
3時間で学べる!ChatGPTのData Analysisモードを使う為のPython基礎講座

ChatGPTの有料プランで使えるAdvanced Data Analysis(旧Code Interpreter)モードはファイルのアップロード、読み込みや、プログラミング的な処理を行えるモードです。
実行するプログラミングコードのロジックは基本的にChatGPTが作成、記述してくれますが、指示の解釈の問題や、現時点での性能面の限界などから、不適切なコードロジックになることもあります。
ユーザーが記述されたコードの内容を理解できれば、適切な修正指示を出し、ChatGPTの能力を引き出す事ができるので、プログラミング未経験、初心者の人もぜひ挑戦してください。
これから説明するPythonというプログラミング言語は、データ分析などでよく使われ、Advanced Data Analysisモードでも基本となる言語です。
目次
はじめに
講座の概要と目的
対象者と事前に必要な知識
解説しないこと
基本的な文法(変数、データ型、演算子)
変数
変数の命名規則
変数の基本的な使い方
データ型
主要なデータ型
型変換
演算子
主要な種類の演算子
制御構文と関数
条件文(if-else)
ループ(for, while)
forループ
forループ - リスト内包表記
関数の定義と呼び出し
関数の基本的な定義 - 基本構造
関数の基本的な定義 - 関数の呼び出し
関数の基本的な定義 - 引数の使用
データ構造
リスト
タプル
辞書
集合(Set)
ファイル操作とモジュール
ファイルの読み書き
Python標準ライブラリと外部モジュールの利用
NumPyと基本的な数値計算
配列作成、操作
統計量、基本的な数値計算
Pandasとデータ整形
データフレームの作成と操作
データの読み込みと出力(CSV, Excel)
データ可視化(Matplotlib & Seaborn): 基本的なグラフの作成
Matplotlibの基本
高度なグラフ作成(Matplotlib)
Seabornの基本
1. はじめに
講座の概要と目的
この講座では、「Advanced Data Analysisモード」を使うための、Pythonの基本的な使い方を解説します。
対象者と事前に必要な知識
対象者: Python初心者、データ分析に興味があるが具体的な方法がわからない人
事前知識: 特になし
解説しないこと
Advanced Data Analysisモードを使うためにPythonで書かれたコードの基本的な部分を読めるようにする事を目標とするため、プログラミングの環境設定などの話はしません。また、中級以降のプログラミングやデータ処理についての話もしません。
2. 基本的な文法(変数、データ型、演算子)
変数
変数とは、プログラミングにおいてデータを一時的に格納するための「仮の名前」または「参照先」です。変数を使用することで、計算結果や関数の出力、あるいは後から使いたい値などを保存しておくことができます。変数に値を割り当てる(代入する)には = 演算子を使用します。
変数の命名規則
変数名はアルファベット(大文字・小文字)、数字、アンダースコア(_)を使用できますが、最初の文字はアルファベットまたはアンダースコアでなければなりません。
Pythonは大文字と小文字を区別するので、variable と Variable は異なる変数として扱われます。
予約語(if、else、while など)は変数名として使用できません。
変数の基本的な使い方

データ型
データ型とは、変数に格納されるデータの「種類」または「形」を示す概念です。Pythonでは、主に数値、文字列、リスト、タプル、辞書、ブール値といった基本的なデータ型があります。データ型によって、その変数がどのような操作や計算に使えるのかが決まります。
主要なデータ型

データ型の確認
Pythonではtype()関数を使用して、変数のデータ型を確認することができます。

型変換
異なるデータ型間で変換が必要な場合もあります。例えば、整数を浮動小数点数に変換したり、文字列を整数に変換したりします。

データ型は、データの特性や扱い方を理解する基礎となる概念です。特にデータ分析の文脈では、データ型によってどのような分析手法が適用できるのか、どのようにデータを前処理するべきかが大いに影響します。
演算子
演算子とは、変数や値に対して特定の計算や操作を行うための記号やキーワードです。Pythonには、算術演算子、比較演算子、論理演算子、代入演算子などがあります。各種の演算子は、データの加工や条件分岐、ループなどの制御構造で頻繁に使用されます。
主要な種類の演算子



演算子は、Pythonにおける計算の基本的な「語彙」の一つです。これらの演算子をうまく使いこなすことで、データの構造や変化を柔軟に表現できます。
3. 制御構文と関数
条件文(if-else)
条件文は、特定の条件が成り立つかどうかに基づいてプログラムの実行フローを制御するための構文です。Pythonでは、if、elif(else ifの略)、else のキーワードを用いて条件文を記述します。条件文は、プログラムに「選択肢」を与え、条件によって異なる操作や計算を行わせることができます。
基本的な構造

ループ(for, while)
ループとは、特定の条件が成り立つ間、あるいは特定のデータ構造を走査する間、同じコードブロックを繰り返し実行するための制御構文です。Pythonでは主にforループとwhileループが使用されます。ループは、繰り返し同じ操作を行う場合や、データの集合に対して一括して操作を行う場合などに非常に便利です。
forループ
forループの基本的な構造は、forキーワードに続いて「イテレータ」(通常はリスト、タプル、文字列などのシーケンス型)を指定し、その各要素に対して一連の操作を行います。この際、ループ内で実行されるコードブロックはインデント(通常はスペース4つまたはタブ1つ)されている必要があります。

この例では、リスト[1, 2, 3, 4, 5]の各要素(element)が順に取り出され、print("Current element:", element)がそれぞれの要素に対して実行されます。
このforループの基本構造を理解することは、Pythonプログラミングの基礎であり、特にデータ分析においても非常に頻繁に用いられます。リストやタプルなどのシーケンス型以外にも、辞書やセット、ファイルオブジェクトなど、多くのオブジェクトがイテレータとして使用できます。
forループ - range関数の利用
Pythonのrange()関数は、一定の範囲の整数を生成するために用いられます。この関数は特にforループでよく使われ、繰り返しの回数を指定するのに便利です。
基本的な形式は range([start,] stop[, step]) です。startは範囲の開始値(省略可能、デフォルトは0)、stopは範囲の終了値(必須)、stepは増加する値(省略可能、デフォルトは1)です。

こちらの例では、range(5)が0から4までの整数を生成し、それぞれの整数(i)に対してprint("Current iteration:", i)が実行されます。
さらに高度な利用として、start、stop、stepパラメータを全て指定することも可能です。

この例では、range(2, 10, 2)が2から8までの偶数を生成し、それぞれの偶数(i)に対してprint("Even number:", i)が実行されます。
range()関数は、特に大量のデータを処理する際や、特定の回数だけ処理を繰り返す必要がある場合に非常に有用です。
forループ - リスト内包表記
Pythonには、forループを使って新しいリストを効率的に生成するための特殊な構文があります。それが「リスト内包表記(List Comprehension)」です。この構文を用いると、短い一行のコードで非常に強力な操作が可能です。
基本的な形式は [expression for item in iterable] です。ここで、expressionはリストの新しい要素を生成する式であり、itemはイテレータ(通常はリストやタプルなど)から取得する要素です。
例えば、0から4までの各整数の二乗を要素とする新しいリストを生成する場合は以下のように書けます。

この例では、range(5)が0から4までの整数を生成し、それぞれの整数(x)に対してx * xが計算され、その結果が新しいリストsquaresに格納されます。
さらに、リスト内包表記では条件文を加えることもできます。例えば、0から9までの整数のうち、偶数だけを二乗して新しいリストに格納する場合は以下のようになります。

この例では、range(10)が0から9までの整数を生成し、それぞれの整数(x)に対してif x % 2 == 0という条件がTrueであれば、x * xが計算されて新しいリストeven_squaresに格納されます。
リスト内包表記はデータの変換やフィルタリングを一行で効率よく行えるため、データ分析においても非常に便利です。
関数の定義と呼び出し
関数は、特定のタスクを実行するためのコードブロックです。関数を使用することで、コードを再利用できるようになり、プログラムが読みやすく、保守しやすくなります。Pythonでは、defキーワードを使用して関数を定義します。
関数の基本的な定義 - 基本構造
関数とは、一連の命令をひとまとめにしたもので、特定のタスクや計算を実行します。関数はコードの再利用性を高め、プログラムをより短く、読みやすく、管理しやすくします。
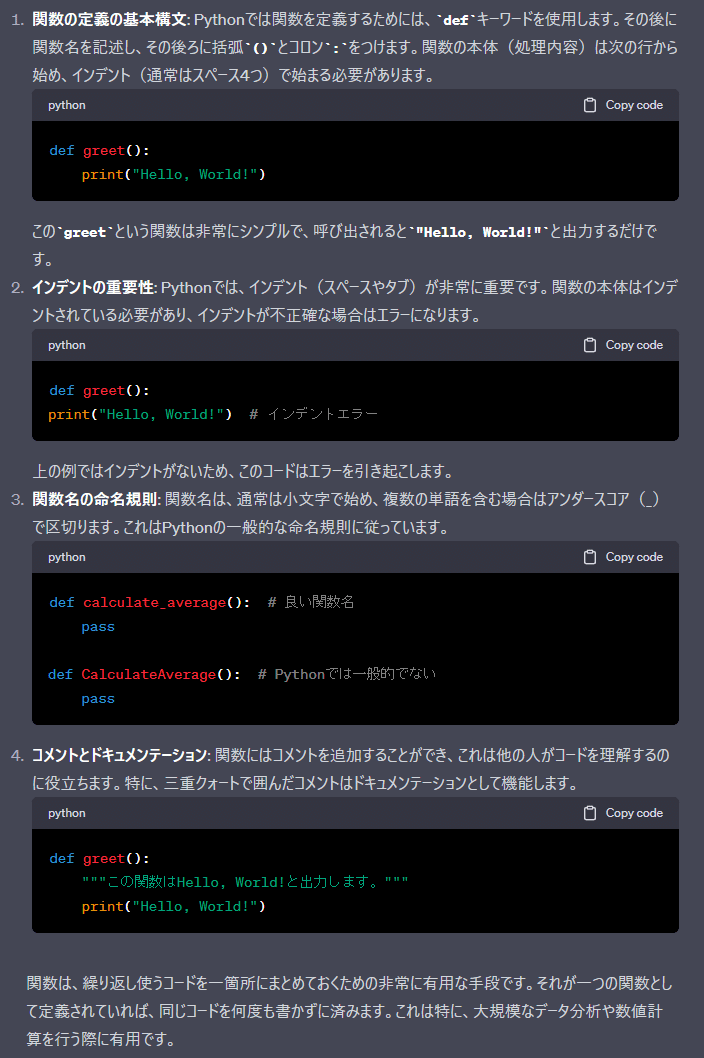
関数の基本的な定義 - 関数の呼び出し
関数を定義しただけでは何も実行されません。定義した関数を実際に動作させるには、それを「呼び出す」(または「実行する」)必要があります。

関数の基本的な定義 - 引数の使用
関数は、特定の情報(引数)を受け取って処理を行うことができます。これにより、同じ関数でも異なる結果を出力することが可能になります。

4.データ構造
リスト、タプル:
Pythonには、複数の要素を一つにまとめるためのデータ構造がいくつかあります。リストとタプルはその中でも基本的かつ多用されるデータ構造です。
リスト

タプル

辞書
Pythonの辞書(dictionary)は、キーと値のペアを格納するデータ構造です。JSON(JavaScript Object Notation)に似た形式であり、データの構造化に非常に便利です。

集合(Set)
集合は、複数の唯一な(重複しない)要素を格納するデータ構造です。集合は数学的な集合と同様の操作(和集合、積集合、差集合など)が可能です。

5.ファイル操作とモジュール
ファイルの読み書き
Pythonでは、テキストファイルやバイナリファイルの読み書きが容易にできます。データの永続化や外部ファイルとのデータ交換に役立ちます。

Python標準ライブラリと外部モジュールの利用
Pythonには豊富な標準ライブラリがあります。これに加えて、外部モジュール(サードパーティのライブラリ)も多数存在します。これらのライブラリとモジュールは、特定の問題を効率よく解決するための便利なツールとして広く用いられています。

6.NumPyと基本的な数値計算
配列作成、操作
NumPy(Numerical Python)は、Pythonで数値計算を効率的に行うためのライブラリです。NumPyの中心的なオブジェクトは多次元配列(通常は1次元または2次元)であり、この配列を効率的に操作する多くの関数が提供されています。

統計量、基本的な数値計算
NumPyライブラリは、基本的な数値計算だけでなく、統計に関する多くの便利な関数も提供しています。

7.Pandasとデータ整形
データフレームの作成と操作
PandasはPythonでデータ解析を行うための強力なライブラリです。Pandasの主要なデータ構造は「データフレーム」であり、このデータフレームを使ってデータの読み込み、加工、分析が可能です。

データの読み込みと書き出し
Pandasでは、さまざまな形式のデータを読み込み・書き出しする機能が提供されています。CSV、Excel、SQLデータベース、JSONなど、多くのデータソースに対応しています。

8.データ可視化(Matplotlib & Seaborn): 基本的なグラフの作成
データ可視化は、データ解析の過程で非常に重要なステップです。Pythonでは、MatplotlibとSeabornという2つの主要なデータ可視化ライブラリがあります。
Matplotlibの基本


高度なグラフ作成(Matplotlib)
Matplotlibは単純な線グラフ以外にも多くの高度なグラフ作成機能を提供しています。以下は、そのいくつかの例です。
1. 複数の線のプロット
単一のグラフ内で複数の線を描画することができます。
labelパラメータを使用して各線に名前を付け、plt.legend()を使って凡例を表示します。
2. 点のプロット(散布図)
plt.scatter()関数を使用して散布図を描画します。
この例では、xとyのデータの一部を取り出してプロットしています。
3. 棒グラフ
plt.bar()関数を使用して棒グラフを描画します。
カテゴリと値を指定して、各カテゴリに対する値を棒グラフで表示します。
4. ヒストグラム
plt.hist()関数を使用してヒストグラムを作成します。
この例では、正規分布に従うランダムな1000個のデータ点を生成し、それを30個のビンでヒストグラムとして表示しています。
以上のように、Matplotlibは非常に多機能で、データの可視化において多くのことが可能です。

5.ベン図

左側のベン図(2集合): 「Set A」と「Set B」という2つの集合があります。Set Aには10個、Set Bには5個の要素が含まれ、両方の集合に共通する要素は2個です。
右側のベン図(3集合): 「Set A」、「Set B」、「Set C」という3つの集合があります。各集合と集合間の共通要素の数は指定した通りです。
Seabornの基本
SeabornはMatplotlibを基にした高度なデータ可視化ライブラリです。Seabornは美しいデフォルトのスタイルと色彩を持っており、複雑な可視化を簡単に行うための高度なインターフェイスを提供しています。
1. ライブラリのインポートと設定
import seaborn as snsでSeabornをインポートします。
sns.set()はSeabornのデフォルトのスタイルと色彩を適用します。
2. 箱ひげ図(Box Plot)
sns.boxplot()を使用して箱ひげ図を作成します。
箱ひげ図はデータの分布を視覚的に表すのに有用です。
3. ヒートマップ
sns.heatmap()関数でヒートマップを作成します。
この例では、10x10のランダムなデータ行列を作成し、その値をヒートマップとして表示しています。
以上がSeabornの基本的な機能の一部です。このライブラリは非常に多機能であり、さまざまな高度なグラフと可視化を簡単に作成することができます。

この記事が気に入ったらサポートをしてみませんか?