SDXLでコピー機学習法を試す

はじめに
コピー機学習法は、LoRAを教師画像と同様の画像しか出力されないレベルまで過学習し(コピー機と呼ばれる理由です)、そこから目的のLoRAを取り出す手法です。詳細は以下の月須和・那々氏の記事をご覧ください。
今回、SDXLでコピー機学習法を試してみました。品質的にはいまひとつですが、一応成功はしましたので、設定等を共有します。
学習にはsd-scriptsを利用しています。
教師データ
とりにく氏の画像を利用させていただきます。
SDXLにおけるコピー機学習法考察(その1)
— とりにく (@tori29umai) September 10, 2023
①まず生成AIから1枚の画像を出力(base_eyes)。手動で目をつぶった画像(closed_eyes)に加工(画像1枚目と2枚目)
②画像3枚目のレシピでまずbase_eyesを学習、CounterfeitXL-V1.0とマージする
③②のモデルをベースに4枚目でclosed_eyesを学習 pic.twitter.com/UmEAzOB5QD
今回は開き目(通常の状態)1枚、閉じ目(LoRA適用時にこうなってほしい状態)1枚の2枚から学習します。以下のようなフォルダに配置します(.tomlを使わず、フォルダ名をキャプションとする方式です)。繰り返し回数192として、1 epoch 192枚にしています。
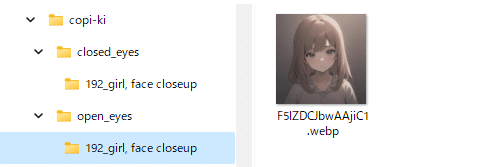
キャプションは「girl, face closeup」で学習します。これは空白でもいいかと思いますが、モデルが早めに収束(過学習)することを期待しています。
学習
設定ファイル
以下のような.tomlを用意しました。
pretraied_model_name_or_path = "path/to/sd_xl_base_1.0_0.9vae.safetensors"
output_dir = "path/to/output_dir"
sample_prompts = "path/to/prompts.txt"
seed = 42
xformers = true
max_data_loader_n_workers = 4
persistent_data_loader_workers = true
gradient_checkpointing = true
resolution = "1024,1024"
train_batch_size = 12
mixed_precision = "bf16"
save_precision = "bf16"
save_every_n_epochs = 1
sample_every_n_epochs = 1
sample_sampler = "k_euler_a"
optimizer_type = "adamw8bit"
unet_lr = 1e-3
network_train_unet_only = true
network_module = "networks.lora"
network_dim = 16
network_args = ["conv_dim=8"]
cache_latents = true
cache_text_encoder_outputs = true今回はsd_xl_baseで学習しました。アニメモデルの方が品質が良くなるかもしれません。
フォルダ名、ファイル名等は適宜書き換えてください。またmixed precisionにfp16を使う場合には、"bf16"を"fp16"に書き換えてください。
バッチサイズは12で、これは24GB VRAMに向けた値です。VRAM容量に応じて減らしてください。dim(rank)が低いため、1まで減らせば8GB VRAMでも動くかもしれません。
また学習率として1e-3と比較的高めの数値を設定しています。これは破綻しない範囲で学習時間を短縮するためです。バッチサイズを小さくした場合は、学習率を下げたほうが良いようです(たとえばバッチサイズ4なら2e-4程度?)。
dim(rank)はLinearで16、Convで8を指定しました。過学習させるためにはそれほど大きな値は必要ないであろうとの認識です。SDXLでは浅い層にはtransformerがなくLinearが存在しないため、"conv_dim"の指定が必要と思われます。
学習の進み具合を見るため、sample_promptsとsample_every_n_epochsを指定しています。サンプルのプロンプトは、学習時と同じにすると良いでしょう。以下のようにseedを変えておくと過学習具合が分かります。
girl, face closeup --w 1024 --h 1024 --d 1
girl, face closeup --w 1024 --h 1024 --d 2開き目のLoRAを学習する
コマンドラインからまず開き目のLoRAを学習します(実際には1行で記述してください)。
accelerate launch --mixed_precision bf16 --num_cpu_threads_per_process 1
sdxl_train_network.py --config_file=path/to/copi-ki.toml
--train_data_dir=path/to/copi-ki/open_eyes
--output_name=sdxl-copi-ki-open
--max_train_epochs 4今回の設定では4 epoch(64ステップ)で十分過学習するようです。

閉じ目のLoRAを学習する
ひとつ目のLoRAをベースモデルにマージし(または--base_weightsオプションを使い)そこからふたつ目のLoRAを学習していく方法と、別にコピー機LoRAを学習し差分を抽出する方法(差分学習法)とがありますが、今回試したところでは後者の方が品質が良かったため、後者を使います。
開き目と同様に学習します。
accelerate launch --mixed_precision bf16 --num_cpu_threads_per_process 1
sdxl_train_network.py --config_file=path/to/copi-ki.toml
--train_data_dir=path/to/copi-ki/closed_eyes
--output_name=sdxl-copi-ki-close
--max_train_epochs 4
sdxl_merge_lora.pyによる抽出
二つのLoRAができましたが、それぞれは目の状態だけでなく、服装、表情、背景、画風やアングルなどあらゆるものを学習しています。しかし二つのLoRAの違いは目の状態だけなので、「(諸々の情報+閉じ目)-(諸々の情報+開き目)」という計算をすれば「目を閉じる」というLoRAだけになることが期待できます。
二つのLoRAの差分はsvd_merge_lora.pyで抽出します(merge_lora.pyでも特殊な条件では動作しますが、通常はsvd_merge_lora.pyを使ってください)。
→ laksjdjf氏のcontributionによりsdxl_merge_lora.pyにconcatオプションが追加されたため、そちらでマージします。concatオプションにより、二つのLoRAを劣化なくマージできます。
python networks/sdxl_merge_lora.py --save_precision bf16
--save_to path/to/sdxl-copi-ki-closing.safetensors
--models path/to/output_dir/sdxl-copi-ki-close.safetensors path/to/output_dir/sdxl-copi-ki-open.safetensors
--ratios 1.0 -1.0 --concat --shufflesave_precisionには学習時と同じ精度を指定するのが良いでしょう。modelsに二つのLoRAを指定します。ratiosに各モデルの倍率を指定しますが、今回は「閉じ目-開き目」なので、閉じ目1.0、開き目-1.0になります。
shuffleオプションを追加し、重みをシャッフルします。シャッフルしないとマージ後のLoRAから元のLoRAを取り出せるため、学習元データがそのまま露呈しますのでご注意ください。
SDXLではなくSD1/2のLoRAの場合、merge_lora.pyでマージできます。
svd_merge_lora.pyを使う場合のコマンドライン例
svd_merge_lora.pyを使う場合についても残しておきます。
new_rankとnew_conv_rankには保存するLoRAのrank(dim)を指定します。ここでは元のLoRAと同じ値を指定しています。元のrankの倍を指定すれば、劣化なく差分抽出できるはずです。
deviceにcudaを指定すると、マージをGPUを使って行います。GPUのメモリが足りなくなる場合はdeviceオプションを外してください(CPUで演算します)。
マージにはそれなりの時間が掛かります。
python networks/svd_merge_lora.py --save_precision bf16
--save_to path/to/sdxl-copi-ki-closing-svd.safetensors
--models path/to/output_dir/sdxl-copi-ki-close.safetensors path/to/output_dir/sdxl-copi-ki-open.safetensors
--ratios 1.0 -1.0 --new_rank 16 --new_conv_rank 8 --device cuda結果
アニメモデルに適用してみた結果は以下の通りです。

まとめ
SDXLでのコピー機学習法は不安定なようで、設定を少し変えるだけでもうまく行かないことがありました。各エポックのサンプル出力が壊れることが多いので、それを参考に、うまく学習できているか(教師画像に近づいているか、破綻していないか)確認しながら進めると良さそうです。
設定を変える場合は、たとえば以下を試してみてください。
ベースモデル
学習率
seed
学習ステップ数(エポック数)
network_dim および conv_dim を増やす、減らす
network_dropout = 0.1 など、ニューロンのdropoutの設定
network_args = ["conv_dim=8", "rank_dropout=0.1"] など、rankのdropoutの設定
可能なら教師データを増やす、減らす
noise_offsetは過学習を意図的に起こすためには外したほうが良さそうです。
おわりに
この記事がSDXLでコピー機学習法を試す方の参考になれば幸いです。また、改めて月須和・那々氏、とりにく氏、laksjdjf氏に感謝いたします。
この記事が気に入ったらサポートをしてみませんか?