
PyTorchでVGGを実装する

最近GPT4等のLLMの登場でディープラーニングが盛り上がっています。
私自身も学習済みのモデルをファインチューニングしたりすることは良くしているのですが、ゼロからモデルを学習させたことがほとんどないため勉強がてらにゼロからモデルを学習させてみようと思います。
まず手始めにシンプルで実装しやすいVGGの論文(Very Deep Convolutional Networks for Large-Scale Image Recognition)を読みながら実装と学習を行ってみようと思います。
実装したコードは以下にアップロードしています。https://github.com/tosiyuki/vgg-food101
VGGの概要
2014年のILSVRCの画像分類部門で2位をとったモデル。
3×3の畳み込み層を採用したことで、AlexNetなどの従来のモデルと比べて深いネットワークを作成することができ、モデルを深くすることで精度が向上することを示した。
学習時に256×256〜512×512のマルチスケールの画像をランダムで用意し、224×224の画像を切り出して学習を行うことで精度が向上することを示した。
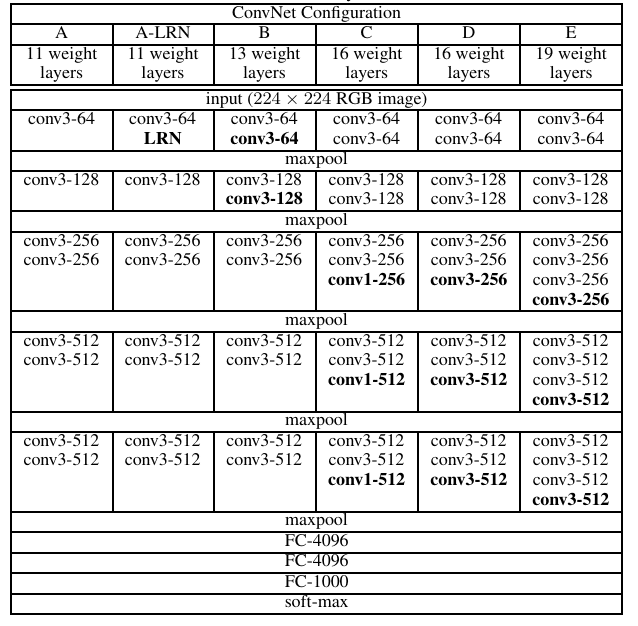
VGGにはVGG16やVGG19など層の深さでモデル名がついていますが、各モデルの構造は下図のとおりです。
学習データの用意
私の環境でImageNetのような大規模なデータを学習させるのは難しいため、今回はFood 101という101種類の料理からできているデータセットを使用します。
Food 101のapple_pieのディレクトリを見ると以下のようになっています。
データの確認をしたところでDatasetクラスを実装します。
from typing import List, Tuple
import os
from PIL import Image
import torch
import torch.nn as nn
import torch.utils.data as data
from torchvision import transforms as transforms
class Food101Dataset(data.Dataset):
def __init__(self, file_list: List[str], scale: int=256,
is_train: bool=True, device=torch.device('cpu')) -> None:
super().__init__()
self.label_list = _load_metadata('classes.txt')
self.scale = scale
self.file_list = file_list
if is_train:
self.transform = nn.Sequential(
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(224),
).to(device)
else:
self.transform = nn.Sequential(
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
transforms.RandomCrop(224),
).to(device)
self._getter_transform = transforms.Compose([
transforms.ToTensor(),
])
def __len__(self) -> int:
return len(self.file_list)
def __getitem__(self, index) -> Tuple[torch.Tensor, str]:
img_path = self.file_list[index]
img = Image.open(img_path).convert('RGB').resize((self.scale, self.scale))
img = self._getter_transform(img)
label = os.path.split(os.path.dirname(img_path))[-1]
return img, self.label_list.index(label)
def _load_metadata(metadata_path: str) -> List[str]:
metadata_path = os.path.join('./data/food101/meta/meta', metadata_path)
with open(metadata_path) as f:
return [i.rstrip()for i in f.readlines()]
def make_datapath_list(is_train: bool=True) -> List[str]:
if is_train:
file_list = _load_metadata('train.txt')
else:
file_list = _load_metadata('test.txt')
target_path = './data/food101/images'
path_list = [os.path.join(target_path, path+'.jpg') for path in file_list]
return path_listFood 101ではmetaデータで訓練セットとテストセットのファイル名が書かれているためそちらを使用して訓練セットとテストセットに分類しています。
また、VGGの論文ではDataAugmentationとしてランダムな水平方向反転す、ランダムなRGBカラーシフト、224×224に切り出すの3つを行っています。
ただ、ランダムなRGBカラーシフトの方法が私には理解できなかったため今回は実装していません(分かる人誰か教えてほしい…)。
モデルの実装
モデルの実装は以下のPyTorchのVGGの実装を参考にしながら行いました。
from typing import List, Union, Dict, Any
import torch
import torch.nn as nn
cfgs: Dict[str, List[Union[str, int]]] = {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"A_LRN": [64, "L", "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"C": [64, 64, "M", 128, 128, "M", 256, 256, "C", "M", 512, 512, "C", "M", 512, 512, "C", "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
class VGG(nn.Module):
def __init__(self, features: nn.Module, num_classes=1000,
dropout: float=0.5, init_weights: bool=True):
super(VGG, self).__init__()
self.features = features
self.avepool=nn.AdaptiveAvgPool2d((7,7))
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(dropout),
nn.Linear(4096, num_classes)
)
if init_weights:
self._init_weight()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avepool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg: List[Union[str, int]]):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
conv2d = nn.Conv2d(in_channels, in_channels, kernel_size=1)
layers += [conv2d, nn.ReLU(True)]
elif v == 'L':
layers += [nn.LocalResponseNorm(5, k=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
def vgg_a(num_classes: int=1000, dropout: float=0.5) -> VGG:
features = make_layers(cfgs['A'])
return VGG(features, num_classes, dropout)
def vgg_a_lrn(num_classes: int=1000, dropout: float=0.5) -> VGG:
features = make_layers(cfgs['A_LRN'])
return VGG(features, num_classes, dropout)
def vgg_b(num_classes: int=1000, dropout: float=0.5) -> VGG:
features = make_layers(cfgs['B'])
return VGG(features, num_classes, dropout)
def vgg_c(num_classes: int=1000, dropout: float=0.5) -> VGG:
features = make_layers(cfgs['C'])
return VGG(features, num_classes, dropout)
def vgg_d(num_classes: int=1000, dropout: float=0.5) -> VGG:
features = make_layers(cfgs['D'])
return VGG(features, num_classes, dropout)
def vgg_e(num_classes: int=1000, dropout: float=0.5) -> VGG:
features = make_layers(cfgs['E'])
return VGG(features, num_classes, dropout)
def get_vgg_model(model_name: str='vgg_a', num_classes:int =1000,
dropout: float=0.5) -> VGG:
if model_name == 'vgg_a':
return vgg_a(num_classes, dropout)
elif model_name == 'vgg_a_lrn':
return vgg_a_lrn(num_classes, dropout)
elif model_name == 'vgg_b':
return vgg_b(num_classes, dropout)
elif model_name == 'vgg_c':
return vgg_c(num_classes, dropout)
elif model_name == 'vgg_d':
return vgg_d(num_classes, dropout)
elif model_name == 'vgg_e':
return vgg_e(num_classes, dropout)CNN層の重みの初期化には当初論文に平均がゼロで分散が10の-2乗の正規分布で初期化したと書かれていたため、そちらで行ってみたのですが学習がうまく進みませんでした。そのため本実装ではHe の初期値を使用しています(論文を読み間違えているかも)。
学習
今回は256×256の画像に対してVGGの論文で提示されているA〜Eまでの6つのモデルを学習させています。
マルチスケール画像をクロップして訓練したほうが精度が向上することも確認したかったのですが学習に時間がかなりかかるのでまた後ほど確認します。
最適化関数は論文にしたがってSGDを使用しておりハイパーパラメータも論文の通りです。
学習順としては最初にAのモデルを学習しました。A以外のモデルについては学習を早く収束させる効果があるということで学習したAの最初の4層の畳み込み層の重みと最後の3層の全結合層の重みをコピーしています。
またバリデーションデータを用意するために訓練データを8:2で分割しました。
学習時のlossとバリデーションデータの精度の進捗は以下のとおりです。
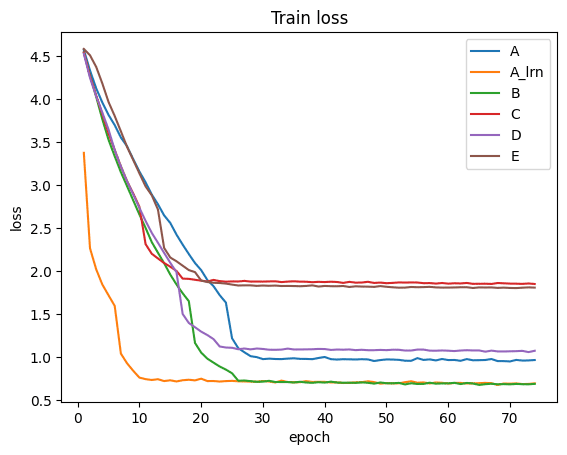
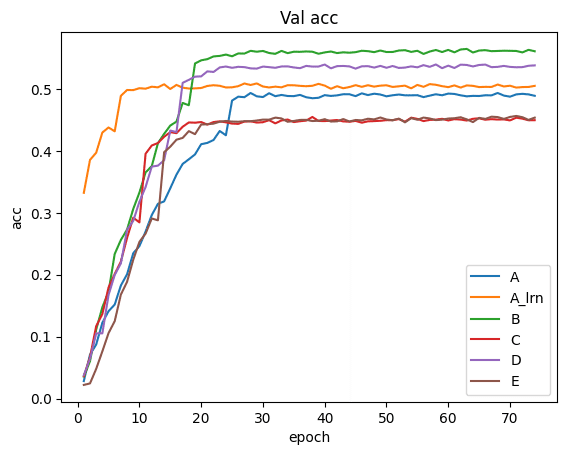
Aの重みを他のモデルにコピーしているためAと比べてその他のモデルは学習が進むのが論文通り早いことが分かります。
一方モデルA, A_LRN, Bまではいい感じに学習ができているように見えるのですがC, D, Eは学習が予想していたより進みませんでした。
Food 101のデータセットではC, D, Eではモデルが深すぎてうまく学習できなかったのでしょうか。Batch Normalizationを使用したりしたら学習がうまくいくのかもしれません。
上記の問題に関しては今後追加で検証を行いたいと思います。
結果
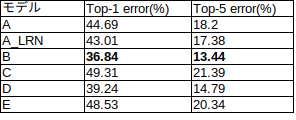
学習時のログでC, D, Eのモデルが思ったよりも学習が進んでいないことは分かったのですがテストデータでも各モデルの精度を確認しました。
以下にモデルごとにtop-1とtop-5のエラー率を示します。
最後に
したがって今回はVGGを論文を読みながら実装していきましたが、学習がうまくいかないなど課題が残りました。
シンプルな画像分類タスクでもゼロから学習してみると思ったより精度が伸びなかったのでLLMなどの複雑な大規模モデルをゼロから学習している人は改めてすごいなと感じました。
今後も勉強がてらに様々なモデルを実装してみようと思います。
TODO
C, D, Eのモデルの学習が想定より進まなかった原因の調査
random RGB colour shiftの調査
マルチスケール画像をクロップして学習したほうが精度が向上することの確認
この記事が気に入ったらサポートをしてみませんか?