
chaiNNerについて書いてみる

chaiNNerと言うノードベースの画像編集ソフトがGitHubで公開されていますが、Gigazineや3d人などの一部のポータルサイトで取り上げられてくらいで情報がないように思い、みんなあまり知らないんじゃないかなーと思ったのでnote初投稿ネタとして書いてみたいと思います。
※Mediumにも似たような投稿ありますが、deeplとchatGPTを頼りながら私が書いて投稿したものなのでパクリ投稿ではないです。
chaiNNerとは?

A flowchart/node-based image processing GUI aimed at making chaining image processing tasks (especially upscaling done by neural networks) easy, intuitive, and customizable.
GitHub上のアプリ説明の冒頭は引用の通りですが、要はノード(色々な機能を持ったパーツ)を繋いで画像処理(AIを使った高解像度化とか)を簡単にできますよ、と言うアプリ…と理解しています。
chaiNNerではAIによる高解像度化をするために使う学習済みモデル(AIによる高解像度化のために使うもの)をGUI操作で簡単に利用できるのでプログラミングスキルや知識がなくても簡単にAIによる高解像度画像を作り出せたり、ノードを繋ぐ事で視覚的に画像編集を組む事ができます。後述する私のような問題を抱えた人にはかなり便利だと思います。更に、Alpha v0.18.0のバージョンからはStable Diffusionも扱えるようになったようなのでコレはかなり注目上がってくるんじゃないかと思います(まだ試してないです)。
【AIによる高解像度化のサンプル】 ※画質は学習済みモデルによります
Switchで撮った画像(1280x720ピクセル)。


と言うわけで、この後書く私が抱えていた問題を解決するために作ったchaiNNerファイル達を置いておくので、「chaiNNerでこんな事ができるんだー」と言うのを知っていただけたら嬉しいです。
私の抱えていた問題とは
800x1,280ピクセルのテキスト主体の画像を1,668×2,388ピクセル(iPad pro11)で表示したい。
画像は大量、かつテキストは実際に読める必要があったので元の画像をそのままiPadで表示しただけでは読めないことはないものの読み辛かったので何かしらの方法で高解像度化する必要があった。
処理したい画像は大量、しかも定型的ではあるものの切り抜きが必要になる画像も大量に存在していた。
waifu2x-caffeを使えば複数の画像を一度に高解像度化はできるものの、テキストに対してはあまり良い画質にならない。また切り抜きはできない。切り抜きは他のソフトに任せる手もなくは無かったが、waifu2x-caffeで高解像度化→別ソフトて切り抜きと言う二度手間になるのは避けたかった。
↑↑↑この問題がchaiNNerなら一発で解決できます!
chaiNNerのサンプルファイル
サンプルファイルはこちら(GoogleDrive) 。
https://drive.google.com/drive/folders/1niTC66_X8pIdwBLiIA4AnxVD0dU6twDj?usp=share_link
【注意】chaiNNerのファイルを動かす場合は解凍後に各自入力画像やフォルダ、学習済みモデルを指定してください。お使いの環境ではうまく動かなかったり、高解像度化は重たい処理なのでお使いのPCスペック次第では処理に長時間がかかる事があるかもしれません(私のPCも貧弱スペックでそこそこ早く動くのはrealesr-general-x4v3.pthくらいでした)。
サンプル1:高解像度化(1枚ずつの処理)
1枚単位で画像を高解像度化します。

サンプル2:高解像度化(サブフォルダも含むフォルダごと処理)
フォルダ内(サブフォルダも対象)の画像をすべて高解像度化します。

サンプル3:高解像度化2(サブフォルダも含むフォルダごと処理)
私が解決したかった問題のために作ったファイルです。できることetcは以下の通り。
複数枚、複数フォルダの画像の高解像度化が可能。
出力サイズを手で入力するのは避けたかったため、最終出力サイズの画像(TargetSizeFile.png)を用意して、それを取り込むことで出力サイズを決定可能。今後もしサイズを変えたくなったらこの画像を差し替えればよし。
上記TargetSizeFile.png流用して画像の余白を埋めが可能。私がやりたかった800x1,280ピクセルから1,668×2,388ピクセルへの拡大だけをすると、拡大後画像をiPadで表示した際に左右に何も表示されない黒い領域ができてしまうのが気に食わなかったので追加した機能(サンプルは色がついていますが自分で使うときは白色です)。

サンプル4:高解像度化3(サブフォルダも含むフォルダごと処理)
やっていることはサンプル3とほぼ同じ。最終的に必要な領域だけ切り出すようにしています(高解像度化する前に切ってしまった方がいいような気もする…)。
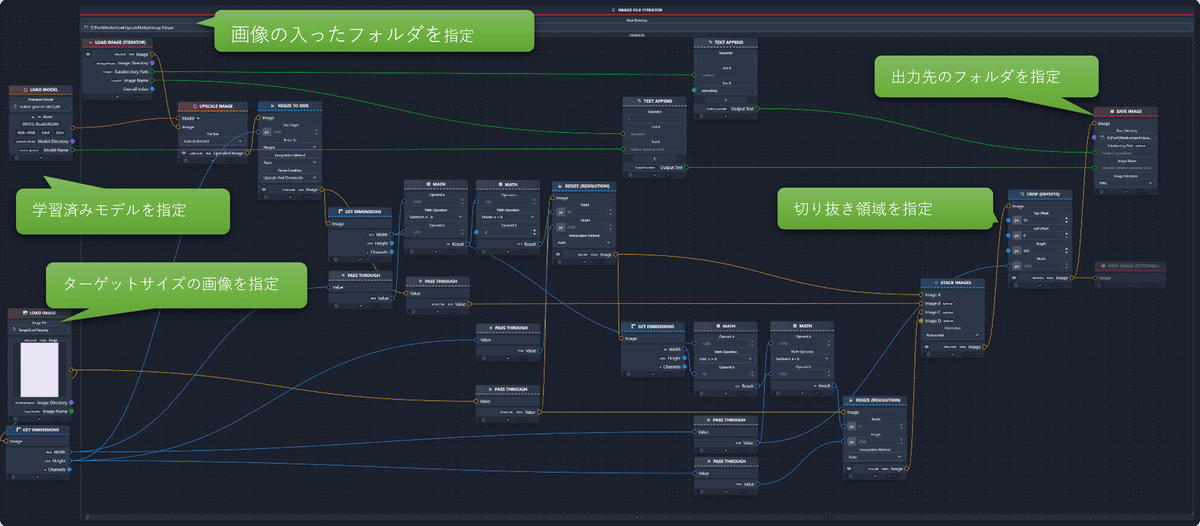
サンプル5:拡大方法による出力結果の比較
chaiNNerでは学習済みモデルを使わない画像拡大機能もあるので、chinNNer自身が持っている拡大機能と、学習済みモデルを使って拡大した場合の画像を比較するためのファイルです。

サンプル5で比較するとこんな感じになります。

サンプル6:学習済みモデルの違いよる出力結果の比較
同一の画像に対して、chiaNNer自身の機能で拡大した画像と2個の学習モデルを使って出力したが画像を並べて比較をします。拡大倍率は揃えておく必要があります。

サンプル6で比較するとこんな感じになります。

最後に
私がサンプルとして載せたものはchaiNNerの機能の極一部を使った簡易的なものだと思ってますが、それでも例えば「勉強用に電子書籍やWebのスクリーンショットを取って書き込みをしたいが、書き込みのために拡大すると画像が荒いので何とかしたい」とか「Switchで撮った画像を高解像度端末の壁紙に使いたいけど荒い…」とか言う時とかにも使えそうです。
Stable Diffusionにも対応したようなので、(もし私のノートPCでも動けば)Stable Diffusionの動かし方や結果も載せたいと思います。ウゴカナイキガスルケド…。
最後までご覧いただきありがとうございました。もしよければサポートからの支援やKo-fiからコーヒー1杯おごって下さい。
https://ko-fi.com/taktak2nak
【おまけ】
chaiNNerファイルを作るにあたって、いくつかテスト画像を取っていたのでおまけでつけておきます。



ここから先は
¥ 200
この記事が気に入ったらサポートをしてみませんか?