
[Rによるデータ分析入門]離散選択モデルの様々(2):順序ロジット・プロビット・モデル

本コラムは(1)では多項ロジット・モデルを紹介しました。(2)では、多項選択モデルの一種である順序ロジット・モデル(Ordered Logit Model)を紹介します。
順序ロジット・モデルとは
順序ロジット・モデルは、被説明変数が、1. 強くそう思う、2.どちらでもない、3. そうは思わない、のように順序を持つ選択肢になっている変数を扱うモデルです。アンケート調査などでは、このような選択肢が用意されていることがよくあります。この変数を通常の最小二乗法で分析すると、第4章のロジット・モデル、プロビット・モデルで紹介したように、理論値が選択肢の範囲を超えたり、また、直線で近似するとモデルのフィットが悪くなるといった問題が生じます。また、最小二乗法では線形の関数を想定していますので、たとえばyがビールの購入額で1000円から2000円に増えれば購入額が2倍になったと解釈できますが、上記のような序列を示す被説明変数で「1.強くそう思う」と「3.そうは思わない」の3-1の差の大きさには特に意味はありません。こうした状況で利用されるのが順序ロジット・モデルです。
順序ロジット・モデルでは、たとえば以下の図1のように、説明変数Xが一定の値、X1以下の場合、選択肢1が選ばれ、X1からX2の間なら選択肢2、X2からX3の間なら選択肢3、X3からX4の間なら選択肢4、X4以上なら選択肢5が選択される、といった状態を想定します。
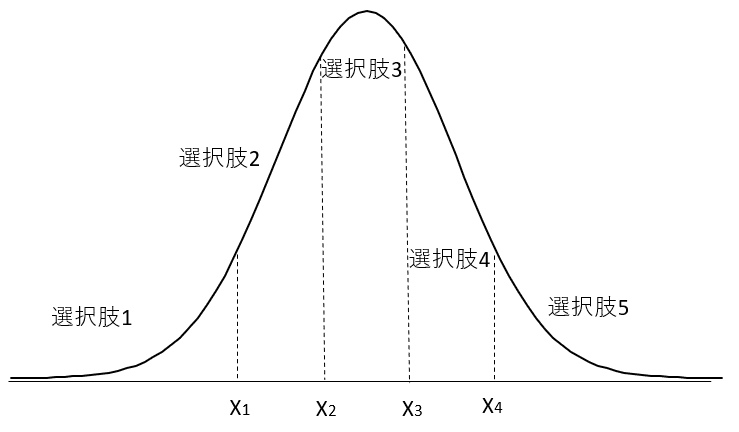
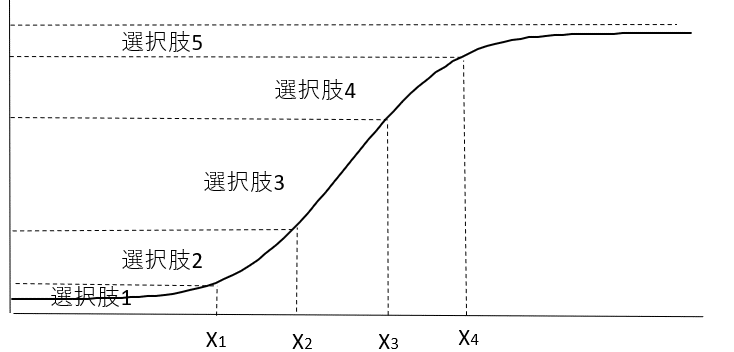
図1では選択肢の選択割合を正規分布の密度関数で描いていますが、これを累積密度関数で表したのが次の図2です。これをロジスティク曲線で近似したのが順序ロジット・モデルです。また、以下の累積密度関数を正規分布で近似することもできて、これを順序プロビット・モデルといいます。第4章で説明したようにロジット、プロビット・モデルは、係数の大きさこと違えど、ほぼ同じ推計結果を導きますが、順序ロジット・モデルと順序プロビット・モデルもほぼ同じ推計結果を導きます。
Rによる推定方法
早速、事例を見ていきましょう。ここで使用するデータは架空のアンケート調査で、勤労者を対象とした幸福度と収入や雇用形態、性別、子供の数について調査したデータです。幸福度(happiness)は、1. 幸福ではない、2. どちらかというと幸福ではない、3. どちらともいえない、4. どちらかというと幸福である、5. 幸福である、という序列をもつ選択肢になっています。これを被説明変数にして、説明変数に収入(income)、雇用形態ダミー変数(regular: 正規労働者なら1)、性別(male: 男性なら1)、子供の数(kids)を用います。
ここで使用するデータとスクリプト例は以下からダウンロードできます。
まず最小二乗法でhappinessを被説明変数とする回帰分析の結果を見ておきましょう。
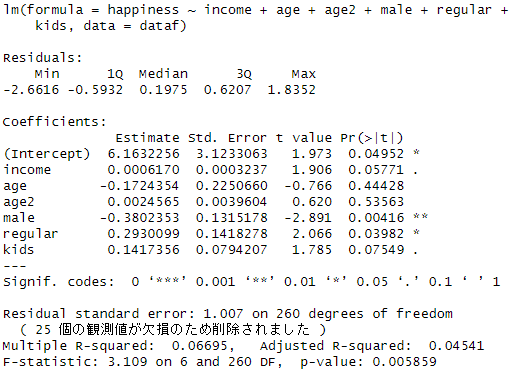
統計的に有意になった変数は、income, male, regular, kidsの4つです。ageとage2は非有意となりました。
順序ロジットモデルの推定
次に順序ロジットを推定します。ここではMASSパッケージに含まれるpolr()関数を使います。事前にMASSパッケージをインストールしlibrary(MASS)で呼び出しておきます。
polr()関数の使い方ですが、
polr(y~x1+x2,data=データフレーム名, method="logit")
で推定できます。methodは何も指定しなければ順序ロジットで、method="probit"にすると順序プロビットモデルの推定になります。
ただし、polr()による推定にあたっては下準備が必要です。今回のhappinessを使ってそのままpolr()を使って推計しようとすると以下のようなエラーが出ます。
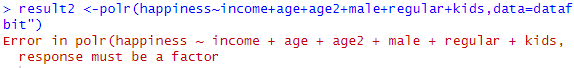
"response must be a factor"とあるようにas.factor()関数で「因子型」の変数に変換しておく必要があります。具体的には、
データフレーム名<-データフレーム名%>%mutate(y=as.factor(y))
で変換が可能です。以下がスクリプト例です。
#被説明変数は因子型(factor)に変換しておく
dataf <- dataf %>% mutate(dep=as.factor(happiness))
#順序ロジット result2 <-polr(happiness~income+age+age2+male+regular+kids,data=dataf)
summary(result2)
#順序プロビット result3 <-polr(happiness~income+age+age2+male+regular+kids,data=dataf,method="probit")
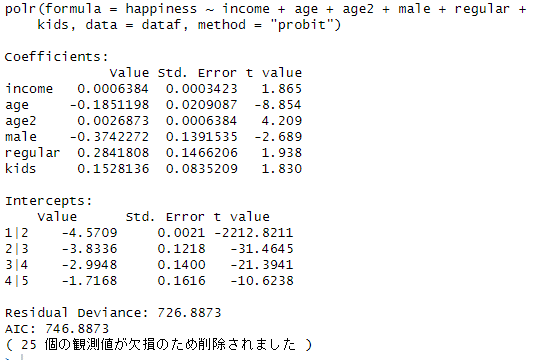
summary(result3)推計結果は以下の通りです。

P値をみていくと、10%未満なのは、income、make、regular、kidsです。所得(income)が高いほど、正社員である場合(regular=1)、子供の数(kids)が多いほど幸福度が高いことがわかります。一方、男性ダミー(male)の係数はマイナスですので女性のほうが幸福度が高いことがわかります。
なお、1|2, 2|3, 3|4, 4|5 という係数が表示されていますが、これは、たとえば図1のX1~X4に対応するパラメータです。
以下は順序プロビットの結果です。係数そのものは直接比較できませんが、順序ロジットと係数の符号や有意性はほぼ同じと言えます。
msummary()による結果出力
polr()関数はmsummary()にも対応しています。ここまで3つの推定式をmsummary()で出力してみましょう。
library(modelsummary)
regs <- list(
model1=lm(happiness~income+age+age2+male+regular+kids,data=dataf),
model2=polr(happiness_f~income+age+age2+male+regular+kids,data=dataf),
model3=polr(happiness_f~income+age+age2+male+regular+kids,data=dataf,method="probit")
)
msummary(regs,stars = TRUE,gof_omit='RMSE|AIC|BIC|Log.Lik.')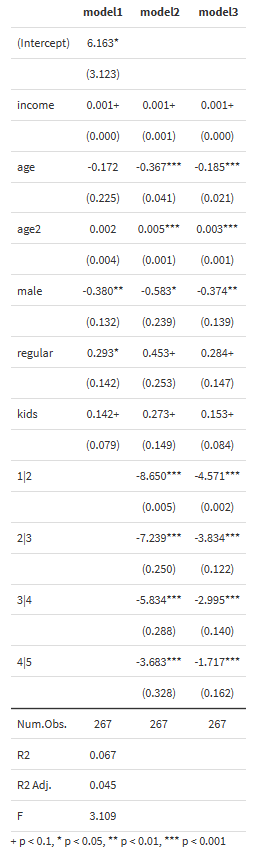
polr()では有意水準を示す*が出ませんが、msummary()ならstars=TRUEオプションを付けると表示されます。
限界効果の計算
polr()で限界効果を計算するには、ererパッケージのocME()関数を使います。あらかじめererパッケージのインストールしておくことが必要です。インストールしたのちlibary(erer)でパッケージを呼び出します。ocME()関数の使い方ですが、polr()で順序ロジット(あるいは順序プロビット)を推定して起き、その結果を含むオブジェクト(以下の例ではresult2)をocME()関数に導入します。
# 限界効果
library(erer)
result2 <-polr(happiness_f~income+age+age2+male+regular+kids,data=dataf)
summary(result2)
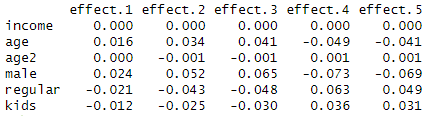
ocME(w=result2)以下がその結果です。順序ロジットの限界効果は、説明変数が変化したときに被説明変数の各選択肢が選択される確率がどの程度変化するかを示します。そのため、限界効果は被説明変数の選択肢の数だけ出てきます。たとえば男性ダミーmaleの限界効果はeffect.1 effect.2 effect3がプラスなので、男性は女性よりも幸福度1~3を選択しがちで、特に3を選ぶ確率が高いと読めます。
最後に参考文献をあげてきます。
本コラムでは何度か紹介している山本勲「実証分析のための計量経済学」第8章P118~に丁寧な説明があります。初心者でも分かりやすく書かれています。
また、もう少しフォーマルな説明が西山ほか(2019)の第8章3-1節・3-2節P.349~にあります。
第3回では、ヘーキット・モデルについて紹介します。
なお本コラムは2024年4月ごろ発売予定の「Rによるデータ分析入門」(仮)のWEBサポートページとして作成されました。WEBサポートの一覧は以下を参照してください。
この記事が気に入ったらサポートをしてみませんか?