
データから物事の原因を特定する 因果探索入門

因果探索とは、データに隠れた因果関係を見つけ出す統計的な手法です。
物事の因果、すなわち「原因」と「結果」をつなぐ関係性のことを因果関係といいます。例えば「喫煙と肺がんの関係」「気温とアイスの販売量」「睡眠時間と集中力」など日常生活においても因果関係をもつ事柄は多くみられます。
しかし因果関係はその重要性に対し、数理的な裏付けのないまま利用されることが多い用語です。
その原因としては因果探索自体の難しさももちろんありますが、そもそも因果関係は定性的データ(数値化が難しく、言葉で表すしかないデータ)であり数理的に解析することが無意味であると認識されていることが根本原因なのではないでしょうか。
この記事は、そんな因果関係を数理的に解析することのメリットおよび、簡単に利用できる因果探索ライブラリ「LiNGAM」を紹介することを目的とした因果探索の入門記事となっています。
因果関係と相関関係の違い
相関関係は、データの中で2つの変数が同時に変化する傾向があるという統計的な関係を指します。
因果関係は、2つの変数が同時に変化し、なおかつ一方の事象がもう一方の事象を引き起こすという直接の原因と結果の関係を指します。つまり相関関係のうち「直接の原因と結果」となっているものを因果関係といいます。
両者は混同されることも多く、「AとBの相関関係」を示しただけで「Aの原因はB」と断言されることもしばしばです。
しかし、このような相関関係と因果関係の混同は誤った結論を導き出してしまうこともあり注意が必要です。例えば次に示す「数学テストの点数と体重」の相関関係はその典型と言えるでしょう。
例:数学テストの点数と体重の相関
とある国にて、全国共通の数学テストが行われました。このテストでは簡単な四則演算から変数を用いた方程式の問題まで様々な難易度の問題が出題されます。
このテストを受験するのは15歳以下の子どもたちです。性別、学年、出身地を問わず受験してもらいます。
このテストの結果と子ども達のパーソナルデータ(身体能力や出生の情報などあらゆるデータが含まれています)を分析し、数学の能力が高い子どもはどういった特徴を持っているか割り出そうというわけです。
そして目論見通りパーソナルデータの中から「子ども達の体重のデータ」がこの数学テストの良否に関連性があることが判明しました。
体重が50kgぐらいの子どもは方程式など複雑な問題を解くこともできる
体重が25kgぐらいの子どもは掛け算など簡単な問題もできない者が多い
子どもの体重が増加するにつれてテストの点数も向上している
このテスト結果のデータだけから結論を出すならば、「体重が重い子どもは数学の学力テストの結果が良い」と言えそうです。
ではこの結果をもとに「数学の学力テストの点を上げるため、ご飯をいっぱい食べさせる」、またはその逆に「ダイエットのため、数学の勉強を一切しない」といった行動をとるのは正しいといえるでしょうか?

答えはもちろん『NO』です。なぜならば数学的能力と体重には何の関係もありません。体重が重いからといって数学の学力が向上するわけではなく、あくまで両者は独立した事柄なのです。
常識的に考えるとこれらの行動はなんだか奇妙な発想に感じますね。
これこそが「相関関係」と「因果関係」の違いを表しています。
つまり、データ上で関係のある事柄たちであっても(相関関係を持つ)、実際にそれらが原因と結果の関係にある(因果関係を持つ)かどうかは別問題なのです。
この数学テストと体重のようにデータ上では関連が見られるが、実際には直接の因果関係がない状態(因果関係のない相関関係)のことを疑似相関といいます。疑似相関の裏側には、それらの関係を説明するための「本当の原因」が隠れています。
「数学テストの点数と体重の相関関係」の本当の原因
実はネタを明かすと「25kg」というのは小学1年生の平均体重で、「50kg」は中学1~2年生の平均体重です。
学年が上がっていけば、成長期にある子どもの身体は成長していきます。例えば小学生期間においては子どもの身長は1年で平均約5~6cm増加します。また筋肉量や骨密度といった体成分の指標もまた成長に伴い増加していきます。
その結果、学年が上がるにつれて体重の数値は増加することになり、基本的には減少することはありません。
また学年が上がるほど、算数や数学の授業を受けるトータルの時間が増え、小学1年生では解けなかった問題も解けるようになっていきます。
例えば、小学2年生では掛け算を、3~4年生では分数を用いた計算を、6年生では平均や比例・反比例といった抽象的な概念を学習します。
小学生と中学生が同じテストを受ければ、中学生の方が良い点数を取るのは必然と言えるでしょう。
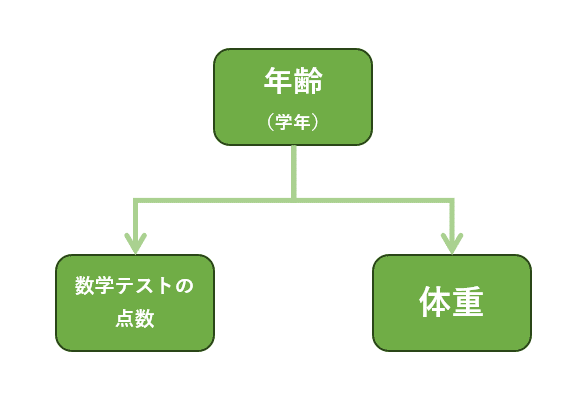
つまりこの例では「体重の増加が原因で数学力が向上する」のではなく、「学年の昇級が原因で数学力が増加する」と「学年の昇級が原因で体重が増加する」という現象が同時に起きていたのです。
考えてみれば実に簡単なトリックでした。これを読んでいる人の中には解説を読むまでもなく予測できた方も多いかもしれませんね。
では、現実の問題では?
さて、この「年齢、学力、体重」の例では、我々の常識を働かせることで「学力は体重によって決まる」という主張に違和感を覚え、「学力、体重の値は年齢によって大きく左右される」という真実味のある原因を思いつくことができました。
ですが、この解決方法はいくつかの問題点があります。
問題①:現実の問題の複雑さ
現実の問題はより複雑です。原因と結果が1対1で結びついているとは限らず、「○○の原因は△△だ」とはっきりと断言できる場面はむしろ稀だと考えられます。
多くの問題では要因は一つではなく、複数の要因が互いに結び付いてひとつの結果を生み出します。このような問題では因果関係を正確に把握することは複雑で難しいものとなります。
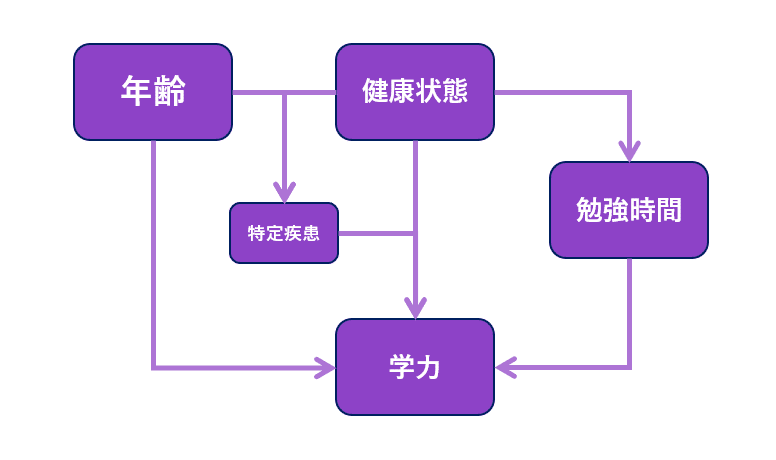
例えば、学力に影響を与える要因が「年齢」「勉強時間」「健康状態」など複数存在する場合、単純に原因を発見するだけでなく、以下のようなことも考えなくてはならないでしょう。
3つの要因のうち、どれが最も影響が大きいか?
ある要因が他の要因に影響を与えていないか?(例:健康状態が悪化することにより勉強時間が確保できなくなる)
特定の状態が重なった時だけ発生する現象はないか?(例:「年齢=6歳以上」で「健康状態=おたふく風邪」になったとき重症化リスクが高まる)
このように複数要因の存在する問題の場合、要因同士の大小関係や相互関係を踏まえて結論を出さなくてはならないため、要因が一つの問題よりも非常に複雑な問題となってしまいます。
さらに言えば、たとえどれだけ複雑であっても、そのデータの中から本当の原因となる項目にたどり着けるならば幸運な事例と言えるかもしれません。
実際には調査したデータの項目の中に本当の原因となる項目が入っていない場合もあるからです。これを潜在変数と言います。

例えば「学力は家庭環境に影響を受けるが、その家庭環境の中で何が影響を与えているか観測できない」といった事例では「家庭環境を構成する観測不可能な因子たち」が潜在変数となります。
潜在変数が存在する場合、当然ながら因果関係は正確に理解できません。
問題②:人間の知識量の限界
我々の経験や直感の及ばない高度な内容だった場合には、当然ながらこの方法は使うことはできません。
例えば「『血液のプロトロンビン時間』と『学力』に関係性があることが判明!」と主張するニュース記事を読んだときに、自分の知識ではっきりと肯定or否定できる人は少ないと思われます。
(ちなみにプロトロンビン時間とは血液が凝固するまでの時間のことです。当然、学力とは関係がありませんのでご注意ください)
このように、専門知識がなければ理解することさえ難しいデータに対して違和感を覚えるのは容易ではありません。ましてや誤った主張に対して本当の原因を指摘することなど門外漢には不可能に近いでしょう。
さらに言えば、今までの常識を覆すような知見に対しては無力どころか、逆にマイナスの影響の方が大きくなる可能性もあります。
例えば、仮に先ほど誤った主張として例示した『体重』と『学力』の関係が実は本当に因果関係を持っていた場合どうでしょうか?現在の我々の常識で推し量ってしまえば、どれだけ観測データで示したとしても「常識的におかしい」の一言で否定してしまうことになるでしょう。
因果探索という解決策
これらの問題に対し、統計学を用いて解決を試みたのが因果探索です。
問題①への対策としては、因果関係の有無のみならず、因果関係の強さを数値的に表す必要があります。因子同士の関係性の強さを数値化できれば複雑な因果関係も理解しやすくなります。また、強い関係性の因子が存在しなければ間接的に潜在変数の存在を示すことができると考えられます。
問題②への対策としては、そのデータの文脈や専門知識、あるいは個人の勘や経験などに頼らず、観測したデータのみから因果関係を解き明かす方法が必要となります。
つまり因果探索とは、データを観測した際に「観測したデータのみから分析を行い」なおかつ「数値的に」因果関係を特定していく方法なのです。
因果探索は統計学の分野で研究が盛んに行われており、これまでに複数の因果探索手法が考案されています。
因果探索の代表的な手法
LiNGAM
ベイジアンネットワーク
因果グラフ
PCアルゴリズム
Graphical Lasso
これらの手法はそれぞれ異なる長所と短所を持っており、データの性質や目的によって適した手法が異なります。
これらの手法の中で最もシンプルで一番試しやすいのは、おそらくLiNGAMでしょう。pythonライブラリがあり、因果探索モデルを比較的簡単に実装することができます。
LiNGAMを使った因果探索
LiNGAMとは「Linear Non-Gaussian Acyclic Model」の略で、和訳すれば「線形非ガウス非巡回モデル」となります。
LiNGAMの特徴
線形な因果関係にモデル化するため、計算量が軽い。
小規模のデータでもそこそこの精度を出せる。
モデルの定義に仮定が多いため、適用可能なデータに制約がある。
LiNGAMの定義
LiNGAMが定義するモデルは以下のような条件で制約されています。
①(非巡回性)観測変数 $${x_i \in \lbrace1, \cdots ,m \rbrace}$$ は因果順序 $${k(x_i)}$$で並べ替え可能である。因果順序では任意の因果関係$${x_i \rightarrow x_j}$$に対し、$${k(x_i) < k(x_j)}$$が成立する。
観測変数 $${x_i \in \lbrace1, \cdots ,m \rbrace}$$ は因果順序 $${k(x_i)}$$で並べ替え可能である。因果順序では任意の因果関係$${x_i \rightarrow x_j}$$に対し、$${k(x_i) < k(x_j)}$$が成立する。
各変数 $${x_i \in \lbrace1, \cdots ,m \rbrace}$$ は自身より順序が前の変数$${x_1 | k(x_i) < k(x_j)}$$の線形和に、ノイズ $${e_i}$$および定数項$${c_i}$$加算した形で表すことができる。すなわち、
$${ x_i = \displaystyle{\sum_{k(x_i) < k(x_j)} b_{ij}x_j + e_i + c_i }}$$
ノイズ $${e_i}$$はすべて互いに独立かつ分散が非零であり、非ガウス分布をもつ連続値の確率変数である。
1.は非巡回性(Acyclic)という性質をモデルに与えます。
巡回とは「Aの原因はB」「Bの原因はC」「Cの原因はA」と無限ループが起こってしまうことです。こうなるとABCの全てが互いに原因であり結果であるという奇妙な因果関係が発生してしまいます。
そこでLiNGAMではモデルに非巡回性の条件を加えて、「原因⇒結果」の流れが一方通行になるようにしています。
2.は線形性(Linearity)という性質をモデルに与えます。
誤解を恐れず言えば、モデルをシンプルに考えるための性質です。計算がしやすくなります。
3.は少し複雑ですが、識別可能性(Identifiability)と呼ばれる性質をモデルに与えます。
識別可能性とは異なるパラメータを持つ2つのモデルが同一の分布を生成しない、つまり「前提条件となる因果関係の状態が異なるならば、得られる結果は必ず別物になる」ということを表します。
この識別可能性を満たしているならば、結果(観測したデータ)から前提条件となる因果関係を逆算したときに、確実に答えを1つの候補に絞ることが可能になります。
逆に識別可能性を条件に加えなければ、因果探索を行っても「『AがBの原因』もしは『BがAの原因』のどちらかです」のような曖昧な結論に陥る可能性があります。
この①~③の定義を満たすLiNGAMモデルに得られたデータを当てはめることで「無限ループのない」「シンプルな」「一意な」因果関係を導き出すことができるようになります。
LiNGAMの実装
DirectLiNGAMという手法を使いデータをLiNGAMモデルを学習していきます。
4つのライブラリ「numpy」「pandas」「graphviz」「lingam」をインポートし、以下のコードを実行します。
# ライブラリのインポート
import numpy as np
import pandas as pd
import graphviz
import lingam
from lingam.utils import make_dot
# 乱数設定
np.set_printoptions(precision=3, suppress=True)
np.random.seed(100)
# テストデータの作成
x3 = np.random.uniform(size=1000)
x0 = 3.0*x3 + np.random.uniform(size=1000)
x2 = 6.0*x3 + np.random.uniform(size=1000)
x1 = 3.0*x0 + 2.0*x2 + np.random.uniform(size=1000)
x5 = 4.0*x0 + np.random.uniform(size=1000)
x4 = 8.0*x0 - 1.0*x2 + np.random.uniform(size=1000)
X = pd.DataFrame(np.array([x0, x1, x2, x3, x4, x5]).T ,columns=['x0', 'x1', 'x2', 'x3', 'x4', 'x5'])
X.head()
# モデルの可視化
m = np.array([[0.0, 0.0, 0.0, 3.0, 0.0, 0.0],
[3.0, 0.0, 2.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 6.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[8.0, 0.0,-1.0, 0.0, 0.0, 0.0],
[4.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
dot = make_dot(m)
# DirectLiNGAMによる学習
model = lingam.DirectLiNGAM()
model.fit(X)
# 因果関係のグラフ表示
make_dot(model.adjacency_matrix_)備考:ライブラリ一覧
numpy == 1.16.2
pandas == 0.24.2
graphviz == 0.11.1
lingam == 1.5.1
コード実行後、以下のような因果関係グラフが可視化されます。
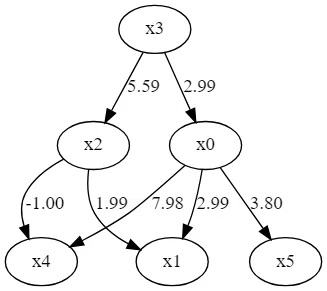
まとめ
以上が因果探索およびLiNGAMの解説となります。今回紹介したのはごく簡単なサンプルコードでしたが、因果探索の導入となれば幸いです。
最後までお読みいただきありがとうございました。
参考文献
A Linear Non-Gaussian Acyclic Model for Causal Discovery [Shimizu et al., 2006]
Welcome to lingam’s documentation!(LiNGAMライブラリ)
この記事が気に入ったらサポートをしてみませんか?