LLM校正ツール開発とプロンプト性能評価手法について

はじめに
LLM活用のアプリケーション開発受託、プロンプトエンジニアリングを行っているphilic.techの出野です。
10年後の我々が今日を振り返るとき、2024年はLLM活用アプリケーション元年となることでしょう。1年でLLMが搭載sされたアプリケーションが次々と生まれてきます。
私たちは、LLMを活用したアプリケーション開発のためのプロンプトエンジニアリングを行う過程で必要不可欠な、プロンプトの性能評価に注力いたしました。
今回のノートでは、プロンプトの性能評価のR&Dとして開発した校正専門ツール「校正くん」を取り上げてプロンプトの性能評価について説明いたします。
早速てすが、この「はじめに」の文章には校正すべき箇所が3つ含れまています!全てお気づきになられましたでしょうか??
校正をテーマとした概要と背景
プロンプトの性能評価のために校正というタスクを選定した理由から説明します。
一言で述べると、校正は一意の答えが求められるため、プロンプトエンジニアリングの性能評価の指標を立てやすいためです。
LLMの性能評価の手法は既にある程度確立しており、研究者間での見解は概ね一致しているといえます。
しかし、プロンプトの性能評価の手法はまだまだ未発達の段階です。
LLMの性能ももちろん重要ですが、プロンプトの性能も重要です。
まず、弊社では答えが一意に定まる問いに対するプロンプトの性能評価手法の構築を行いました。今後、創造性のある答えが求められる問いに対するプロンプトの性能評価の実現を目指していきます。
そのために、我々は大規模言語モデル(LLM)を活用し、日本語に特化した文章校正ツールを開発しました。このツールは、文章の論理性・誤字脱字などを確認する校正に加え、事実と異なる情報を精査する校閲を行い、ユーザーがより正確かつ自然な文章を作成できるようサポートします。
従来の文章校正ツールは、主に単語のスペルミスや基本的な文法エラーのみに焦点を当てた限定的な機能に留まり、且つ精度の観点からも実用性が乏しいものでした。しかし、LLMの台頭により、より文脈を理解し、自然言語の複雑な構造に対処できるようになりました。
我々はR&D対象として新たな文章校正システムの開発に着手し、ユーザーが高度な文章校正機能を手軽に利用できるようになることを目指しました。
本文では、この取り組みにおけるプロンプトエンジニアリングの過程と、性能評価について説明いたします。
技術的詳細
使用した言語モデル:
本ツールでは、OpenAIのGPT-3.5及びGPT-4(Generative Pre-trained Transformer 4)を主に使用しました。GPTは大規模言語モデルであり、文脈の理解と文章生成において高い性能を発揮します。
インフラストラクチャ:
Amazon Web Services (AWS)を用いて、クラウドベースでの構築を行いました。Lambda関数は、Pythonを使用しました。Serverless Frameworkフレームワークを用いてDockerからイメージをプッシュすることで、諸々の手間を簡略化しました。本記事ではプロンプトエンジニアリングに重点を置くため、詳細な説明は割愛します。
目指すゴール「校正」とは?
今回のツール開発における話の前に、「校正」とは何か?、ユーザーが求める文章チェックの機能とは何か?を説明します。
まず、文章チェックは「校正」と「校閲」に大きく二分されます。
それぞれの言葉の定義が私自身曖昧だったため確認しました。
「校正」とは
字義としては,比べ、あわせて訂正すること。
転じて、現在では伏字、誤植、脱落、組誤り、さらに体裁上の不備、また明らかな原稿の誤りなどを直し改めること
「校閲」とは
誤っている情報を発見して、それを正す作業。
校閲時に見つかった情報の誤りは、「確実に間違いである」とわかるものであれば、校正時同様に赤字で修正の指示を入れる「朱書き」を行うが、正誤があやふやであったり、校閲者では裏付けの確認が取れない場合は、青字で指摘し、編集者へ返す。
今回の校正ツールの場合、ユーザが期待する機能(LLMだから可能である機能)には「校閲」も含まれると考えました。
つまり、以下のような機能を持つ校正ツールを開発することをゴールとしました。
校正ツールの理想的な機能(実際にプロの「校正」者、「校閲」者に依頼した場合と同じ機能)
単語単位での「校正」の機能を持つ
スペルチェック:スペル(綴り)ミスを検出
句読点チェック:適切な句読点の使用を確認
文章単位での「校正」の機能を持つ
文法チェック:誤った文法構造や不適切な単語の使用を検出
文体やトーン(音調)の改善:文章の一貫性や適切なトーン(音調)を維持するための提案
類義語や表現の提案:より適切な単語や表現を提案
「校閲」の機能を持つ
事実関係を確認し、間違いがあるものを指摘する
校正ツール(プロンプト)の性能指標を定義しよう
プロンプトエンジニアリングを行う際、それぞれのプロンプトの性能評価が必要になります。
以下の思考から、F値をベースとした性能評価手法を考案しました。
どのプロンプトが優れているかの評価を行いたい。
↓
客観的な指標が望ましい。 (既存のプロンプトエンジニアリングは、主観的判断がほとんどである)
↓
科学的アプローチによって定量評価できないか。
↓
校正を分類問題に帰着させ、F値で評価しよう。
校正を分類問題に帰着させる上で、いくつか定義が必要な部分があったので、何点か解説します。 (定義説明に関してはテクニカルな話題になるので、ざっと読みたい方は飛ばしてください。)
言葉の定義
まず、Positive/Negativeについて。
Positive:校正を行うべき箇所
Negative:Positive以外の箇所
例:「慎吾は来月からの生活に胸を踊らせていた。」であれば、Positiveは「踊」、それ以外はNegativeにラベル付けされる。
次に、Weak/StrongNegativeについて説明します。

下の図をご覧ください。
誤り箇所(校正が必要な箇所)に対し、校正ツールが修正するフローにはいくつかの分岐が考えられます。
まず、誤り箇所を誤りと認識できずに「正しい」と判定し修正を行わない場合があります。この場合、校正ツールによる判定はNegativeです。
次に、誤りと判定したが、その修正が正しい場合と誤った訂正の場合が考えられます。この分岐は、実際に校正ツールを制作していて初めて気がついた点でした。
例えば、
「3Rとは、リメイク(Remake)、リユース(Reuse)、リサイクル(Recycle)の3つのRのことです。」
という文章に対し、
「リメイク(Remake)」→「リデュース(Reduce)」とすれば正しい訂正になりますが、「リメイク(Remake)」→「リユース(Reuse)」
とすれば誤った訂正となります。しかし、後者の訂正は誤ってはいるものの、校正ツールのユーザーが誤り箇所に気づくヒントを与える可能性は大いにあります。
よって、誤り箇所を特定できたらWeakPositiveとし、その中で正しく修正できたものに対してはStrongPositiveと定義しました。
今回のF値の計算には、より厳しい基準で校正ツールを評価したいのでStrongPositiveを採用しました。
次に、正しい箇所(校正の必要がない箇所)に対しても、フローが考えられます。
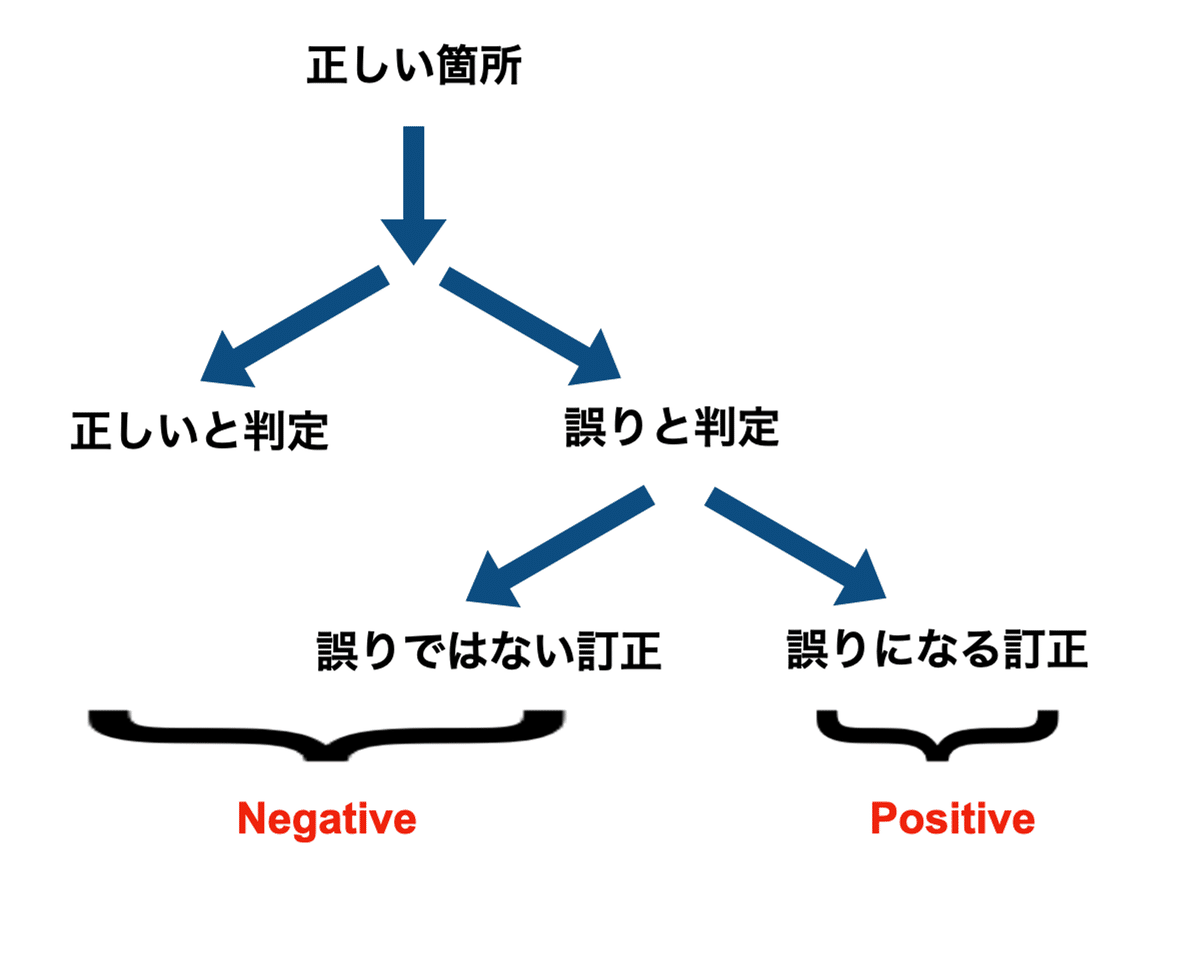
まず、正しい箇所を正しいと認識した場合、校正ツールによる判定はもちろんNegativeです。
次に、校正ツールは誤りと判定したが、その修正が誤りになる訂正とそうでない場合が考えられます。この分岐も、校正ツールを制作して初めて気がついた点でした。
例えば、
「きょうの夜ご飯はハンバーグ。」という文章に対し、「きょう」→「今日」とする訂正は、誤りにはならない訂正です。
よって、正しい箇所を誤りにしてしまう訂正をPositiveとし、それ以外をNegativeと定義しました。
校正は2値分類問題
よって、校正のタスクは一般的な2値分類問題とみなせて、校正の結果を以下の表の4章限(TN,FN,FP,TP)に分類できます。例えば、「肝に命じて」を「肝に銘じて」に修正できたら 「銘じて」への修正はTPに分類されます。「肝に命じて」を「キモに命じて」に修正したら、「キモ」はFPに、「命じて」はFNに分類されます。
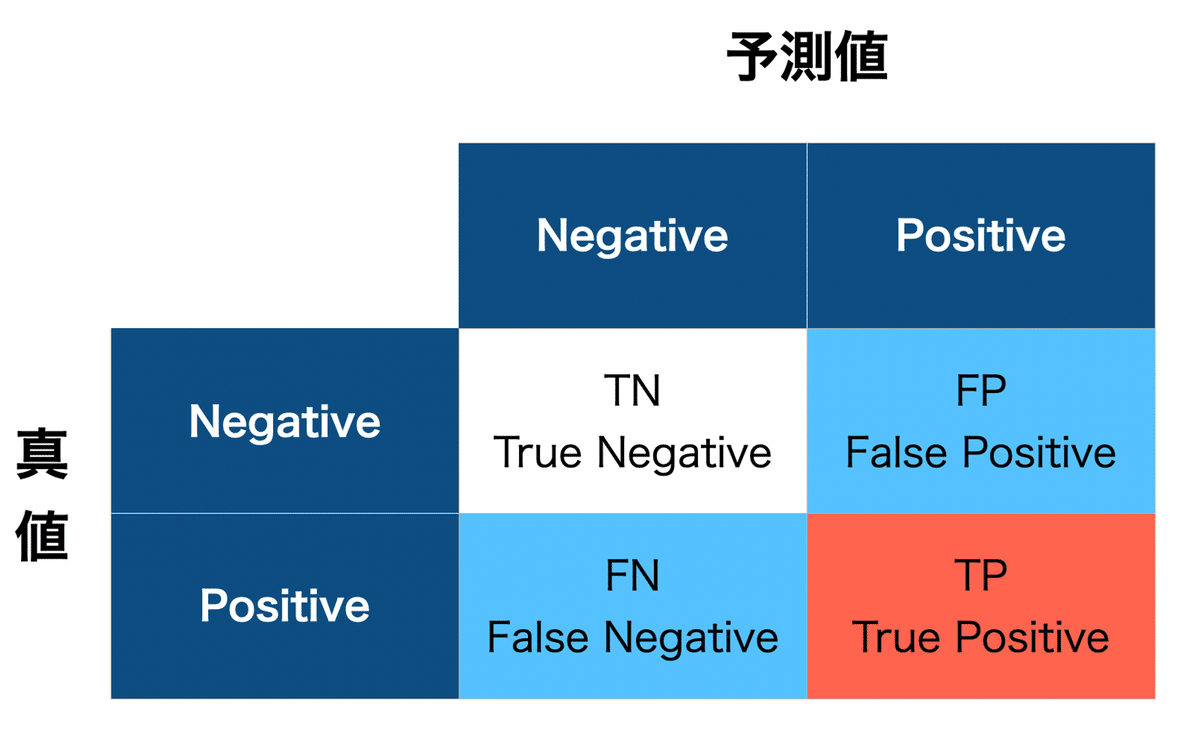
F値で性能評価
このような2値分類モデルの性能評価は、F値 (F1, F-measure)で判断されることが多く、今回の校正のプロンプトエンジニアリングには、以下のF値を採用します。(F値は、適合率と再現率のバランスの良さを見る指標。詳しくは、参考文献をご覧ください。)

プロンプトエンジニアリングの手法
プロンプトエンジニアリング検証環境の作成
プロンプトエンジニアリングを行うにあたって、以下のようなスプレッドシートを用意しました。(モザイク処理かける)
検証環境を作成した意図は、今回の場合のように大量にGPTに出力してもらって、その結果を比較する場合、(I)並列での処理行うことができて、(II)かつ複数出力の結果が同一画面に出力されて欲しいからです。この検証環境の構築により工数削減がなされました。

一番左の行が、校正対象の例文の集合です。これら23個の例文は、それぞれ約300文字で、計75箇所の訂正が必要な箇所を含んでいます。誤りの種類は多岐にわたり、誤字脱字、文法ミスなどの基本的なものから、校閲レベルの高度な修正を要求する箇所もあります(具体的な修正の結果は後述します)。
画面の右側では、GASで組んだ関数を用いてGPTによる校正結果を出力します。
比較したプロンプト
プロンプトスタイルとして、有名な深津式プロンプトに加え、条件を細かく指定する条件指定プロンプト、単純な指示のみのシンプルなプロンプトの3種類用意しました。
(プロダクト保護の観点からプロンプトの詳細は明示できません。)
また、校正箇所を箇条書きで出力するプロンプトと、校正後の文章を全文出力させるプロンプトの2種類の出力形態を用意しました。
それらに加え、gpt3.5と4の比較を行いました。
結果:シンプルなプロンプトが最強(F値=0.93)
検証の手順
検証は以下の手順で行いました。
各プロンプトで例文を校正する
校正箇所を、TP,FP,FNに分類する
F値を計算し、比較する。
F値の結果
以下がF値の表です。F値=0.93という驚愕の数字も出現しました。
gpt3.5(箇条) gpt3.5(全文) gpt4(全文) 初期 0.54 0.77 0.84 シンプル 0.63 0.70 0.93 深津 0.59 null null
(深津式は文章を大幅に変更してしまうため、全文出力のF値の計算ができませんでした。)
この表からわかることは3つです
校正タスクにおいて、全文出力は箇条出力に比べ優れている
プロンプトはシンプルが最強
GPT4は3.5に比べ圧倒的に性能が高い
以下でこの3点を詳しく説明します。
全文出力と箇条出力
結果の表から見て取れるように、全てのプロンプトで全文出力の方が箇条出力に比べF値が高い傾向にありました。
箇条出力のF値が下がる理由は、指摘漏れのFNが多くなるからです。GPTに全文と箇条を同時に出力してもらうと分かるのですが(下の文章)、全文出力では修正できた部分を箇条出力では見落としています。同時に出力しているのに、差が出てしまうのは大変興味深い現象です。
以下は、gpt-3.5-turboでの例です。
校正文章
はじめまして、私の名前は田中 太郎です。私は30さいです。私が日本に住んでおり、東京の近くに住んでいます。趣味がいろんな物ですが、特に音楽を聞く、映画を観る、旅行行くが好きです。私の家族には両親と妹と一緒に住んでいて、ペツトの犬も一緒に暮らしている。私は現在、大手のIT企業に勤めており、ウェブ開発者として働いています。仕事にて、プログラム言語に、JavaScript、Python、Ruby等を使っています。私は大学で情報科学を学んだ、そして卒業後に現在の会社に入りまた。
箇条出力
校正箇所1: ペツト > ペット 校正箇所2: 言語に > 言語を 校正箇所3: 一緒に行っている > 一緒に暮らしている 校正箇所4: また > または
全文出力
はじめまして、私の名前は田中太郎です。私は30歳です。私が日本に住んでおり、東京の近くに住んでいます。趣味がいろいろありますが、特に音楽を聞く、映画を観る、旅行に行くのが好きです。私の家族には両親と妹と一緒に住んでいて、ペットの犬も一緒に暮らしています。私は現在、大手のIT企業に勤めており、ウェブ開発者として働いています。仕事では、プログラム言語にJavaScript、Python、Rubyなどを使っています。私は大学で情報科学を学び、卒業後に現在の会社に入りました。
シンプルプロンプトが何故強いのか?
ほとんどのケースにおいてシンプルプロンプトのF値が高い結果となりました。条件指定のプロンプトは、誤った指摘のFPが多く、F値が下がってしまいました。このプロンプトでは、校正というタスクを分解し、より具体的な指示として与えます。その結果、それぞれのミスを見つけようと躍起になり、必要以上に頑張ってしまったためFPが増えたと予想されます。優秀な部下と同じで、目指すべきゴールだけシンプルに伝える方が、gpt君にとってもやりやすかったのかもしれません。
一つ誤解しないで頂きたいのが、少なくともこの校正タスクにおいてはシンプルプロンプトが最強だということです。他のタスクにおける最適なプロンプトのスタイルは当然変わってきます。
校正前文章
「うまい話にはウラがあるということを肝に命じていなくちゃならんよな。」
校正後文章(シンプルプロンプト)
「うまい話にはウラがあるということを肝に銘じていなくちゃならんよな。」
校正後文章(条件指定プロンプト)
「うまい話にはウラがあるということを肝に銘じていなくちゃなりませんよね。」
GPT-4スゴすぎる、、
前後の文脈を踏まえた校正も可能にするgpt4の性能には圧倒されます。。
校正タスクにおけるgpt4と3.5の性能差はF値によく反映されています。
校正前文章
顧客は建設会社か工務店で、消費者からのクレームに悩むこともない。いわゆるBtoCという業種で、業績もよい。
校正後文章(gpt3.5)
顧客は建設会社か工務店で、消費者からのクレームに悩むこともない。いわゆるBtoCという業種で、業績もよい。
校正後文章(gpt4)
顧客は建設会社か工務店で、消費者からのクレームに悩むこともない。いわゆるBtoBという業種で、業績もよい。
プロンプトの性能評価の3要点
今回の検証で見えたプロンプトの性能評価の要点3つです。
タスクを限定する
ゴールを明確にする
科学的アプローチによる性能評価を行う(or数値による性能評価を行う)
万能で何でもやらせたくなるLLMだからこそ、あえて行うタスクを限定することが大事です。我々人間が、自身で何をやりたいかを理解し明確にしない限り、LLMもその優秀さをどの方向に発揮して良いか分からなくなるからかと思われます。(既存のプロンプトエンジニアリングは汎化性能を求めすぎている?)
そして、今回の校正くんではゴールを「校正」と「校閲」の2点に限定しました。このゴールに設定したことで、客観的指標に基づく性能評価の土台を作る事が出来ます。
最後に、科学的アプローチによってプロンプトを定量評価することで、プロンプトエンジニアリングに再現性と記述性をもたらします。
競合校正ツールとの比較
競合校正ツールとの比較を行いました。校正くんの性能の高さを理解して頂ければ幸いです。
校正対象の文章
「SDGsは2010年9月の国連サミットで採択されました。3Rとは、Remake(リメイク)、Reuse(リユース)、Recycle(リサイクル)の3つのRRのことで。」
校正くん結果
「SDGsは2015年9月の国連サミットで採択されました。3Rとは、Reduce(リデュース)、Reuse(リユース)、Recycle(リサイクル)の3つのRのことです。」
競合ツールA結果(typoless)
「SDGsは2010年9月の国連サミットで採択されました。3Rとは、Remake(リメイク)、Reuse(リユース)、Recycle(リサイクル)の3つのRRのこと。」
競合ツールB結果(word)
「SDGsは2010年9月の国連サミットで採択されました。3Rとは、Remake(リメイク)、Reuse(リユース)、Recycle(リサイクル)の3つのRRのことで。」
修正できた箇所の差
単語レベルの修正に関して、wordが指摘できなかった部分をtypolessと校正くんは指摘できた。一方、RRという衍字には校正くんのみ指摘できました。
修正としてハイレベルである「Remake」から「Reduce」への修正や、校閲にあたる「2010年」→「2015年」に関しては校正くんのみが指摘できました。
課題と今後の展望
課題:課題として残っているのはgptの出力の安定性に関する制御です。「校正くん」の入力文にSQLインジェクションのような形でプロンプトの挿入と上書き(プロンプトインジェクション)を行われた場合、悪意を持ったユーザーに出力結果をコントロールされてしまいます。今回は出力文章が想定した回答と極端にずれている場合に、エラーとして処理をして問題に対処可能でした。しかし、これは万能な解決策ではありません。この入力・出力制御という点が、我々の課題と言えます。
次の検証:今回の取り組みは、一意に答えを求めることの出来る問いに対するプロンプトエンジニアリング でした。弊社が今後取り組んでいくのは、前述の通り、創造性が求められる問いに対するプロンプトエンジニアリングです。具体的には、エントリーシートの改善をサポートする「ESくん」のプロダクト開発に現在着手しています。このプロダクトは、エントリーシート作成に忙殺されている就活生がより意義のある就活を行えるようサポートします。
まとめ
「校正くん」の開発にあたり、従来のプロント構築ではない科学的アプローチによる性能評価を踏まえたプロンプトエンジニアリングを行いました。
具体的には、まず校正ツールの目指すべきゴールを定義し、F値による定量比較によってプロンプトの比較検証をしました。
その結果、シンプルプロンプトが強いという意外な発見やgpt4における「校正くん」の圧倒的な性能を確認する事ができました。
参考文献
https://arxiv.org/abs/2312.16171
https://note.com/ai_frontline/n/n303463f20db6
https://www.tactsystem.co.jp/blog/catalog_32/
この記事が気に入ったらサポートをしてみませんか?