PyCaretのデータセットで遊ぶ #1 「bank」

1日1回くらいのペースでPyCaretで遊んだ結果を書いていこうと思います。
最初の初回ではbankのデータを使って分類問題を解いていこうと思います。
まずデータを取得してきます。
//python
from pycaret.datasets import get_data
from pycaret.classification import *
df_bank = get_data('bank')
分かる範囲でになりますが、データの内容です。
データ数は45211件になります。
次にデータの前処理をします。
//python
categorical_features = ['job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'month',
'poutcome']
set_data = setup(data=df_bank,
target='deposit',
train_size=0.9,
categorical_features=categorical_features)そしてモデルを比べてみます。
//python
compare_models()
lightgbmが一番よさそうだったのでこれで行きましょう。
//python
model = create_model('lightgbm')
model = tune_model(model, optimize='Accuracy')
モデルを選択し、チューニングして交差検証をします。
これでモデルが完成。PyCaret簡単すぎてやばいですねw
//python
predict_model(model)未知データを使った予測です。最初の前処理の時に訓練データとテストデータで分けてくれているのでこれだけで予測結果を出せます。

正解率が9割を超えているのでかなり精度高く予測できてるかもしれないですね。ここからは図をプロットしてみていきましょう。
//python
plot_model(model, plot='confusion_matrix')
混合行列をプロットしてみる。
見てもらうとわかりますが、ラベル1の予測精度が低いですね。
//python
plot_model(model, plot='class_report')
こちらでは濃い色の方がよりスコアが高いです。やはりラベル1はかなり精度が悪いですね。
//python
plot_model(model, plot='boundary')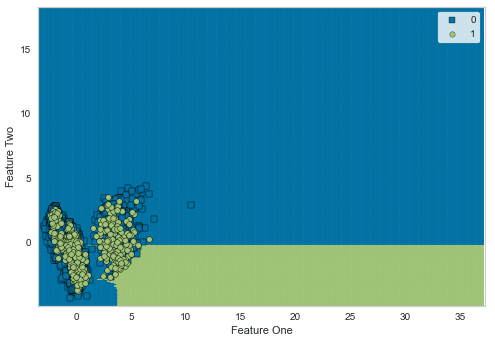
決定境界をプロットしてみましたが、かなり重なり合っててうまく分類できていないことが分かります。
//python
plot_model(model, plot='learning')
学習曲線を見てみると、過学習も起こさず順調に精度をあげているので、もう少し多めに学習できると、ラベル1もちゃんと精度が出るかもですね。
最後に特徴量がどのように結果に影響を及ぼしているのか確認しましょう。
//python
plot_model(model, plot='feature')
一番影響しているのは債権の残存期間ですね。
この記事が気に入ったらサポートをしてみませんか?