
データアナリストの姿勢と道具箱

こんにちは、先進情報学研究所の林 尚芳です。弊社では、VALUENEX Analytics Meetupというユーザー会を開催しています。2020年10月に第1回を開催し、私は「データアナリストの姿勢と道具箱」というテーマで発表しました。今回のnoteでは、当時の発表内容を紹介します。
私はデータアナリストとして働いており、クライアントの皆様とデータ解析・調査プロジェクトを実施しています。このような立場から意識している姿勢や、使っている道具を紹介することで、皆様の日々のデータ解析・調査業務を少しでも豊かにできれば幸いです。

VALUENEX AIR - 先進情報学研究所
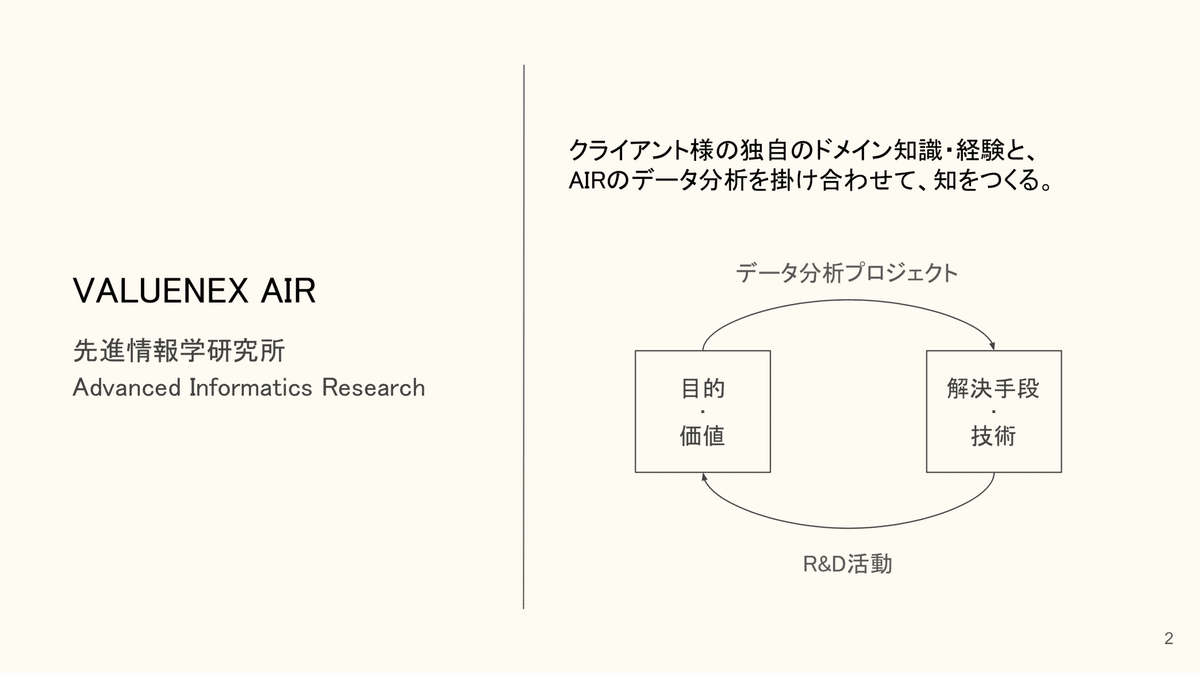
私は「先進情報学研究所(AIR: Advanced Informatics Research)」に所属しています。研究所と銘打っていますが、純粋な研究をやっているのではなく、データ解析・調査プロジェクトといったクライアントワークを担っています。商用サービスであるVALUENEX Radarはさることながら、プロジェクトの目的に応じて様々なデータ解析手法を考案し、実問題で利活用しています。その際、クライアント様の持つドメイン知識・経験からフィードバックをいただきながら、データ解析手法をブラッシュアップさせていき、共に「知」をつくっています。
公開できる具体的な仕事は少ないのですが、例えば、下記のような事例がありますので、興味のある方はご覧いただけると幸いです。
私が意識している3つのデータアナリストの姿勢
データアナリストとして私が意識していることは、下記の3つの点です。本noteでは1つずつ具体例を交えながら紹介します。
1. 問いからスタート
2. ソリューションフリー
3. 「考える」と「つくる」の振り子
1. 問いからスタート


例えば、クライアントに「良い研究者を探索したい」と要望されたらどうしますか?

私はいきなり手を動かすのではなく、まずはこの要望を噛み砕き、問いを見つめ直します。「良い」とは何か?クライアントが探索する目的は何か?その「良い」をデータで評価できるのか?なぜ研究者なのか?アウトプットをどのように情報設計すれば、クライアントは意思決定・アクションすることができるのか?・・・自問自答、クライアントへのヒアリング、先行文献調査等を行いながら、どのようなデータ解析・調査設計にすれば良いかを組み立てます。
2. ソリューションフリー

汎用最適なソリューションはない

当時、機械学習のコミュニティで話題になったQuoraの質問と回答を紹介します。「機械学習に関する論文は全て新しいアルゴリズムが紹介されているんですか?」という質問です。この質問に対して、「アルゴリズム提案で氾濫している。ただし、あらゆる問題を効率良く解けるアルゴリズムはない(ノーフリーランチの定理)。研究者よ、アルゴリズムに傾倒するのではなく、解きたい問題に注視せよ。」といった回答がなされています。
弊社はVALUENEX Radarというテキストマイニング×可視化ツールを提供していますが、目的や問題に応じて、適切に手段を考える必要があると考えています。問題によっては、わざわざテキストマイニングしなくても、単純な集計や相関分析で十分かもしれません。なので、自分の強みとするデータ解析手法はあって良いと思いますが、目的・問題に応じて、本当に適切な手段は何か、一度ソリューションフリーな状態で考えてみるのも良いのではないでしょうか。
適切なデータ・手法・指標を考える

今回の事例である「良い研究者を探す」という要望については、例えば、上記のような整理が考えられます。同じ論文系の指標を使うにしても、研究実績を表す「引用系情報」や、人脈・コンピテンシーを反映している可能性のある「共著系情報(ネットワーク重要性)」等が挙げられます。また、これらの指標は時間的な違いもあり、引用系情報だと発表してから引用されるまでに時間がかかりますが、共著系情報は発表された時点で参照することができます。他にも色んな観点があると思いますが、こういった質の異なる指標を組み合わせることで、多角的に研究者情報を検討することができます。

参考に、ネットワーク重要性のイメージを示します。研究者同士の共著ネットワーク構造から、誰がどういう観点で重要かというものを定量指標化することができます。

例えば、引用系指標をある種の実績、共著系指標(重要性指標トレンド)をある種の成長期待を表す1つの指標だと考えると、この2つを組み合わせることで、研究者のフェーズ感を推定できるかもしれません(上記左図)。実績が高くて成長期待が低下・一定というのは「大御所」、実績が高く成長期待も高いのは「リーダー」。実績だけでは見つかりにくいが、成長期待が高まってきているのは「エマージング」、といった整理が考えられます。
実際に機械学習分野のデータを使って解析したところ、上記右図のようになりました。いわゆるディープラーニングの父である3名は左上(大御所)、GAN(敵対的生成ネットワーク)という有名なアルゴリズムを提唱した方が右上(リーダー)に位置しています。また、実績(被引用数)だけで探索すると、これらの研究者に隠れてしまうが、成長期待も掛け合わせると炙り出されるような研究者が右下(エマージング)に位置しています。
あとは、探索の目的に応じて、大御所から探すのか、エマージングから探すのか等の方針が決まってきます。このように目的に応じて「良い」という意味合いが異なるため、その「良い」をどのように指標化・意味付けできるかを考えながら、データ解析に取り組んでいます。
アウトプットの情報設計を行う

ここまで「良い」とは何か?それはどのようなデータや指標で表現できるのか?を考えてきました。では、ここまで解析したことを、どのようにアウトプットすれば、業務にスムーズに活かせるのでしょうか?アウトプットの情報設計をする上では、ナカミとカタチの2つを意識しています。
ナカミというのは、「業務上、どのような情報が必要なのか?」という観点です。例えば、先ほどのフレークワークで、一定の良い研究者群が見えてきたところで、実際にヒアリングするといったアクションに移すには、何らかのツテがあった方がいいかもしれません。その場合、自社に全く関係のない研究者よりも、例えば、自社の元関係者(自社研究所からアカデミアに移ったアルムナイ等)であったり、今何らかの関係のある機関に所属する研究者を優先的に洗い出すこと等が考えられます。そのためには、各研究者の過去・現在の所属情報をデータに付与しておくと良いでしょう。
一方、カタチというのは、「業務上、どのような形式が適切か?」という観点です。しっかりとした成果発表の場であれば報告書が良いと思いますが、同僚と手分けして探索したり、議論しながら対話的に探索したい場合は研究者個票データや何らかの対話的可視化ツールなどがあった方が良いでしょう。その際、個票であればエクセルで良いと思いますが、もし余力があれば、VBAで探索業務を効率化する機能を作っても良いかもしれません。また、対話的可視化ツールも、既にTableauといった有償BIツールをお使いであれば活用できますし、無償のものでもGoogle Data Portal等も有用だと思います。プログラミングができる方であれば、Pythonで簡単にアプリ化するライブラリも増えてきたので利用してみると良いです。ちなみに私は、Bokehが好きで使っています。その他、Plotly、Streamlit等も触ってみたいです。
3. 「考える」と「つくる」の振り子


最後のパートですが、ここでは普段使っている道具も合わせて紹介していきたいと思います。データ分析に限ったことではないと思いますが、仕事の質を高めるには、「考えること」と「つくること」を振り子のように行き来して行くと思います。そのためには「知識」と「考具」が大事だと考えています。それぞれ下記に紹介していきます。
知識:データのデータ

データのデータを自分なりに更新し続けています。例えば、同じ論文データベースであっても、Scopus、arXiv(厳密にはプレプリント)、PubMedといった様々な種類があります。また、特許、ニュース、企業情報も同様です。そこで、各データベースの特徴(含まれている情報、取得のしやすさ、用途・目的等)を整理しています。ちなみに、このnoteでも、データベースの紹介記事を書いているので、興味ある方はご覧ください。
知識:科学計量学

科学計量学という分野をご存知でしょうか。論文や特許といった情報を活用して、科学技術の動向や、どんな研究者がどう評価されているのかといった「科学を計る」分野です。英語ではScientometricsや、もう少し広い概念ではScience of Scienceと言うキーワードで検索していただければと思います。科学技術動向等を調査する際は、既に科学計量学の研究者が参考になる文献を発表している可能性があるため、事前に調査してみると良いです。データ解析手法が参考になる場合もあれば、興味のあるテーマで既に基礎的な調査内容がある場合もあります。それらをベースに、ご自身の工夫を積み重ねることで、より早くより良いプロジェクトを実施できると思います。
知識:データサイエンス - データビジュアライゼーション

データサイエンスそのものの勉強も大事です。今回はデータビジュアライゼーションについて、簡単に紹介します。上記に書いてあるものは、Visual Information Seeking Mantraという、1996年に提唱された情報探索の基本的作法です。「まずは全体を眺め、重要な局所に注視し、不要な局所は割愛し、そして必要に応じて詳細情報を探索しなさい。」おそらく、普段から調査・データ解析をしている方からすれば、当たり前にように感じるのではないでしょうか。一方で、普段自分が実施していることを、改めて言語化することも少ないのではないでしょうか。こういう言語化を通じて、情報探索設計をスムーズにしたり、仲間と共通認識を持つことも重要だと思います。

参考に、データビジュアライゼーション分野のトップカンファレンスであるIEEE VISの系譜も紹介します。元々は科学可視化(SciVis)から始まり、情報可視化(InfoVis)や可視化分析(Visual Analytics)といったテーマが積み重なり、広がりを見せています。上記の図表は、A Metadata Collection about IEEE Visualization Publications (2017)から引用しています。
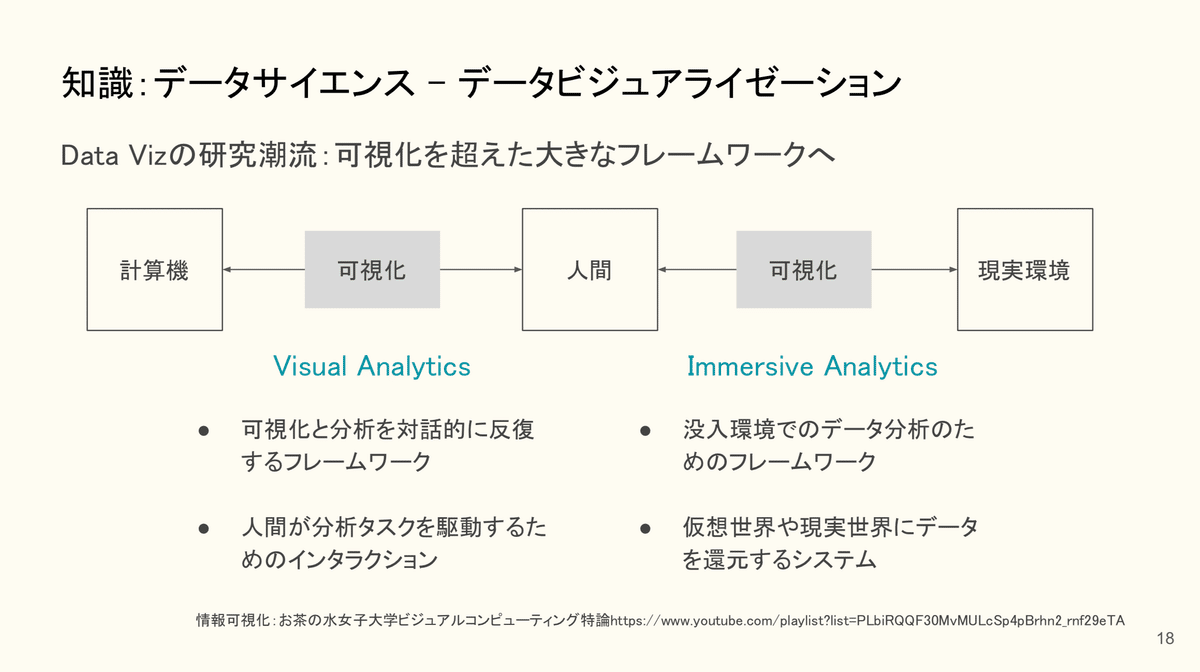
最近ですと、可視化を超えた大きなフレームワーク提案がなされています。例えば、人間と計算機の間に可視化を入れることで対話的分析を実現することもあれば、現実空間に可視化を入れることで没入的分析なども提案されています。
このようにデータビジュアライゼーションという研究領域もどんどん発展しています。アカデミックな最新のナレッジを仕入れ、自身のデータ解析プロジェクトで試してみるのも良いのではないでしょうか。
ちなみに、「お茶の水女子大学ビジュアルコンピューティング特論・情報可視化」という講義動画がYouTubeに公開されているのでオススメです。「意思決定を助ける 情報可視化技術」の著者である伊藤貴之先生の講義です。

ここまで「知識」について紹介いたしました。最後に「考具(考えるための道具)」についてもお話しします。
考具:スケッチして他者からフィードバックを得る
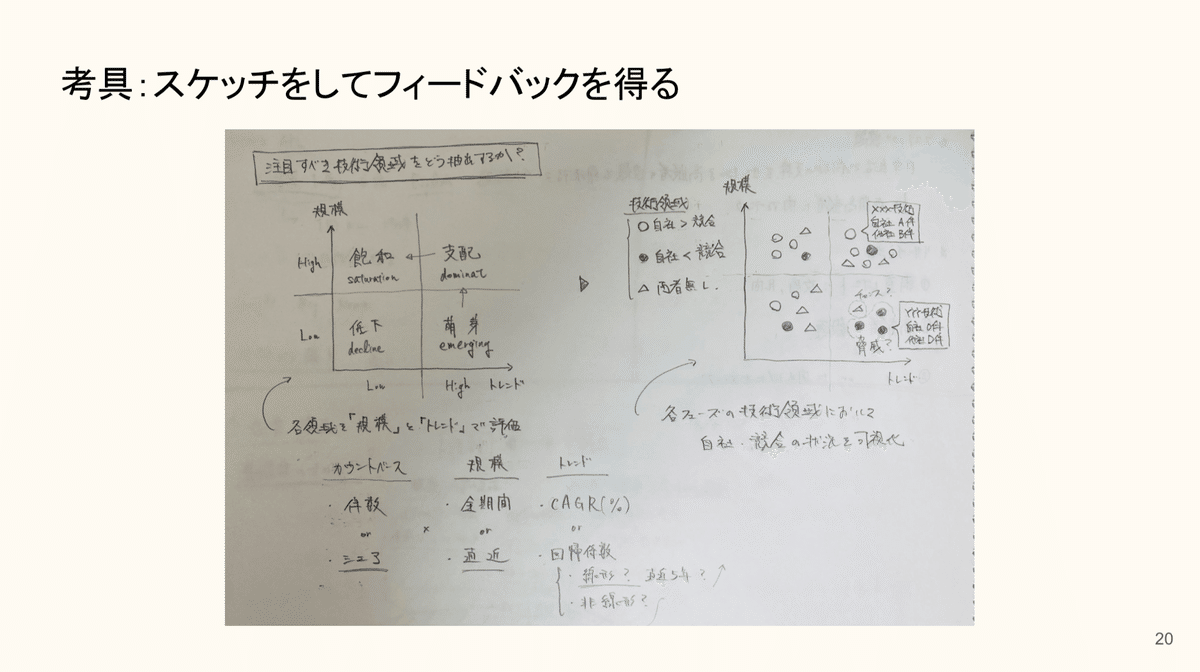
初めてやる分析内容の場合、プログラミングやコンピュータに向かう前に、どんな風にデータ解析すれば良いか、どのようにアウトプットを整理すれば良いだろうか、という点について、紙とペンで検討します。上記のようなラフなスケッチを描いて、他者からフィードバックを得て、データ解析の方針をブラッシュアップしていきます。
考具:エクセル・プログラミング

ある程度方針が決まってきたら、エクセルやプログラミングをします。これらの道具を使う意味は、「考える」と「つくる」の反復回数を増やせるからです。それは「自動化:よくやる工程を自動化・高速化する」と「プロトタイピング:アイディアを形にして良いか悪かを判断する」ができるためです。

上記は、よくあるデータ解析工程において、エクセルやプログラミングの介在価値を整理した例です。弊社のユーザー様ですと、似た工程を実施されており、何らかの方法で型化したいと考えている方がいらっしゃるのではないでしょうか。その際、エクセルやプログラミングを活用いただければと思います。

ちなみに私は、普段はPythonを使うことが多いです。理由は、1. データ解析の幅広いタスクをカバーできる、2. 文法がわかりやすい、3. 対話的なプログラミング環境が充実していることです。

上記はJupyerという対話的プログラミング環境です。打ったコードがその場で結果を見ることができるので、まるでスケッチを描くようにプログラミングできる点がオススメです。またこれを同僚に共有することもできるので、チームで行うプロジェクトでも便利だと思います。
まとめ

データ分析は手法自体が面白いので、ついつい手段の目的化に陥りやすいと思います。そのため、プロジェクト中は、「何のために?」、「もっとシンプルにできないか?」といった自問自答をしながら進めています。(逆に、手段が目的化するからこそ、新たな価値を見出すこともあると思っています。ただし、時間に限りのあるプロジェクトでは、うまく頭を切り替えないといけないです。)
そのような中で、今回のnoteでは、私が意識しているデータアナリストとしての姿勢や、普段使っている道具を紹介しました。何かの折に、皆さんのデータ解析・調査に対する姿勢や道具といった「データ考具」も教えていただけると嬉しいです。
この記事が気に入ったらサポートをしてみませんか?