
データを作るということ

筆:八木 拓真(東京大学、VideoRecog. Group)
こんにちは!東京大学生産技術研究所で特任研究員をしています八木と申します(個人サイト)。専門はコンピュータビジョン、特に動画像認識で、cvpaper.challengeでは映像認識グループでアドバイザーを務めています。
本記事は 研究コミュニティ cvpaper.challenge 〜CV分野の今を映し,トレンドを創り出す〜 Advent Calendar 2022 の15日目になります。
突然ですが、みなさんの研究ではどんなデータを使っていますか?深層学習が当たり前のように使われるようになった今日、課題解決におけるデータの役割は以前にも増して大きくなっています。多くの方はコミュニティが提供するデータセットを使う形で研究をしているかと思いますが、私は機会に恵まれ、これまで複数の研究で自らデータセットを作る経験をしてきました。本記事では、コンピュータビジョン分野における「データを作る」プロセスについて自分の体験とその時の気づきを含めて書いてみたいと思います。
データセットができるまで
機械学習を試したことのある方なら、MNISTやMS COCOなどのデータセットを一度は使ったことがあるかと思いますが、それらのデータがどのように作られたか考えたことはあるでしょうか?例えば、手書き数字認識データセットであるMNISTは米国国勢調査局の従業員と高校生(!)の書いた手書き数字がそれぞれ3万枚ずつ含まれており、前者の方が明らかに綺麗で認識も簡単だそうです。超解像などの画像処理の評価で今でも伝統的に使われているKodak Lossless True Color Image Suiteは90年代にフィルムで撮影された写真(!)で構成されているため、ノイズの出方がデジタル写真とは異なります。
また、機械学習モデルの評価においては、評価データが訓練データと同じ分布から生成された未知のデータであることを暗に仮定しているため、作ったデータがそれに従わないと困ったことになります。あるデータセットがどのような題材をどのような過程で収集したかを知ることは、ベンチマークでよい性能を出したり、あるモデルの結果がどのような意味を持つのかを解釈したりするための手掛かりになります。では、実際データセットができるまでにはどのようなプロセスを踏むのでしょうか?
私の専門である動画認識では概ね次の手順でデータセットは作られます:
試し撮り
諸元・分量の決定
収録手順書の作成
倫理審査の実施
実験協力者の募集
本収集の実施
アノテーションラベルの定義
アノテーションの実施
アノテーションの品質チェック
データの分割
コードの整備
データセットの公開
まず、何を差し置いても評価したい対象を決めて、その対象を表すデータ(動画/写真/テキスト/音声)などを試しに集めてみて、本当に評価したい側面がそのデータに現れるか、どのような性質を持ちそうかを徹底的に検証します。よさそうだと分かれば、それをどの程度集めれば作りたい/使ってみたい手法の学習や評価に使えるかを吟味し、適切な分量を設定します。続いてすぐ収録に移れるかというとそういうことはなく、データを決められた通りに収集するための手順書の作成や、人を対象とする場合倫理審査や協力者の募集などのプロセスを必要に応じて踏む必要があります。収集後は自力あるいはクラウドソーシングなどを用いて適切なアノテーション(正解情報)を付与し、ベンチマークとして使える整備をして初めてデータセットを世に出すことができます。書き出してみるとたくさんありますね。規模の大小はあれど、すべてのデータセットがこの過程を経て作成されているわけです。
私のデータ作成遍歴
ここで講釈を続けてもよいのですが、結局のところ何から始める必要があって、具体的にどのようにして1つのデータセットが生み出されるのでしょうか?今回は、私の経験を振り返る形で実例を紹介したいと思います。
初研究で手話を撮る(2015)
私がコンピュータビジョン分野で研究をするきっかけになったのは学部3年の時に参加したハッカソンでした。当時そこでチームメイトから誘われる形で取り組んだのが「深層学習を用いて映像から日本手話を文章に変換(翻訳)するAI」で、実質初めての研究プロジェクトはデータを集めるところから始まりました。
音声言語と同じく、手話の世界も国ごとに使う言葉が異なります。日本で使われているのは日本手話(JSL)なので、当然アメリカ手話(ASL)などのデータを使いまわすことはできません。そこでメンバーのつてで東京大学のバリアフリー支援室の職員の方にお願いして聴者・ろう者の手話者の方にほぼボランティアで収録をお願いして手話を演じる様子をRGB-Dカメラを用いて7名分撮りました。

この初めてのデータセット収集で印象的だったのは、(1) アノテーションルールの統一の難しさ (2) 聴者とろう者の間の表現力の差 でした。音声もそうですが、流暢な発話は単語やフレーズ間の境目を見分けることが非常に難しくなります。また、同じ意味でも指や手の動かし方に微妙にバリエーションがあるなど、そのドメインに詳しくないと難しい現象に頻繁に遭遇し、容易に正解がつけられないこともしばしばでした。また、先天性のろう者の方は手指の形だけではなく、表情・うなずき・視線などのあらゆる手段を使ってその言葉のニュアンスを表現するのに対し、第2言語として習った聴者の方にはそれがあまりなく、もはや別物とも呼べるものでした。これは機械学習においてはドメインギャップと呼ばれる現象そのものですが、最初の研究にして強烈な印象を残したのでした。
汗をかいて歩き回った研究がヒットする(2017)
手話認識をきっかけにコンピュータビジョンビジョンの分野に足を踏み入れ、修士入学後まもなく「胸に装着したウェアラブルカメラで撮影した一人称視点映像から歩行者の1秒後の位置を予測する」研究に取り組みました。この研究は私が初めて国際会議に通した思い出深い研究であると共に、今でも引用される自分のヒット作でもあります。一方、この取り組みを世に出せたのは突発的な思い付きからでした。
当時一人称視点映像の歩行映像データベースは存在せず、春から夏にかけては事前に収録された大学構内の映像や研究室内のメンバーで集めたごく小規模の映像で実験を繰り返していたのですが、結果は芳しくなく、何よりリアルな状況に沿っていないのではないかという疑問が燻っていました。そこで9月の某日、「とにかく歩いてみよう」と決め、胸にGoProカメラを付けて毎日都内各所歩き回り、そこに突如数時間分のデータセットが誕生したのでした。
実践はしばしば思考に勝ります。人が歩いている様々な場所を探し、実際に歩行者を観察しながら歩いてみることで「思ったより目線はこっちに向かないな(みんなスマホを見ている)」「身体の向きは進行方向を反映しているな」等のリアルな観察が得られ、それが提案手法の考案にも寄与したと思っています。闇雲にデータを集めてミーティングで数字を出したところ、「(1か月半後の)CVPRに出そう」となり、その結果が多数の後続研究に何かしら寄与したのですから、巡りあわせはわからないものです。

探し物は何ですか?(2020)
これはデータセット構築というよりはユーザ実験ですが、面白かった体験として紹介したいと思います。この取り組みでは物を置いた場所を忘れた際のもの探し行動を支援するシステムを作成し、そのシステムが使わない場合と比べて本当にもの探しを効率化するのかを検証するために「セルフかくれんぼ」の枠組みで実験をしました。ごく簡単に説明すると、実験参加者に首にカメラを書けてもらった状態で20個程度のモノを部屋内に自由に隠してもらい、インターバル課題(100ます計算)を設けて記憶をリセットさせたうえで、再度そのうちのいくつかのモノだけを正しくとってくる、という課題です。
研究としては、システムの補助なしで全て自力で思い出されても、逆に難しすぎて差がつかないのも困るわけですが、どのくらい課題を複雑にするかはチームメンバーと喧々諤々で議論しても直前まで決まりませんでした。最後に自分で同じ課題をやってみて、このくらい難しければいいだろうと本番に臨むと、参加者皆独自の記憶術を披露して補助なしでもサクサク置いた場所を思い出すではありませんか。集計したところきわどく差がついたのと定性分析で使えると評価してもらったので無事論文になりましたが、自分の経験のあてにならなさにびっくりすると共に冷や汗ものでした。
AIシステムは最終的に人に帰ってくる、と私は考えていますが、人の数だけその行動にはバリエーションがあり、それを体感するという点で印象に残る実験でした。

挑戦的なベンチマークの作成に悪戦苦闘する(2021)
細かい説明は省きますが、博士課程の研究を通じた問題意識として「実世界の難しさを反映した課題を解く」というものがありました。そこで、映像からの手-物体接触判定や物体インスタンスの識別などの課題に対して、リアルな状況で撮影されたデータセットに新たにアノテーションを付与するというアプローチをとりました。
新しい課題に取り組む際はその課題に合わせたデータをやりやすい形で集めるのが常道ですが、これらのケースでは既に別の目的で収集されたデータを別の用途に転用するため、効率よく必要な情報を引き出すために色々と工夫する必要がありました。そのため、これらの研究ではアノテーション手順やその運用について工夫することに力点を置きました。
例えば、手-物体接触判定のアノテーションでは、研究室の後輩と共同でアノテーションを行ったのですが、内輪のコラボレーションというのもあって、プロジェクトの目標からタスクの説明、ツールの使い方などをドキュメントにまとめ、随時疑問点を追記で解消していくという方針を取りました。難しいケースについては具体例を見せながらQ&Aで回答することですり合わせを図ることで品質を維持できるようにしました。

また、必要な場合は独自のアノテーションツールを作成し、アノテーション作業とその効率化を同時並行で行うこともありました。下図の同一物体アノテーションツールでは、作業の過程で得られたフィードバックを基に機能を追加することで当初の数倍の作業速度を実現し、複雑な映像データに対して対処できたと考えています。
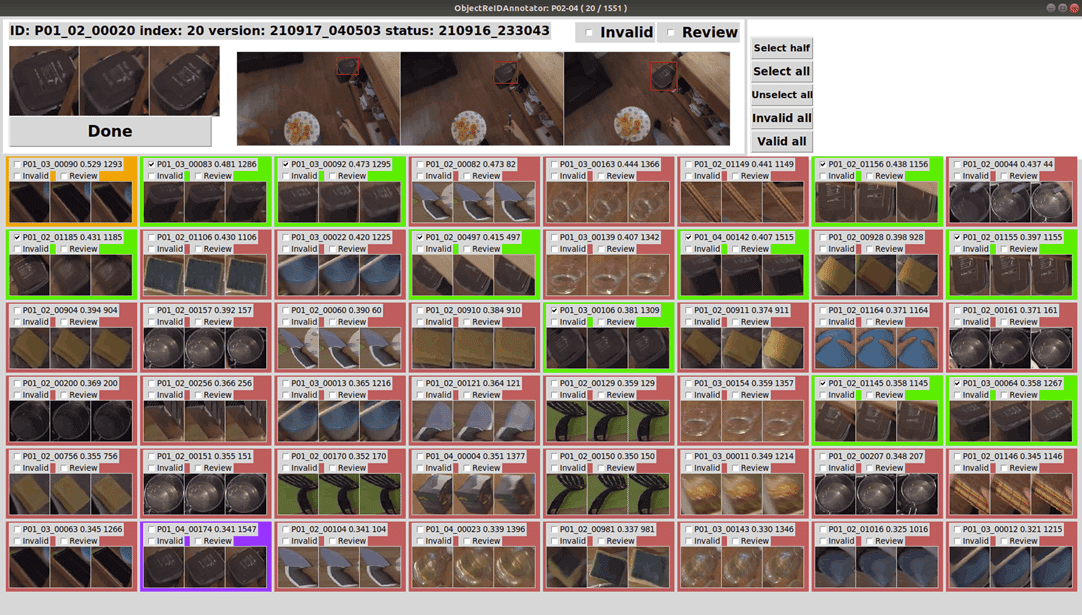
ここで紹介した2つのタスクは両方ともアノテーションが難しく、1秒分の動画をアノテーションするのに数分かかるなど、率直に言えば非効率的な仕事でした。しかしながら、こうした努力に本質が含まれていることもまた事実なのです。
世界規模のデータセット構築の一翼を担う(2020~)
時間は前後して2020年に戻ります。個人レベルでの仕事の傍ら、指導教員の紹介でMetaと13の大学組織が共同で世界規模の一人称視点映像データベースをつくるEgo4Dプロジェクトに参加しました。今年はじめに公開されたv1では世界各地の様々な属性・立場の人が撮影した約3,670時間の一人称視点映像とそれに付随した5つのベンチマークタスクが提供されています。私はこのプロジェクトの東大チームの実施担当者として計80人、140時間超の映像の収集に携わりました。

大学や研究所で行う研究の典型的な限界の1つとして、「実験参加者が院生や先生に限られる」という問題があります。しかしながら、大学の外を出れば当然違う世界が広がっており、人の数だけ文化や活動は異なってきます。本プロジェクトはそうした偏った参加者構成を見直し、なるべく多様な人たちの活動を撮ろうとしたところに特色があります。私たちのチームでも実験参加者を年齢・性別などがばらけるように募集し、普段全くAI研究に接することのない人たちに協力してもらいました。
東大チームではテーマをいくつかに絞り、そのなかの1つとして調理映像の収録を行ったのですが、キッチンをこちらで用意するのではなく、カメラ一式を説明時に持ち帰ってもらい各自の自宅で自力で撮影してもらうという方式を取りました。期間内は実施報告や質問を随時受け取り、最終日までどのような映像が出てこないというもどかしさがありましたが、集まった映像を見ると質素で整頓されたキッチンから映画に出てきそうな小道具だらけのキッチンまで、こんなにも幅が出るものかと驚きました。この分野で主流のデータセットはアメリカやヨーロッパ発のものがほとんどであるため具に見ると研究対象もその文化や慣習に寄せたものになっているのですが、今回国内でしっかり集めてみて、食材・道具・調理法などすべてがガラッと変わり、AIを作るにあたっての課題すら変わってしまうことに気づかされました。アジア以外にも中東やアフリカなどから映像提供があり、そうした場所からのデータが含められた点だけでも収穫があったと思います。
また、この大規模プロジェクトの特色として、昨今のプライバシーの権利への意識の高まりを反映した厳格な収集プロセスがあります。まず、このデータ収集に参加した協力者には全員プロジェクトの目的やデータの公開範囲に関する同意を取っています。また、(解析で必要がある場合を除き)人の顔や車両ナンバー、住所氏名などの個人情報は半自動でぼかす等の匿名化処理を全映像に対して実施しており、撮影者およびその周辺の人物のプライバシーに配慮しています。AIシステムが私たちの生活に波及してくるにあたり、不適切なデータの撤回(例:tinyimages)や著作物の学習への利用の是非などが以前にも増して注目を集めており、今後これまで以上にこうした配慮が重要になることは間違いありません。
課題を「生む」側に回る
ここまで駆け足で私とデータの関わりについて振り返ってきました。ここで、みなさんの中には「苦労ばかりで、何がうれしいのか?」と思う方もいらっしゃるかと思います。確かに、こうしたデータを集める研究には次のようなデメリットがあると思います:
データの収集や処理に時間をとられて、重要な手法開発に時間を割けない
権利関係のリスクが多く常時気を抜けない
大企業が集める大規模データベースやそれを使ったモデルに淘汰される可能性がある
一方、私はデータ収集研究には次のような魅力があると感じています:
誰かが考えた課題に追従するのではなく、自ら課題を考え一番に取り組める
データ収集の過程を通じてその領域の専門家になり、ユニークな発見を通じて新たなアイデアを生み出せる
研究対象に直に接することで見識を広められる
なかでも、データ収集を通じてその領域の専門家になることは一般的な解法が普及し、真に難しい課題が発見された今だからこそ様々な領域で求められています。特に、画像・言語・音声などを扱う応用領域においては、それがどのようなモデルで効率よく解けるかを数理的に考えるだけでなく、ある現象がどのようなメカニズムで成り立っているかを考えることも大事ではないでしょうか。
昨今は基盤モデルに代表される大規模かつ一般性を持ったモデルが持て囃されていますが、私としてはそれらと課題創出型の取り組みの両方がバランスよく回ってくれることを願っています。
おわりに
本記事では、自分の経験を基にデータセットを作るとはどういうことかをつらつら書いてみました。ちなみに、今も現在進行形で次のようなプロジェクトで新たなデータを作る取り組みを行いながら、忙しくも充実した日々を過ごしています:
バイオ実験作業映像の解析
物体状態変化認識
場面に応じた適切な行動の予測AIの構築
みなさんも問題を解くだけでなく、問題を作る側に回ってみませんか?
最後になりますが、私(八木)は2023年のMIRU/cvpaper.challenge合同メンターシッププログラムの委員を務めます。もし本記事のようなデータセットを扱う研究をやってみたいという方がいらっしゃいましたら、ぜひ次期の募集への応募をご検討ください!
それでは引き続き、研究コミュニティ cvpaper.challenge 〜CV分野の今を映し,トレンドを創り出す〜 Advent Calendar 2022 をお楽しみください。
この記事が気に入ったらサポートをしてみませんか?