
科学技術情報データベースを知ろう! - プレプリント・arXiv編

こんにちは、先進情報学研究所の林 尚芳です。前回は「科学技術情報データベースを知ろう! - Microsoft Academic Graph & Lens編」を執筆しました。今回は「プレプリント・arXiv編」をお届けしたいと思います。プレプリントの概要、代表的なプレプリントサーバーであるarXivの検索方法やAPIによるデータ取得方法、arXivだからこそ見つかる面白い研究事例等を紹介します。
プレプリントとは
科学技術情報を調査する際、学術文献を使うことが多いと思います。学術文献には、原著論文、総説論文、レター、会議録、学位論文といった様々な形態があります。特に、査読を通じて雑誌に掲載される原著論文が、研究者の成果として重要なものだと考えられます。一方で、各形態の重要性は分野によって異なる部分もあり、例えば機械学習といった進歩のスピードが早い分野では、国際会議録も難関かつ注目度が高いです。
このように、調査対象分野や目的に応じて、適切に学術文献の形態を選択する必要があります。その際、是非、検討の候補に入れていただきたいのが「プレプリント」という形態です。プレプリントとは、査読前の段階で、オープンアクセスできるプラットフォームに登録・公開される論文原稿です。
図表1に原著論文とプレプリントの学術情報流通の違いを示します。前者では査読によって質をコントロールができますが、その分、出版までに時間を要したり、雑誌アクセスの価格が高騰する等の問題もあります。一方、プレプリントの場合、査読がないため、研究成果がすぐに公開され無償でアクセスできたり、即時公開による先取権獲得といったメリットがあります。ただし、玉石混合かつ大量の研究情報が公開されることになるため、そこから重要な情報を獲得していく力が重要となるでしょう。
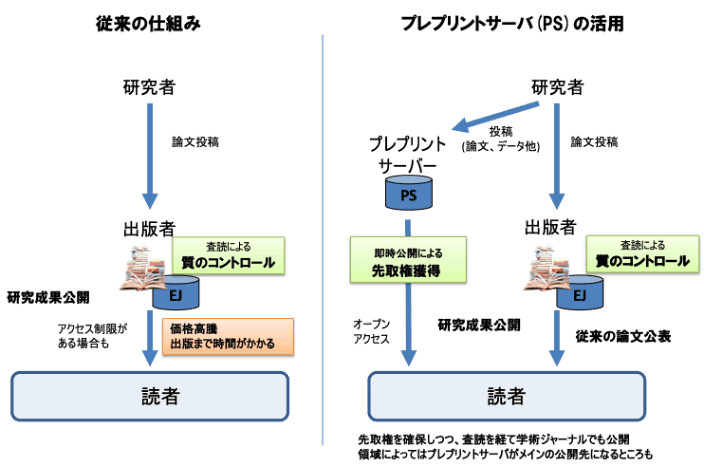
NISTEP:「COVID-19が加速する学術ジャーナルと論文の変容(2020)」より抜粋
また、オープンサイエンスという意味でも重要な役割を担っており、例えば、COVID-19に関する研究では、図表2のように大量のプレプリントが公開され、研究成果の即時共有と研究推進が図られていました。COVID-19に対する研究者たちの努力を感じる結果です。

京都大学:「新型コロナウイルス感染症流行下における未査読論文の公開動向(2020)」より抜粋
arXivとは
プレプリントが投稿・公開されるサーバーのことをプレプリントサーバーと言います。物理・数学・計算機科学分野であれば、コーネル大学が運営しているarXiv(アーカイブ)が有名です。その他にも、bioRXiv(生物学)、ChemRxiv(化学)、medRxiv(医学)、PsyArXiv(心理学)などがあります。また2022年3月からは、JSTが国産プレプリントサーバー「JXiv(ジェイカイブ)」の運用を開始しました。このように、分野や国によって様々なプレプリントサーバーがあるため、一度、自身の興味分野のものがないか検索してみることをお勧めします。
arXiv検索方法
ここでarXivの操作や得られる情報について、簡単に紹介します。図表4は、図表3の「Subject search and browse」から「Computer Science」を選ぶと開かれる画面です(こちらからも飛べます)。ここにキーワードや分野コード等を入力することで検索することができます。また、Advanced Searchを利用することで、詳細な検索を行うことができます。
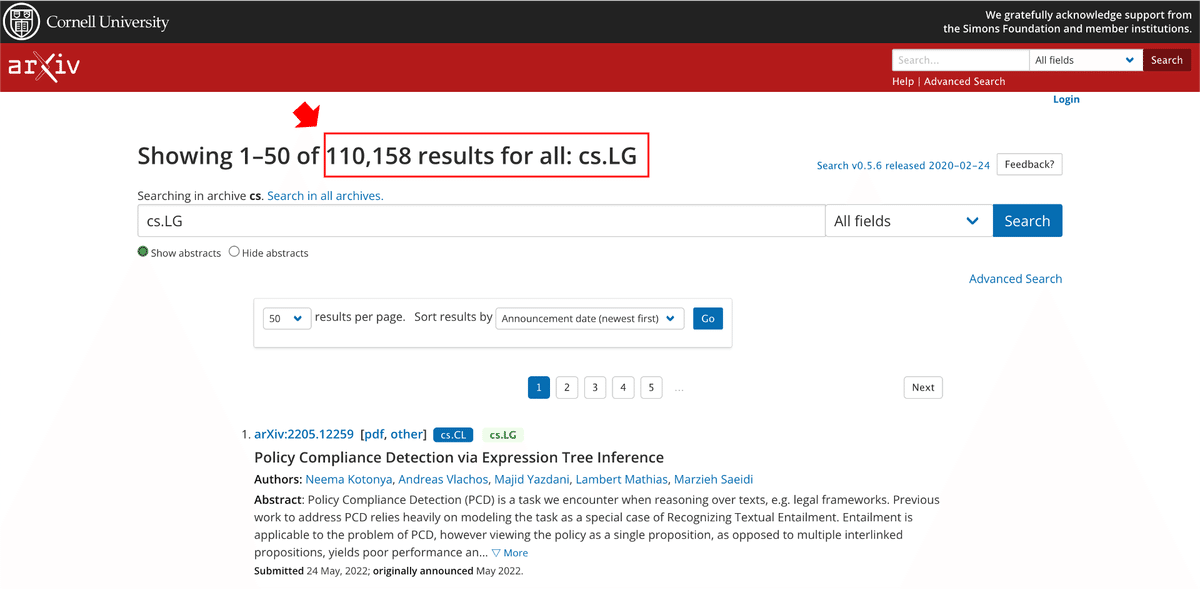
図表5は、「cs.LG」という分野コードで検索した結果です。このコードは「Computer Science - Learning」の略称であり、機械学習分野を意味しています。2022年5月25日現在、110,158件もの文献が蓄積されていることが分かります。その他にも、cs.CV(コンピュータビジョン)、cs.CL(言語処理)、cs.AI(人工知能)、stat.ML(機械学習)といった多くのコードがあります。分野コードは「arXiv Category Taxonomy」に公開されているので参考にしてください。
図表6に実際の文献例を示します。Comment欄には国際会議や雑誌にアクセプトされたという情報が記載されている場合があるのですが、この文献は機械学習の最難関会議の1つであるICML2022にアクセプトされているようです。また閲覧できる情報は、Title、Abstract、Authorはもちろんのこと、PDFをダウンロードして全文を読むことができます。PDFからうまく文書情報を抜き出せれば、Introduction、Methodology、Result、Conclusionとった情報でもテキストマイニングができるかもしれません。分析アイディアが広がりますね。

arXivLabsを使いこなす
図表7に、ここ数年で自然言語処理業界に大きなインパクトを与えたBERTのプレプリントを紹介します。これは2018年にGoogleが発表したアルゴリズムで、様々な自然言語処理・理解タスクで当時最高精度を叩き出したものです。初めて世界に公開したのもこのarXivだと思われます。今もなお、BERTの利活用や派生アルゴリズムの研究が活発に行われています。

画面の下の方に進むと、図表8のようなタブが現れます。これはarXivLabsという機能で、arXivが様々な情報提供方法を実験的に試しているものです。例えば、Bibliographic Toolsタブでは、Semantic Scholarから抽出した当該文献の引用数・被引用数を確認することができます。

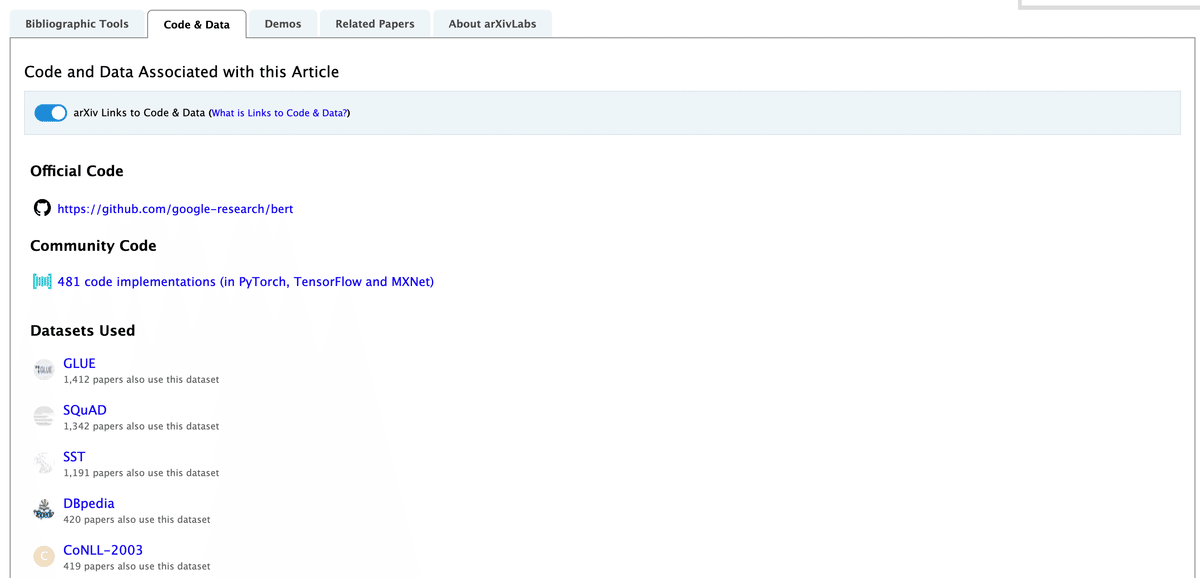
また、Code & Dataタブでは、GitHub等で公開されている関連プログラムのコードやデータを確認することができます。
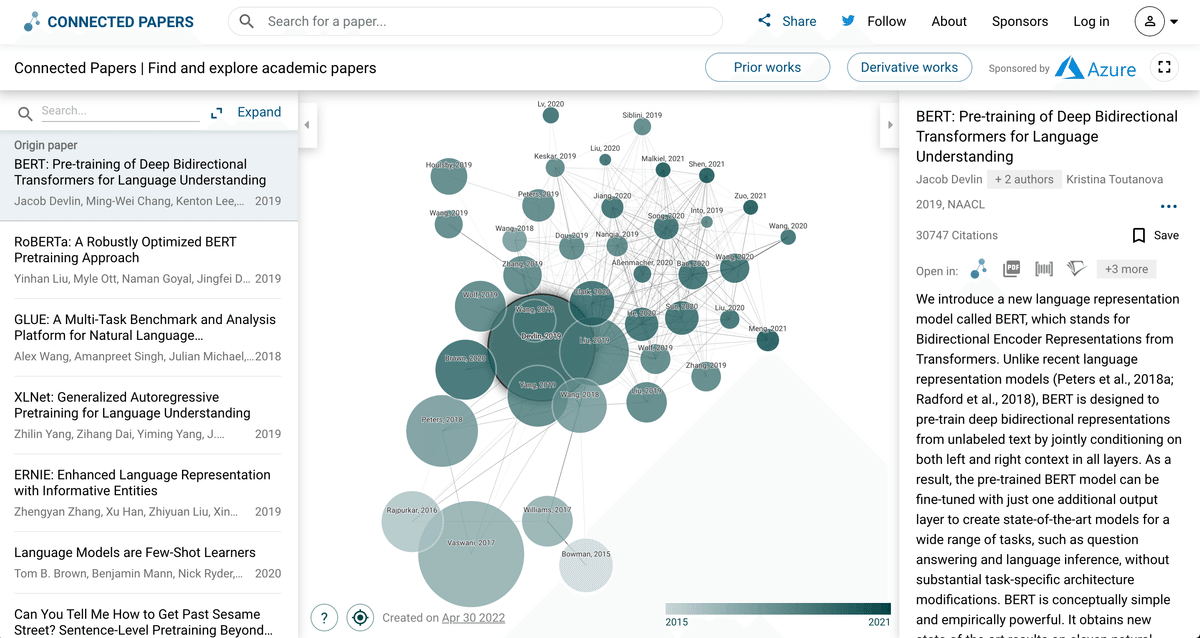
Related Papersタブでは、Connected Papersという機能があります。これは当該文献の引用・被引用関係を元に、文献同士の類似度を計算し、文献間の構造を可視化するものです。これによって、類似文献や周辺の研究動向を簡単に把握することができます(こちらからアクセスできます)。なお、類似度計算は、引用分析でよく使われる「共引用」と「書誌結合」を使っており、ネットワーク可視化には「力学モデル」を採用しています。単純な引用ツリーの可視化ではありません。Connected Papersのアルゴリズムに興味がある方は、こちらに説明があるのでご確認ください。また、共引用や書誌結合の計算方法に興味がある方は、伊神:「文献の関連性の分析:書誌結合,共引用分析,自然言語処理(2020)」が参考になります。
arXivだからこそ見つかる面白い事例
ところで皆さんは、Yoshua Bengio教授をご存知でしょうか?2018年のチューリング賞(計算機科学界のノーベル賞)を、Geoffrey Hinton教授、Yan LuCan教授とともに受賞しており、ディープラーニング革命の父の1人です。
Bengio教授は、2017年に「The Consciousness Prior (事前状態としての意識)」というプレプリントをarXiv上で発表しています。人工知能に意識を組み込み、性能を上げるための概念を記したものです。Daniel Kahnemanのファスト&スローで書かれている、システム1とシステム2の思考の話も踏まえながら提唱されています。詳しくは本文献を読んでいただくか、下記の記事が参考になると思います。どちらも2021年7月の記事ですが、arXivを追っていれば2017年時点でBengio教授が提唱する概念を知ることができます。こういった概念やアイディア等の提唱は、おそらく原著論文や国際会議で採択されることは難しく、arXivならではの情報だと考えられます。玉石混合ではありますが、arXivから突飛な概念・アイディアを見つけるといった使い方も面白いでしょう。
データの取得方法
これまでWebブラウザ上での操作を解説しましたが、データをダウンロードして分析したいというニーズもあると思います。残念ながら、今のところ、Webサイトから検索結果をダウンロードする機能はありません(2022年5月25日現在)。ただし、APIを公開しているため、手元でスクリプトを書いて実行すれば、検索・データ取得をすることが可能です。ちなみに私は、arXiv APIのPythonラッパーを利用しています。下記記事が分かりやすいです。
参考に、私が作成したPythonスクリプトも共有します。事例として「2022年4月にサブミットされたcs.LGカテゴリの文献」を検索していますが、クエリ部分はお好きに変更いただければと思います。処理としては、取得したJSONから、データ分析に利用する情報を抽出し、表形式に加工してtsvファイルで出力しています。tsvファイルには、ID、タイトル、アブスト、分野コード(カテゴリ)、著者名、著者所属組織、公開年、更新年、DOI、arXivのURL、ジャーナルといった情報が含まれています。JSONには他の情報もあるので、必要に応じて修正・追加していただければと思います。(※スクリプトの使用は自己責任でよろしくお願いいたします。)
import arxiv
import pandas as pd
import json
# クエリ
## 例)2022/4/1〜4/30にサブミットされたcs.LGカテゴリの文献
## 1回の読み出しの上限は3万件という仕様(https://arxiv.org/help/api/user-manual#paging)
## 3万件を超える場合は、予め日付などでクエリを複数に分けると良い(1万前後が良いだろう)
l = arxiv.query(query='cat:cs.LG AND submittedDate:[20220401 TO 20220430235959]',
sort_by='submittedDate',
sort_order='ascending',
max_results = 20000,
max_chunk_results = 6000)
# json出力
with open('arxiv_csLG_202204.json', 'w') as f:
json.dump(l, f, indent=2)
# jsonのデータフレーム化
df = pd.io.json.json_normalize(l)
# 複数カテゴリ・著者を区切り文字「|」でジョイン
categories_li = []
authors_li = []
for record in l:
x = []
for ent in record['tags']:
x.append(ent['term'])
categories_li.append('|'.join(x))
authors_li.append('|'.join(record['authors']))
df['authors'] = authors_li
df['categories'] = categories_li
# データクレンジング
df['id'] = [x[-1] for x in df.id.str.split('/')]
df['categories'] = [' '.join(x.replace('\n',' ').replace('"',' ').split()) for x in df['categories']]
df['authors'] = [' '.join(x.replace('\n',' ').replace('"',' ').split()) for x in df['authors']]
df['title'] = [' '.join(x.replace('\n',' ').replace('"',' ').split()) for x in df['title']]
df['abstract'] = [' '.join(x.replace('\n',' ').replace('"',' ').split()) for x in df['summary']]
df['journal_reference'] = [' '.join(str(x).replace('\n',' ').replace('"',' ').split()) for x in df['journal_reference']]
df['affiliation'] = [' '.join(x.replace('\n',' ').replace('"',' ').split()) for x in df['affiliation']]
df['doi'] = [' '.join(str(x).replace('\n',' ').replace('"',' ').split()) for x in df['doi']]
df['published_year'] = [x[0] for x in df['published_parsed']]
df['updated_year'] = [x[0] for x in df['updated_parsed']]
# データフレームの出力
df[['id',
'title',
'abstract',
'categories',
'authors',
'affiliation',
'published_year',
'updated_year',
'doi','arxiv_url',
'journal_reference']].to_csv('arxiv_csLG_202204.tsv', sep='\t', index=False, encoding='utf-8')最後に
今回のnoteでは、プレプリントおよびarXivの特徴や面白さについて紹介しました。弊社VALUENEXでは、プレプリント情報を使った研究開発動向分析プロジェクトも行なっていますので、興味がある方はお声がけください。
また、この「科学技術情報データベースを知ろう!」シリーズですが、私が最も紹介したかったMAG、Lens、arXivの記事を公開することができました。次回の執筆テーマは未定ですが、今後もこのシリーズは続けようと思います。引き続きよろしくお願いいたします。
この記事が気に入ったらサポートをしてみませんか?