
richmanbtcさんのbot周りについて調べたり改造したりしたのでそれのまとめ

色々やってみたのでそれのまとめです。
この記事は、botter初心者とその他botter界隈に限らないPythonを用いた仮想通貨の自動売買に興味のある有象無象森羅万象の人間のために書いているわけではないです。ご自身の判断で参考にしたりしなかったりなさってください。
コードは参考です。間違えてるかもしれないです。
なお、独自のポエミーアレンジにより、かなり読みにくくなっておりますがよろしくお願いします。
参考
このnoteはrichmanbtcさんのこちらのチュートリアルがもとになっています。
指値考えてみた
チュートリアルでは窓14のATR*0.5をcloseからの指値の幅として使っていました。
ATRとは
高値と安値の差の指数平滑平均らしいです。
指値作成案
指値の幅を0.5から変えてみる。
このATRを平均足に適用して指値を作ってみる。
実体だけの足の平均で作ってみる。
上下のヒゲの長さの平均だけで作ってみる。
など
今回は一番上の指値幅について、後で最適化してみようと思います。
テストデータで検証してみた
チュートリアルでは触れられてなかったので一応書いてみました。
一番最初のところの、
# 実験に使うデータ期間を限定する
df = df[df.index < pd.to_datetime('2021-04-01 00:00:00Z')]をコメントアウトして、全ての範囲で特徴量、buy/sell_price、buy/sell_fep,fet、buy/sell_executed、y_buy/sell、buy/sell_costを計算した後に、
# データの分割
df_all = df.copy()
df = df[df.index < pd.to_datetime('2021-04-01 00:00:00Z')]
# このdfがtrain用のデータになる。
# チュートリアルに合わせてdfのままにしている。として、df(train用)を使って学習しy_pred_buy、y_pred_sellを埋めたあと、test用データだけ抜き出す。
df_test = df_all[df_all.index>=pd.to_datetime('2021-04-01 00:00:00Z')]分かりにくいのでmodelをbuyとsellに分ける。
df(train用)で学習したmodelを使ってy_pred_buy/sellを埋めて、
model_buy = lgb.LGBMRegressor(n_jobs=-1, random_state=1)
model_sell = lgb.LGBMRegressor(n_jobs=-1, random_state=1)
model_buy.fit(df[features], df['y_buy'])
model_sell.fit(df[features], df['y_sell'])
df_test['y_pred_buy'] = model_buy.predict(df_test[features])
df_test['y_pred_sell'] = model_sell.predict(df_test[features])バックテストして、
df_test['cum_ret'], df_test['poss'] = backtest(
cl=df_test['cl'].values,
buy_entry=df_test['y_pred_buy'].values > 0,
sell_entry=df_test['y_pred_sell'].values > 0,
buy_cost=df_test['buy_cost'].values,
sell_cost=df_test['sell_cost'].values,
# pos_size=df['pos_size'].values # 後でbacktestを改造します。
)プロットする。
df_test['cum_ret'].plot()
plt.show()
これでテストデータでの結果を見ることができました。
山です。
よく見ると左の方に大きな噴火口があります。ペロッ!これは…!!!
元気な富士山です。オンギャァ
LGBMについて色々試してみた
LGBMの特徴は?由来は?読み方は?メリット・デメリットは?過学習しやすい?処理速度は最速!
調べてみましたが、LGBMの年収は分かりませんでした。
パラメータをいじってみた
paramsを設定して、modelの引数にぶちこんでパラメータをいじれるようにしてみました。
# ↓はLGBMのデフォルトの設定。
params = {
'reg_alpha': 0.0, # float 0~1 # 小さいほど過学習
'reg_lambda': 0.0, # float 0~1 # 小さいほど過学習
'subsample': 1.0, # float 0~1 # 大きいほど過学習
'colsample_bytree': 1.0, # float 0~1 # 大きいほど過学習
'num_leaves': 31, # int 2~ # 大きいほど過学習
'subsample_freq':0, # int 0~ # 大きいほど過学習
'min_child_samples':20, # int 0~ # 小さいほど過学習
'n_estimators': 100, # int 0~ # よくわからん
}
model = lgb.LGBMRegressor(n_jobs=-1, random_state=1, **params)ここからは個人の感想ですが、num_leavesは小さめにするとよさそうでした。reg_alphaとreg_lambdaは0.5くらいにすると良い感じに雑に学習してくれるように感じました。n_estimatorsは小さいと学習しきらないっぽくて、雑でいいからとりあえずでかくした方がいいのかもしれないと思いました。あとは全く意味が分からなかったです。
ExtraTreesを使ってみた
去年のアドベントカレンダーで話題になっていたExtraTreesというのを使ってみました。書いたはいいがこれもよくわかってないです。
from sklearn.ensemble import ExtraTreesRegressor
model = ExtraTreesRegressor(n_jobs=-1, random_state=1)試すと、LGBMRegressorよりかなり時間がかかりました。デフォルトだとリターンもよくありませんでした。n_estimatorsをデフォルトの100から300に増やすと若干よくなりました。extra_treesの引数は発見できず。技術力のNASAが露呈する結果となりました。皆さん是非試してみてください(丸投げ)
特徴量とかモデル詳しく見てみる
特徴量とかモデルを詳しく見てみようのコーナーです。一般的には詳しく見ていますので、本職の方はご退場ください。
ヒストグラムと散布図
とにかくヒストグラムと散布図を見てみます。このとき df[df['y_buy']!=0]とするとy_buyが0でないときのデータだけになり、見やすくなります。(そのままだと0が多くて見にくいと思う)
for f in features:
df[df['y_buy'] != 0][f].plot.hist(bins=100)
plt.title(f)
df[df['y_buy']!=0].plot.scatter(x=f, y='y_buy')
plt.title(f+'_buy')
df[df['y_sell']!=0].plot.scatter(x=f, y='y_sell')
plt.title(f+'_sell')
plt.show()実行すると…


こんな感じで全ての特徴量のヒストグラムと散布図が出てきます。
なんかよくわからないものもあります。01の特徴量もありました。

ちょっとエッチな特徴量もありました。

以上、とりあえずヒストグラムと散布図でデータを見てみようのコーナーでした。
PDP
PDPとは、modelの挙動の説明ができるやつらしいです。雑に説明すると、特徴量Xがある値を取った時どういう予測になるかを、その特徴量Xの最小値から最大値まで試して、グラフにするやつです。詳しくはここからどうぞ。今回はmodel_buy(買い側)について見てみます。
from sklearn.inspection import PartialDependenceDisplay
for f in features:
fig, ax = plt.subplots()
PartialDependenceDisplay.from_estimator(
estimator=model_buy,
X=df[features],
features=[f],
kind='average',
ax=ax,
)
plt.show()実行すると特徴量について一個ずつ表示してくれます。例えばBETAという特徴量では、
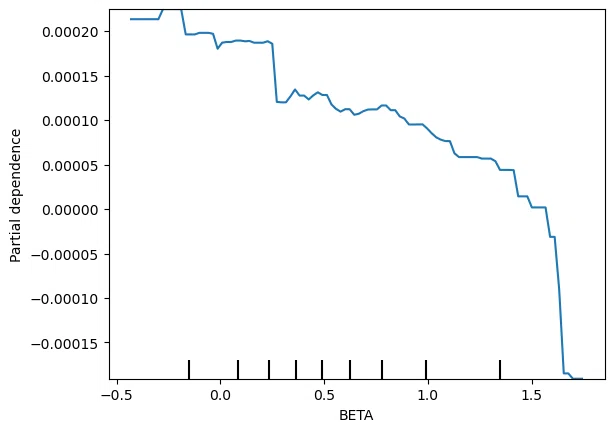
値が大きくなるごとに予測値が小さくなっているようでした。
こういうキモい形してるやつもあります。よくわかりません。

ロット調整してみた
実運用では部分約定という敵がいるため、こいつらを消す必要があります。ということで今回は、NATRというボラ指標をもとにボラが小さいときにロットが小さくなるよう調整してみました。
NATRとは
NATRとは、ATRをcloseで割って100を掛けて作ってあるものです。
バックテストの改造
ポジションの大きさを変えたいのでバックテストを少しだけ改造します。
def backtest(cl=None, hi=None, lo=None, pips=None,
buy_entry=None, sell_entry=None,
buy_cost=None, sell_cost=None,
pos_size=None, # 追加
):
n = cl.size
y = cl.copy() * 0.0
poss = cl.copy() * 0.0
ret = 0.0
pos = 0.0
if pos_size is None: # 追加
pos_size = cl.copy()*0.0+1.0 # 追加
for i in range(n):
prev_pos = pos
# exit
if buy_cost[i]: # 買い
vol = np.maximum(0, -prev_pos)
ret -= buy_cost[i] * vol
pos += vol
if sell_cost[i]: # 売り
vol = np.maximum(0, prev_pos)
ret -= sell_cost[i] * vol
pos -= vol
# entry
if buy_entry[i] and buy_cost[i]:
# 変更
# vol = np.minimum(1.0, 1 - prev_pos) * buy_entry[i]
vol = np.minimum(1.0*pos_size[i], 1 - prev_pos) * buy_entry[i]
ret -= buy_cost[i] * vol
pos += vol
if sell_entry[i] and sell_cost[i]:
# 変更
# vol = np.minimum(1.0, prev_pos + 1) * sell_entry[i]
vol = np.minimum(1.0*pos_size[i], prev_pos + 1) * sell_entry[i]
ret -= sell_cost[i] * vol
pos -= vol
if i + 1 < n:
ret += pos * (cl[i + 1] / cl[i] - 1)
y[i] = ret
poss[i] = pos
return y, posspos_sizeの配列を渡せるようにしました。
サイズの決定方法
改良したbacktestのpos_sizeに渡すやつを作ります。
df['pos_size'] = 1.0*np.minimum(df['NATR'].values, t)/tNATRの閾値tを上限に、NATRの値によってポジションが小さくなるような0~1の配列ができます。ちなみに、ポジション変更なしの場合は
df['pos_size'] = 1.0でいけます。
閾値tの決定方法
雑ですが、
df['NATR'].mean()で平均を出すと0.489と出てきたので、切りよくt=0.5にしてみます。

t = 0.5
df['pos_size'] = 1.0*np.minimum(df['NATR'].values, t)/tバックテスト
閾値を基準にポジションを小さくするだけなので、バックテストのグラフの形はあまり変わりません。リターンは8.117437から8.280866に若干増えました。よく見ると、最初のボラがない時期にポジションを小さくすることで損失を押さえていたようです。最終のリターンはあんまり変わってないので、ボラがある時期では逆効果なのかもしれません。


ポジションサイズを確認する
df['poss']にサイズが格納されているので、df['poss'].plot()で見ることができます。
直近3000本のポジションサイズを見てみます。ボラが大きいのでほぼフルポジになっています。
df.loc[df.index[-3000]:df.index[-1],'poss'].plot(figsize=(50,10))
次に最初の頃のボラが小さいときの3000本をプロットしてみます。結構サイズを調整してくれていることが分かります。
df.loc[df.index[0]:df.index[3000],'poss'].plot(figsize=(50,10))
実際に運用するときにロット調節しないとだめなのは出来高の小さい日本の取引所でやる場合か、えぐいばけもんロットを積むガチでヤバい人だと思います。もっと正確にやるならvolumeとかから作った方が良さそうに思います。
ドローダウンを調べてみる
これでできます。figsizeを50,10にしておくと横長になって見やすくなります。
df['DD'] = df['cum_ret']-df['cum_ret'].cummax()
df['DD'].plot(figsize=(50, 10))
plt.grid()
plt.show()
ローソク足を詳しく見てみる
コードに自信がありません。
15分足
時間足の高値安値が1時間のうちどの辺で発生しやすいのかを調べてみました。
df_high_arg = df['hi'].rolling(4).apply(np.argmax)
df_low_arg = df['lo'].rolling(4).apply(np.argmin)
df_high_arg.resample('1h',offset='45min').last().plot(kind='hist', bins=4)
plt.show()
df_low_arg.resample('1h',offset='45min').last().plot(kind='hist', bins=4)
plt.show()15分足を4本分rollingして最大値と最小値のインデックスを取得します。この状態だと1時間ピッタリのrolling以外のargmaxを調べてしまった列があるので、rolling(4)で00分,15分,30分,45分をrollingできている、45分のindexの列だけ取り出します。


どっちも最初の15分で高値安値を取りやすいようです。
1分足
15分足の4本のヒストグラムだとよくわからないので1分足でもやってみました。これは1分足のデータを使っているので別途ダウンロードするなどしてください。
df_high_arg = df['high'].rolling(60).apply(np.argmax)
df_low_arg = df['low'].rolling(60).apply(np.argmin)
df_high_arg.resample('1h', offset='59min').last().plot(kind='hist',bins=60)
plt.grid()
plt.show()
df_low_arg.resample('1h', offset='59min').last().plot(kind='hist', bins=60)
plt.grid()
plt.show()

これで1時間のうちのどのあたりで高値安値を取っているのかが分かりました。1時間の区切りの前後が最も転換しやすく、次に15分毎に転換しがちなようです。
とくにhighの方が特徴的な形になっていました。このとがっている部分を掘っても良いのかもしれませんが、逆に、ぱっとみ20~30分ではhigh側もlow側も転換しにくそうなので、この時間限定で順張りするようなbotとか面白いかもしれません。
値幅で見てみた
同じ1分足のデータで高値安値ではなく、値幅も見てみました。最大値の場所と最小値の場所で調べてみました。
df_diffmax_arg = df['close'].pct_change(1).rolling(60).apply(np.argmax)
df_diffmin_arg = df['close'].pct_change(1).rolling(60).apply(np.argmin)
df_diffmax_arg.resample('1h', offset='0min').last().plot(kind='hist', bins=59)
plt.grid()
plt.show()
df_diffmin_arg.resample('1h', offset='0min').last().plot(kind='hist', bins=59)
plt.grid()
plt.show()

maxとminがほとんど同じ場所で盛り上がっています。よくわからない。合ってるんかこれ?
その他
同じようにヒゲの長さとかvolumeとかも見ると面白いかもしれないと思いました。
最適化してみた
DEAPというpipでインストールできるやつを使って最適化してみました。コピペしたサイトによると、自分が作ったやつは遺伝的アルゴリズムというものを使っているようでした。よくわかってないです。

DEAPを使うメリット
DEAPでポンとまではいきませんが、DEAPでポポポポポポポポポポンくらいにはなりました。今までfor文をブンブン回すなどしていたので、個人的にはかなり進歩したと思います。
最適化した変数
今回は指値を作る際の指標の窓の大きさ、指値幅2つで作ってみました。自分が実際に最適化したときは、作った指値(のどれがいいのか)、指値を作る際の指標の窓の大きさ、指値幅の三つを最適化してました。
3つくらいならfor文回した方がいい気もしますが、そういうのはあまり考えないようにします。
目的関数
最適化ではMLを使わずに全てエントリーするという条件でバックテストしてみました。
目的関数は色々試した結果、リターンの最大化よりエラー率やp平均法で求められる数値の最小化の方が良さそうな感じがしました。
目的関数は複数設定できます。
今回はエラー率とp平均法で求められる数値をオーバーフィット最小化してみました。
DEAPのコードの参考
https://dse-souken.com/2021/05/25/ai-19/
https://qiita.com/tyoshitake/items/e76f6f8e4110731606bc
実装
まず、evalという、評価するための関数を作ってその中にメインの部分をコピペします。今回はerror_rateとp_meanを最小化してみます。individual[0]に指値距離、individual[1]に窓を設定することにして、これらをDEAP君に最適化してもらいます。
# train用のデータをコピーして最適化に使う。
df = pd.read_pickle('df_features.pkl')
df_all = df.copy()
train = pd.to_datetime('2021-04-01 00:00:00Z')
df_train = df[df.index < train].copy()
def eval(individual, df_e=df_train, pips=pips):
# individual[0]が指値距離 (0.01<individual[0]<2.0)(float)
# individual[1]が窓 (2<individual[1]<100)(切り捨ての整数)
# 想定の範囲外の場合、適当に多き数字を返すようにする。
# returnの最後にはかならず,を付ける
if individual[0]*2 < 0.01 or int(individual[1]*100) < 2:
return 1000, 1000,
# ATRで指値距離を計算します
df_e['ATR'] = talib.ATR(df_e['hi'].values, df_e['lo'].values, df_e['cl'].values, timeperiod=int(individual[1]*100))
limit_price_dist = df_e['ATR'] * individual[0]*2
# ここからコピペ--------------------------------------------------------
limit_price_dist = np.maximum(1, (limit_price_dist / pips).round().fillna(1)) * pips
# 終値から両側にlimit_price_distだけ離れたところに、買い指値と売り指値を出します
df_e['buy_price'] = df_e['cl'] - limit_price_dist
df_e['sell_price'] = df_e['cl'] + limit_price_dist
# Force Entry Priceの計算
df_e['buy_fep'], df_e['buy_fet'] = calc_force_entry_price(
entry_price=df_e['buy_price'].values,
lo=df_e['lo'].values,
pips=pips,
)
# calc_force_entry_priceは入力と出力をマイナスにすれば売りに使えます
df_e['sell_fep'], df_e['sell_fet'] = calc_force_entry_price(
entry_price=-df_e['sell_price'].values,
lo=-df_e['hi'].values, # 売りのときは高値
pips=pips,
)
df_e['sell_fep'] *= -1
horizon = 1 # エントリーしてからエグジットを始めるまでの待ち時間 (1以上である必要がある)
fee = df_e['fee'] # maker手数料
# 指値が約定したかどうか (0, 1)
df_e['buy_executed'] = ((df_e['buy_price'] / pips).round() > (df_e['lo'].shift(-1) / pips).round()).astype('float64')
df_e['sell_executed'] = ((df_e['sell_price'] / pips).round() < (df_e['hi'].shift(-1) / pips).round()).astype('float64')
# yを計算
#df_e['y_buy'] = np.where(
# df_e['buy_executed'],
# df_e['sell_fep'].shift(-horizon) / df_e['buy_price'] - 1 - 2 * fee,
# 0
#)
#df_e['y_sell'] = np.where(
# df_e['sell_executed'],
# -(df_e['buy_fep'].shift(-horizon) / df_e['sell_price'] - 1) - 2 * fee,
# 0
#)
# バックテストで利用する取引コストを計算
df_e['buy_cost'] = np.where(
df_e['buy_executed'],
df_e['buy_price'] / df_e['cl'] - 1 + fee,
0
)
df_e['sell_cost'] = np.where(
df_e['sell_executed'],
-(df_e['sell_price'] / df_e['cl'] - 1) + fee,
0
)
df_e_copy = df_e.dropna().copy()
# ポジションは調整する
#df_e['pos_size'] = 1.0 *np.minimum(df_e['NATR'].values, 0.5)/0.5
# MLは使わず、全てエントリーした結果を最適化する
df_e_copy['y_pred_buy'] = 1.0
df_e_copy['y_pred_sell'] = 1.0
# バックテストで累積リターンと、ポジションを計算
df_e_copy['cum_ret'], df_e_copy['poss'] = backtest(
cl=df_e_copy['cl'].values,
buy_entry=df_e_copy['y_pred_buy'].values > 0,
sell_entry=df_e_copy['y_pred_sell'].values > 0,
buy_cost=df_e_copy['buy_cost'].values,
sell_cost=df_e_copy['sell_cost'].values,
#pos_size = df_e['pos_size'].values,
)
#ここまでコピペ---------------------------------------------------
x = df_e_copy['cum_ret'].diff(1).dropna()
#t, p = ttest_1samp(x, 0)
p_mean_n = 5
p_mean = calc_p_mean(x, p_mean_n)
error_rate = calc_p_mean_type1_error_rate(p_mean, p_mean_n)
# returnの最後にはかならず,を付ける
return error_rate, p_mean,
#色々設定できるよ-----------------------------------------------
#df_e_copy['DD'] = df_e_copy['cum_ret']-df_e_copy['cum_ret'].cummax()
#return df_e_copy['DD'].cumsum().at[df_e_copy.index[-1]],
#dd = list(np.where(df_e_copy['DD'] >= 0.0)[0])
#dd.append(len(df_e_copy))
#dd = np.diff(dd)
#return dd.max(),
#cum_ret = df_e_copy.at[df_e_copy.index[-1], 'cum_ret']
#return cum_ret,
次にdeapのアレコレをimport
import random
from deap import base
from deap import creator
from deap import tools色々なパラメータの設定。POPを減らすと時間短くなります。
#乱数の固定
random.seed(1)
#何世代まで行うか
NGEN = 10
#集団の個体数
POP = 100
#交叉確率
CXPB = 0.9
#個体が突然変異を起こす確率
MUTPB = 0.2さらに、なんかDEAP独自の関数の設定をしていきます。
toolbox.register()には、最初の文字列が関数名、次が実行する関数、その後に実行する関数の引数をいれます。
例えば
toolbox.register("attribute", random.uniform, 0, 1)
とすると、toolbox.attributeを実行した際、random.uniform(0,1)を実行してくれるようになるらしいです(?)
よくわかってないですが動きます。大丈夫。大丈夫です。
#最小化問題として設定
creator.create("FitnessMin", base.Fitness, weights=(-1.0, -1.0,))
#個体の定義。
creator.create("Individual", list, fitness=creator.FitnessMin)
#各種関数の設定を行う
toolbox = base.Toolbox()
#random.uniformの別名をattribute関数として設定
toolbox.register("attribute", random.uniform, 0, 1)
#attributeを2回やって返す関数をindividualとして定義。これで変数を作成する
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attribute, 2)
#集団の個体数を設定するための関数を準備
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
#トーナメント方式で次世代に子を残す親の数
toolbox.register("select", tools.selTournament, tournsize=3)
#交叉関数の設定。一点交叉を採用
toolbox.register("mate", tools.cxOnePoint)
#突然変異関数の設定。indpbは各遺伝子が突然変異を起こす確率
toolbox.register("mutate", tools.mutUniformInt, low=0, up=1, indpb=MUTPB)
#評価したい関数
toolbox.register("evaluate", eval)そして最適化をします。ポンッ!!!!
# 時間かかる
# 最初の個体
pop = toolbox.population(n=POP)
print("Start of evolution")
fitnesses = list(map(toolbox.evaluate, pop))
for ind, fit in zip(pop, fitnesses):
ind.fitness.values = fit
print(" Evaluated %i individuals" % len(pop))
for g in range(NGEN):
print("-- Generation %i --" % g)
offspring = toolbox.select(pop, len(pop))
offspring = list(map(toolbox.clone, offspring))
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < CXPB:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < MUTPB:
toolbox.mutate(mutant)
del mutant.fitness.values
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
print(" Evaluated %i individuals" % len(invalid_ind))
pop[:] = offspring
fits = [ind.fitness.values[0] for ind in pop]
length = len(pop)
mean = sum(fits) / length
sum2 = sum(x*x for x in fits)
std = abs(sum2 / length - mean**2)**0.5
print(" Min %s" % min(fits))
print(" Max %s" % max(fits))
print(" Avg %s" % mean)
print(" Std %s" % std)
print()
b_ind = tools.selRandom(pop, 20)
print('random_ind')
for i in b_ind:
print(f'{float(i[0]*2):.4f}, {int(i[1]*100)}')
best_ind = tools.selBest(pop, 1)[0]
print(f'{float(best_ind[0]*2):.4f}, {int(best_ind[1]*100)}, {best_ind.fitness.values}')
print()
print()
print("-- End of (successful) evolution --")
best_ind = tools.selBest(pop, 1)[0]
print(f"Best individual is {best_ind}, {best_ind.fitness.values}")
print(f'{float(best_ind[0]*2):.4f}, {int(best_ind[1]*100)}, {best_ind.fitness.values}')ポンッ!!!!
にはかなり時間がかかります。
結果
訓練用データで最適化した結果、指値距離は0.6425、窓は84となりました。魔法の数字です。
結果の検証
では最適化した結果を訓練用データとテストデータに適用して観察してみます。
まずはデフォルトのMLなし、指値距離0.5、窓14の結果です。


今年から凄くしんどそうだなという印象です。
訓練用データでのエラー率は0.0176 p平均法の数値は0.232でした。
しかし、DEAPにはこのグラフを右肩上がりにする偉大なる ”チカラ” があります。みんな信じて。
では、行きます。こちらがMLなし、訓練用データで最適化したパラメータの結果です。
ワクワク…!!
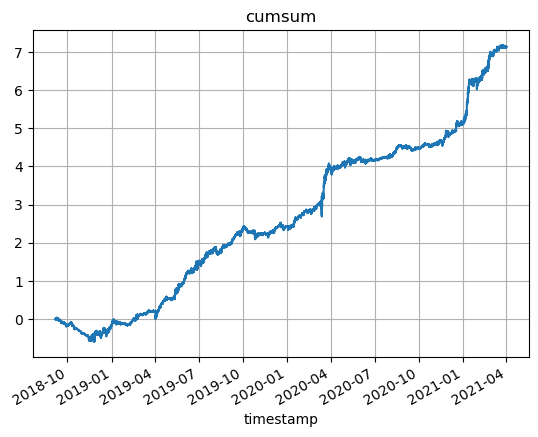
最適化に使用した期間のデータでのバックテストはいい感じです✨✨
初期の方のドローダウンが小さくなっています!
エラー率は0.00283となり1/5以下、p平均法は0.161となり確実に小さくなています!
これは検証用データのバックテストにも期待できますね!
検証用データのバックテストは….

お…?ちょっと良くなってる…?なんかでも思ったよりあんまり…
と思ったそこのあなた。
大丈夫です。まだMLを適用してないので。
我々はまだ力を残している。
それではMLを適用してみましょう。
3 2 1 …. ぁ~~ヨイショ!!!!
ソレイケ!!!! ポンッ!!!!


質疑応答タイム
DEAPでポンとは?
DEEPでポンのオマージュです。
この分野では素人なのですが…
お帰りください。
素人質問で恐縮ですが…
こちらにポロリするまで出られない部屋がございます。
それでPDPを見るとどんなことが分かるんですか?
知りません。
機械学習モデルの解釈手法にはPDP以外にもPFIやSHAPなどがありますが…
知りません。
それって本当に最適化と言えるんですか?
はい。私が最適化だと言えばそれは最適化になります。
ロット調整は本当に部分約定に効果があるんですか?根拠はあるんですか?
わかりません。根拠はございません。
全体の通しのプログラムファイルはありますか?
殴り書きしただけなので動くかわからないですが、あります。
おわり
この記事が気に入ったらサポートをしてみませんか?