
kohya_ssでLoRA学習環境を作ってコピー機学習法を実践する(SDXL編)

こんにちはとりにくです。皆さんLoRA学習やっていますか?
私はそこらへんの興味が薄く、とりあえず雑に自分の絵柄やフォロワの絵柄を学習させてみて満足していたのですが、ようやく本腰入れはじめました。
というのもコピー機学習法なる手法――生成される絵になるべく影響を与えず、制御できるLoRAの学習法――を知ったので、ぜひ自分でも作ってみたいと思い、チャレンジしました。コピー機学習法のやり方は以下のkohyaさんの記事がめちゃくちゃわかりやすいです。
今回はその学習ができる環境構築方法&上記のKohyaさんの手法を用いた実践手段をまとめていきたいと思います。
前提条件
Python:3.10.8
CUDA:11.8
導入方法
①コマンドプロンプトでkohya_ssをgit clone
cd C:\
git clone https://github.com/bmaltais/kohya_ss.git②kohya_ssフォルダのsetup.batを実行

以下のような画面がでてくるので『1』と入力
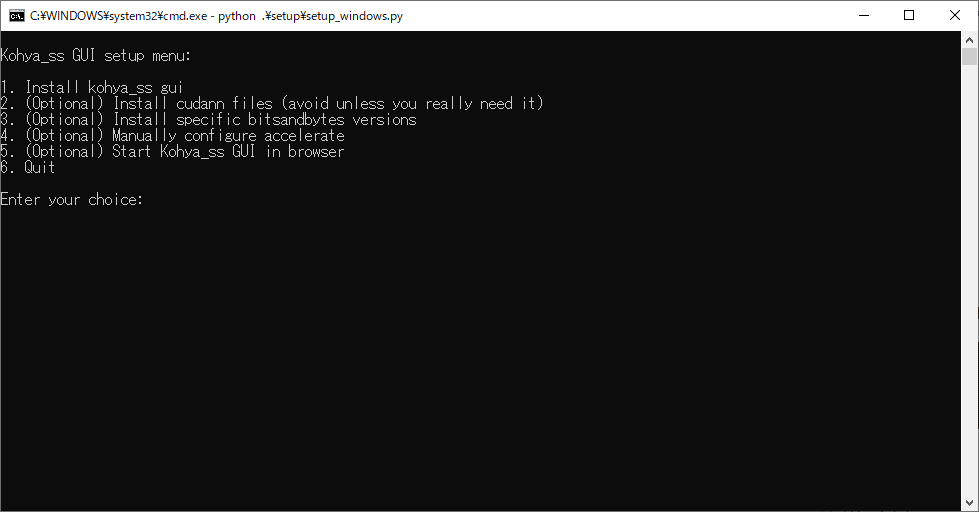
次は『2』

自動で必要なライブラリがインストールされます(結構時間がかかるので待つこと)
なんか色々聞かれるので以下のように答える。
- This machine
- No distributed training
- NO
- NO
- NO
- all
- bf16元の画面に戻るので次は『2』を入力

したら
"C:\kohya_ss\setup..\cudnn_windows" could not be found.
と怒られるので

しょうがないので以下のファイルから直接zipをDL。
C:\kohya_ss直下にに保存&解凍。もう一度『2』を選択すると
https://github.com/bmaltais/python-library/raw/main/cudnn_windows.zip

次に『3』→『3』

最後に『6』で終了する。
これでインストールはひとまず終了。
GUIを使わない場合は以下のようなvenv.cmdを作っておくと簡単にコマンドプロンプトから仮想環境に入れて便利です
cmd /k venv\Scripts\activate③画像を用意する
自分は生成AIから出力した画像を加工して以下のような画像を用意した。


④ sdxl_train_network.pyを実行
あとはkohyaさんのnoteを参考にしてください(ぶん投げ)
というのもあまりにもあんまりなので自分の設定ファイルをzipにまとめておきます。
以下のファイルをC:\kohya_ss直下において以下のようなコマンドを実行すると過学習されたLoRAが作成されます。(kohyaさんの記事だと4epochでしたが自分はなんとなく6epoch位回しています)
accelerate launch ^
--mixed_precision bf16 ^
--num_cpu_threads_per_process 1 ^
sdxl_train_network.py ^
--config_file="C:\kohya_ss\user_config\eyes\copi-ki.toml" ^
--train_data_dir="C:\kohya_ss\user_config\eyes\train\open_eyes" ^
--output_name=sdxl-copi-ki-open_eyes ^
--max_train_epochs 6環境によってパスが変わってくると思いますのでそこらへんは適宜調整してください。
さて、open_eyesとfacelessをそれぞれ6epochほど学習させた結果がこれです。



重ね合わせてみると微妙にずれていますが、まぁこれで良しとしましょう。
⑤svd_merge_lora.pyによる抽出
python networks/svd_merge_lora.py ^
--save_precision bf16 ^
--save_to "C:\kohya_ss\user_config\output\eyes\faceless.safetensors" ^
--models "C:\kohya_ss\user_config\output\eyes\sdxl-copi-ki-faceless.safetensors" ^
"C:\kohya_ss\user_config\output\eyes\sdxl-copi-ki-open_eyes.safetensors" ^
--ratios 1.0 -1.0 ^
--new_rank 16 ^
--new_conv_rank 8 ^
--device cudaC:\kohya_ss\user_config\output\eyes\faceless.safetensors"が作成されるのでこれが欲しかったfacelessLoRAになります。
試しに推論させてみましょう。まずはLoRAを使わずに。


キャラデザ変わってんがな!!!!!明らかに過学習させた画像に引っ張られています。ぐぬぬぬぬ、コピー機学習法。難しいです・・・。(4epoch版もダメでした)
この記事が気に入ったらサポートをしてみませんか?