僕が選んだモダンな分析環境※2019年5月現在

こんにちは
taskey Railsエンジニアの田代です。作っているもの
サーバエンジニアと言えど、スタートアップではRailsだけを書いていたら良いという訳には行きません。
今回は、突然データ分析基盤を作ってくれと頼まれ、当時BIツール?何それ?美味しいの?状態の僕が、どのように数多のツール群から技術選定をして社内のデータ基盤を作り上げ、データ基盤エンジニア(仮)になったのかを書かせていただきます。
対象者: データ可視化に関して悩んでいるマーケター、BIサーバ、集計DB構築に関して悩んでいるエンジニア
※実際のデータは出せません。分析基盤設計の参考となるよう僕が選んだツールを問題意識とPOINTを踏まえてご紹介させて頂きます。

(先に結論)
前提知識 -peep DB -
peepではシステムDB(MySQL)の他にlog収集用としてElasticsearchを採用しております。AuroraDB, Elasticsearchは共にAWSです。
またデータ収集の為、
・Adjust
・Repro
これら外部サービスを使用してAWS S3へのエクスポートもして頂いております。
他にも海外版のpeepサーバ用のJawsDBがHerokuで動いています。

(黄色線で囲まれた部分が該当)
選定 -BIツール-
[問題意識]
・データを取ってからのビジュアライズが手間
・Queryや共有管理が出来ていない
・複数のDBからデータを抜き出したい
BIツールですが一般的なモノですと、
・Superset
・Metadata
・Redash
これらがあげられるかと思われます。問題点に関してはどれも比較的網羅出来そうでした。
それぞれを試しての印象ですが、Supersetはまだ未完成部分を多く感じ、Metadataは完成度も高く機能も豊富だったのですが、豊富故の複雑さが気になってしまいました。
今回弊社BIツールとして採用したのはRedashです。
開発も盛んで、シンプルかつ強力なBIツールです。
query resultという機能を使うことで、データのストックや別のDB同士のJOINも可能となります。
また、分析基盤ということもあり、Heroku上でサクッと動かすRedash on Herokuというスタイルを選択しました。
[POINT]
・Redash on Heroku 参考記事
・Redashにはホスティング版もある
・MetadataやSupersetはGUIで情報を抜き出すことも出来るが、分析となるとSQLを書かないとなかなか厳しい
・Redashはupdateガイドも揃っているので頼もしい
・Redashのメンテナーが日本にいるので心強い @ありたさん

(黄色線で囲まれた部分が該当)
選定 -データウェアハウス-
[問題意識]
・外部DB同士のJOINに関してRedashのquery result機能だけでは限界がある
・集計で本番DBを叩いているのは道徳に反している
データウェアハウスですが一般的なモノですと、
・Redshift
・BigQuery
ほぼこの2強になるかと思われます。
弊社ではBigQueryを採用しました
正直悩んだのですが、近年の傾向と情報の新鮮さからこの選択をしました。
また、従量課金制であるBigQueryは、まだデータ分析の基盤が整い切っておらず料金の予想がつきにくい現段階だと都合がよかったです。
BigQueryで150万溶かした話が有名ですが、相当なデータ量がない限りは心配はいりません。一応料金トリガーは設定しています。
現在はBigQueryですが、今後の料金次第ではRedshiftへの移行も全然考えております。
[POINT]
・BigQueryは従量課金制
・Redshiftは定量課金制
・BigQueryは使用料金に関してトリガーを設定して通知を送ることが出来る
・カラム型データベースはSELECT句を絞ることで料金を抑えることが出来る

(黄色線で囲まれた部分が該当)
選定 -データ転送ツール-
[問題意識]
・転送をスムーズに行うことが出来る
・peep DB群全てに対応することが出来る
・転送jobを管理することが出来る
データ転送だとEmbulk x Digdagという方法がメジャーかと思われます。ただ、スタートアップ故時間を投資することが出来ないということもあり、今回はtroccoというサービスを使わせて頂くことにしました。
troccoは2018年11月8日にリリースしたばかりのサービスです。知らない方も多いと思います。内容としてはembulkのホスティング版だと思って頂いて問題ありません。
実はElasticsearchのみ対応していないという欠点があったのですが、相談したところなんと1週間で追加実装して頂けました。※追加料金等はかかってません。
自分でembilkを構築するのには面倒なjob管理やら通知管理等もGUIでサクサクと設定出来てしまいます。
絶賛使用中ですが、サポートが手厚く質問への対応もとてもスピーディーで快適に使わせて頂いております。
時間を買いたい皆さまには、是非ともチェックして頂きたいサービスとなっております。
[POINT]
・各種設定がGUIでサクサク出来る
・スケジュール管理が安心
・サポートが手厚い
・自社構築するより絶対に割安※料金はask
・絶賛進化中
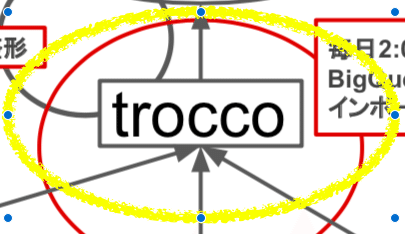
(黄色線で囲まれた部分が該当)
まとめ
今回はpeepの分析基盤周りに関して、まとめさせて頂きました。

ざっくりとデータ表示までの流れは下記のようになってます。
1. AuroraDB, Elasticsearch, S3から毎晩troccoを使ってBigQueryにデータを転送
2. BigQuery各種データセットからtrrocoを通してBigQuery集計用テーブル変換、転送
3. それらを元にRedashを使いデータをビジュアライズする
今後の課題としては海外版や、AuroraDBの一部データはまだ本番を見ているところもあるので、それらを移行していくことです。
正直手探りな知見ですが、データ基盤作成に少しでも参考になりましたら幸いです。また、この使い方やツールも良いよってことがありましたら是非教えてください。
ここまで読んで頂きありがとうございました。
CM
[募集]
/assets/images/3748968/original/79a37f05-2ac3-4867-b04b-7d1c43a8c3ac?1557734464)
/assets/images/3749138/original/4383c534-7ebc-45bc-9990-67c64f6cc2a1?1557736804)
/assets/images/3749264/original/0ee4faba-0816-4f86-bc87-e4f9ade9bd55?1557738289)
[主催コミュニティ]
[ドラムで入ってるバンド]
この記事が気に入ったらサポートをしてみませんか?