
adaboostのはなし

adaboostは、高い予測精度を持つ教師あり学習のmeta-algorithmとして、これまでの高い評価を得てきました。このnoteでは、adaboostの仕組みと性質について、その概要を説明します。
1. Kearns-Valiant問題
1988年、KearnsとValiantは次のような問題を提案しました:「2値分類問題がもし弱学習可能であれば、それは強学習可能か?」誤解を恐れず平たい言葉で言うと、誤分類率が必ずしも十分良いとは限らず50%より少し小さい程度の学習器を作るアルゴリズムがあるならば、それから誤分類率が十分に低くなるような学習器を作るメタアルゴリズムを提案できるかという問題でした。
* 弱学習器:誤分類率が少なくとも50%よりは低い学習器
* 強学習器:誤分類率が十分に低いような学習器
1990年、Schapireはこの問題を肯定的に解決し、このようなメタアルゴリズムとしてboostingを提案しました。
=== boostingメタアルゴリズム(一般的な場合) ===
hyperparameters :
* 標本の重みつき分布D
* 弱学習器の学習アルゴリズムL
* 繰り返しの最大数T
process :
1. D[1] <- D
2. for t in 1,...,T
3. h[t] = L(D[t])
4. e[t] = 標本点の重みD[t]のもとでのh[t]の誤分類率
5. D[t+1] = D[t]をe[t]に基づいて修正する。
6. end
output : H(x) = h[1](x),...,h[T](x)によって与えられる関数
======
この後、Shapireによるrecursive majority gate formulationやFreundによるboost by majorityが具体的なboosting meta-algorithmとして提案されましたが、これらは弱学習器の誤分類率の上限を事前に見積もっておく必要があり、理論的には良い性質を備えていても、用いるには困難な手法であるという問題を抱えていました。
1995年、FreundとShapireはこの問題を解決するadaboostを提案し、初めて実用に耐えうるboosting meta-algorithmとして評価されました。実際、adaboostは"adaptive boosting"の略で"adaptive"は未知パラメータの設定が必要ないことを意味しています。二人はこの功績を讃えられ2003年にゲーテル賞を受賞しました。
2. adaboostのmeta-algorithm概要
adaboostのmeta-algorithmは次の通りです。なお一般的に、標本の重み付き分布の初期値には一様分布、弱学習器には決定木分類器が用いられます。ここで、x[i]は標本点iの入力、y[i]は標本点iの出力ラベル(+1/-1)とし、弱学習器h[t](x[i])もまた+1か-1の値を返すものとします。
=== adaboostメタアルゴリズム ===
hyperparameters :
* 標本の重み付き分布D
* 弱学習器の学習アルゴリズムL
* 繰り返しの最大数T
process :
1. D[1] <- D
2. for t in 1,...T
3. h[t] = L(D[t])
4. e[t] = 標本点の重みD[t]のもとでのh[t]の誤分類率
5. if e[t] > 0.5 then break
6. a[t] = (1/2)*log((1-e[t])/e[t])
7. D[t+1](i) ∝ D[t](i)*exp(-a[t]y[i]h[t](x[i]))
8. end
output : H(x) = sign(a[1]h[1](x)+...+a[T]h[T](x))
======
基本的には、outputの式の形からadaboostは弱学習器の重み付き多数決によって予測を決める強学習器を作る仕組みだということが見て取れます。また、弱学習器の信頼度a[t]という記号が現れますが、これは
* 弱学習器の重み
* 標本の重み付き分布の更新の仕方を決めるパラメータ
です。
なおadaboostの特徴は、信頼度a[t]を決定する式と信頼度a[t]を用いた重み付き分布の更新式にあると言っても過言ではありません。要するに6行目と7行目がadaboost meta-algorithmの特徴です。(実際、他はboostingの一般論なので、確認してみてください。)
3. 信頼度の定義と信頼度による重み付き分布の更新の仕組み
3.1 信頼度の定義 : adaboostでは繰り返しステップtで学習された弱学習器の信頼度をa[t] = (1/2)*log((1-e[t])/e[t])で定義します。グラフで書くと以下の通りです。

このグラフから誤分類率が0に近いほど急激に高い信頼度を与えることが分かります。
3.2 信頼度による重み付き分布の更新の仕組み : 重み付き分布の更新式を理解するとき、予測が正しいときと間違っているときで式を場合分けして書いてみると助けになるでしょう。予測が正しいときy[i]h[t](x[i]) = 1, y[i]h[t](x[i]) = -1になることに注意すると、
* 予測が正しいとき : D[t+1](i) ∝ D[t](i)exp(-a[t])
* 予測が間違っているとき : D[t+1](i) ∝ D[t](i)exp(a[t])
となり、予測が正しい標本点はその弱学習器の信頼度に応じて小さい重みに、予測が間違っている標本点はその弱学習器の信頼度に応じて大きい重みに更新されることが分かります。
要するに、adaboostでは前の弱学習器がある標本点を誤分類したとき、次の弱学習器ではより重視して学習されます。また、特に前の弱学習器の精度が高いほど、その弱学習器が誤分類した標本点は次の弱学習器ではかなり重要視される傾向にあります。
4. adaboost meta-algorithmの性質
4.1 外れ値に対する敏感性 : 標本の重み付き分布の更新は、弱学習器の信頼度が「指数的に」重みの更新に働くことを主張しています。これは例えば外れ値が標本に含まれていた場合、精度の高い弱学習器でもその外れ値を誤分類することで次の弱学習器はその外れ値を重要視して学習することを意味しています。このようにadaboostは外れ値に対して敏感なmeta-algorithmです。これについては、2000年にDomingoとWatanabeによって提案されたMadaboostなどの改良が知られています。
4.2 adaboost meta-algorithmの汎化性能 : adaboost meta-algorithmの繰り返しの最大回数は大きくし過ぎると直感的には過剰適合してしまうのではないか思われますが、実は過剰適合することは比較的稀であることが経験上知られています。例えば、1998年のShapireの報告によれば、以下のように訓練誤差がほぼ0に至った後もテスト誤差は減少し続けていることが見て取れます。[画像 : R. Shapire, Explaining Adaboost, 1998より]
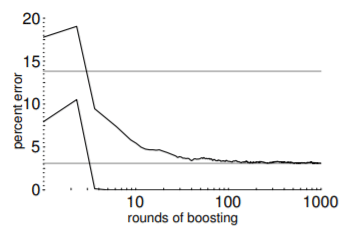
この現象の理論的説明にはrandomforestとadaboostの理論的類似性やmarginによるadaboostの解釈などいくつかの視点から説明が試みられていますが、納得のいく説明が与えられるには至っていないようです。
謝辞
このnoteは、ピースオブケイク社で開かれている統計勉強会の講義資料です。講義の機会を与えてくださった勉強会参加者の皆様に感謝申し上げます。
サポートをいただいた場合、新たに記事を書く際に勉強する書籍や筆記用具などを買うお金に使おうと思いますm(_ _)m