
自分がよく使う言葉でワードパレットを作りたい! RMeCabで頻出語を探そう

私は二次創作小説書きです。
最近、「合作することで、他人と自分の文体を混在させられないか?」と考えています。その方法は思案中ですが、案の一つとして、「自作によく出てくる語をワードパレットにし、他人にそのワードパレットで書いてもらうと、文体キメラに近づけるかも」というものがあります。
今回、Rを使って自作によく出てくる語を抽出し、自作頻出ワードパレットを作りました。いつかまた同じことをしたくなった未来の私のために、作業メモを残しておきます。Rの初心者向け記事ではありませんで、ご容赦ください。
なお、完成したワードパレットはこちら。

一息に言うと
RMeCabの関数RMeCabFreqを用いて、テキスト内の語の出現回数を数える。
用意するもの
R
Rstudio
RMeCab
分析に使用したいテキスト(.txtファイル)
なお、私はWindowsユーザーです。Macなどの場合は作業手順が異なるようなので、ご注意ください。
【余談】KH coderは使わないのか?
「テキストマイニングならKH coderでは?」と思われた方もいらっしゃるかもしれません。私もそう思いました。私がRを使ったのは、最近Rでデータを扱う機会があったので、テキスト分析も面白がってやってみた次第です。
KH coderは使ったことがありません。インターネットの解説記事をざっと見た限り、とても簡単そうです。Rをインストールするよりわかりやすいかと思います。自分の小説のテキストマイニングをやってみたい方は、ぜひKH coderのご利用をご検討ください。
こちらは、KH coderを使った楽しそうな記事。ヨルシカの歌詞の頻出語を調べていらっしゃいます。やはり「夏」が強いんですね。
手順
さっそく、頻出語を調べていきましょう。
まず、参考にしたサイトを置いておきます。これで手が動く人はどうぞ。
参考にしたサイト
R によるテキスト分析入門 https://www.jstage.jst.go.jp/article/jkg/70/4/70_181/_pdf
形態素の頻度分析 http://www.ic.daito.ac.jp/~mizutani/mining/rmecabfreq.html
1) 分析用のテキストを作る
csvファイルでも分析できるようですが、今回はtxtを使います。
メモ帳を起動します(※.txtならなんでもいいです)。
ひとつのメモ帳に、全部のテキストを入れましょう。読み込ませたいテキストを、とにかくコピペしていきます。
テキストファイルは、Rファイルと同じフォルダに保存すると、あとで楽です。
2) RとRstudioをインストールする
各自調べられたし。この記事などわかりやすいです。
3) RMeCabをインストールする
私はWindowsユーザーなので、バイナリの方をインストールします。

文字コードはUTF-8! SHIFT-JISでインストールしたら、取り込んだテキストが文字化けし、再インストールする羽目になったので注意。
4) Rのコードを書く
このように書きました。余計な記載も残ってますが、自分用ということで……。
#package install
install.packages("tidyverse")
install.packages("RMeCab", repos = "http://rmecab.jp/R")
library(tidyverse)
library(RMeCab)
#RMeCabのテスト
res <- RMeCabC("すもももももももものうち")
unlist (res)
#今いるディレクトリの確認
getwd()
#読み込んだテキストファイルに入っている語について、活用形を原形に変換した上で、その頻度を数えて、結果をデータフレームとして返す
fret <- RMeCabFreq("textt.txt") #今いるディレクトリの直下に置くと便利
View(fret)
#欲しい品詞、かつ、30回以上登場しているものだけを取り出す
#名詞、動詞、形容詞、形容動詞、副詞
fret2 <- fret[(
(fret$Info1 == "名詞" & fret$Info2 == "一般") |
(fret$Info1 == "動詞" & fret$Info2 == "自立") |
(fret$Info1 == "形容詞" & fret$Info2 == "自立") |
(fret$Info1 == "名詞" & fret$Info2 == "形容動詞語幹") |
(fret$Info1 == "副詞")
)
& fret$Freq > 30,
]
#品詞が日本語で入っているとソートに使えないため、数字に置き換えた列を作成
#1:名詞、2:動詞、3:形容詞、4:形容動詞、5:副詞(その他はあれば9)
fret2 <- fret2 %>%
mutate (type = case_when(
fret2$Info1 == "名詞" & fret2$Info2 == "一般" ~ 1,
fret2$Info1 == "動詞" ~ 2,
fret2$Info1 == "形容詞" ~ 3,
fret2$Info1 == "名詞" & fret2$Info2 == "形容動詞語幹" ~ 4,
fret2$Info1 == "副詞" ~ 5,
TRUE ~ 9
))
#品詞別に並べ、さらにその中で頻度が高い順にする
fret2 <- fret2 %>%
arrange(type, -Freq)
#出来上がった表の確認
view(fret2)5) 出力された表から、好きな語を抜き出す
先ほどのコードを実行すると、このような表ができます。
サボって5種類の品詞を同じ表に入れてしまったので、typeでフィルターをかけて品詞別に表示させてチェックしました。

6) ワードパレットにする
Rが抽出してくれた語から、特徴的なものや自分が好きなものを選んで、エクセルにコピペしました。

ワードパレットとしては、
スタンダードな3語1セット
10語1セット
の2種類を作りました。10語版を作ったのは、「10語も使って一本書いてもらえば、文体キメラになりやすいのでは?」という思いです。
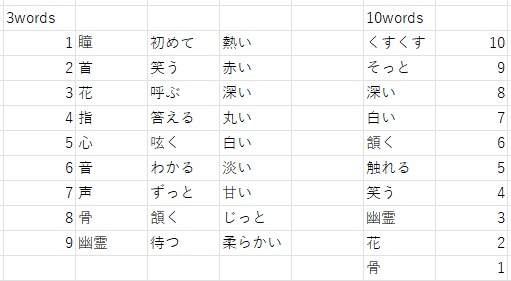
あとはCanvaでいい感じに成形します。これでワードパレットが完成です!

感想
「私の煮凝り」みたいなワードパレットができました! これを使って私が作文をしたら、煮詰まった遺伝情報がエラーを吐いて壊れそうです。
作業の手間の話。
解析用のテキストファイルを作るコピペ作業から、RMeCabのインストール・コード書き、語をリストアップして組み合わせるところまで、およそ2時間で終わりました。案外、簡単です。
目的はワードパレットを作ること。共起ネットワークを描画するでなし、結果を論文にするでもなし。最後には自分の目で好きな語をピックアップするので、Rで出力するものは、適当な塩梅で構わないのです。
実は2ファイル使っていた話。
私は複数ジャンルで作文をしているので、2ジャンルの創作物について、別々に頻出語チェックをしてみました。すると、当然というべきか、出てくる語が違って面白かったです。
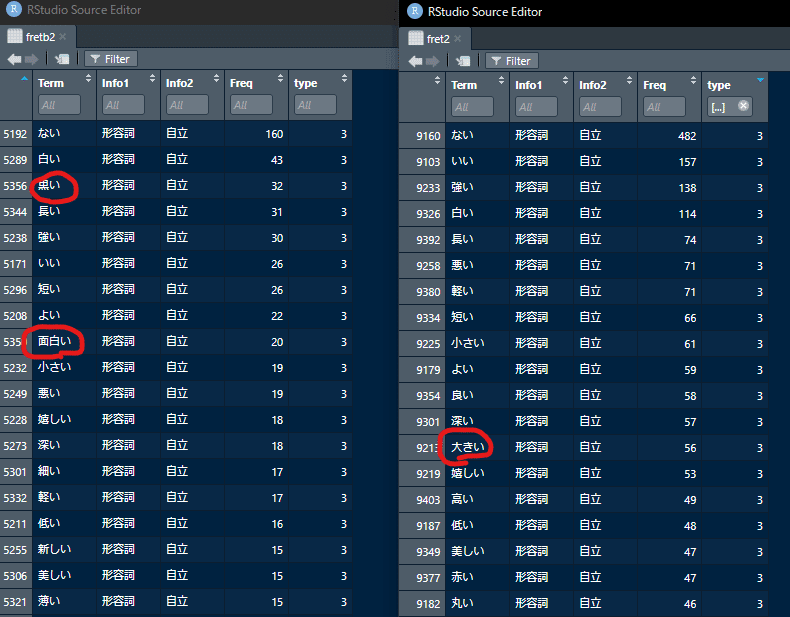
ただし、形容動詞はいずれも「静か」と「穏やか」が頻出でした。癖ですね。
今度機会があれば、KH coderを使ってもみたいです。それでは。
ごきげんオタクライフに使わせていただきます🌱