
書記が数学やるだけ#823 項目反応理論モデルの推定

項目反応理論モデルの推定について,手順を追って説明する。
問題

説明
前回示したロジスティック回帰モデルは,最尤法やベイズ統計などを用いて解析することができる:


異なるテスト同士の比較では,等化という手法を用いる。

解答
まず,能力パラメータの最尤推定を導出する。

テストパラメータを推定する方法として,能力パラメータとの同時最尤推定や,能力パラメータを周辺化して除いた周辺最尤推定などが挙げられる。また,これを
応用してベイズ統計により解くことも可能である。

項目反応理論におけるフィッシャー情報量をテスト情報量といい,さらに項目ごとに項目情報量が定義できる。

ここでは,PyMC3によるベイズモデルを実装する,ロジスティック回帰モデルの
応用と考えれば良い。
import pymc3 as pm
import numpy as np
# データの準備
responses = np.array([[1, 1, 1, 1, 0],
[1, 1, 1, 0, 0],
[1, 1, 0, 0, 0],
[1, 0, 0, 0, 0]])
num_items = len(responses[0])
num_people = len(responses)
# モデルの構築
with pm.Model() as irt_model:
# 能力パラメータを事前分布を指定して定義
ability = pm.Normal('ability', mu=0, sd=1, shape=num_people)
# 項目パラメータ(難易度および識別力)を事前分布を指定して定義
item_difficulty = pm.Normal('item_difficulty', mu=0, sd=1, shape=num_items)
item_discrimination = pm.HalfNormal('item_discrimination', sd=1, shape=num_items)
# 項目特性曲線(Item Characteristic Curve, ICC)を定義
theta = ability[:, np.newaxis] - item_difficulty
logits = item_discrimination * theta
# 応答確率のロジスティック関数
p = pm.math.invlogit(logits)
# データ生成分布を指定
observed = pm.Bernoulli('observed', p=p, observed=responses)
# 推定
with irt_model:
trace = pm.sample(1000, tune=1000)
# 推定結果の確認
pm.summary(trace)
pm.traceplot(trace)
pm.plot_posterior(trace)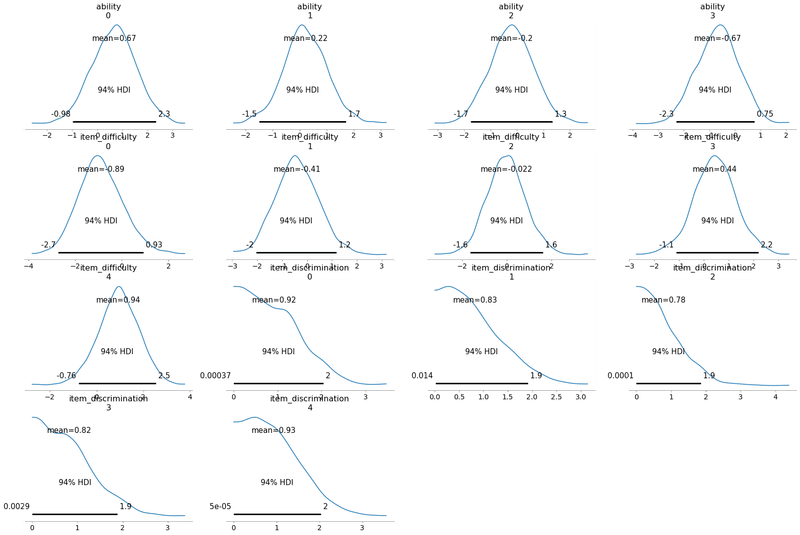
テスト情報関数の実装は以下の通り。
#テスト情報関数を計算する関数
def compute_test_information(ability_values, item_difficulty, item_discrimination):
theta = ability_values[:, np.newaxis] - item_difficulty
logits = item_discrimination * theta
p = 1 / (1 + np.exp(-logits))
information = item_discrimination**2 * np.exp(-logits) / (1 + np.exp(-logits))**2
test_information = np.sum(information, axis=1)
return test_information
# モデルからサンプリングされたパラメータの事後分布からランダムサンプルを抽出
sampled_ability = trace['ability'][::10]
sampled_item_difficulty = trace['item_difficulty'][::10]
sampled_item_discrimination = trace['item_discrimination'][::10]
# テスト情報関数の計算
ability_values = np.linspace(-3, 3, 1000)
test_information_values = np.zeros((len(sampled_ability), len(ability_values)))
for i in range(len(sampled_ability)):
test_information_values[i, :] = compute_test_information(
ability_values, sampled_item_difficulty[i, :], sampled_item_discrimination[i, :]
)
# テスト情報関数の可視化
plt.figure(figsize=(10, 6))
plt.plot(ability_values, np.mean(test_information_values, axis=0), label='Mean Test Information')
plt.fill_between(
ability_values,
np.percentile(test_information_values, 2.5, axis=0),
np.percentile(test_information_values, 97.5, axis=0),
alpha=0.3,
label='95% CI'
)
plt.title('Test Information Function')
plt.xlabel('Ability')
plt.ylabel('Test Information')
plt.legend()
plt.show()
同様に項目反応関数も実装する。
#項目情報関数を計算する関数
def compute_item_information_function(ability_values, item_difficulty, item_discrimination):
theta = ability_values[:, np.newaxis] - item_difficulty
logits = item_discrimination * theta
information = item_discrimination**2 * np.exp(-logits) / (1 + np.exp(-logits))**2
return np.sum(information, axis=1)
# 計算と可視化
ability_values = np.linspace(-3, 3, 1000) # ポイントの数を増やす
plt.figure(figsize=(12, 8))
for i in range(num_items):
plt.subplot(2, 3, i + 1)
# 寸法を一致させるためにability_valuesを再計算
computed_ability_values = np.linspace(-3, 3, 1000)
plt.plot(computed_ability_values, compute_item_information_function(
computed_ability_values, sampled_item_difficulty[:, i], sampled_item_discrimination[:, i]
), label=f'Item {i + 1}')
plt.title(f'Item Information Function - Item {i + 1}')
plt.xlabel('Ability')
plt.ylabel('Information')
plt.legend()
plt.tight_layout()
plt.show()
異なるテスト間における尺度変換と,mean-sigma法における等化係数を導出する。

本記事のもくじはこちら:
学習に必要な本を買います。一覧→ https://www.amazon.co.jp/hz/wishlist/ls/1XI8RCAQIKR94?ref_=wl_share