書記のBio/Chem-Info日誌#20 深層学習を用いた分子記述子による薬理活性の推定(PyTorchによる実装)

今回は深層学習を用いた分子記述子による薬理活性の推定を,PyTorchによる実装で示していく。
問題
「CHEMBL203」に含まれる化合物について,EGFR kinaseに対する阻害活性の有無を,pIC50により評価したい。化合物を示すデータとしては,分子記述子を使用する。
データの前提条件
データはKNIMEのTeachOpenCADDにある「W2_filtered_compounds.csv」を使用する。本データでは,CHEMBL203の分子のうち,ルールオブファイブを満たすものを抽出している。
参考;
データの前処理
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader
from rdkit import rdBase, Chem
from rdkit.Chem import AllChem, PandasTools, Descriptors
from rdkit.Chem.Draw import IPythonConsole#csvファイルの読み込み
df = pd.read_csv("W2_filtered_compounds.csv")
df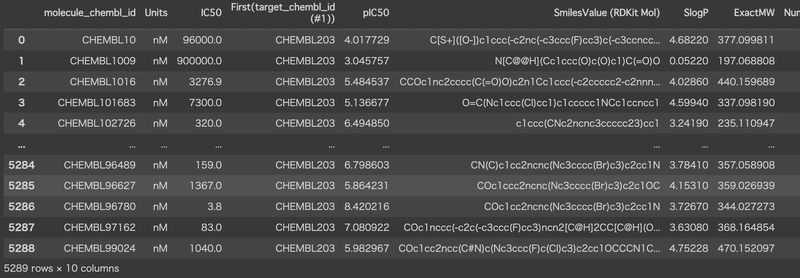
阻害活性について,「pIC50>6.3」を活性ありとする。
#阻害活性の有無を”A"に格納
df.loc[df['pIC50'] > 6.3, 'A'] = 1
df.loc[~(df['pIC50'] > 6.3), 'A'] = 0df["A"].value_counts()1.0 3143
0.0 2146
Name: A, dtype: int64
次に,必要な列のみを抽出する。「SmilesValue (RDKit Mol)」は分析では使用しないが,分子記述子の生成に必要なので抽出する。
df2 = df[["SmilesValue (RDKit Mol)", "A"]]
df2
分子記述子は,Descriptors.descListを各Smilesごとに実行することで生成される。これで必要なデータは揃った。
参考:
PandasTools.AddMoleculeColumnToFrame(df2,'SmilesValue (RDKit Mol)')
for i,j in Descriptors.descList:
df2[i] = df2.ROMol.map(j)
df2.head()
Tensor型への変換
PyTorchによる計算を行うには,Tensor型への変換が必要である。
まず独立変数Xについて,上の表から'SmilesValue (RDKit Mol)',"ROMol","A"を除いたものである。
ここで標準化(平均0分散1に正規化)をして,極端に大きな値にならないよう調整する(これをしないと正しく計算できない)。
#独立変数X
X = df2.drop(['SmilesValue (RDKit Mol)',"ROMol","A"], axis = 1)
#一つでも欠損値があれば除去
X = X.drop(X.columns[np.isnan(X).any()], axis=1)
#列ごとに標準化
X = X.apply(lambda x: (x-x.mean())/x.std(), axis=0)
X = X.drop(X.columns[np.isnan(X).any()], axis=1)
X
従属変数Yは"A"の値である。
Y = df2["A"]
Y次に,train用のデータとtest用のデータを分割する。これはsklearn.model_selectionにあるtrain_test_splitで簡単に実行できる。
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size = 0.25)ここまでpandasのデータを扱ってきたが,ここでPyTorchのTensor型へ変換する。独立変数はFloat型,従属変数はLong型とする。
train_X = torch.FloatTensor(train_X.values)
train_Y = torch.LongTensor(train_Y.values)
test_X = torch.FloatTensor(test_X.values)
test_Y = torch.LongTensor(test_Y.values)次に,TensorDatasetを作成する。ちなみに,チュートリアルのMNISTはこの型から始まっており,自作データを用いる際は以上の手順を踏んでTensorDatasetを自作する必要がある。
train=torch.utils.data.TensorDataset(train_X, train_Y)
train[0]概ね以下のように表示されていれば成功している。

さらにDataLoaderの作成を行う,これによりバッチ処理を容易に行うことができる。
train_loader = torch.utils.data.DataLoader(train, batch_size=32, shuffle=True)
test=torch.utils.data.TensorDataset(test_X, test_Y)
test_loader = torch.utils.data.DataLoader(test, batch_size=32, shuffle=True)ここまでがTensor型への変換である。自作データを用いる場合,「Tensor型へ変換→TensorDatasetを作成→DataLoaderの作成」が一つの難関と思われる。
深層学習の実装
データさえ整えば,あとは計算するだけ。
モデルについて,PyTorchのチュートリアルにあるものをいつ部変更したものを使用した。入力を182次元,出力を2次元とさえすれば,中身はなんでも良い(が,重み行列の次元でも精度は大きく変わりうる):
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.linear_relu_stack = nn.Sequential(
nn.Linear(187, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 2),
nn.ReLU()
)
def forward(self, x):
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
print(model)NeuralNetwork( (linear_relu_stack): Sequential( (0): Linear(in_features=187, out_features=512, bias=True) (1): ReLU() (2): Linear(in_features=512, out_features=512, bias=True) (3): ReLU() (4): Linear(in_features=512, out_features=2, bias=True) (5): ReLU() ) )
ここで損失関数CrossEntropyと,最適化の手法SGDを指定しておく。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)学習は以下のコードで実施した。
for epoch in range(5000):
total_loss = 0
for train_x, train_y in train_dataloader:
optimizer.zero_grad()
output = model(train_x)
loss = criterion(output, train_y)
loss.backward()
optimizer.step()
total_loss += loss.item()
if (epoch+1)%50 == 0:
print(epoch+1, total_loss)100 50.77189637720585
200 39.08833669126034
300 28.41612298041582
400 19.720915339887142
500 13.404347594827414
600 9.27785163372755
700 6.6366918804124
800 5.03389000473544
900 3.9686651369556785
1000 3.2751896237023175
最後にテストデータの当てはまりの良さを見ておく。
result = torch.max(model(test_X).data, 1)[1]
accuracy = sum(test_Y.data.numpy() == result.numpy()) / len(test_Y.data.numpy())
accuracy0.8087679516250945
それなりの精度は出せたので,今回はここまでとする。
今回はPyTorchによる深層学習を,自作データから実施した。チュートリアルではないようなトラブルが多数あり,今後の実装の参考にするつもりである。
本記事のもくじはこちら:
リニューアル
学習に必要な本を買います。一覧→ https://www.amazon.co.jp/hz/wishlist/ls/1XI8RCAQIKR94?ref_=wl_share