
仮想通貨の価格予測因子を考えてみた

初めに
2023年12月末より、Aidemy Premium「データ分析講座」を受講しました。このブログは、本講義の一環で、受講修了条件を満たすために公開しています。
本ブログでは、仮想通貨であるビットコイン、及びリップルにおける過去の価格推移と仮想通貨に関する記事を参照し、今後の価格予測の参考となる情報を探索することを目的に分析してみました。
分析に用いる環境・自己経験
分析環境
Python3
MacBook Pro(M1)
Safari
Google Colaboratory
自己経験
Pythonについては初学者です。
普段は、SASを用いた集計解析のお仕事していますが、Pythonを使った機械学習、及びその関連技能を用いたデータ分析は素人です。
分析に至る経緯
家族が海外で働く話が出たため、何かあった場合に送金手数料が少ない手段で送金できないか?と考えたことがきっかけで、仮想通貨に興味を持ちました。
そこで、仮想通貨に関する情報を収集すると、特定の発行管理者がいないこと、悪用防止のための暗号化技術を使用していること、海外への送金コストが少ないことがわかり、ビットコイン、リップルといった仮想通貨の利用を考えました。
https://go.sbisec.co.jp/prd/ifa/column/money_20200128_01.html
利用するには、法定通貨から仮想通貨への両替が必要になるため、両替レートを注視する必要があります。
しかし、仮想通貨はレートの変動が大きく、両替のタイミングが読みづらく、参考となる情報も少ないです。
そこで、過去の価格変動や海外経済ニュース(記事情報)も交え、ある程度将来性の予測の一因にできないかと考えたことが、今回のデータ分析に至る経緯です。
※ビットコインは価格が相当高いので、手数料は相対的に高くなっています…
分析手順
01.下準備(データ収集と環境整備)
2023年3月21日~2024年3月21日の日本円換算レートに基づくビットコイン、及びリップルの価格推移ファイルを下記サイトよりダウンロードしました。
価格取得日に応じた記事情報を入手する為、下記サイトに利用登録しました。
Google Driveへの接続とMeCabを使えるように各種設定を行います。
#01.Google Driveへ接続
from google.colab import drive
drive.mount('/content/drive')
#02.MeCabを使えるように準備する
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.702.前処理
ビットコインの日本円価格推移情報を活用できるように形成します。
#パッケージ読み込み
import pandas as pd
#ビットコインの推移情報取込み
btcjpy = pd.read_csv('/content/drive/MyDrive/Aidemy/MyTask/dat/BTCJPY Historical Data20230321_20240321.csv')
#日付文字列を日付値に変換の上 、YYYYmmdd形式表示へ変更する
btcjpy['date_change'] = pd.to_datetime(btcjpy['Date'], format='%m/%d/%Y')
#必要な項目を出力する
btcjpy = btcjpy.drop(['Open', 'High', 'Low', 'Vol.', 'Change %'], axis = 1)
btcjpy['Price'] = btcjpy['Price'].str.replace(',', '').astype(float)リップルの日本円価格推移情報を活用できるように形成します。
#パッケージ読み込み
import pandas as pd
#リップルの推移情報取込み
xrpjpy = pd.read_csv('/content/drive/MyDrive/Aidemy/MyTask/dat/XRPJPY Historical Data20230321_20240321.csv')
#日付文字列を日付値に変換の上 、YYYYmmdd形式表示へ変更する
xrpjpy['date_change'] = pd.to_datetime(xrpjpy['Date'], format='%m/%d/%Y')
#必要な項目を出力する
xrpjpy = xrpjpy.drop(['Open', 'High', 'Low', 'Vol.', 'Change %'], axis = 1)
xrpjpy['Price'] = xrpjpy['Price'].astype(float)海外のビットコイン、リップルに関する記事情報を取り込み、形成します。
取り込む前に、「News API」の利用登録を行い、「API-Key」を入手します。
記事をプログラムで取得するには、「API-Key」を指定する必要があるためです。
形成にあたっては、実行日から過去30日の記事しか取り込めないとのことなので、実行日である2024年3月21日(23時頃)を起点に記事を取り込みました。
#Request処理 import requests
headers = {'X-Api-Key': '(ご自身で登録したAPI-Keyを入力してください)'}
#01-1.ビットコインに関する記事を取得
url = 'https://newsapi.org/v2/everything'
params = {
'q': '( BTC OR ビットコイン ) AND ( 暗号 OR 仮想 )',
'sortBy': 'publishedAt',
'pageSize': 100
}
response = requests.get(url, headers=headers, params=params)
print(response)
#01-2.取得データをデータフレームに変換する
import pandas as pd
pd.options.display.max_colwidth = 25
if response.ok:
data = response.json()
df_btc = pd.DataFrame(data['articles'])
print('totalResults:', data['totalResults'])
print(df_btc[[ 'publishedAt', 'title', 'url']])
#02-1.リップルに関する記事を取得
url = 'https://newsapi.org/v2/everything'
params = {
'q': '( XRP OR リップル ) AND ( 暗号 OR 仮想 )',
'sortBy': 'publishedAt',
'pageSize': 100
}
response = requests.get(url, headers=headers, params=params)
print(response)
#02-2.取得データをデータフレームに変換する
import pandas as pd
pd.options.display.max_colwidth = 25
if response.ok:
data = response.json()
df_xrp = pd.DataFrame(data['articles'])
print('totalResults:', data['totalResults'])
print(df_xrp[[ 'publishedAt', 'title', 'url']])
#03-1.2データフレームを結合の上、日付情報をYYYY/MM/DD形式に変更
article_all = pd.concat([df_btc, df_xrp], ignore_index=True)
article_all['atdate_extract'] = article_all['publishedAt'].str.split(pat='T', expand=True)[0]
article_all['date_change'] = pd.to_datetime(article_all['atdate_extract'])
#04-1.データフレームをCSVで一度出力する
article_all.to_csv("/content/drive/MyDrive/Aidemy/MyTask/dat/article_all.csv")※04-1:取得期間固定のため、CSVファイルにする処理をしています。以下、固定後データの加工プログラムです。
#データ前処理 その3_20240322以降はこちらを活用
#News APIより取得・csv化した海外のビットコイン、リップルの記事ヘッドライン情報を取り込む
#パッケージ読み込み
import pandas as pd
#ビットコインの推移情報取込み
article_all = pd.read_csv("/content/drive/MyDrive/Aidemy/MyTask/dat/article_all.csv")
article_all['date_change'] = pd.to_datetime(article_all['atdate_extract'])取り込んだ記事情報データに感情分析を実施し、日時別PN平均値を格納します。
ここで、同日複数記事があった場合、その日に発行された記事に対するPN値の平均値を日時別PN値とします。感情分析については、以下をご参照ください。
感情分析に用いる感情値辞書は、高村大也氏(東京工業大学)作成の「単語感情極性値対応表」を用いました。
#article_allデータフレームからPN値を出力する
#パッケージ読み込み import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import MeCab
import re
pd.set_option('display.unicode.east_asian_width', True)
#01-1.感情値辞書の読み込み
pndic = pd.read_csv("http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic",\
sep=':',
encoding='shift-jis',
names=('Word','Reading','POS', 'PN')
)
print(pndic)
#01-2.word_listにリスト型でWordを格納
word_list = list(pndic['Word'])
#01-3.pn_listにリスト型でPNを格納
pn_list = list(pndic['PN'])
#01-4.pn_dictとしてword_list, pn_listを格納した辞書を作成
pn_dict = dict(zip(word_list, pn_list))
m = MeCab.Tagger('')
def add_pnvalue(diclist_old, pn_dict):
diclist_new = []
for word in diclist_old:
base = word['BaseForm'] # 個々の辞書から基本形を取得
if base in pn_dict:
pn = float(pn_dict[base])
else:
pn = 'notfound' # その語がPN Tableになかった場合
word['PN'] = pn
diclist_new.append(word)
return diclist_new
#02-1.各記事のPN平均値を求める
def get_mean(dictlist_new):
pn_list = []
for word in dictlist_new:
pn = word['PN']
if pn!='notfound':
pn_list.append(pn)
if len(pn_list)>0:
pnmean = np.mean(pn_list)
else:
pnmean=0
return pnmean
def get_diclist(text):
parsed = m.parse(text)
lines = parsed.split('\n')
lines = lines[0:-2]
diclist = []
for word in lines:
l = re.split('\t|,',word) # 各行はタブとカンマで区切られてる
d = {'BaseForm':l[7]}
diclist.append(d)
return diclist
#02-2.辞書型配列を作成して出力
dict = {'date_change': article_all['date_change'], 'article': article_all['description']}
df_corpus = pd.DataFrame(dict)
#02-3.日付列を時系列順に並び替える
df_corpus = df_corpus.sort_values(['date_change'])
#02-3.日付列をインデックスに設定
df_corpus = df_corpus.set_index(['date_change'])
#02-4.空のリストを作り、記事ごとの平均値を算出
means_list = []
for text in df_corpus['article']:
dl_old = get_diclist(text)
dl_new = add_pnvalue(dl_old, pn_dict)
pnmean = get_mean(dl_new)
means_list.append(pnmean)
df_corpus['pn'] = means_list
#02-5.日付ごとのPN平均値を算出する
df_corpus_mean = df_corpus.groupby('date_change').mean(numeric_only=True)
#02-6.日付をx軸, PN平均値をy軸にしてプロットし、傾向を確認
x = df_corpus_mean.index
y = df_corpus_mean.pn
plt.plot(x,y)
plt.grid(True)
plt.xticks(rotation=45)
plt.show()ここでPN値を確認すると、負の値が多いため傾向がつかみにくい状況です。
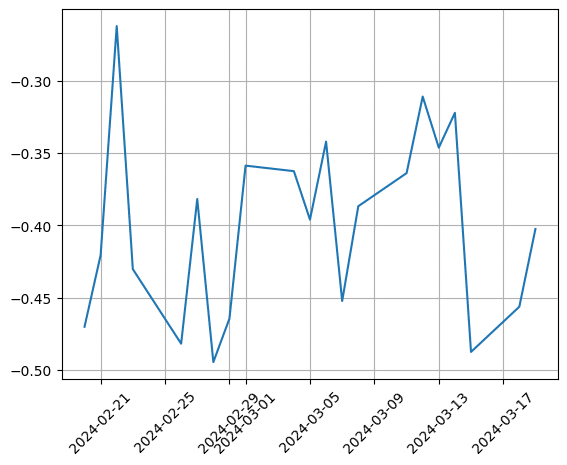
そこで、PN値に標準化を行いました。
#03-1.PN平均値を標準化する
#means_listをnumpy配列に変換 means_list = np.copy(means_list)
# means_listを用いて標準化を行う。
x_std = (means_list - means_list.mean()) / means_list.std()
for i in range(len(df_corpus.index)):
df_corpus['pn'].values[i] = x_std[i]
#03-2.日付ごとのPN標準化平均値を算出する
df_corpus_stmean = df_corpus.groupby('date_change').mean(numeric_only=True)
#03-3.日付をx軸、PN標準化平均値をy軸にしてプロットし、傾向を確認
x = df_corpus_stmean.index
y = df_corpus_stmean.pn
plt.plot(x,y)
plt.xticks(rotation=45)
plt.grid(True)PN値を標準化(データを平均0、分散1の正規分布で合わせること)することで、特徴量の評価を行う際、外れ値や他の特徴量の影響範囲を受けないようにします。
標準化するとこのようになりました。
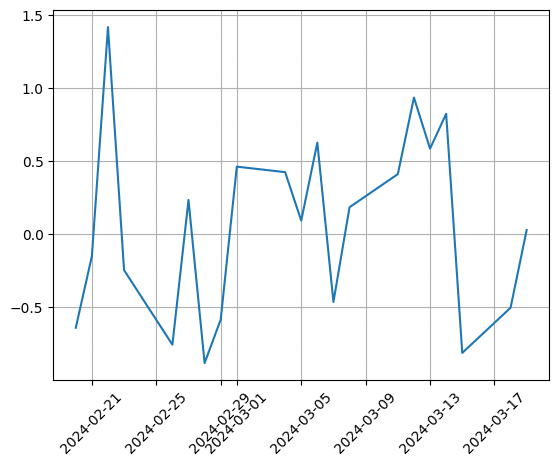
※各数値は、訓練用・テストデータに分割後、改めて標準化します。
最後に、取り込んだ各仮想通貨の情報と記事情報を日付で連結し、これを学習データとテストデータに分割するための元データとします。
元データについては、以下のパターンを用意します。
ビットコインレート:120日間(btcjpy_120)
リップルレート:120日間(xrpjpy_120)
ビットコインレート:30日間(btcjpy_30)
リップルレート:30日間(xrpjpy_30)
ビットコインレート×記事感情情報:30日間(btcjpy_30_PN)
リップルレート×記事感情情報:30日間(xrpjpy_30_PN)
※()内は、データフレーム名
#パッケージ読み込み import pandas as pd
from sklearn.model_selection import train_test_split
#01-1.btcjpyより変化量データを算出
btcjpy['Price_diff_1'] = btcjpy['Price'].diff()
btcjpy['Price_diff_3'] = btcjpy['Price'].diff(3)
#01-2.btcjpyより120日、30日データを出力
btcjpy_120 = btcjpy[:120]
btcjpy_30 = btcjpy[:30]
#01-3.感情分析データフレームとビットコインの価格推移データフレームを日付でマージ
btcjpy_30_PN = pd.merge(btcjpy_30, df_corpus_mean, how='left', on='date_change')
btcjpy_30_PN = btcjpy_30_PN.fillna(0)
#02-1.xrpjpyより変化量データを算出
xrpjpy['Price_diff_1'] = xrpjpy['Price'].diff()
xrpjpy['Price_diff_3'] = xrpjpy['Price'].diff(3)
#02-2.xrpjpyより120日、30日データを出力
xrpjpy_120 = xrpjpy[:120]
xrpjpy_30 = xrpjpy[:30]
#02-3.感情分析データフレームとリップルの価格推移データフレームを日付でマージ
xrpjpy_30_PN = pd.merge(xrpjpy_30, df_corpus_mean, how='left', on='date_change')
xrpjpy_30_PN = xrpjpy_30_PN.fillna(0)分析に際し、価格予測に用いる説明変数として用意する価格差分を示す日数をそれぞれ、1日、及び3日としました。また、PN値がNaNの日は、0とします。
03.訓練用データとテストデータ分割
訓練用データとテストデータに分割し、応答変数と説明変数の標準化を行います。
応答変数:ビットコイン・リップルの価格(標準化後)
説明変数:過去1日の価格変化(以降、1日変化とする。標準化後)、3日の価格変化(以降、3日変化とする。標準化後)、及びPN値(標準化後)
まずはビットコインからです。
どのような説明変数・応答変数として用いたのか明示的に示しています。
#02.各データを訓練用データ、テストデータに分割する
#分割条件は、test_size = 0.2, random_state = 42
#02-1.ビットコインの価格推移120
btcjpy_120_train, btcjpy_120_test = train_test_split(btcjpy_120, test_size=0.2, random_state=42, shuffle=False)
#訓練用データフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
btcjpy_120_train = btcjpy_120_train.dropna()
btcjpy_120_train['Price_stval'] = (btcjpy_120_train['Price'] - btcjpy_120_train['Price'].mean()) / btcjpy_120_train['Price'].std()
btcjpy_120_train['Price_stdiff_1'] = (btcjpy_120_train['Price_diff_1'] - btcjpy_120_train['Price_diff_1'].mean()) / btcjpy_120_train['Price_diff_1'].std()
btcjpy_120_train['Price_stdiff_3'] = (btcjpy_120_train['Price_diff_3'] - btcjpy_120_train['Price_diff_3'].mean()) / btcjpy_120_train['Price_diff_1'].std()
#訓練用データフレーム形成 btcjpy_120_train = btcjpy_120_train.set_index(['date_change'])
btcjpy_120_train = btcjpy_120_train.drop(['Date'], axis = 1)
#テストデータフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
btcjpy_120_test = btcjpy_120_test.dropna()
btcjpy_120_test['Price_stval'] = (btcjpy_120_test['Price'] - btcjpy_120_test['Price'].mean()) / btcjpy_120_test['Price'].std()
btcjpy_120_test['Price_stdiff_1'] = (btcjpy_120_test['Price_diff_1'] - btcjpy_120_test['Price_diff_1'].mean()) / btcjpy_120_test['Price_diff_1'].std()
btcjpy_120_test['Price_stdiff_3'] = (btcjpy_120_test['Price_diff_3'] - btcjpy_120_test['Price_diff_3'].mean()) / btcjpy_120_test['Price_diff_1'].std()
#テストデータフレーム形成 btcjpy_120_test = btcjpy_120_test.set_index(['date_change'])
btcjpy_120_test = btcjpy_120_test.drop(['Date'], axis = 1)
#02-2.ビットコインの価格推移30
btcjpy_30_train, btcjpy_30_test = train_test_split(btcjpy_30, test_size=0.2, random_state=42, shuffle=False)
#訓練用データフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
btcjpy_30_train = btcjpy_30_train.dropna()
btcjpy_30_train['Price_stval'] = (btcjpy_30_train['Price'] - btcjpy_30_train['Price'].mean()) / btcjpy_30_train['Price'].std()
btcjpy_30_train['Price_stdiff_1'] = (btcjpy_30_train['Price_diff_1'] - btcjpy_30_train['Price_diff_1'].mean()) / btcjpy_30_train['Price_diff_1'].std()
btcjpy_30_train['Price_stdiff_3'] = (btcjpy_30_train['Price_diff_3'] - btcjpy_30_train['Price_diff_3'].mean()) / btcjpy_30_train['Price_diff_1'].std()
#訓練用データフレーム形成 btcjpy_30_train = btcjpy_30_train.set_index(['date_change'])
btcjpy_30_train = btcjpy_30_train.drop(['Date'], axis = 1)
#テストデータフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
btcjpy_30_test = btcjpy_30_test.dropna()
btcjpy_30_test['Price_stval'] = (btcjpy_30_test['Price'] - btcjpy_30_test['Price'].mean()) / btcjpy_30_test['Price'].std()
btcjpy_30_test['Price_stdiff_1'] = (btcjpy_30_test['Price_diff_1'] - btcjpy_30_test['Price_diff_1'].mean()) / btcjpy_30_test['Price_diff_1'].std()
btcjpy_30_test['Price_stdiff_3'] = (btcjpy_30_test['Price_diff_3'] - btcjpy_30_test['Price_diff_3'].mean()) / btcjpy_30_test['Price_diff_1'].std()
#テストデータフレーム形成 btcjpy_30_test = btcjpy_30_test.set_index(['date_change'])
btcjpy_30_test = btcjpy_30_test.drop(['Date'], axis = 1)
#02-3.ビットコインの価格推移30×感情分析データ
btcjpy_30_PN_train, btcjpy_30_PN_test = train_test_split(btcjpy_30_PN, test_size=0.2, random_state=42, shuffle=False)
#訓練用データフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
btcjpy_30_PN_train = btcjpy_30_PN_train.dropna()
btcjpy_30_PN_train['Price_stval'] = (btcjpy_30_PN_train['Price'] - btcjpy_30_PN_train['Price'].mean()) / btcjpy_30_PN_train['Price'].std()
btcjpy_30_PN_train['Price_stdiff_1'] = (btcjpy_30_PN_train['Price_diff_1'] - btcjpy_30_PN_train['Price_diff_1'].mean()) / btcjpy_30_PN_train['Price_diff_1'].std()
btcjpy_30_PN_train['Price_stdiff_3'] = (btcjpy_30_PN_train['Price_diff_3'] - btcjpy_30_PN_train['Price_diff_3'].mean()) / btcjpy_30_PN_train['Price_diff_1'].std()
btcjpy_30_PN_train['pn_stval'] = (btcjpy_30_PN_train['pn'] - btcjpy_30_PN_train['pn'].mean()) / btcjpy_30_PN_train['pn'].std()
#訓練用データフレーム形成 btcjpy_30_PN_train = btcjpy_30_PN_train.set_index(['date_change'])
btcjpy_30_PN_train = btcjpy_30_PN_train.drop(['Date'], axis = 1)
#テストデータフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
btcjpy_30_PN_test = btcjpy_30_PN_test.dropna()
btcjpy_30_PN_test['Price_stval'] = (btcjpy_30_PN_test['Price'] - btcjpy_30_PN_test['Price'].mean()) / btcjpy_30_PN_test['Price'].std()
btcjpy_30_PN_test['Price_stdiff_1'] = (btcjpy_30_PN_test['Price_diff_1'] - btcjpy_30_PN_test['Price_diff_1'].mean()) / btcjpy_30_PN_test['Price_diff_1'].std()
btcjpy_30_PN_test['Price_stdiff_3'] = (btcjpy_30_PN_test['Price_diff_3'] - btcjpy_30_PN_test['Price_diff_3'].mean()) / btcjpy_30_PN_test['Price_diff_1'].std()
btcjpy_30_PN_test['pn_stval'] = (btcjpy_30_PN_test['pn'] - btcjpy_30_PN_test['pn'].mean()) / btcjpy_30_PN_test['pn'].std()
#テストデータフレーム形成 btcjpy_30_PN_test = btcjpy_30_PN_test.set_index(['date_change'])
btcjpy_30_PN_test = btcjpy_30_PN_test.drop(['Date'], axis = 1)次はリップルです。
#02.各データを訓練用データ、テストデータに分割する
#分割条件は、test_size = 0.2, random_state = 42
#02-1.リップルの価格推移120
xrpjpy_120_train, xrpjpy_120_test = train_test_split(xrpjpy_120, test_size=0.2, random_state=42, shuffle=False)
#訓練用データフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
xrpjpy_120_train = xrpjpy_120_train.dropna()
xrpjpy_120_train['Price_stval'] = (xrpjpy_120_train['Price'] - xrpjpy_120_train['Price'].mean()) / xrpjpy_120_train['Price'].std()
xrpjpy_120_train['Price_stdiff_1'] = (xrpjpy_120_train['Price_diff_1'] - xrpjpy_120_train['Price_diff_1'].mean()) / xrpjpy_120_train['Price_diff_1'].std()
xrpjpy_120_train['Price_stdiff_3'] = (xrpjpy_120_train['Price_diff_3'] - xrpjpy_120_train['Price_diff_3'].mean()) / xrpjpy_120_train['Price_diff_1'].std()
#訓練用データフレーム形成 xrpjpy_120_train = xrpjpy_120_train.set_index(['date_change'])
xrpjpy_120_train = xrpjpy_120_train.drop(['Date'], axis = 1)
#テストデータフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
xrpjpy_120_test = xrpjpy_120_test.dropna()
xrpjpy_120_test['Price_stval'] = (xrpjpy_120_test['Price'] - xrpjpy_120_test['Price'].mean()) / xrpjpy_120_test['Price'].std()
xrpjpy_120_test['Price_stdiff_1'] = (xrpjpy_120_test['Price_diff_1'] - xrpjpy_120_test['Price_diff_1'].mean()) / xrpjpy_120_test['Price_diff_1'].std()
xrpjpy_120_test['Price_stdiff_3'] = (xrpjpy_120_test['Price_diff_3'] - xrpjpy_120_test['Price_diff_3'].mean()) / xrpjpy_120_test['Price_diff_1'].std()
#テスト用データフレーム形成 xrpjpy_120_test = xrpjpy_120_test.set_index(['date_change'])
xrpjpy_120_test = xrpjpy_120_test.drop(['Date'], axis = 1)
#02-2.リップルの価格推移30
xrpjpy_30_train, xrpjpy_30_test = train_test_split(xrpjpy_30, test_size=0.2, random_state=42, shuffle=False)
#訓練用データフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
xrpjpy_30_train = xrpjpy_30_train.dropna()
xrpjpy_30_train['Price_stval'] = (xrpjpy_30_train['Price'] - xrpjpy_30_train['Price'].mean()) / xrpjpy_30_train['Price'].std()
xrpjpy_30_train['Price_stdiff_1'] = (xrpjpy_30_train['Price_diff_1'] - xrpjpy_30_train['Price_diff_1'].mean()) / xrpjpy_30_train['Price_diff_1'].std()
xrpjpy_30_train['Price_stdiff_3'] = (xrpjpy_30_train['Price_diff_3'] - xrpjpy_30_train['Price_diff_3'].mean()) / xrpjpy_30_train['Price_diff_1'].std()
#訓練用データフレーム形成 xrpjpy_30_train = xrpjpy_30_train.set_index(['date_change'])
xrpjpy_30_train = xrpjpy_30_train.drop(['Date'], axis = 1)
#テストデータフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
xrpjpy_30_test = xrpjpy_30_test.dropna()
xrpjpy_30_test['Price_stval'] = (xrpjpy_30_test['Price'] - xrpjpy_30_test['Price'].mean()) / xrpjpy_30_test['Price'].std()
xrpjpy_30_test['Price_stdiff_1'] = (xrpjpy_30_test['Price_diff_1'] - xrpjpy_30_test['Price_diff_1'].mean()) / xrpjpy_30_test['Price_diff_1'].std()
xrpjpy_30_test['Price_stdiff_3'] = (xrpjpy_30_test['Price_diff_3'] - xrpjpy_30_test['Price_diff_3'].mean()) / xrpjpy_30_test['Price_diff_1'].std()
#テスト用データフレーム形成 xrpjpy_30_test = xrpjpy_30_test.set_index(['date_change'])
xrpjpy_30_test = xrpjpy_30_test.drop(['Date'], axis = 1)
#02-3.リップルの価格推移30×感情分析データ
xrpjpy_30_PN_train, xrpjpy_30_PN_test = train_test_split(xrpjpy_30_PN, test_size=0.2, random_state=42, shuffle=False)
#訓練用データフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
xrpjpy_30_PN_train = xrpjpy_30_PN_train.dropna()
xrpjpy_30_PN_train['Price_stval'] = (xrpjpy_30_PN_train['Price'] - xrpjpy_30_PN_train['Price'].mean()) / xrpjpy_30_PN_train['Price'].std()
xrpjpy_30_PN_train['Price_stdiff_1'] = (xrpjpy_30_PN_train['Price_diff_1'] - xrpjpy_30_PN_train['Price_diff_1'].mean()) / xrpjpy_30_PN_train['Price_diff_1'].std()
xrpjpy_30_PN_train['Price_stdiff_3'] = (xrpjpy_30_PN_train['Price_diff_3'] - xrpjpy_30_PN_train['Price_diff_3'].mean()) / xrpjpy_30_PN_train['Price_diff_1'].std()
xrpjpy_30_PN_train['pn_stval'] = (xrpjpy_30_PN_train['pn'] - xrpjpy_30_PN_train['pn'].mean()) / xrpjpy_30_PN_train['pn'].std()
#訓練用データフレーム形成 xrpjpy_30_PN_train = xrpjpy_30_PN_train.set_index(['date_change'])
xrpjpy_30_PN_train = xrpjpy_30_PN_train.drop(['Date'], axis = 1)
#テストデータフレーム #NaNが含まれるレコードは削除する(変化量が同定できないため)
xrpjpy_30_PN_test = xrpjpy_30_PN_test.dropna()
xrpjpy_30_PN_test['Price_stval'] = (xrpjpy_30_PN_test['Price'] - xrpjpy_30_PN_test['Price'].mean()) / xrpjpy_30_PN_test['Price'].std()
xrpjpy_30_PN_test['Price_stdiff_1'] = (xrpjpy_30_PN_test['Price_diff_1'] - xrpjpy_30_PN_test['Price_diff_1'].mean()) / xrpjpy_30_PN_test['Price_diff_1'].std()
xrpjpy_30_PN_test['Price_stdiff_3'] = (xrpjpy_30_PN_test['Price_diff_3'] - xrpjpy_30_PN_test['Price_diff_3'].mean()) / xrpjpy_30_PN_test['Price_diff_1'].std()
xrpjpy_30_PN_test['pn_stval'] = (xrpjpy_30_PN_test['pn'] - xrpjpy_30_PN_test['pn'].mean()) / xrpjpy_30_PN_test['pn'].std()
#テストデータフレーム形成 xrpjpy_30_PN_test = xrpjpy_30_PN_test.set_index(['date_change'])
xrpjpy_30_PN_test = xrpjpy_30_PN_test.drop(['Date'], axis = 1)これで訓練用データとテストデータの分割ができました。
04.予測モデルの構築
予測モデルを構築し、予測精度を計測します。
記事情報を付与していない120日、及び30日のデータを使い、予測モデルの手法を検討します。ここでの流れは以下の通りです。
各価格推移情報(120日、及び30日)のデータに3つの予測モデルを設定し、決定係数を導出する
訓練用データとテストデータ間の決定係数を導出する
上記2つの決定係数を比較し、差分の大きさや1に近いかなど、確認する
3の結果から採用する予測モデルを用い、PN値を付与した各価格推移情報(30日)のデータに適用してみる
04-1.ビットコインの予測
応答変数は、ビットコイン価格(標準化後)、説明変数は、過去1日、及び3日の価格変化(標準化後)としています。
「ビットコイン120日情報」
#パッケージ読み込み from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
#01-1.BTC120のモデル構築
#線形回帰 print('ビットコイン120日情報')
print('線形回帰の予測モデル適合情報')
model = LinearRegression()
model.fit(btcjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_train[['Price_stval']])))
pred = model.predict(btcjpy_120_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(btcjpy_120_test[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_test[['Price_stval']])))
print()
#ラッソ回帰 print('ラッソ回帰の予測モデル適合情報')
model = Lasso()
model.fit(btcjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_train[['Price_stval']])))
pred = model.predict(btcjpy_120_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(btcjpy_120_test[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_test[['Price_stval']])))
print()
#リッジ回帰 print('リッジ回帰の予測モデル適合情報')
model = Ridge()
model.fit(btcjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_train[['Price_stval']])))
pred = model.predict(btcjpy_120_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(btcjpy_120_test[['Price_stdiff_1','Price_stdiff_3']], btcjpy_120_test[['Price_stval']])))
print()ビットコイン価格推移120日データより以下の数値が算出されました。
ビットコイン120日情報
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.0039094936564343374
テストデータの決定係数:-0.01328540359083652
ラッソ回帰の予測モデル適合情報
訓練用データの決定係数:0.0
テストデータの決定係数:0.0
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.0039083123139597165
テストデータの決定係数:-0.012843743593155654
「ビットコイン30日情報」
#01-2.BTC30のモデル構築
#線形回帰 print('ビットコイン30日情報')
print('線形回帰の予測モデル適合情報')
model = LinearRegression()
model.fit(btcjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_train[['Price_stval']])))
pred = model.predict(btcjpy_30_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(btcjpy_30_test[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_test[['Price_stval']])))
print()
#ラッソ回帰 print('ラッソ回帰の予測モデル適合情報')
model = Lasso()
model.fit(btcjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_train[['Price_stval']])))
pred = model.predict(btcjpy_30_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(btcjpy_30_test[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_test[['Price_stval']])))
print()
#リッジ回帰 print('リッジ回帰の予測モデル適合情報')
model = Ridge()
model.fit(btcjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_train[['Price_stval']])))
pred = model.predict(btcjpy_30_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(btcjpy_30_test[['Price_stdiff_1','Price_stdiff_3']], btcjpy_30_test[['Price_stval']])))
print()ビットコイン価格推移30日データより以下の数値が算出されました。
ビットコイン30日情報
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.48172024620766773
テストデータの決定係数:-3.3312283487949994
ラッソ回帰の予測モデル適合情報
訓練用データの決定係数:0.0
テストデータの決定係数:-2.220446049250313e-16
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.48132829849199266
テストデータの決定係数:-3.165079569114101
ビットコイン120日、及び30日情報、いずれの訓練用データもラッソ回帰の決定係数は0となりました。
一方、予測モデル間(線形回帰、リッジ回帰)において訓練用データ、テストデータともに決定係数の値に差はありませんでした。
以上より、PN値を付与した30日のデータにおける予測モデルには、線形回帰、及びリッジ回帰を用います。
(テストデータの決定係数が負の値が得られている点は、後ほど考察します)
最後に、PN値を付与した30日のデータを使い、PN値を加えた際の訓練用データとテストデータの決定係数に大きな違いがないかをみてみます。
ビットコインでは、線形回帰、リッジ回帰で比較してみようと思います。
「ビットコイン30日情報 with PN値」
#01-3.BTC30×PNのモデル構築
#線形回帰 print('ビットコイン30日 with PN情報')
print('線形回帰の予測モデル適合情報')
model = LinearRegression()
model.fit(btcjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], btcjpy_30_PN_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], btcjpy_30_PN_train[['Price_stval']])))
pred = model.predict(btcjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']])
print('テストデータの決定係数:' + str(model.score(btcjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']], btcjpy_30_PN_test[['Price_stval']])))
print()
#リッジ回帰 print('リッジ回帰の予測モデル適合情報')
model = Ridge()
model.fit(btcjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], btcjpy_30_PN_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(btcjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], btcjpy_30_PN_train[['Price_stval']])))
pred = model.predict(btcjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']])
print('テストデータの決定係数:' + str(model.score(btcjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']], btcjpy_30_PN_test[['Price_stval']])))
print()ビットコイン価格推移30日 with PN値データより以下の数値が算出されました。
ビットコイン30日 with PN情報
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.5557048769802055
テストデータの決定係数:-3.8015409144791183
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.554991544365978
テストデータの決定係数:-3.614829924259663
PN情報を付与したビットコイン30日情報では、訓練用データの決定係数は0.5を超えてきましたが、テストデータの決定係数は、ビットコイン30日情報で算出した決定係数よりも低下しました。
04-2.リップルの予測
応答変数は、リップル価格(標準化後)、説明変数は、過去1日、及び3日の価格変化(標準化後)としています。
「リップル120日情報」
#01-1.XRP120のモデル構築
#線形回帰 print('リップル120日情報')
print('線形回帰の予測モデル適合情報')
model = LinearRegression()
model.fit(xrpjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_train[['Price_stval']])))
pred = model.predict(xrpjpy_120_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_120_test[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_test[['Price_stval']])))
print()
#ラッソ回帰 print('ラッソ回帰の予測モデル適合情報')
model = Lasso()
model.fit(xrpjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_train[['Price_stval']])))
pred = model.predict(xrpjpy_120_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_120_test[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_test[['Price_stval']])))
print()
#リッジ回帰 print('リッジ回帰の予測モデル適合情報')
model = Ridge()
model.fit(xrpjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_120_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_train[['Price_stval']])))
pred = model.predict(xrpjpy_120_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_120_test[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_120_test[['Price_stval']])))
print()リップル価格推移120日データより以下の数値が算出されました。
リップル120日情報
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.08759706170003223
テストデータの決定係数:0.2144124213034042
ラッソ回帰の予測モデル適合情報
訓練用データの決定係数:0.0
テストデータの決定係数:0.0
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.08759542320269076
テストデータの決定係数:0.21397776535705793
「リップル30日情報」
#01-2.XRP30のモデル構築
#線形回帰 print('リップル30日情報')
print('線形回帰の予測モデル適合情報')
model = LinearRegression()
model.fit(xrpjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_train[['Price_stval']])))
pred = model.predict(xrpjpy_30_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_30_test[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_test[['Price_stval']])))
print()
#ラッソ回帰 print('ラッソ回帰の予測モデル適合情報')
model = Lasso()
model.fit(xrpjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_train[['Price_stval']])))
pred = model.predict(xrpjpy_30_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_30_test[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_test[['Price_stval']])))
print()
#リッジ回帰 print('リッジ回帰の予測モデル適合情報')
model = Ridge()
model.fit(xrpjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_30_train[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_train[['Price_stval']])))
pred = model.predict(xrpjpy_30_test[['Price_stdiff_1','Price_stdiff_3']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_30_test[['Price_stdiff_1','Price_stdiff_3']], xrpjpy_30_test[['Price_stval']])))
print()リップル価格推移30日データより以下の数値が算出されました。
リップル30日情報
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.5972897165632913
テストデータの決定係数:-0.5299791480627374
ラッソ回帰の予測モデル適合情報
訓練用データの決定係数:0.03126037125933401
テストデータの決定係数:-0.0011806274028769437
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.5969977225369093
テストデータの決定係数:-0.5124914418762221
ビットコインの時と異なりラッソ回帰の決定係数は、リップル120日情報では、訓練用データ、テストデータともに0でしたが、30日情報では、訓練用データは0.03126037125933401、テストデータはわずかに0を下回る結果となりました。
一方、線形回帰、リッジ回帰においては、訓練用データ、テストデータともに決定係数の値に差はあまりないものの、リップル30日情報では、テストデータが負の値になっています。
以上より、PN値を付与した30日のデータにおける予測モデルには、ビットコイン同様、線形回帰、及びリッジ回帰を用いました。
(リップル30日情報のテストデータの決定係数が負の値が得られている点は、後ほど考察します)
「リップル30日情報 with PN値」
#01-3.XRP30×PNのモデル構築
#線形回帰 print('リップル30日 with PN情報')
print('線形回帰の予測モデル適合情報')
model = LinearRegression()
model.fit(xrpjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], xrpjpy_30_PN_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], xrpjpy_30_PN_train[['Price_stval']])))
pred = model.predict(xrpjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']], xrpjpy_30_PN_test[['Price_stval']])))
print()
#リッジ回帰 print('リッジ回帰の予測モデル適合情報')
model = Ridge()
model.fit(xrpjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], xrpjpy_30_PN_train[['Price_stval']])
print('訓練用データの決定係数:' + str(model.score(xrpjpy_30_PN_train[['Price_stdiff_1','Price_stdiff_3','pn_stval']], xrpjpy_30_PN_train[['Price_stval']])))
pred = model.predict(xrpjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']])
print('テストデータの決定係数:' + str(model.score(xrpjpy_30_PN_test[['Price_stdiff_1','Price_stdiff_3','pn_stval']], xrpjpy_30_PN_test[['Price_stval']])))
print()ビットコイン価格推移30日 with PN値のデータフレームより以下の数値が算出されました。
リップル30日 with PN情報
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.5742668938664358
テストデータの決定係数:-0.5790635421232633
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.5740536014133535
テストデータの決定係数:-0.558863668405194
PN情報を付与したリップル30日情報では、PN情報を付与していないリップル30日同様、訓練用データの決定係数は0.5を超えてきましたが、テストデータの決定係数は、リップル30日情報で算出した決定係数よりも低下してしまいました。
考察
01.ビットコインの予測結果
線形回帰、リッジ回帰ともに、120日情報の訓練用データ、テストデータ、30日情報の訓練用データ、テストデータの決定係数に変化はありませんでした。
しかし、取得期間が短い30日情報では、訓練用データ、テストデータ間の決定係数の差が広がったように思えます。考えられる可能性は、以下と考えます。
① ビットコインは価格変動が大きいため、標準化しても変動は大きい。そのため、評価期間によってはモデルの当てはまりは悪くなり、訓練用データ、テストデータ間の決定係数に開きが出てくるのでは?
② 単純に評価期間が120日でも短い
また、テストデータでは決定係数が負の値を示していました。これはモデルの当てはまりが単純に悪い可能性もあるため、説明変数を1つに絞ってみました。
その結果を以下に示します。
参考01:ビットコイン120日情報(1日変化を説明変数から除去)
線形回帰の予測モデル適合情報
訓練用データの決定係数:1.3303493938243705e-05
テストデータの決定係数:-0.004289142919168043
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:1.3303244108753276e-05
テストデータの決定係数:-0.004270475024730214
参考02:ビットコイン120日情報(3日変化を説明変数から除去)
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.002536445774442231
テストデータの決定係数:0.026034071838490602
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.0025361525098134274
テストデータの決定係数:0.02578111592801191
線形回帰、及びリッジ回帰による予測モデル間において、訓練用データとテストデータの差が少ないのは、いずれも説明変数から3日変化を除いたモデルでした。
以降、説明変数から3日変化を示す変数を除き、PN情報を付与したビットコイン30日情報に改めて適用してみました。
参考03:ビットコイン30日 with PN情報(3日変化を説明変数から除去)
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.38008958741198184
テストデータの決定係数:-1.3438478529312805
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.37904342282845527
テストデータの決定係数:-1.2485164448596024
PN情報も考慮すると、ビットコインの価格を考察する上で必要な因子は、
・「前日と当日のビットコインの価格差(1日変化、標準化後)」
・「記事情報(標準化PN値)」
があると参考になるかと今回は結論づけました。
02.リップルの予測結果
ビットコインの結果同様、線形回帰、リッジ回帰ともに、120日情報の訓練用データ、テストデータ、30日情報の訓練用データ、テストデータの決定係数に変化はありませんでした。
また、取得期間が短い30日情報でもビットコイン同様、訓練用データ、テストデータ間の決定係数の差が広がりました。可能性として以下が考えられました。
① ビットコイン同様、価格変動の影響。評価期間により予測モデルの当てはまりは悪くなり、訓練用データ、テストデータ間の決定係数に開きが発生する?
※ビットコインほど変動は大きくないが…
② 単純に評価期間が120日でも短い
一方、テストデータではリップル30日情報のみ、負の値を示していました。リップル120日情報ではこの現象は認められなかったため、説明変数にも問題があるのかもしれません(相関関係が高い等)。
とりあえず、ビットコインの時と同様、説明変数を1つに絞ってみました。
以下に結果を示します。
参考01:リップル120日情報(1日変化を説明変数から除去)
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.08237229357390996
テストデータの決定係数:0.22495883506332903
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.08237014693171918
テストデータの決定係数:0.22434097437491318
参考02:リップル120日情報(3日変化を説明変数から除去)
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.04470736097384065
テストデータの決定係数:0.07983376852281077
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.04470219189522151
テストデータの決定係数:0.07945089613721379
説明変数から1日変化を除いた予測モデルの場合、最初に構築した予測モデルよりも決定係数が増加していました。そのため、改めて1日変化の変数を除き、PN情報を付与したリップル30日情報を用いて予測モデル構築してみました。
参考03:リップル30日 with PN情報(1日変化を説明変数から除去)
線形回帰の予測モデル適合情報
訓練用データの決定係数:0.5448746490328258
テストデータの決定係数:-0.43909795731721446
リッジ回帰の予測モデル適合情報
訓練用データの決定係数:0.5446110057996869
テストデータの決定係数:-0.42043779152567873
PN情報を加えると、訓練用データの決定係数は増加するものの、テストデータの決定係数が負の値になることは変わらない状況です。
以上より、リップルの価格を考察する上で必要な因子は、
「3日前と当日のリップルの価格差」
と今回は結論づけました。
なお、リップルに関する情報は1記事しか抽出されていないため、説明変数に「記事情報(標準化PN値)」を加えるのはやはり不適切なのかもしれません。
03.ラッソ回帰
ラッソ回帰は、予測に影響を及ぼしにくいデータに関連する係数を0に近づける手法(L1正則化)を用いた回帰となります。
ビットコイン、リップルの予測モデルにおける説明変数の設定では、訓練用データの係数を0に近づけ過ぎてたため、決定係数が0になったと考察します。
説明変数と応答変数間の相関係数を求めると詳細な原因がわかるかもしれません。
なお、リップル30日情報では、ラッソ回帰でも決定係数が算出されました。
感想
今回、自分が考える説明変数は、ビットコイン、及びリップルの価格推測因子となりうるのかを分析の目的とし、複数の予測モデルの決定係数を比較し、妥当性を検証してみました。
この分析では、説明変数の数が限られていたため、他にも説明変数として投入できる情報があるとより面白い結果になるかもしれません。たとえば、日経平均株価、海外のNews情報、S&P 500などでしょうか。
もし時間があれば、この点はぜひ試してみたいところです。
全体を通じ、このデータ分析では、分析目的に応じたデータ選定にとても時間をかけてしまいました。そしてこれが最も困難な作業であると感じました。
数理的・Pythonプログラムの知識不足もあるかもしれませんが、分析目的がある程度固まっていないと、データ入手で判明する問題点に対する補正がうまくいかなかったり、データ加工後の変数上の課題…たとえば欠損など、柔軟な対応(アジャイルな修正)やデータ選定の見直しが迅速にできなかったと思います。
この困難さ、面白さをデータサイエンスに関する業務で体験、習得できるのならば、そちらの道に行ってもいいかもしれないと、本格的に考え始めました。
この記事が気に入ったらサポートをしてみませんか?