
書記が数学やるだけ#573 判別分析の計算,数量化2類

判別分析について考える。
問題

説明
判別分析では,どちらの群に属するかを推測するための手法である。

データ間の距離を示すのに,マハラノビス距離がよく出てくる。

解答
マハラノビス距離により,線形判別関数が記述できる。

1変数の場合については手計算で動かしてみる。
#必要なライブラリ
from sklearn import datasets
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
#irisデータセット
dataset = datasets.load_iris()
target_names = dataset.target_names
targets = dataset.target
feature_names = dataset.feature_names
features = dataset.data
df = DataFrame(features, columns = feature_names)
df['target'] = target_names[targets]
df.head()#"petal length (cm)", "sepal length (cm)"のみ
df1 = df[["petal length (cm)", "sepal length (cm)", "target"]]
#"virginica"を除去
df1 = df1[df1['target'] != "virginica"]
#ラベル名を変更
df1 = df1.replace({'setosa': 'S', 'versicolor': 'V'})判別関数に必要なパラメータを求めておく。
#Sのパラメータ(サンプル数,平均,分散)
df1_S=df1[df1["target"]=="S"]
n_S=len(df1_S)
x_S=df1_S["sepal length (cm)"]
mu_S=x_S.sum()/n_S
s11_S=((x_S-mu_S)**2).sum()
print("Sのサンプル数=", n_S, ",平均=", mu_S, ",分散=", s11_S)Sのサンプル数= 50 ,平均= 5.006 ,分散= 6.088200000000001
#Sのパラメータ(サンプル数,平均,分散)
df1_V=df1[df1["target"]=="V"]
n_V=len(df1_V)
x_V=df1_V["sepal length (cm)"]
mu_V=x_V.sum()/n_V
s11_V=((x_V-mu_V)**2).sum()
print("Vのサンプル数=", n_V, ",平均=", mu_V, ",分散=", s11_V)Vのサンプル数= 50 ,平均= 5.936 ,分散= 13.055200000000001
#SV合算の平均,分散
mu_bar_hat=(mu_S+mu_V)/2
sigma2_hat=(s11_S+s11_V)/((n_S-1)+(n_V-1))
print("SV合算の平均=", mu_bar_hat, ",分散=", sigma2_hat)SV合算の平均= 5.471 ,分散= 0.19534081632653064
これらより,判別関数を示すことができる。
#線形判別関数の推定式
print("線形判別関数の推定式:z=", ((mu_S-mu_V)*(mu_bar_hat)/sigma2_hat), "+", -(mu_S-mu_V)/sigma2_hat, "x")線形判別関数の推定式:z= -26.04693732565792 + -4.7609097652454615 x
各データの値を代入して,SとVのどちらに属するかを決める。
#線形判別関数の代入値
df1["z_hat"]=(mu_S-mu_V)*(x-mu_bar_hat)/sigma2_hat
df1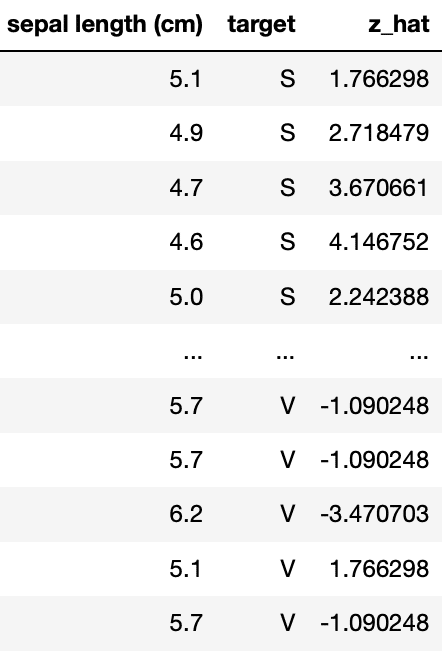
#判別予想
df1['pre_target'] = np.where(df1['z_hat']>=0, 'S', 'V')
df1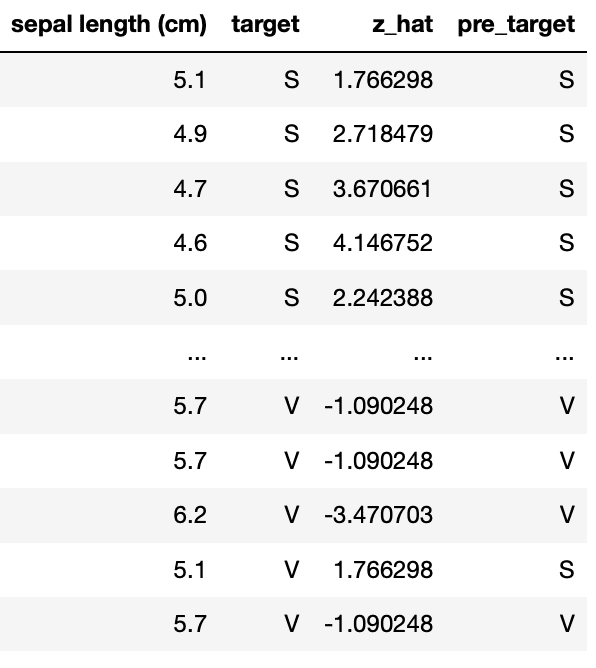
判別表を作成しておく。
#推定と実際の比較
pd.crosstab(df1['target'], df1['pre_target'])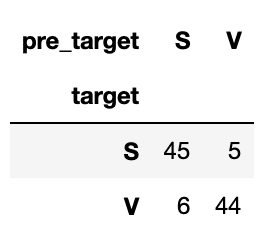
#実際のデータ
sns.scatterplot(x='sepal length (cm)', y='petal length (cm)', hue='target', data=df1)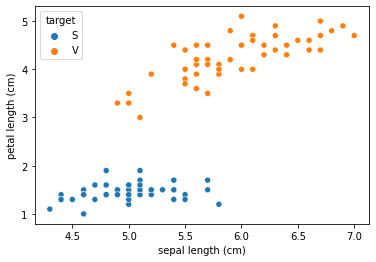
判別関数により,赤線で区切り分けがされることがわかる。
#判別の推定(赤線が基準)
sns.scatterplot(x='sepal length (cm)', y='petal length (cm)', hue='pre_target', data=df1)
plt.vlines(mu_bar_hat, 0, 7, colors='red', linewidth=3)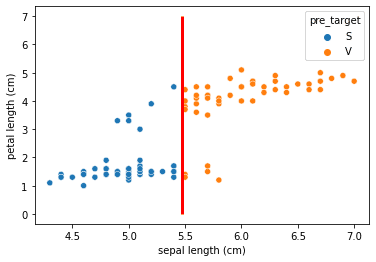
次に2変数について,sklearnのLinearDiscriminantAnalysisを用いることにする。
#LDAの実行
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
x = df1.drop('target', axis=1).values
y = df1['target'].values
lda = LinearDiscriminantAnalysis()
lda.fit(x, y)
print('係数', lda.scalings_)
cv = np.mean(np.dot(lda.means_, lda.scalings_))
print('定数値', cv)係数 [[ 3.55223051]
[-1.26818713]]
定数値 3.2246797126482476
これにより以下の境界を得る。
sns.scatterplot(x='sepal length (cm)', y='petal length (cm)', hue='target', data=df1)
x1 = np.linspace(4, 8, 100)
plt.plot(x1, -(x1 * lda.scalings_[1][0] - cv) / lda.scalings_[0][0], c='red', linewidth=3)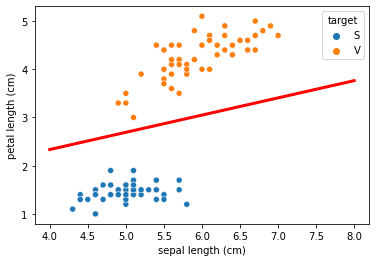
本記事のもくじはこちら:
この記事が参加している募集
学習に必要な本を買います。一覧→ https://www.amazon.co.jp/hz/wishlist/ls/1XI8RCAQIKR94?ref_=wl_share