
Depth Pro+YOLO11でカメラと人物の距離の推定を試してみた

概要
Appleが発表した単眼深度推定モデルのDepth Proを試してみました。
Depth Proはゼロショットで実際の距離の推定ができる点が特徴です。
YOLO11のセグメンテーションモデルと組み合わせて、カメラと人物の距離を推定してみました。
高速な推論を謳っていますが、あまり速くはありませんでした。
Google ColabのL4インスタンスで810×1080のサンプル画像に2秒以上かかりました。
下の2つ目のリンクはデモページです。
実施内容
デモページでお試し
回数制限はあるようですが、デモページでDepth Proを試すことができました。
以下は試した結果の画像で、左側が入力画像、右側がデモページの出力画像です。






上手くいったものと、変な結果になっているものとがありました。
空や遠くの山など、距離が遠すぎるもの推定は難しそうです。
(特に空は推定結果よりはるかに遠い値になるべきかと思います)
右側の画像に表示された数値に単位 m がついていることから、距離を推定していることが確認できます。
デモページでは深度推定の他にも3Dモデルを生成できるようでした。
(使い方が悪いのかうまくできませんでした。)
Google Colabでカメラ~人物間の距離取得のお試し
Google Colab ProのL4で実行しました。
インストール
まずは下記の記事を参考に、Google ColabでDepth Proの実行環境を整えます。
!git clone https://github.com/apple/ml-depth-pro.git
%cd ml-depth-pro
!pip install -e .
!mkdir checkpoints学習済みの重みと使用する画像を取得します。
!wget -P checkpoints https://huggingface.co/apple/DepthPro/resolve/main/depth_pro.pt
!wget https://ultralytics.com/images/bus.jpg人物の検出で使用するので、YOLO11の環境も整えます。
!pip install ultralyticsお試しコード
下記のコードでグレースケールの深度推定結果を得ることができます。
depth_pro の import でエラーが発生したので、「from src import depth_pro」に変更しました。
また、深度推定結果の画像は見慣れた形式の 近:白 ~ 黒:遠 になるようにしています。
import numpy as np
from PIL import Image
import time
import torch
from src import depth_pro
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load model and preprocessing transform
dp_model, transform = depth_pro.create_model_and_transforms()
dp_model = dp_model.to(device)
dp_model.eval()
torch.cuda.synchronize(); start = time.perf_counter()
# Load and preprocess an image.
image, _, f_px = depth_pro.load_rgb("bus.jpg")
image = transform(image).to(device) # Move image to the same device as the model
# Run inference.
with torch.no_grad():
prediction = dp_model.infer(image, f_px=f_px)
depth = prediction["depth"] # Depth in [m].
focallength_px = prediction["focallength_px"] # Focal length in pixels.
np_depth = depth.squeeze().cpu().numpy()
torch.cuda.synchronize(); end = time.perf_counter()
print(f"Inference time: {end - start} sec")
# Save depth map
depth_normalized = (255 - (np_depth - np_depth.min()) / (np_depth.max() - np_depth.min()) * 255).astype(np.uint8) # depth map normalization
depth_map = Image.fromarray(depth_normalized)
depth_map.save("bus_depth_map.jpg")
下記はYOLO11のXサイズのインスタンスセグメンテーションモデルで人を検出し、得られたマスクで各人物の距離を取得します。
import cv2
from ultralytics import YOLO
from ultralytics.data.utils import polygon2mask
from ultralytics.utils.plotting import Annotator, colors
yolo11_seg = YOLO("yolo11x-seg.pt")
yolo_results = yolo11_seg("bus.jpg")
yolo_result = yolo_results[0]
anno = Annotator(cv2.imread("bus.jpg"))
orig_shape = yolo_result.orig_shape
cls_names = yolo_result.names
for i, obj in enumerate(yolo_result):
cls_name = cls_names[int(obj.boxes.cls.item())]
if cls_name != "person":
continue
box = obj.boxes.xyxy.cpu().numpy()[0]
mask = polygon2mask(orig_shape, obj.masks.xy)
# Image.fromarray((mask * 255).astype(np.uint8)).save(f"mask_{i}.png")
Image.fromarray((mask * depth_map).astype(np.uint8)).save(f"masked_depth_map_{i}.png")
masked_depth = depth.cpu() * mask
obj_depth_min = (masked_depth[masked_depth > 0]).min()
obj_depth_avg = (masked_depth[masked_depth > 0]).mean()
obj_depth_max = (masked_depth[masked_depth > 0]).max()
print(f"{cls_name}: min={obj_depth_min:.2f}[m], avg={obj_depth_avg:.2f}[m], max={obj_depth_max:.2f}[m]")
anno.seg_bbox(obj.masks.xy[0], mask_color=colors(i), label=f"{obj_depth_avg:.2f}m", txt_color=(0, 0, 0))
anno.save("result.jpg")Depth Proの結果の深度とバイナリのマスクをかけるとマスク部分の深度のみ抽出できます。
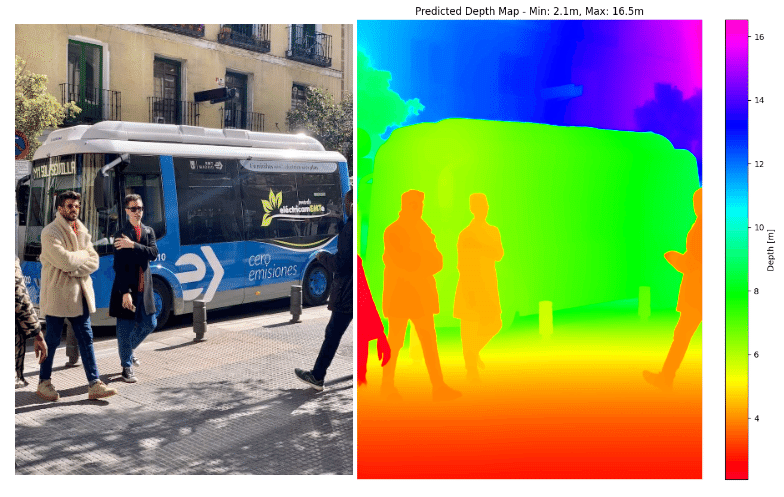
上記コードの実行結果は以下のようになりました。





# 下記は出力セルに Print された結果
person: min=3.30[m], avg=4.16[m], max=7.51[m]
person: min=3.65[m], avg=4.31[m], max=10.05[m]
person: min=4.30[m], avg=4.59[m], max=6.81[m]
person: min=2.13[m], avg=2.64[m], max=7.58[m]インスタンスセグメンテーションのマスクが完璧ではなく、背景などの余分な画素も含まれてしまうため最小値、最大値は使用せず、平均値をカメラと人物の距離としました。
Depth Proの結果を利用しているので、当然ではありますがデモページの結果と比べても概ね同じくらいの値になっています。
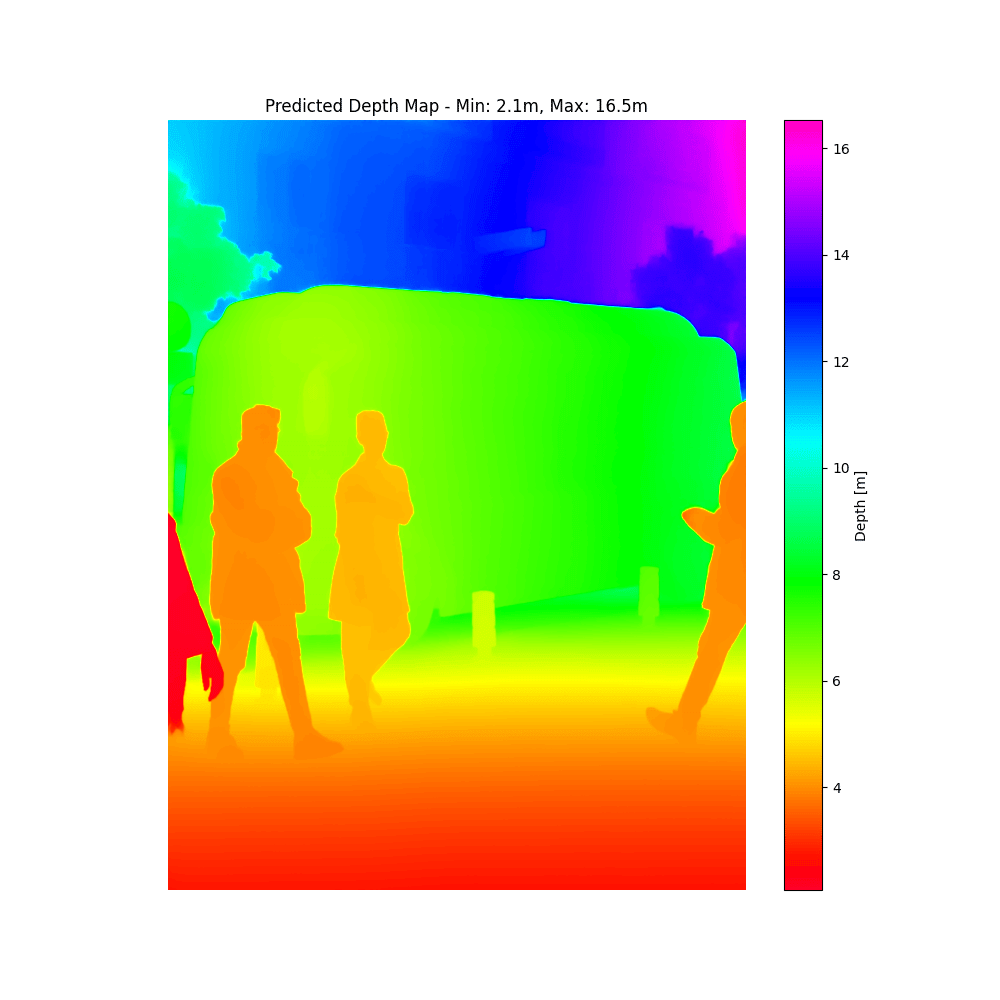
ただし課題として、バスの様に奥行方向にも長さがある対象は、距離のグラデーションができてしまうので単純に平均値を利用することはできません。
参考までに、バスの距離も表示すると以下の様になります。

余談
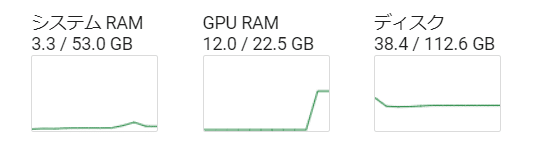
Depth ProのGPUメモリ使用は 12~15GB ほどでした。
また、以下のコードで Depth Pro の処理時間を計測しました。
810×1080の画像1枚の推論に2秒以上かかっています。
for i in range(10):
torch.cuda.synchronize(); start = time.perf_counter()
# Load and preprocess an image.
image, _, f_px = depth_pro.load_rgb("bus.jpg")
image = transform(image).to(device) # Move image to the same device as the model
# Run inference.
with torch.no_grad():
prediction = dp_model.infer(image, f_px=f_px)
depth = prediction["depth"] # Depth in [m].
focallength_px = prediction["focallength_px"] # Focal length in pixels.
np_depth = depth.squeeze().cpu().numpy()
torch.cuda.synchronize(); end = time.perf_counter()
print(f"({str(i+1):0>2}) Inference time: {end - start} sec")結果
(01) Inference time: 2.105501956000012 sec
(02) Inference time: 2.140413370000033 sec
(03) Inference time: 2.149166528999899 sec
(04) Inference time: 2.1621543410000186 sec
(05) Inference time: 2.159724575000041 sec
(06) Inference time: 2.165391252999939 sec
(07) Inference time: 2.1688327669999126 sec
(08) Inference time: 2.1785304429999997 sec
(09) Inference time: 2.1797918879999543 sec
(10) Inference time: 2.1908328099999608 secまとめ
単眼かつゼロショットで距離を推定できる点が大きな魅力です。
距離が得られるため、セグメンテーションと組み合わせることで対象物体(今回は人)までの距離を推定してみました。
距離が不要であれば、精度と速度の点でDepth Anything V2の方が個人的には好みです。