
IMPORTXML でスクレイピング!

この記事でネタにする「スクレイピング」は、
ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。
というものです。今回は、Google スプレッドシートで利用できる IMPORTXML という関数を用いて、簡単なスクレイピングを行ってみます。
IMPORTXML とは?
IMPORTXML は、以下のヘルプ記事で説明されている Google スプレッドシートで利用できる関数です。Microsoft Excel には実装されていない Google スプレッドシート独自の関数です。
構文
IMPORTXML(URL, XPath クエリ)
URL - 検証するページの URL です。プロトコル(http:// など)も含めます。
URL の値は二重引用符で囲むか、適切なテキストを含むセルへの参照にする必要があります。
XPath クエリ - 構造化データで実行する XPath クエリです。
XPath について詳しくは、http://www.w3schools.com/xml/xpath_intro.asp(英語)をご覧ください。
実際にやってみる!
(1)今回のターゲット
今回のスクレイピングの対象は、以下のサイト(ページ)です。

上図のような CDTV による今週のランキングが表示されているページをスクレイピングして、そのデータを Google スプレッドシートに取り込んでみます。
(2)実際にチェックするページのデータを見てみると…
スクレイピングの対象となるページのソース(HTML)を確認してみると、取り込みたいランキング部分は、下図のようになっています。
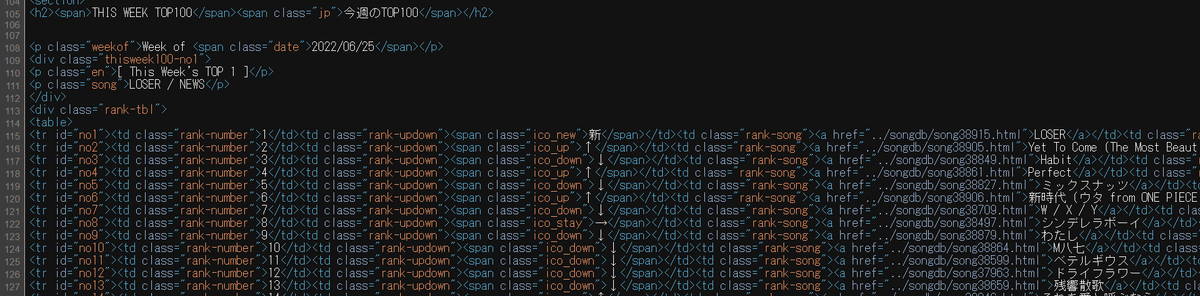
例えば、上図のランキングの表を定義している部分を見てみると、表の 1列目は下図のように
<td class="rank-number">
となっています。この class の値を利用して、表のデータを取り出してみようと思います。
(3)IMPORTXML を使ってみる
セル A4 に、次のような数式を設定します。
=IMPORTXML($B$1,"//*[@class='rank-number']")上記の数式は、以下の URL などを参考にしながら、試行錯誤してたどり着いたものです。
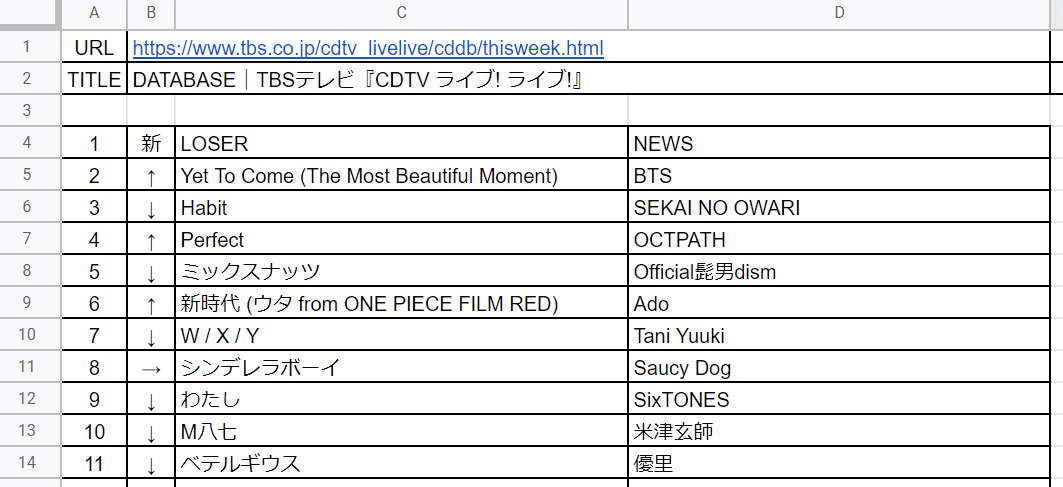
この数式を入力すると、セル B1 に入力されている URL にアクセスして、下図のように表の 1列目の内容を取り出せました。
下図では 10位までの内容となっていますが、実際にはセル B1 のページにあるように、100 までの数字が取得できました。

2列目も同様に HTML を確認すると、class の値は「rank-updown」となっていました。

1列目と同様に、セル B4 に
=IMPORTXML($B$1,"//*[@class='rank-updown']")と設定すると、下図のように先週のランキングとの比較が表示されました。

更に、同様に 3列目と 4列目も簡単に取得できました。
(4)取得したデータを加工
前項までで、Web ページの内容を、Google スプレッドシートに取り込めました。スプレッドシートに取り込めれば、その後は更に数式で加工したり、下図のように「条件付き書式」で体裁を整えたり、といったことも可能です。

注意点
理屈がわかっていれば、Web ページから必要な情報だけを抽出できるので、便利な技術・テクニックなのですが、サーバー側にしてみると機械的なアクセスとなるので、アクセス先によってはアクセスが拒否されてしまうケースも存在します。そのような場合には諦めるしかありません。
また、アクセス先のページの構造が変更になった場合には、IMPORTXML の引数を見直し、変更しなければなりません。
この辺りに留意した上で、利用できる範囲で利用して、作業を効率化して楽をするのがいいと思います!
この記事が気に入ったらサポートをしてみませんか?