
北京冬季五輪とTwitter -1万4千ツイートをAIで手軽に分析してみよう

このnoteでは北京冬季オリンピックの開催を受け、Twitterユーザーがどんな話題に興味関心を示しているのかについてAIを用いた簡単な分析を行い、Twitterにおけるオリンピックへの熱狂の実態を明らかにするともに、専門的な知識のない人でも手軽にAIを使ったツイート分析が可能な方法をご紹介します。
2月4日、北京冬季オリンピックが開催されました。これで北京は世界で初めて夏のオリンピックと冬のオリンピックが開催された年になります。新型コロナウィルスの感染拡大など懸念されていた事項がありましたが、無事対策に尽力しての開催となりました。日本人選手はウィンタースポーツも競合選手が揃っています。メダル獲得に期待したいですね。
また開会式も夏のオリンピックに比較すると大幅に規模を縮小しての実施となりましたが、北京らしさを感じる完成度の高いものでした。多くの人はこれから選手たちが織り成すドラマへの期待に胸を膨らませたのではないでしょうか。また、そうした盛り上がりはSNSの投稿として現れます。特に投稿が短文であるが故に即時性の高いTwitterでは、ツイートを分析することで人々がオリンピックのどんなことに興味を持っているかが分かります。
テキストマイニング
こうした分析ではテキストマイニングという手法を用いることが多いです。Twitterに寄せられた特定のキーワードを含むツイートのテキストをデータとして収集し、そしてそれをテキストマイニングで分析します。

テキストマイニングとは、文字列のデータマイニングのことで、単語などをテキストから抽出し、出現の頻度や関係性を分析することができます。テキストマイニングが画期的なのはAIを駆使した自然言語処理を活用している点です。たとえば、ただ単に頻出する文字列を抽出するだけでは、「てをはに」といったどんな文章にも用いられる表現のみがヒットしてしまい、分析に使えるデータを得ることができません。したがって、名詞や形容詞など単語を抽出することで、より分析が容易になります。
このテキストマイニングの技術を活用してツイートを分析してみたいと思います。
調査方法
調査方法はいたってシンプルです。まず、北京五輪に関するツイートをなるべく大量に取得します。この際は北京五輪キーワードを含むツイートを対象にしたいと思います。なるべく大量としたのは、TwitterのAPIによるツイートの取得に関して、一定時間内に取得できるツイート数の制限があるためです。またテキストマイニングを行うにはそれなりの処理能力を要します。データが膨大になればそれだけ分析が困難になってしまいます。具体的な数については使用するAPIやツールに沿って決めたいと思います。
そして北京五輪に関するツイートのデータを取得したら、今度はこれをテキストマイニングで処理し、それらのツイートにどんな言葉が登場しているのかを見てみます。これを明らかにすることで、Twitterユーザーが北京五輪のどんなことに関心を示しているかが分かります。
データの入手方法
データの入手にはTwitterのAPIを用います。APIによるツイートの取得には制限があり、一回のコールで最大100件、15分間で最大180コールと決まっています。つまり15分間で最大18000ツイートまで取得できます。
TwitterのAPIを使ってツイートするのはいたって簡単ですが、多少のコーディングが必要になります。ここでコーティングのできない人が手軽にツイートを取得する方法をご紹介します。
出典:https://torilab.sakura.ne.jp/twitter/searcher/index.html
「ホントレ検索β版」はTwitterのトレンドを分析するためのツールで、東京大学大学院工学系研究科の鳥海不二夫教授が無料で公開しています。「ホントレ検索β版」では無料で一度に18000ツイートを分析することができますが、今回はテキストマイニングが目的になるので、ツイートの取得に使用したいと思います。
またテキストマイニングには今回、環境やライブラリなどをゼロから自分で用意しているとかなり手間がかかってしまうので、ユーザーローカルさんが無料で提供している「AIテキストマイニングツール」を使用したいと思います。
出典:https://textmining.userlocal.jp/
「AIテキストマイニングツール」はテキストやファイルをアップロードするとバックエンドでテキストマイニングを実施してくれる大変便利なウェブサイトです。「AIテキストマイニングツール」を使って無料で分析できるのは20万文字までになります。だいたい1ツイートが最大140字として、おおよそ1万4千ツイートまで無料で分析することができます。
分析してみた
では分析してみましょう。非常に簡単なのでみなさんも一緒にトライしてみてください。
まず「ホントレ検索β版」にアクセスして、ツイートを取得します。キーワードを入力して、「最大収集ツイート数」を140に指定し、「検索」ボタンを押下します。ツイートの取得には少し時間がかかります。
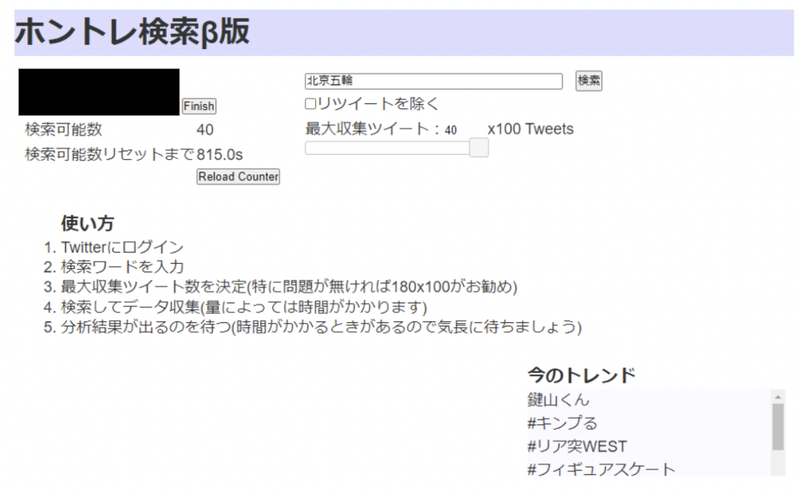
しばらくすると「Download CSV」というボタンが出現します。このボタンを押下することでツイートをCSVファイルとしてダウンロードすることができます。
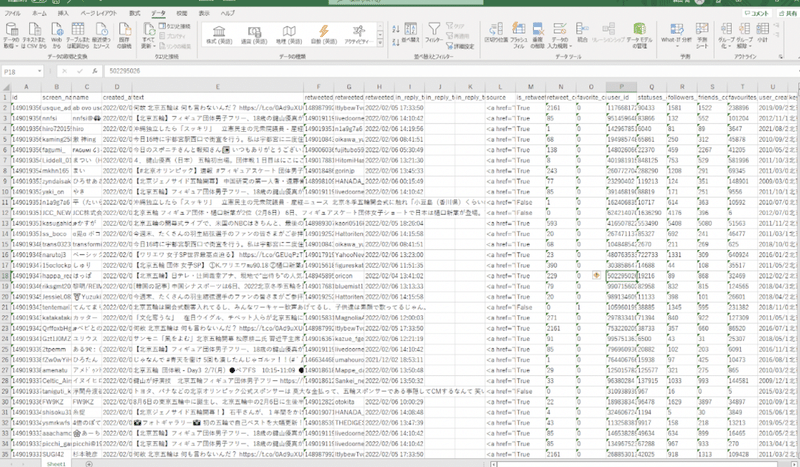
ダウンロードできたらCSVファイルを読み込んで、少し整理しましょう。このデータにはユーザーIDやタイムスタンプも含まれます。このままではツイート以外の情報が占める文字数が多く、後程行う「AIテキストマイニングツール」の上限文字数に達してしまうため、ツイート本文以外の情報は取り除いてしまいます。
それが終わったら、今度は「AIテキストマイニングツール」にアクセスします。「ファイルをアップロード」から先ほどのファイルをアップロードします。アップロードできたら、「テキストマイニングする」のボタンを押下し、結果が表示されるのを待ちます。
結果が出力されました!
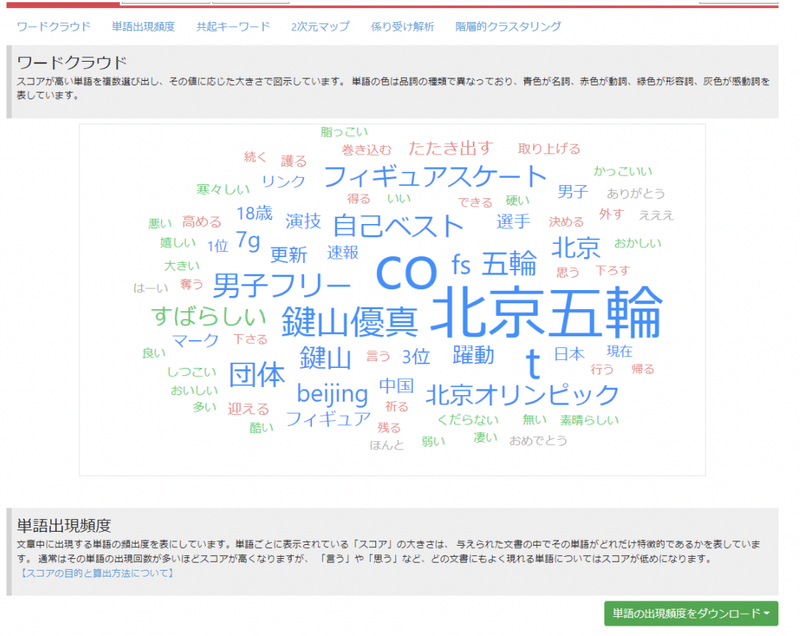
分析結果
まず「北京五輪」を含むツイートについて結果を見てみましょう

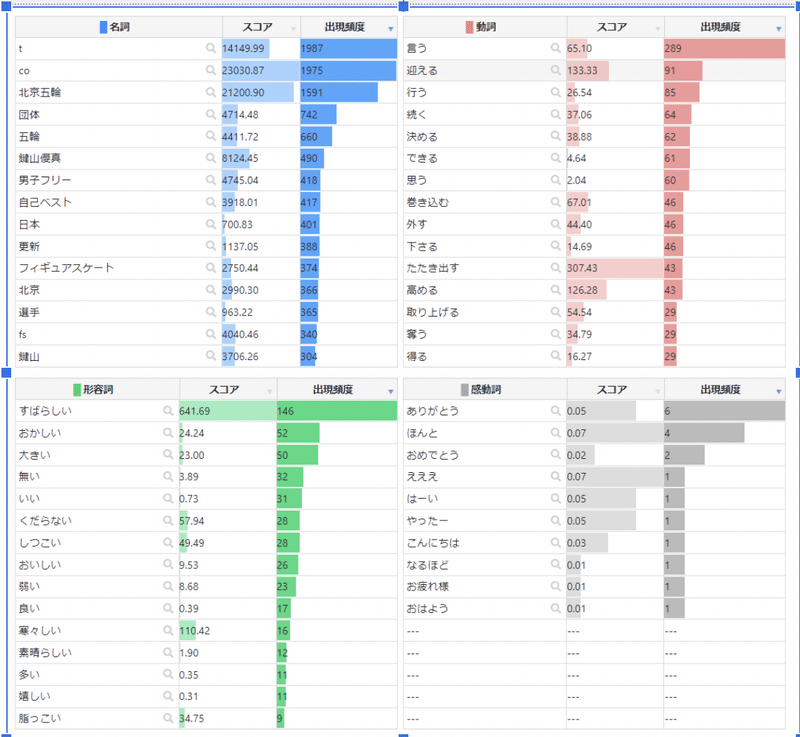
いずれも「AIテキストマイニングツール」の分析結果画面に表示された図になります。
名詞の分析結果については男子フィギュアスケートの鍵山優真選手への注目度の高さが伺える結果だったかと思います。当時、鍵山優真選手は初のオリンピック参加でありながら、自己ベストを更新し予選一位通過という素晴らしい成果を見せました。それだけ人々が感動したことを示していると言えるかと思います。
形容詞では「すばらしい」という言葉が圧倒的に多用されていました。これは何に対する形容なのでしょうか。
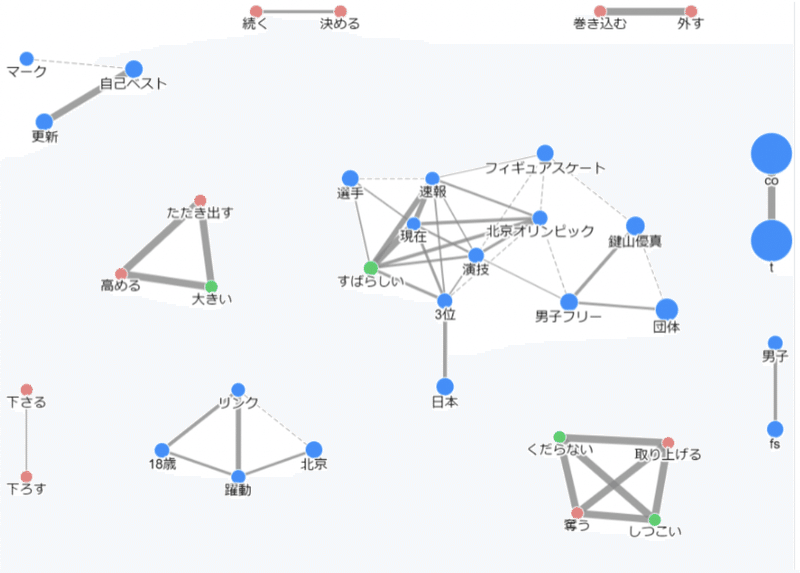
上の図は「AIテキストマイニングツール」の分析結果画面に出力された、頻出パターンの類似性を示したものです。上の画像から「すばらしい」は当時3位だったフィギュアスケート団体戦の日本チームの成果に対する形容だったことが伺えます。
やはりフィギュアスケートでの日本人選手の活躍は例年通り著しく、人々の感動がツイートの分析から見て取れますね。こうした分析のメリットは、実際にどれくらいの人がどのような内容の投稿をしたのかを数字をもって知ることができる点です。タイムラインを見ていて、なんとなく肌感覚でどういった内容のツイートが多いかを知ることができても、それを数字化することはテキストマイニングなしには困難です。
今後の期待
こうした無料のツールを使って簡単にテキストマイニングが行えることは本当に素晴らしいと思います。またこうした分析結果はダウンロードも可能です。ぜひ手軽に調査結果が欲しい際に活用されてみたらいかがでしょうか。
この記事が気に入ったらサポートをしてみませんか?