ポーカーAI開発 part8 ~DeepCFRを使ってみる~

こんにちは!ナガメ研究所です。人を楽しませるポーカーAIの開発をしています。これまでのセルフプレイ(自己対戦する強化学習)から、現在はGTO戦略と近似するモデルを獲得するCFRアルゴリズムを用いたDeepCFRを試してみています。
CFRとは
Counterfactual Regret Minimizationの頭文字を取っており、GTO戦略を近似的に求めるアルゴリズムです。ポーカーを例にとると、フォールド、チェック、ベットなど、どの行動を取ったほうが良かったと結果から後悔を値として求め、それを最小化するような戦略パラメータを探索するものになります。
DeepCFRとは
CFRアルゴリズムはあるハンドに対してあらゆる状況をすべて網羅的に計算し、相手の行動まですべて探索した上で戦略を求めるため計算に非常に時間がかかります。実際には、ある程度ハンドやボードなどのゲーム状況を抽象化する必要があります。例えば、ハンドは数字そのままを扱うのではなく、♥A♥Kと♥A♥Qは同じグループとして扱ったり、ベットサイズは大・中・小などでまとめてしまうなどの工夫が考えられます。抽象化することでゲームの情報空間はより小さくなるため計算時間を短縮できます。しかし、この抽象化に答えはなく、属人的にやりすぎると真のGTOから離れてしまうことが問題となってきます。
DeepCFRはこの問題を解決しつつ、すべてのハンドのCFRを計算せずともある程度近似できるアルゴリズムとなります。CFRの後悔値の最小化をニューラルネットワークに置き換えるものです。ニューラルネットワークの汎化性能が高いためゲーム状態の抽象化をせずそのまま学習できることが強みとなります。
ただし、DeepCFRの元論文では簡単化されたリミットテキサスホールデムのため、今回は論文といくつか異なる学習設定を適用しました。
実装
GoogleのDeepMindが開発したOpenSpielライブラリを使用し、自作したヘッズアップのノーリミットテキサスホールデム学習環境に適用してみました。以下は開発時点の工夫点です。
ベットサイズの簡略化
先ほどゲームの簡略化が必要ないと説明したばかりですが、筆者の開発環境ではベットサイズを無制限にすることは困難でした。選択できる行動が多いとその先のゲーム展開が膨大になるためです。実際、筆者はポーカーをするうえでベットサイズはポットに対して大・中・小の3パターンくらいしか使っていませんし、最初は完璧な戦略を求めるよりもある程度の戦略を獲得できる実験結果を得られる方が良いと考えました。そこで、ベットサイズはプリフロップがポット1/1, 2/1, 3/1、それ以外のラウンドでは1/3, 1/2, 1/1の3パターンとしました。
ラウンドごとに学習を分割
プリフロップ、フロップ、ターン、リバーでそれぞれモデルの学習を分けました。これは、プリフロップが最も多く、リバーが最も少ないというデータの不均衡を緩和するためです。また、実際に学習してみて「リバーの判断をよく間違えるな」など弱点を見つけた場合、追加の学習を行いやすいなどメリットもあると考えています。
その他学習パラメータ
論文の学習パラメータは個人のマシンではとても動かせないほど膨大なため、バッチサイズは1,000,トラバーサルは1,000としています。(論文では20,000, トラバーサル10,000)。その他のパラメータも環境に合わせて下げています。モデルサイズは論文通りです。
学習
各ラウンド専用モデルを100イテレーション(約1日)かけて学習しました。
実際に対戦してみた
ポーカー歴半年?の筆者と勝負します。1BBが10点の200BB持ちのヘッズアップで、毎ハンドで持ち点をリセットする特殊ルールとします。100ハンド勝負し最終的にどれくらいBBを獲得したかを競いたいと思います。
見づらくて申し訳ありませんが、実際に筆者がAIと対戦したときのコンソール画面のスクリーンショットを貼っておきます。

今回の筆者Aのハンドは♠5,♣6である。
コンソールで数字を選択してアクションを決定する。
0はフォールド、1がコール、2がチェック、3~5が前述のベットサイズに対応する。
AIが45点の追加ベットをしたため、SBの5点と合わせて合計で50点かけられている状態。ここではコールを選択

チェックに対して50点のベットをされる。6がボトムヒットしており、どちらかというとBB有利なボードと考えコール。


強いハンドなのでベットします。AIはコールを選択
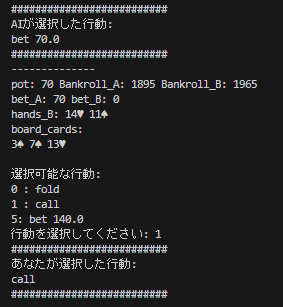

フロップのドンクベットとこちらがJ♠を持っていることからフラッシュ完成は薄いだろうと考え、レイズも検討しましたが、こちらにA、Kを含むハンドが多いのにベットしてきたことを考えてツーペアは依然としてあるのでコールに止めました。

対戦結果
各ハンドの勝敗
筆者:48勝、AI:51勝、引き分け:1
獲得BB
筆者:-77.9BB AI:+77.9BB
負けました。点数にして779点、1ハンド平均0.8BBほど負ける結果となりました。
考察と感想
先ほどの通り、ハンドの勝率も獲得BBもこちらが負けるという結果に終わりました。悔しいけど嬉しいような複雑な気持ちです。
感想ですが、アクションの多くがポラライズされている印象でした。ポラライズとは、手札が極端に強いか極端に弱いケースが存在するということです。大きいベットサイズや頻繁なレイズでポットが大きくなる傾向にあったと思います。
ドローがあるようなボードでもプレッシャーを多く与えてきます。逆にフラッシュが完成されているようなボードではこちらのブラフが通りやすかった印象です。
AIはフロップ以降のアクションが単調に見えました。特にこちらのベットに必ずと言っていいほどレイズが来るので、ハンドが良いときだけベット→レイズ→リレイズで大きく稼ぎ、それ以外は無理せずチェックで回し、多めにフォールドする戦略を取りました。このAIは過去のハンドの履歴は考慮していないので、同じ行動を取っていてもエクスプロイトされない点は人間よりも楽です。もっと対戦回数を重ねれば、他にも弱点が見えてくるかもしれません。
敗因の大きい部分は強いハンドで脳死でオールインしてしまったことです。なぜならAIはプリフロップのハンドレンジが広く、ベットやレイズはブラフだろうとたかをくくってしまいました。前述の通りアグレッシブなのでこちらがストレートやフルハウスができているときに毎回オールインまで持っていき、フラッシュやフォーカードなどより強い役を持たれていたのが大きくBBを獲得された原因です。普段ならハンドが強くても降りるべき場面ですが、相手のブラフ頻度の高さから降りられなかったです。。。
まとめ
筆者のポーカーレベルではブラフかバリューかの見分けがつかないほどバランスが取れているように見えました。論文よりも状態数の多いゲームをより少ないパラメータとデータ数で学習しているためGTOには程遠いかもしれませんが、それでも面白いAIができたと思います。
次回の記事では、対戦したAIとのログを取って分析する予定ですので見てみたいという方がいらっしゃればスキかフォローお願いします!励みになります!
後日談
他のGTOツールを調べていたところポーカースノーウィーというサービスがおそらくDeepCFRなどの技術を用いているのではないかと思います(少なくともニューラルネットワーク技術は使用している)。先程紹介したベットサイズの抽象化など、奇しくも一致していましたが偶然です。しかし、このアプローチはある程度良いものであると確信できて安心しました。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?