗ v を追加すると性能が低下する。
最も重要な成分は、要素毎の差|u – v|です。連結モードは、ソフトマックス分類器の学習にのみ関連していることに注意してください。
推論では、STSベンチマークデータセットの類似度を予測する際に、余弦類似度と組み合わせて文の埋め込みuとvのみが使用されます。
要素間の差は、2つの文埋め込みの次元間の距離を測定し、類似のペアはより近く、非類似のペアはより遠く離れていることを確認します。
回帰目的関数を用いて学習すると、プーリング戦略が大きな影響を与えることがわかります。そこでは、MAX戦略はMEANやCLS-token戦略よりも有意に悪いパフォーマンスを示します。これは、(Conneau et al., 2017)と対照的である。
InferSentのBiLSTM層がMEANプーリングではなくMAXを使用することが有益であることを発見した人がいました。
7 計算効率
文の埋め込みは数百万文単位で計算する必要があるため、高速な計算が求められています。
このセクションでは、SBERT を平均的な GloVe 埋め込み、InferSent (Conneau et al., 2017)、および Universal Sentence Encoder (Cer et al., 2018) と比較する。
比較のために、STSベンチマーク(Cer et al., 2017)の文を使用します。
我々は、Python辞書ルックアップとNumPyを用いた単純なフォーループを用いて、平均GloVe埋め込みを計算します。
InferSent4はPyTorchをベースにしています。
Universal Sentence Encoderについては、TensorFlowをベースにしたTensorFlow Hub version5を使用しています。S
BERTはPyTorchをベースにしています。文の埋め込みの計算を改善するために、スマートバッチング戦略を実装しました。
長さが似ている文はグループ化され、ミニバッチで最も長い要素にのみパディングされます。
これにより、トークンのパディングに伴う計算オーバーヘッドを大幅に削減しました。
パフォーマンスは、Intel i7-5820K CPU @ 3.30GHz、Nvidia Tesla V100 GPU、CUDA 9.2、cuDNNを搭載したサーバー上で測定しました。
結果は表7に示されています。

CPU上では、InferSentはSBERTよりも約65%高速である。
これは、はるかに単純なネットワークアーキテクチャによるものです。
InferSentは単一のBiLSTM層を使用しているのに対し、BERTは12個の積層されたトランスフォーマー層を使用しています。
しかし、トランスフォーマーネットワークの利点は、GPU上での計算効率です。
そこでは、スマートバッチングを用いたSBERTは、InferSentよりも約9%、Universal Sentence Encoderよりも約55%高速である。
スマートバッチングは、CPUで89%、GPUで48%の高速化を達成しています。
平均的なGloVe埋め込みは、文の埋め込みを計算する最速の方法であることは明らかです。
8 結論
私達は、BERTが、cosine-類似度のような一般的な類似性尺度と併用するにはむしろ適さないベクトル空間にセンテンスをすぐに写像することを示した。
7STS課題の性能は、平均的なGloVe埋め込みの性能を下回っていた。
この欠点を克服するために、我々はSentence-BERT(SBERT)を発表した。 SBERTは、Siamese/トリプレットネットワークアーキテクチャでBERTを改良した。
我々は、様々なコモンモンベンチマークで品質を評価したが、最先端の文埋め込み手法よりも大幅な改善を達成することができた。
BERTをRoBERTaに置き換えても、我々の実験では有意な改善は得られなかった。
SBERT は計算効率が高い。
GPU 上では、InferSent よりも約 9%速く、Universal Sentence Encoder よりも約 55%速い。
SBERT は、BERT でモデル化することが計算的に不可能なタスクに使用できる。
試験のために、階層的クラスタリングを用いた 10,000 文のクラスタリングでは、約 5,000 万個の文の組み合わせを計算しなければならないため、BERT では約 65 時間を必要とする。 SBERTでは、この作業を約5秒に短縮することができた。
Varealでの取り組み
Varealでは、最新論文や技術の実証/導入だけでなくPoC、機械学習を含むシステム構築、運用までサポートすることが可能です。
ご興味をお持ちいただけましたら是非御問い合わせください。
ちなみに、現在はSentence BERTを用いた質疑応答システムの研究開発を中心としてNLP周りに取り組んでおります。
それ以外にも、顔認証システムや表形式データへの機械学習システム構築/運用、データサイエンスの基本である統計のセミナーや経営者の方に向けた機械学習活用セミナーも行っております。
この記事が気に入ったらサポートをしてみませんか?