Windows環境でCLBlast+llama-cpp-python

先週はふつーに忘れました。別に書くことあるときベースでも誰にも怒られないのですが、書かなくなるのが目に見えているので書きます。てんななです。
今週、はというより今日は午前にローカルLLMで遊べそうなマシン構成をフォロワーに見繕ってもらったり、フォロワーがのたうち回っていたので以下の記事を試したりしていました。
Windows(without WSL)環境の記述が薄かったので、メモ代わりに残しておきます。
環境
Windows 11 Pro
Intel Core(TM) i7-8700 @ 3.20GHz
NVIDIA GeForce GTX 1080 6GB
メインメモリ:32GB
cmakeのインストール
Windows用インストーラーを使ってつっこむ
OpenCL libraryのインストール
このあとの手順で、Could NOT find OpenCL library, install it or set OPENCL_ROOT と言われたらやる。
このコメントが役に立った。Windows用のSDKをダウンロードしてきて、ビルド時にオプションとして指定するだけ。
CLBlastのインストール
Windows版CMakeはオプションが異なるので対応する。また、何も考えずにinstallすると、C:\Program Files\clblast なんかに入る。半角スペースのせいであとのビルドでエラーになるので、インストール先を指定しておく。
git clone https://github.com/CNugteren/CLBlast.git
mkdir build
cd CLBlast
cmake .. -DBUILD_SHARED_LIBS=OFF -DOVERRIDE_MSVC_FLAGS_TO_MT=OFF -DCMAKE_BUILD_TYPE=Release -DCMAKE_PREFIX_PATH=D:\CLBlast\lib\cmake\CLBlast -DOPENCL_ROOT=C:/OpenCL-SDK-v2023.04.17-Win-x64 -A x64
cmake --build . --config Release
cmake --install . --prefix=D:\CLBlastPythonのインストール
めんどくさいのでMicrosoft StoreからPython 3.12.2をインストール。元記事の通り、仮想環境も作った方が他の記事を試すときに影響を受けないのでおすすめですが、こちらもめんどくせえのでスキップ。
llama-cpp-python(with CLBlast)のビルド
環境変数CMAKE_ARGSは読み込まなかった? り、CmdとPowershellで記法が違ったりするので、コマンドラインオプションで与えてあげる方が安定する。-DCMAKE_PREFIX_PATH=… のパスは前のビルドと合わせること。
pip install llama-cpp-python --upgrade --force-reinstall --no-cache-dir -C cmake.args="-DBUILD_SHARED_LIBS=off;-DLLAMA_CLBLAST=on;-DCMAKE_PREFIX_PATH=D:\CLBlast\lib\cmake\CLBlast"推論
とりあえず元記事の通りにやる。` BLAS = 1` が含まれているのは確認しつつも、`OSError: exception: access violation reading 0x00000000124CD000` になった。
>python main.py
ggml_opencl: selecting platform: 'NVIDIA CUDA'
ggml_opencl: selecting device: 'NVIDIA GeForce GTX 1080'
llama_model_loader: loaded meta data with 24 key-value pairs and 419 tensors from D:\GitWorkSpace\clblast-project/aixsatoshi-calm2-7b-chat-7b-moe-q4_0.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = .
llama_model_loader: - kv 2: llama.context_length u32 = 32768
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 9: llama.expert_count u32 = 2
llama_model_loader: - kv 10: llama.expert_used_count u32 = 2
llama_model_loader: - kv 11: llama.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 12: llama.rope.freq_base f32 = 500000.000000
llama_model_loader: - kv 13: general.file_type u32 = 2
llama_model_loader: - kv 14: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 15: tokenizer.ggml.tokens arr[str,65024] = ["<|endoftext|>", "<|padding|>", "!",...
llama_model_loader: - kv 16: tokenizer.ggml.scores arr[f32,65024] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 17: tokenizer.ggml.token_type arr[i32,65024] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 18: tokenizer.ggml.merges arr[str,64756] = ["ã ģ", "ã Ĥ", "ã ĥ", "ã Ģ", ...
llama_model_loader: - kv 19: tokenizer.ggml.bos_token_id u32 = 0
llama_model_loader: - kv 20: tokenizer.ggml.eos_token_id u32 = 0
llama_model_loader: - kv 21: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 22: tokenizer.ggml.padding_token_id u32 = 0
llama_model_loader: - kv 23: general.quantization_version u32 = 2
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type f16: 32 tensors
llama_model_loader: - type q4_0: 321 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_vocab: mismatch in special tokens definition ( 26/65024 vs 24/65024 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 65024
llm_load_print_meta: n_merges = 64756
llm_load_print_meta: n_ctx_train = 32768
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 2
llm_load_print_meta: n_expert_used = 2
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 500000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 32768
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q4_0
llm_load_print_meta: model params = 11.34 B
llm_load_print_meta: model size = 6.00 GiB (4.55 BPW)
llm_load_print_meta: general.name = .
llm_load_print_meta: BOS token = 0 '<|endoftext|>'
llm_load_print_meta: EOS token = 0 '<|endoftext|>'
llm_load_print_meta: UNK token = 0 '<|endoftext|>'
llm_load_print_meta: PAD token = 0 '<|endoftext|>'
llm_load_print_meta: LF token = 32 '?'
llm_load_tensors: ggml ctx size = 0.32 MiB
llm_load_tensors: offloading 32 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 33/33 layers to GPU
llm_load_tensors: CPU buffer size = 142.88 MiB
llm_load_tensors: OpenCL buffer size = 6005.88 MiB
.................................................................................................
llama_new_context_with_model: n_ctx = 1024
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: freq_base = 500000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CPU KV buffer size = 512.00 MiB
llama_new_context_with_model: KV self size = 512.00 MiB, K (f16): 256.00 MiB, V (f16): 256.00 MiB
llama_new_context_with_model: CPU output buffer size = 127.00 MiB
llama_new_context_with_model: CPU compute buffer size = 172.51 MiB
llama_new_context_with_model: graph nodes = 1668
llama_new_context_with_model: graph splits = 1
AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 0 |
Model metadata: {'general.name': '.', 'general.architecture': 'llama', 'llama.context_length': '32768', 'llama.rope.dimension_count': '128', 'llama.embedding_length': '4096', 'llama.block_count': '32', 'llama.feed_forward_length': '11008', 'llama.attention.head_count': '32', 'tokenizer.ggml.eos_token_id': '0', 'general.file_type': '2', 'llama.attention.head_count_kv': '32', 'llama.expert_count': '2', 'llama.expert_used_count': '2', 'llama.attention.layer_norm_rms_epsilon': '0.000001', 'llama.rope.freq_base': '500000.000000', 'tokenizer.ggml.model': 'gpt2', 'general.quantization_version': '2', 'tokenizer.ggml.bos_token_id': '0', 'tokenizer.ggml.unknown_token_id': '0', 'tokenizer.ggml.padding_token_id': '0'}
Using fallback chat format: None
Traceback (most recent call last):
File "D:\GitWorkSpace\clblast-project\main.py", line 31, in <module>
print(llama.generate("USER:こんにちは、自己紹介して\nASSISTANT:"))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "(ざっくり省略)local-packages\Python312\site-packages\llama_cpp\_internals.py", line 311, in decode
return_code = llama_cpp.llama_decode(
^^^^^^^^^^^^^^^^^^^^^^^
OSError: exception: access violation reading 0x00000000124CD000手順ミスでBLAS=0になっていた頃は応答生成できていたので、しばらく首を傾げましたが、元記事のPythonコードにある `,n_gpu_layers=-1` を 削除するか、 `,n_gpu_layers=0` にしたら通りました。
出力を比較するとggml ctx sizeやbuffer sizeが変わっています。
# NG
llm_load_tensors: ggml ctx size = 0.32 MiB
llm_load_tensors: offloading 32 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 33/33 layers to GPU
llm_load_tensors: CPU buffer size = 142.88 MiB
llm_load_tensors: OpenCL buffer size = 6005.88 MiB
# OK
llm_load_tensors: ggml ctx size = 0.16 MiB
llm_load_tensors: offloading 0 repeating layers to GPU
llm_load_tensors: offloaded 0/33 layers to GPU
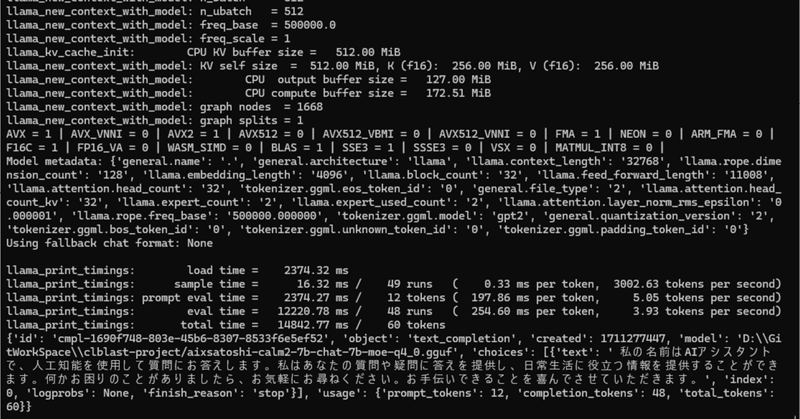
llm_load_tensors: CPU buffer size = 6148.75 MiB応答はこんな感じ。いい感じですね。買い換えなくてもGeForce GTX 1080で戦えたりする?(いいえ)
llama_print_timings: load time = 2454.00 ms
llama_print_timings: sample time = 32.90 ms / 98 runs ( 0.34 ms per token, 2979.00 tokens per second)
llama_print_timings: prompt eval time = 2453.96 ms / 12 tokens ( 204.50 ms per token, 4.89 tokens per second)
llama_print_timings: eval time = 24721.64 ms / 97 runs ( 254.86 ms per token, 3.92 tokens per second)
llama_print_timings: total time = 27688.72 ms / 109 tokens
{'id': 'cmpl-53d20a21-fda0-4751-8675-3c42398cc86c', 'object': 'text_completion', 'created': 1711276089, 'model': 'D:\\GitWorkSpace\\clblast-project/aixsatoshi-calm2-7b-chat-7b-moe-q4_0.gguf', 'choices': [{'text': ' はじめまして。私は「AI」 という名前の新しい人工知能です。「AI(アイ)」とは、「Artificial Intelligence」(アーティフィシャル・インテリジェンス) の略で、日本語ではそのまま「人工知能」と訳されます。コンピュータープログラムの一種であり、人間のような思考や行動を可能にする能力を持っています。私の主な役割は、様々なタスクを自動化し、ユーザーの生活を便利にすることであり、日々進化しています。何か質問やご要望がありましたらお気軽にお聞きください!', 'index': 0, 'logprobs': None, 'finish_reason': 'stop'}], 'usage': {'prompt_tokens': 12, 'completion_tokens': 97, 'total_tokens': 109}}調べたら、n_gpu_layersはGPUリソースの使用量を指定するパラメーターのようなので、with CLBlastの状態でGPU(のVRAM)を使おうとしたら死んだ、ってことですかね。なんもわかったないけど戦えてなぁいのはわかった。
追記: てきとうに rocket-3b.Q4_0.gguf を指定してみたら,n_gpu_layers=-1でも動きました。性能不足でFAですね。
llm_load_tensors: ggml ctx size = 0.27 MiB
llm_load_tensors: offloading 32 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 33/33 layers to GPU
llm_load_tensors: CPU buffer size = 69.08 MiB
llm_load_tensors: OpenCL buffer size = 1463.52 MiBllama_print_timings: load time = 486.98 ms
llama_print_timings: sample time = 23.55 ms / 85 runs ( 0.28 ms per token, 3609.80 tokens per second)
llama_print_timings: prompt eval time = 486.94 ms / 23 tokens ( 21.17 ms per token, 47.23 tokens per second)
llama_print_timings: eval time = 6734.02 ms / 84 runs ( 80.17 ms per token, 12.47 tokens per second)
llama_print_timings: total time = 7552.62 ms / 107 tokens
{'id': 'cmpl-280c1ae9-e949-418e-a37d-084826862f9c', 'object': 'text_completion', 'created': 1711277924, 'model': 'D:\\GitWorkSpace\\clblast-project/rocket-3b.Q4_0.gguf', 'choices': [{'text': ' 私のノート・エンジーです。「ASSISTANT」とも称することで,AI(Artificial Intelligence)を使用しています。ASSISTANTは24hours/365day隔たMulti-lingual&Multi-taskingな専門技 能を持つ専門技能なものであります。', 'index': 0, 'logprobs': None, 'finish_reason': 'stop'}], 'usage': {'prompt_tokens': 23, 'completion_tokens': 85, 'total_tokens': 108}}追記2: @tori29umai さんがビルドしたアプリだと、モードが違うのかOpenCLじゃなくてCUDA0が選択されて、ダメだったモデルも動いたので、なんかビルドオプションが足りないかもしれません。FAとはFake Answerの略です。
llm_load_tensors: CPU buffer size = 142.88 MiB
llm_load_tensors: CUDA0 buffer size = 6005.89 MiB結局スペック足らんって話ですけど
来月大阪日本橋へ行くことになったのでしばらく忘れる
— てんなな-8 (@tennana_tef) March 24, 2024
おまえは肉を食らってアウトプットを出すのだ、という圧をかけることができそうです。