
CLIP Text Deprojectorを使って画像生成してみる ~モデルアーキテクチャのさらなる改良~

前回は学習率(learning rate)の調整をしましたが、今回はよりよい性能を求めてモデルアーキテクチャを改良してみます。
前回の記事
他のStable Diffusionの関連記事
Layered Diffusion Pipelineを使うためのリンク集
ライブラリの入手先と使用法(英語) : Githubリポジトリ
日本語での使用方法の解説 : Noteの記事
モデルアーキテクチャ
現在使用しているモデルアーキテクチャは、下の記事で導入した改良版となっています。
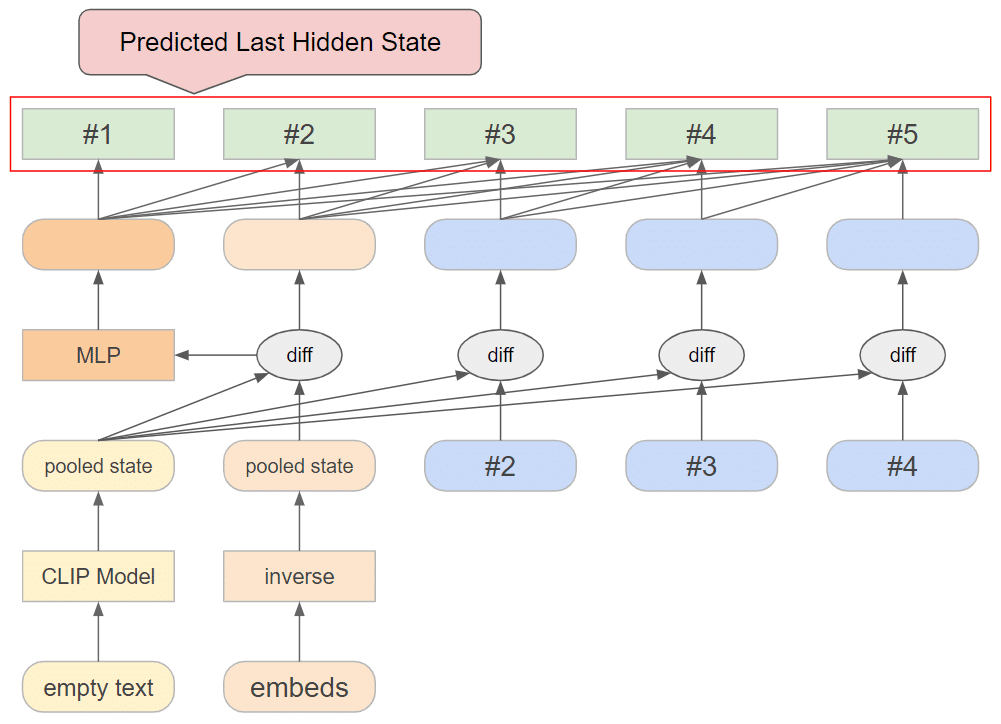
入力値の変更
今回注目したのは、transformerレイヤへの入力値です。現在は、transformerレイヤの出力値を1つずつずらして入力値としています。実際には出力値から空文字列のembeddingを引き算していますが、空文字列のembeddingは定数なので、事実上は出力値をそのまま入力値として渡しているのと同じです。
まず試したのは、出力値をそのまま入力値とするのではなく、まず出力値の値を隣同士で引き算して、その結果を入力値とする方式です。これは、last hidden stateの隣同士の差分のところに、その位置に対応するトークンの純粋な情報が含まれていると考えられるためです。

2つ目に試したのは、現行のアーキテクチャと新アーキテクチャの合成を行うため、現行アーキテクチャの入力値と新アーキテクチャの入力値、さらに入力embeddingを全てベクトル連結して、全ての要素を線形結合したものを新たな入力値としました。

出力値の変更
さらに、出力側でも変更を試しました。残差接続の考え方を用いて、次の2種類のモデルのバリエーションを作りました。
transformerレイヤの出力値を前トークンのlast hidden stateに加算する
transformerレイヤの出力値をtransformerレイヤの入力値に加算する


生成画像の比較
入力値の変更
まずは入力値の変更を行ったモデルについて、生成画像の比較を行いました。今回はアンサンブルモデルではなく、単体モデルを使って比較を行っています。
最上段はdeprojectorなし、2段目は出力値をずらして入力値とする現行のアーキテクチャ、3段目は出力値の差分を入力値とする新アーキテクチャ、4段目は両方の入力値を線形結合したもう一つの新アーキテクチャです。


単一embeddingの方では現行アーキテクチャと新アーキテクチャの違いはあまり大きくありませんが、複数embeddingの合成では新アーキテクチャの方が1段目のdeprojectorなしの画像に近い画像が生成されています。
3段目(出力値の差分)と4段目(線形結合)との比較では、4段目の方がややプロンプトの内容をより正確に反映しているようです。
出力値の変更
次に、残差接続を用いた出力値の変更を行ったモデルについて、生成画像の比較を行いました。使用した新アーキテクチャは、全て線形結合を用いた入力値を用いています。
最上段はdeprojectorなし、2段目は残差接続なし、3段目は前トークンの出力との残差接続、4段目は入力値との残差接続を用いたモデルとなっています。


単一embeddingでも複数embeddingの合成でも、残差接続を用いたモデルアーキテクチャで明らかな改善は見られませんでした。
まとめ
transformerレイヤの入力値に、現行モデルの入力値に加え、transformerレイヤの出力値の隣同士の差分と、入力embeddingをベクトル連結して全要素線形結合したものを用いる、新アーキテクチャを用いることで、複数embeddingの合成に対する生成画像の質が向上しました。
transformerレイヤの出力側に残差接続を用いる方法は、生成画像の質に大きな影響を与えませんでした。
なお、今回試した新アーキテクチャの入力値の計算には不要な計算が含まれているため、計算式を整理して簡略化を行う必要があります。
この記事が気に入ったらサポートをしてみませんか?