
【SEO】Indexing APIでインデックス登録を高速化させる方法

要約(TL;DR)
・Indexing APIでクローラーを呼び寄せる事が可能
・APIを叩いたらすぐにクローラーが来た
・このAPIでインデックス登録を早める事は可能
・ただし、本来の仕様とは異なる使い方なので注意
"インデックス登録"のありがたさに気づく
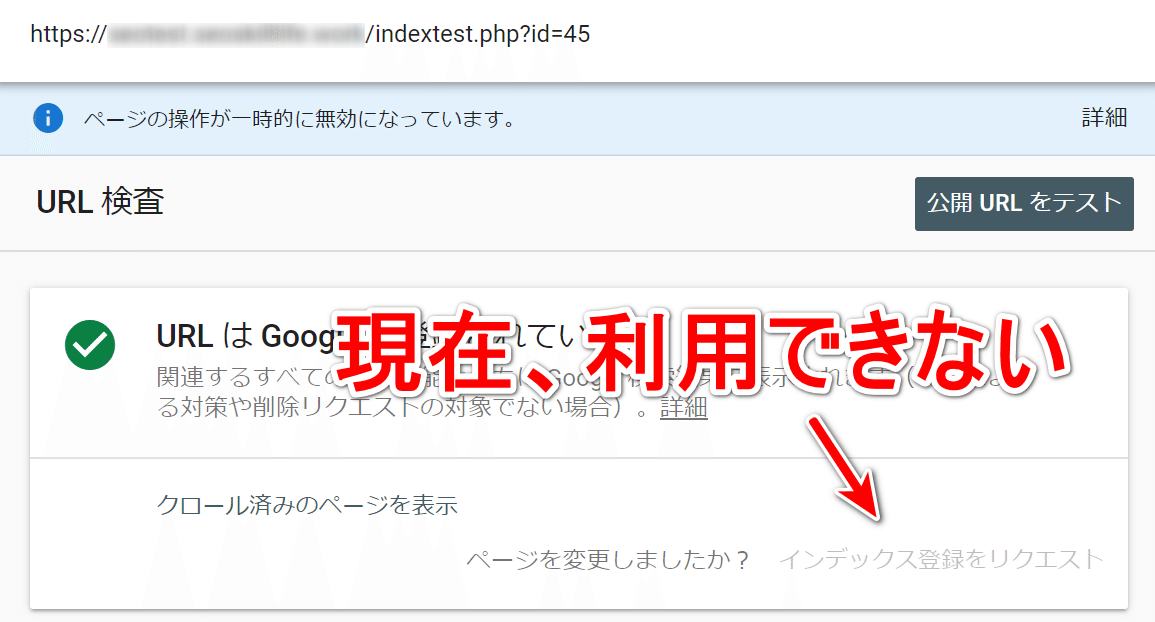
2020-11-14現在、Googleサーチコンソールのインデックス登録が利用できなくなっています。
Googleの発表によると『技術的なアップデートを行うため、10月14日から提供を停止しており、数週間で再提供を予定している』との事でした。
しかし、今日現在も利用できず、機能の提供停止から1ヶ月以上が経過しようとしています。
インデックス登録機能の提供が停止して以降、「数日経ってもインデックス登録されない。サチコが使えないからどうすればいい?」という質問も頂く事がありました。

そこで、今回はサーチコンソールのインデックス登録機能以外でインデックス化を促進する方法が無いか調査してみました。
そもそも、インデックス登録されるには?
GoogleのインデックスデータベースにWebページのコンテンツを登録させるには、大きく4つの工程を通る必要があります。
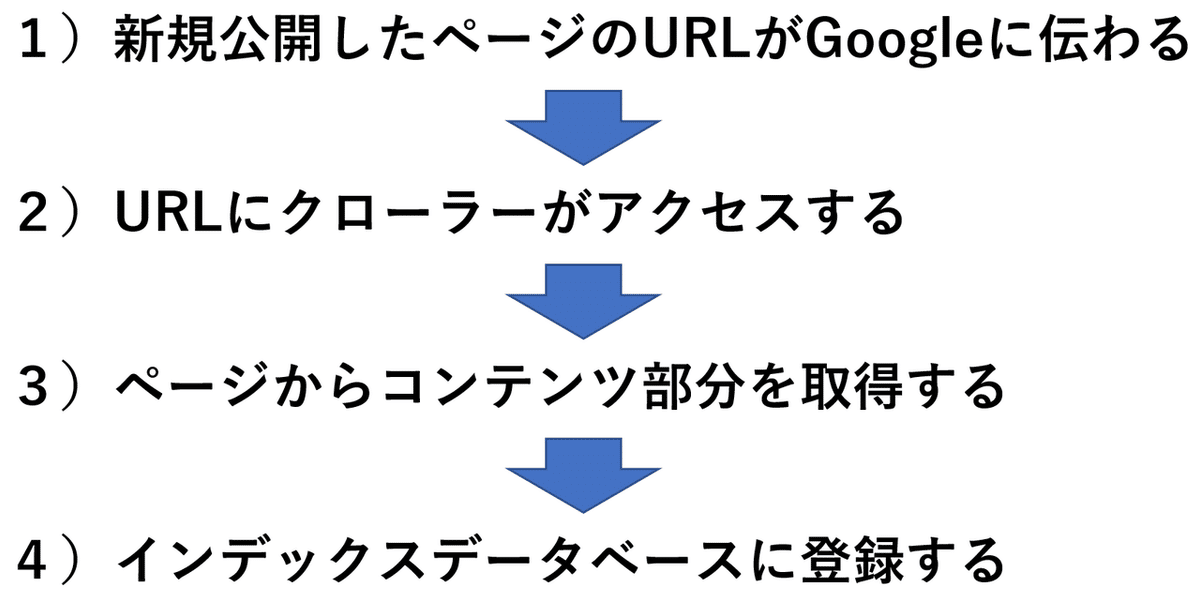
1)新規公開したページのURLがGoogleに伝わる
新たに公開したWebページの場合、その存在はWebページのオーナー(作者)しかしりません。
いち早くGoogleにインデックス登録してもらうには、公開したWebページのURLを伝える必要があります。
URLを伝える手法として下記が挙げられます:
・XML/RSS/TXT サイトマップ
・内部リンク(HTMLサイトマップ)
・外部からのリンク
・PubSubHubbub
・Index API
・サーチコンソールのURL検査ツール
毎日、大量の新しいWebページが公開される大規模サイトであればXMLサイトマップなどを有効活用し、新URLの存在をGoogleに知らせる必要があります。
しかし、ブログサイトや企業のオウンドメディアなど小~中規模のサイトで、新しいWebページが常にTOPページに表示されるようなCMS(Wordpressなど)を利用している場合は、通常のクローリングによって新URLが発見されるため、XMLサイトマップなどで意図的にURLをGoogleに伝える必要性は低いと考えられます。
2)URLにクローラーがアクセスする
Googleが検出したURLにクローラーがアクセスし、Webページのコンテンツを取得しようと試みます。
クローラーが問題なくアクセスできているか否かを確認する方法は下記の通りです:
・サーチコンソールのURL検査ツール(ライブテスト)
・リッチリザルトテスト
基本的にはサーチコンソールのURL検査ツールを使って確認します。
リッチリザルトテストでは、レンダリングされたHTMLも確認でき、Vue.jsなどを活用しページをレンダリング生成するような場合でも、正しくGoogleクローラーがレンダリングできているかその場で確認できます。

3)ページからコンテンツを取得する
いわゆる「パース (Parse)する」工程を指します。
クローラーが取得した(GETリクエストで取得した)Webページをレンダリングし、ユーザーがWebブラウザで見る形と同じ状況下にし、コンテンツを取得&解析する工程です。
『GooglebotがJavaScript を処理する仕組み』で説明されている「処理」がこれに該当します。
4)インデックスデータベースに登録する
クローラーとレンダーによってGoogleがコンテンツを取得できたとしても、必ずしもインデックスに登録されるわけではありません。
例えば、コンテンツがほとんど無い白紙に近いページや、他のWebサイトやサイト内の他Webページとコンテンツが重複している場合は、コンテンツの品質が一定基準を下回っていると判断され、インデックスに登録されない事があります。
もし、クローラーのアクセスもあり、問題なくレンダリングできているにも関わらず、インデックス登録の率が低い場合は、掲載コンテンツの品質を見直すと良いでしょう。
サチコの「インデックス登録」は最強!?
インデックス登録までの流れをざっくり4つの工程で考えた場合、サーチコンソールの「インデックス登録」は、最も強制力があると分かります。

他の手法と比較しても「URLの通知→クローリング→インデックスDBへの登録」までリアルタイムで実行されるため、一秒でも早くインデックス登録を試みるには最も効果的といえるでしょう。
では、他の手法で次に効果的なものはどれでしょうか?
インデックス登録までの工程を4つに分けて考えた場合、インデックスDBへの登録に作用があるのはサーチコンソールのみと言えます。
では、2番目の工程「クローリング」までに限定して手法を評価すると、直接的な作用を持つ手法は「Indexing API」と「サイトマップ」の2つであると考えられます。
Indexing APIを検証
Indexing APIとは2018年に公開されたインデックス登録を操作できるAPIを指します。
もともとは、しごと検索向けのインデックス操作を目的としたAPIとして公開され、今現在もIndexing APIの説明には「JobPostingまたはBroadcastEventがあるページのみ使用できる」と書かれています。
現在、Indexing API は、JobPosting または BroadcastEvent が VideoObject に埋め込まれたページをクロールするためにのみ使用できます。
出典:https://developers.google.com/search/apis/indexing-api/v3/quickstart
しかし、先日下記のツイートが投稿されていました:
Google API Indexing working in Google Colab ✅
— Natzir (@natzir9) November 12, 2020
This URL has been submitted, crawled and indexed in less than 3 minutes: https://t.co/xSG94mc00o pic.twitter.com/5nExsF0R2y
このツイートによると「Indexing APIでURLを投稿したら3分以内にGoogleにインデックスされた」との事。
あれ、Indexing APIは仕事検索もしくはBroadcastEventにしか利用できなかったのでは?と思い、早速検証してみました。
■検証環境
SEO検証向けのWebサイトに約100ページほどの簡易的なコンテンツページを設置しました。

↑Wikipediaから取得した各地域の説明を表示したコンテンツ
■検証した内容
今回の実験で検証する内容は下記の通りです:
1)URLを通知したらクロールされるか?
2)何%のURLがクロールされるか?
3)どのくらい(時間)でクロールされるか?
4)JobPostingで無くとも利用できるか?
1~3の結果が「即時にクロールされ、通知したURLのほぼすべてがクロールされる」であれば、クローリング促進において有効な手法といえます。
また、4ではインデックス登録可否でその有効性を確認します。もし、クロールしてもインデックス登録されないのであれば、やはりJobPostingが埋め込まれていないと有効では無いと考える事ができます。
■APIを使うための環境構築
まず、サーチコンソールアカウントとGoogle APIの2者間を紐付ける必要があります。今回は、こちらのブログ記事を参考に設定しました。
次に、バッチ処理をするためのサーバーからGoogleAPIを操作するべく、PHPのライブラリをサーバーに導入しました。
Composerを使って最新のAPIクライントをインストールします。
composer require google/apiclient:"^2.7"Indexing APIにURLを通知するPHPスクリプトは下記のような簡単なものを作り、実行しました。
<?php
require_once 'vendor/autoload.php';
$client = new Google_Client();
$client->setAuthConfig('credentials.json');
$client->addScope('https://www.googleapis.com/auth/indexing');
$httpClient = $client->authorize();
$api = 'https://indexing.googleapis.com/v3/urlNotifications:publish';
$data = "{
\"url\": \"https://*********/indextest.php?id=".$id."\",
\"type\": \"URL_UPDATED\"
}";
$res = $httpClient->post($api, ['body' => $data]);
$statusCode = $res->getStatusCode();
echo $content . $statusCode;用意した100ページ分をAPIを通して、Googleに通知していきます。

■検証結果
(検証1)URLを通知したらクロールされるか?
APIを通してURLを通知した後、アクセスログに変化があるかリアルタイムで見ていました(tail -fで追っていた)

↑実際のアクセスログ
APIを実行したのが2020-11-14 20:36ごろで、1分後にはGoogleのスマホクローラーが大量にアクセスしはじめました。
予想に反して、わずか1分足らずでGoogleクローラーが続々とアクセスし始めてきました。
当然、GoogleクローラーがアクセスしたURLは、すべてAPIで通知したURLのみである事から、Indexing APIによってクローラーが発動したのは明白であると考えられます。
(検証2)何%のURLがクロールされるか?
また、今回の検証では「APIで通知したURLすべてに対してクローラーのアクセスを誘発できたか」という点を検証すべく、URLにID番号をつけました。
100ページ分を通知したのに対し、実際に回遊があったのは97ページ分。したがって、3ページ分はまだ未回遊であるものの、97%のURLが回遊されたことになります。

(検証3)どのくらい(時間)でクロールされるか?
時間別のGoogleクローラーのアクセス数を集計した結果が下記の通りです:
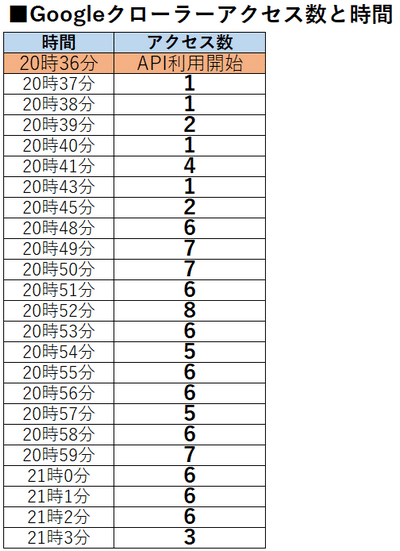
APIで送信直後からGoogleクローラーによるアクセスが発生し、20分間を経過したころから、10秒に1回以上の間隔でクローラーがアクセスし始めます。
今回の検証では、100ページ分のアクセスをGoogleBotが終えるまでに要した時間は約30分(単純計算、1ページあたり18秒でクロールしている計算)でした。
(検証4)JobPostingで無くとも利用できるか?
「利用できる=インデックス登録に作用する」とした場合、APIで送信したURLはどれくらいインデックス登録されるのか?を確認しました。
まずはサーチコンソールのURL検査を使い、各URLの状況を確認していきます。
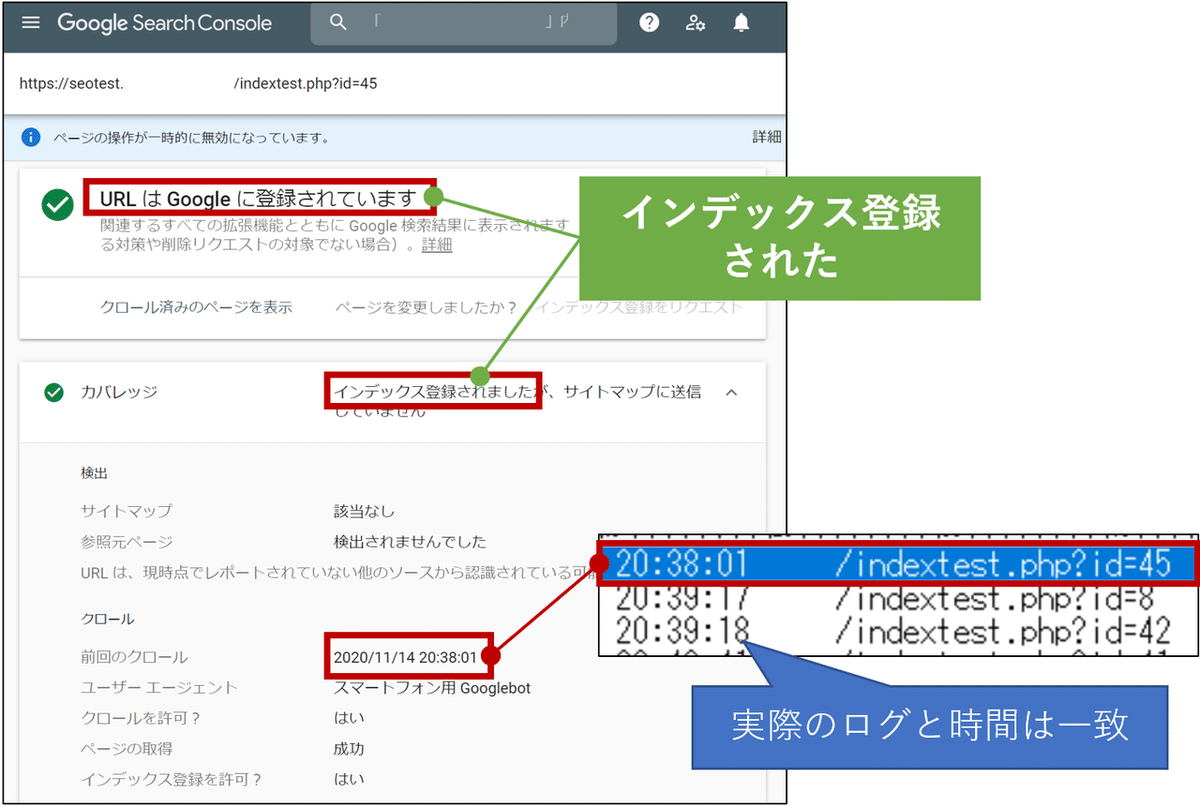
100URLのうち20個をランダムサンプリングし、手動でサーチコンソールのURL検査をチェック。結果、20個のURLすべてが「URLはGoogleに登録されています」という結果になりました。
また、サーバー側のログのアクセス時間とサーチコンソールの時間が一致している事から、Indexing APIで呼び寄せたクローラーは正式なWeb検索向けのクローラーであったという事も確認できました。
しかし、「site:検索」で確認した所、3ページしかインデックスが表示されなかったのも事実です。

なぜサーチコンソールの結果とsite:の結果が一致しないのかは不明ですが、検証した当日中にはGoogle検索結果には表示されませんでした。
---------------------------------------
以上の結果から、下記の結果になりました。
1)URLを通知したらクロールされるか?
→ クロールされる(Indexing APIは有効)
2)何%のURLがクロールされるか?
→当検証結果では97%
3)どのくらい(時間)でクロールされるか?
→約1分程度。ほぼリアルタイムと考えて良いスピード
4)JobPostingで無くとも利用できるか?
→利用できる。インデックス登録も確認できた。しかし、SERPs表示には時間を要している?
※Update
site:検索で表示されるインデックス数は時間の経過と共に徐々に増えています。実際に検索結果に表示されるには時間を要するようです。
Indexing API検証を終えて
今回の検証を終えて、Indexing APIは通常のWeb検索向けインデックス登録にも有効活用ができる、という事がわかりました。
しかしながら、デメリットもあります。
まず、現時点でGoogleがアナウンスしている当APIの利用目的はJobPosting または BroadcastEventが埋め込まれたページのクロールになります。
通常のWebページをクロールさせるためのAPIでは無い為、この使い方が安定的かつ継続的に保証されるわけではありません。
また、当APIには制限があり、1日あたり200回までしか利用できません。
これは、1日あたりに送信できるURLが200本までという事を指します。
コンテンツを主体としたWebメディアであれば200本でも十分ですが、データベース型の大規模サイトであれば、200本は極めて少なく、新URLの通知をこのAPIだけでカバーする事はできません。
Google社に申請する事で制限を緩和することもできますが、サイトマップのような膨大なURLの通知をするための仕様ではないように思われます。
大規模サイトの場合は、引き続きサイトマップの有効活用を模索するのが望ましいでしょう。
この記事が気に入ったらサポートをしてみませんか?