
AIイラストが理解る!StableDiffusion超入門【2024年夏最新版】A1111、Forge対応

こんにちは、2022年10月からAIイラストの技術解説記事をweb連載してます、賢木イオです。この記事は、これまでFANBOXで検証してきた120本(約70万文字)を超える記事をもとに、2024年春現在、画像生成を今から最短距離で学ぶための必要情報をまとめたメインコンテンツです。
これから画像生成を学びたい初心者の方や、手描きイラストにAI技術を取り入れてみたい方が最初に読む記事として、必要知識が網羅的に備わるよう解説しています。素敵なイラストを思い通りに生成するために覚えるべきことを紹介しつつ、つまずきやすいポイントや参照すべき過去記事、やってはいけないことなどを紹介していますので、最初にこの記事から読んでいただくとスムーズに理解できるはずです。
解説役は更木ミナちゃんです。よろしくお願いします!

画像生成AIの仕組みをざっくり解説
まず最初に、画像生成AIがどうやってイラストを出力しているのかについて、難しいこと一切抜きの「イメージ」で簡単に解説します。
画像生成AIは、教師データとなる無数の画像とテキストのペアから学習することで、テキスト指示に応じた新しい画像を出力することができるAIです。そうした訓練を積んだAIのことを「学習済みモデル」と呼びますが、この記事で紹介する「StableDiffusion(以下SD)」もその一つです。text-to-image(=文章から画像)と言って、「プロンプト」と呼ばれるテキストで指示すると、AIが何を生成したらよいかを判断して、適切な画像を出力することができます。
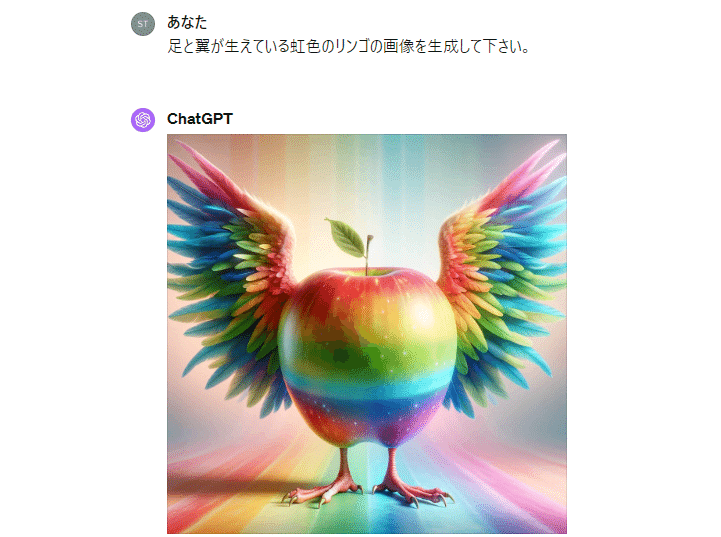
例えば「1girl,sky,smile」と指示されたら、AIはこのように笑顔の少女と空が描かれたイラストを生成できます。

「潜在拡散モデル」と呼ばれる学習済みモデルは「ノイズを加えた画像からノイズを取り除いて元画像に戻す訓練」を積んでいます。例えば「これはリンゴだよ」と言われてノイズで汚れた画像を見せられたら、ノイズを除去してきれいなリンゴの画像を出力できるようにする訓練です。その訓練をひたすら繰り返していくうち、AIは全く無意味なノイズ(砂嵐画像)からでも、テキスト指示通り「赤くて丸いリンゴらしい画像」を推測できるようになるわけです。
例えば、「虹色」や「足が生えている」「翼がある」の概念を個別に学んだAIであれば、教師データに存在しない「翼と足が生えている虹色のリンゴ」が生成できます。
画像生成はコラージュなのか?
よくある誤解として、「AIはイラストを切り貼りしてコラージュしている」というものがありますが、教師データであるイラストそのものはAIの中には記憶されていません。もし何十億枚という教師データを全て記憶していたなら、数GB程度で済むはずがありませんよね。AIは学習した画像そのものを使うのではなく、テキストとのペアから学んだ「特徴・傾向」に従って存在しないイラストを生成しているのです。

ただ、「女の子」という概念を学ぶとき、片手を上げた初音ミクの画像1枚でしか学んでいないモデルがあったとしたら、「女の子を描いて」と指示すると、片手を上げた青いツインテールの女の子を描いてしまいます。AIはテキストの意味を理解しているかのように振る舞えるだけで、本当の意味で理解しているわけではないのです。「教師データそのものを出してはならない」という感覚もないため、学習や生成の仕方によっては教師データそっくりなものが意図せず生成されることがあります。
ただ女の子を生成するつもりが、誰かが描いたミクさんイラストにそっくりな画像が出てきたら困りますね。よほど意図して学習内容と指示内容を偏らせないとそんなことは起きませんが、ユーザーが生成したものをよく見て、公開してよいか判断することが非常に重要となります。
実際の生成の様子
画像生成は「ステップ」と呼ばれる段階を踏んで行われます。無意味なノイズから「存在しない元画像」を推測する過程を1ステップ、2ステップと繰り返すことで、より鮮明・高画質なイラストができあがっていくわけです。さきほどのイラストの生成過程を見てみますと…

AIくんは最初、まったく無意味なノイズ画像を渡されて「これは空と笑顔の女の子の画像だよ、ノイズを取り除いてごらん」と言われます(Step0)。健気なAIくんは教師データから学んだ傾向に従って、なんとなくそれらしい感じにノイズを取り除き、ちょっぴり「少女・笑顔・青空」っぽい何かができていきます。
その画像が再度AIに渡されて、ノイズを同じように取り除くと、だんだんと空や人間らしきものが浮かび上がってきます。何度もこの工程(ステップ)が繰り返される中で、AIくんはなんとなく「青い空と白い雲、中央に何か黒っぽいもの」を見出したようです。それをさらに元画像としてノイズ除去していくうちに、黒いものを女の子の服にしたり、雲の一部を髪の毛と解釈したりとブラッシュアップが進んでいったことが分かります。
このように、画像生成AIは「青空を背景に立つ笑顔の女の子」のイラストを教師データの中から検索して、それを基に「切り貼り」しているわけではなく、連想ゲームのように指示通りの画像に近づけているのです。
ただし、AIは「読み込ませた画像のコラージュ」に近い行為をすることもできます。それは「text2image」ではなく「image2image」と呼ばれる別の仕組み。それについては後述します。
どこで、どうやって生成するのか
さて、我々がAIイラストを楽しむ方法は、大きく分けて次の2つがあります。
①自分のパソコンにツールをインストールして使う(StableDiffusion系)
②ウェブ経由でAI画像生成サービスを使う(NovelAI、midjourneyなど)
この記事で紹介するのは、①の「ローカル生成」です。①は電気代以外は無料で利用でき、利用するモデルも自由に選べるのが特徴。自宅PCでNSFW(Not Safe for Work、職場で見られない=成人向け)を含む好みのイラストを無限に生成できる代わりに、GPU性能をはじめとしたある程度のマシンスペックが要求されます(※高性能GPUをクラウド経由でレンタルすることは可能)
一方、②の「ウェブサービス系」は月額利用料金が掛かることが多いですが、自分の端末上で生成が行われないため、ネット環境さえあればスマホからでも気軽に楽しめるのがメリットです。NSFW画像が生成できないなど、ある程度の制限があります。
NovelAIとかNiji journeyって?
本題の①について説明する前に、ざっと「②」の画像生成サービスにどんなものがあるかについても触れておきましょう。覚えておきたいのはDALL-E3、Midjourney(Niji journey)、NovelAIの3つです。
まず、23年9月にOpenAI社が発表した画像生成AI「DALL-E3」。ChatGPTに日本語で指示することで枚数制限なく生成が可能で、実写調もイラスト調も強いです。Microsoftの「Image creator」経由なら誰でも無料で生成できるため、画像生成入門にはもってこいと言えます。
二次元イラストで圧倒的に強いのは「NovelAI」。いわゆる版権キャラクターやNSFW(成人向け)画像の生成に制限がなく、生成精度も高いことで非常に人気です。特に、画像の一部を塗りつぶして手直しする「インペイント機能」が圧倒的に優れており、何度もインペイントを繰り返すことで思ったとおりのポーズや表情に「寄せる」ことが可能です。
先駆者的存在「Midjourney(Niji Journey)」も根強い人気を誇っています。Midjourneyは実写調や絵画風、Niji Journeyは日本のアニメイラスト風の生成が得意で、最低月10ドル(年払いだと月8ドル)から利用可能。契約すると両方で生成が可能になります。生成はDiscord上、もしくは公式サイト上で行われます。
これらのサービスはどれか一つだけを使ってもよいですが、ローカル生成と組み合わせることで、より自分の意図したイラストを生成できるようになります。商用利用の可・不可などが異なるため、よく規約を読んで利用しましょう。
SD生成に必要な「WebUI」とは
さて、話をSDに戻しましょう。この記事では①のローカル生成について紹介するわけですが、StableDiffusionをローカル環境(自分のパソコン)で使うための代表的ツールが「StableDiffusionWebUI」です。AUTOMATIC1111氏が配布しているため、「A1111版SDwebUI」とか「A1111」などと略されることも多いです。

多くのユーザーがこちらのツールを使ってAIイラスト生成を行っており、より正確に絵作りを指示できる「Controlnet」や「LoRA」といった拡張機能や、さまざまな特徴を持った学習モデルなどが日々公開され続けています。
ちなみに、主流派であるA1111版SDwebUIのほかにも、「Forge」や「ComfyUI」、「Fooocus」などさまざまなWebUIが登場しており、ユーザーの生成環境は枝分かれしています。特に、今年2月に登場した快速webUI「Forge」は、ほぼA1111版と同じ見た目と使い勝手なのに生成速度が非常に早いため、急速に乗り換えが進んでいます。「ComfyUI」はA1111版より詳細なワークフローを設定できるのが特徴で、操作が上級者向けのUIとして知られています。

生成するのが特徴(公式Githubより引用)
「StableDiffusion」やその派生モデルと各種webUIの関係は、ゲームソフトとハードの関係とよく似ています。無数の種類があるモデルの中から好きなものを選び、ハードに差して遊ぶのです。ソフトが同じなら基本的に同じ画像が生成できますが、「ハードが違うと入力画面や各種モードの使い勝手が違うよね」程度に理解していればOKです。
画像生成AIをまず触ってみたい人は・・・
AIイラストを全く触ったことがなく、グラフィックボードなどを買おうか迷っている方は、StableDiffusionに挑戦する前にまず「DALL-E3」や「NovelAI」を先に体験してみることをおすすめします。「ImageCreator」では、Microsoftアカウントを作るだけでDALL-E3を今すぐ試せるので、初心者はまずこちらで遊び倒すのがいいでしょう。
「予備知識もグラボも不要で、簡単に高精細なイラストが作れるなら、もう全部DALL-Eでいいんじゃない?」となりそうですが、そうでもありません。DALL-Eは簡単な日本語指示で高精細な画像を生成できますが、逆に言えば「基本的にAIお任せ」なので、AIに言葉で伝えられないようなこまかな指示をしたり、間違えた部分を直したりするのが苦手です。22年9月から連綿と進化してきたStableDiffusionは、やや操作が難解ではあるものの、よりユーザーの感性を活かした自由な画像生成が可能となっているのです。

(水彩風で、実写風で、アニメ調でと指示することも可能)
Pixivで見られるような美麗なアニメイラストを生成したい方は、NovelAI(通称・NAI)をおすすめします。国内ではいったん廃れた時期もあったのですが、最新のバージョン3(NAIdiffusionV3)の性能がすさまじく、インペイント機能だけでも課金する価値があると断言できる性能を誇っています。日本語での生成はできませんが、日本語に対応したプロンプトの候補を表示する機能もありますので、英語が苦手な方も大丈夫。「プロンプト超辞典」を参考にしながら生成してみるとよいでしょう。
StableDiffusionに必要なマシンスペック
さて、SDWebUIやForgeで画像生成するためには、NVIDIA製「GeForce RTX20」シリーズ以降のグラフィックボードが搭載されたPCが必要です。
・グラフィックボード 映像をパソコン画面に出力するためのパーツ、通称グラボ。画像処理に特化して計算を行う半導体チップ「GPU」を搭載している。GPUはCPUやマザーボードに標準で搭載されていることが多いので、グラボがなくてもゲームや動画再生はできるが、負荷の強い画像処理を行うには必須。マザーボードの規格やPCケースによって、デカすぎてささらないこともあるので買う前にお店の人に聞こう。
・VRAM GPUに搭載されるビデオメモリ(の容量)。画面に表示する内容を一時的に保存するためのパーツで、大きいほど映像遅延がなくなる。グラボによってVRAM容量は異なり、画像生成においては何GBかがとても重要。できれば12GBあるとうれしい。
VRAMの容量は最低8GB、できれば12GB以上のものがないと、GPUに負担のかかる高画質な画像生成や複数同時生成が難しくなるとされています。基本的なイラスト生成だけを楽しむならVRAM8GBでも問題ありませんが、後述する「LoRA」などの追加学習を自前で行う場合は、最低12GB以上のグラボが欲しくなってきます。
こちらはツイッター上で実施された、AI術師の利用しているグラボのアンケート結果です。昨年1月時点とやや時間がたっていますが、おおむねユーザーの分布が想像できると思います。
お待たせしました
— ₿ え̤̮み̤̮ゅ̤̮ふ̤̮ぇ̤̮ず̤̮ ₿ (@EmilyPhase) January 29, 2023
第一回AIイラスト界隈グラボのTier表作成しました!
参加していただいた方、作成にご協力していただいた方本当にありがとうございました!
???になっているa girlさんの生成スピードがとんでもなく界隈最速だと思います。
動画の掲載許可をいただいたのでリプに掲載します! pic.twitter.com/qBMtIPsydG
一番のボリューム層が、スタジオ真榊でも使い倒したコスパ最強グラボ「RTX3060(12GB)」。RTX3060にはVRAM8GBモデルもあるのですが、もし購入するのであれば前述の理由で12GBモデルを強くオススメします。高価なグラフィックボードほど1枚の画像生成に掛かる時間が短縮され、高解像度なイラストの複数同時生成も可能になりますが、GPUの性能が低いと、生成途中にVRAMが圧迫され、しばしば「CUDA out of memoryエラー」(GPUのメモリ不足)が発生してしまうからです。
こちらは23年1月にRTX3060を購入したときと、23年12月にPCごと新しくしてRTX4080を導入したときの全体公開記事です。
CPUやメモリ、ストレージについても詳しく触れていますので、これからPCやグラボを購入して画像生成を始めたい方には参考になると思います。23年1月当時、RTX3060(VRAM12GB)は5万円以上しましたが、この記事を書いている24年3月現在は4万円を切っており、依然としておすすめなグラボとなっています。
さきほどの術師グラボTier表によると、RTX3060の次のボリュームゾーンはRTX3090、その次が最高峰のRTX4090です。画像生成AIとグラボについては、「ちもろぐ」さんのこちらの記事に大変詳しくまとまっており、あらゆるモデルの実力が網羅されているので、購入を検討されている方はぜひ参考にされてください。
グラボ以外のCPUやHDDは?
では、CPUやディスク容量についてはどうでしょうか。WebUIにおける画像生成は基本的にはGPU依存なので、よほど古いCPUを積んでいなければ大丈夫と言われています。ある程度生成速度には差が出るようですが、GPUほど明確な差は出ません。むしろ、画像生成や追加学習中にいろいろな作業をする場合は、メモリをできるだけ増設しておくことをおすすめします。

一方、HDD容量については、あればあっただけ良い!2TB欲しい!という感じです。学習モデルは一つあたり4~8GBほどありますし、ControlnetやLoRAなど拡張機能に必要なファイルもかなりストレージを圧迫します。さらに、外出中にも高解像度の画像をバカスカ無限生成していくとなると、最低でも100GBは開けておきたいところです。
おすすめなのは、HDDでなくSSDを増設して画像生成関連専用のドライブにしてしまうこと。スタジオ真榊では23年7月にこちらの中華SSDを12,980円で購入し、新しくしたRTX4080搭載PCでも使っています。ファイル転送や読み込みは早いし容量はたっぷり余裕があるし、マザーボードに直接差すだけで簡単だし、大変買って良かったです。PCの買い換え時にもそのまま付け外しするだけでしたので、お値段以上に活躍してくれました。
【コラム】独断と偏見の「松竹梅コース」
「PC知識があまりなく、グラボを買うのも初めて」という方にローカル生成向けおすすめ構成を答えるなら、私なら次のように回答します(24年3月現在)。もちろん、人によって意見はさまざまでしょうから、あくまでご参考まで。
【松:RTX4070Super】384,780円(税込)

「PC分からんけど40万までなら出せる」人向け。4070Superは最新・高性能の高額コスパモデル。Forgeの登場で、VRAM12GBが少ないと感じるシーンは減った。もしこれでVRAM不足と思ったら4070SUPERを売って、ハイエンド沼に踏み入ろう。
【竹:RTX3060(12GB)】10~15万円

「コスパ最高で間違いないやつがいい!」と言われたら、4万を切ったRTX3060(12GB)をすすめておけばまず異論は出ないはず。できればSSDは2TB、メモリは最低32GB、できれば64GBのBTOを注文したい。既にPCを持っていてグラボだけ欲しいという場合も、入門用なら3060が最初に思い浮かぶ。
【梅:NovelAI Opusプラン/月25ドル】10万円も出せない人
AIイラスト向けデスクトップPCが欲しいが10万円も出せない場合は、いったん諦めてNovelAIで画像生成を始めたほうがいいと思います。NovelAIにはドル建てで10ドル、15ドル、25ドルの3プランがあり、主にそれぞれもらえる通貨「Anlas」の数が異なりますが、払うなら無限生成ができる25ドルの「Opus」プランがおすすめ。現在グラボなしのPCを使っている場合は、とりあえずそれでSDに挑戦してみてもよいし、4万円でRTX3060単品を買って搭載してみるのが良いはず。ちゃんとPC内にささるかどうか事前に確認を。

WebUI、結局どれがいい?
StableDiffusionを触るにあたって、どのWebUIでSD何系のモデルを使ったらよいかは「プレステ5とSwitchどちらを買うべきか」と同じような問いです。つまり人によるわけですが、最初はA1111を選んでおけばたいていの解説記事が助けてくれるのでおすすめです。A1111で画像生成に慣れれば、ほぼ完全に同じ見た目の「Forge」を使うことも楽にできるはずです。
インストール・アップデート方法はいろいろな方法があるのですが、StabilityMatrixというアプリケーションを使うと、A1111、Forge、ComfyUIなどの主要UIを一括でインストールでき、使用するモデルも共有できて便利です。
「いきなりForge」も全然OK
最初からA1111ではなくForgeを入れてしまうのも有力な選択肢です。基本的に使い方は同じですし、何より生成速度が早い。VRAM12GBのグラボでもSDXLに挑戦できますので、AnimagineXL3を触ってみたい方は「いきなりForge」でも全く構いません。
新しい機能もA1111より先にForgeが対応するというケースも出てきています。マイナスポイントとしては、一部の拡張機能が対応していない可能性があること、A1111向けの解説記事に書いてあることと操作系が違っていて戸惑う可能性があることくらいでしょうか。インストールも簡単なので、一度は自分の環境でどれくらい速度が変わるか見ておくとよいでしょう。
画像生成の基礎知識
さて、PC環境が整い、無事SDWebUIをインストールできたら、さっそく画像を生成していくことになります。こちらがSDWebUIの操作画面です。(A1111版ですが、forgeもほぼ同じ見た目です)

日本語化した上、拡張機能も多数導入していますので、インストールしたての画面とは異なることをご了承ください。ちなみに、画面のテーマカラーは「設定▶ユーザーインターフェース▶Gradio theme」で変更できます。
初めてだと何がなんだかわからないと思いますので、こちらに画像の説明文を作りました。拡大してご覧ください。画像内の大きな数字①~⑥は、下記の項目ごとの数字に対応しています。
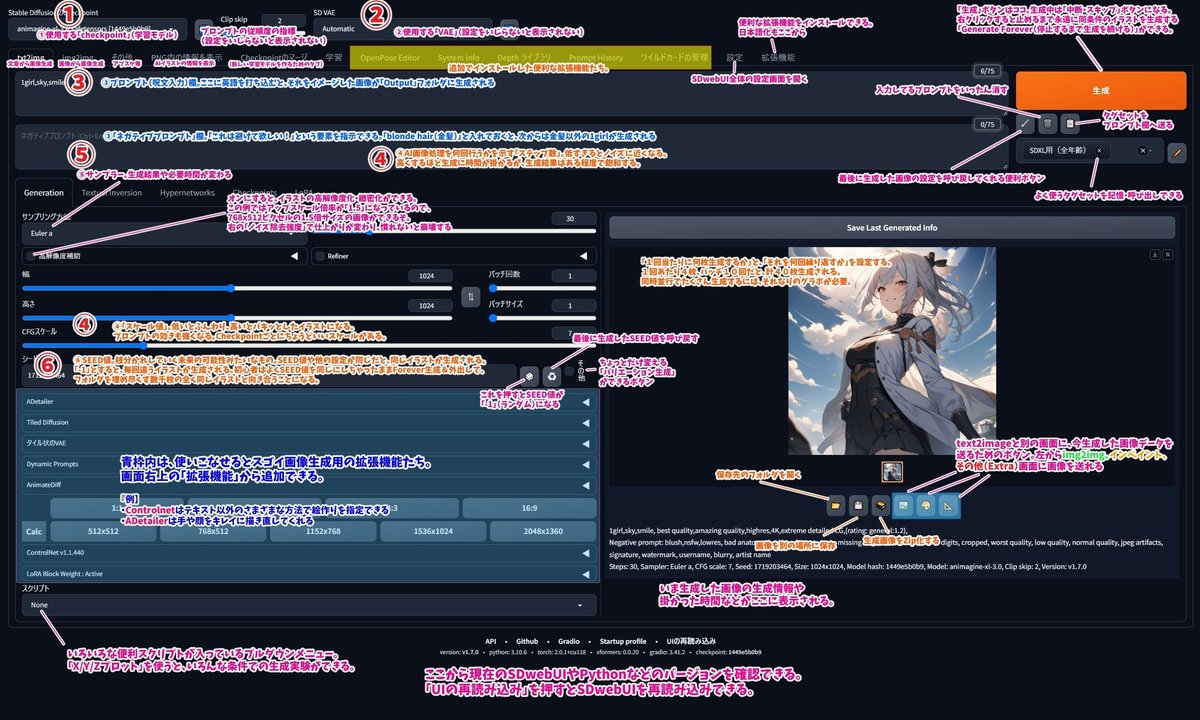
①学習モデル(Checkpoint)
SDwebUIはAIではなくただのインターフェース(ゲーム機本体のようなもの)ですので、それ単体では画像生成を行うことができません。大量の画像とテキストのペアから学習した「学習済みモデル」(通称Checkpoint)を読み込ませる必要があります。それがゲームソフトに当たるStableDiffusionなわけですが、実は多くのユーザーはStableDiffusionモデルそのものは使っておらず、そこから派生したさまざまな特徴を持つモデルを使って生成しています。

こちらは自作したモデルを共有できるプラットフォーム「Civitai」のスクリーンショットです。実写のようなフォトリアルな画像に特化したものや、アニメ調のイラストが得意なモデル、緻密で美しい風景の再現が得意なモデルなど、主に学習させた教師データによりさまざまな特徴・種類があることがサムネイルから分かると思います。同じプロンプト指示でも、どんなモデル(Checkpoint)を使うかによって、生成されるイラストは大きく変わるわけですね。
学習モデルは既存のモデル同士を好きな配合で融合させて好みのものを作り出すことができるため(マージと言います)、日々無数のモデルがCivitaiなどに無償で投稿され、共有されています。学習モデルによってライセンス表記があり、「生成画像の商用利用禁止」などのルールが定められているので、必ずチェックした上で使用する癖をつけましょう。
ちなみに、基盤モデルであるStableDiffusionそのものにもさまざまなバリエーションがあり、最も広く流通しているのが初期型の「SD1.5系」。後継として「2.1系」、最新の「SDXL系」があるのですが、要求されるグラボ性能が高まったことから、なかなかSD1.5系からの「移住」は進んでいません。

後述するLoRAやControlnetなどの拡張機能は、基盤モデルの壁を越えて利用できない(SD1.5系用のものをSDXLモデルに使い回せない)ことも、移住がなかなか進まない原因です。ただ、SDXL系の雄「AnimagineXL3.0」の登場で、思い切ってSDXLに移行したというユーザーも増えつつあります。
②VAE
「Variational Autoencoder」の略。何をしているかを説明するにはまず、拡散モデルの画像生成AIには「テキストエンコーダ」「U-NET」「VAE」の三つのモジュールがあり、潜在空間上でノイズ除去が・・・などなどというややこしい説明が必要なのですが、ここでは割愛します。
「人間がプロンプトを指示」▶「テキストエンコーダが翻訳」▶「U-NETが不思議空間でAIにしか見えないお絵描きをする」▶「VAEが人間にも分かる『絵』に翻訳してくれる」という画像生成プロセスのうち、最後の翻訳部分を担当する役割だと理解すれば十分です。
VAEによって何が変わるかというと、学習モデルが生成した画像の「見栄え」や「色合い」が変化します。こちらの画像は、全く同じ生成設定でVAEだけを変更したもの。右は色合いがビビッドになっていることがわかります。

学習モデルやLoRAなどに比べるとあまりたくさんのVAEが流通しているわけではありませんので、「なぜか色が褪せて見えるな?」と思ったら別のVAEを使ってみる、程度の認識でOKです。学習モデルごとに対応するVAEが配布されていることもありますが、賢木はずっと同じSD1.5系のVAE「kl-f8-anime2.ckpt」を使っています。保存先は「models\VAE」です。
SDXL系ではSDXL専用のVAEを使う必要がありますが、モデルに「同梱」されている場合も多いです。VAEの設定を「Automatic」や「none」にしても普通に生成できれば、モデルにVAEが同梱されています。人気モデルのAnimagineXL3はVAE「none」で生成できますし、間違ってSD1.5系の「kl-f8-anime2」を使うと崩壊してしまいます。

③プロンプトとネガティブプロンプト
プロンプトとネガティブプロンプトは、Text2image(文章から画像生成)における最も重要な要素。AIはプロンプト欄に書かれた呪文を基に画像を生成します。「1girl,smile,sky,school uniform,peace sign,looking at viewer」などと、基本的にはカンマ「,」で区切って、盛り込みたい要素を箇条書きで並べていくだけでOKです。「被写体は何人でどんな構図か、どんな見た目の誰がどこで何をしているか、どんな画風か」を指定するのがコツ。正しい「呪文」でないと認識しないわけではなく、DeepL翻訳でざっくり英文化して放り込んでもけっこう理解してくれます。
スペルを間違えても理解してくれることがありますが、「white hair ribbon」と指示したらキャラの髪が白くなってしまった("white hair"+ribbonと誤解された)、ということもたまにあるので、上手な意思疎通をするにはコツが要ります。分脈より、あくまで書いた単語に反応しがちな傾向があります。
「何を生成するか」を指示するプロンプトに対し、「何を生成しないか」を入力する欄であるネガティブプロンプトも同じくらい重要です。「金髪はだめ」「男は描くな」と指示するだけでなく、「低品質な画像はダメ」と指示すると高品質になるので、この2つがうまく釣り合うことで素敵なイラストが生成できるようになります。
詳しいプロンプトの書き方については、こちらの記事にまとめてあります。「超入門」の次にこちらを読むと、画像生成がスムーズにできるようになっていくと思います。
ローカル生成におけるプロンプト・ネガティブプロンプトについては日本最大級の「プロンプト超辞典」に詳しくまとめていますので、慣れてきたらこちらをご参照ください。また、chichipuiなどのAIイラスト投稿サイトでは、プロンプトがイラストと一緒に公開されていますので、大変参考になります。
現在はモデルや生成環境の多様化が進み、Controlnetを始めとしたさまざまな手法も登場したため、プロンプトは以前ほど大きな存在ではなくなってきています。それでも、やはりどんなイラストが生成されるかはプロンプトが大きく左右するもの。まずはいろんなプロンプトを試して、text2imageに習熟するのが上達への道です。
ちなみに、AIを使う人が「AI術師」と呼ばれることがあるのは、呪文のようなプロンプトを駆使して画像生成するから。「AI絵師」と呼ぶ人もいますが、この表現は努力して手描きイラストのスキルを積んできたクリエイターの気分を害することがあり、「AIイラストを自分で手描きしたとうそをつく人」の意味に使われることもあるため、自称する人はまれです。スタジオ真榊では単に「画像生成AIユーザー」を使うことが多いです。
④ステップとスケール
ステップ(サンプリングステップ数)は AI がノイズを取り除く作業の反復回数のこと。「青空と少女」のイラストで実験したとおり、ステップ1だと、まだ意味のないノイズからさほど離れることができず、ぼんやりした概念のようなものが生成されます。ステップ数が多いほど絵のクオリティが上がる反面、生成に時間がかかります。適正なステップ数は使用する学習モデルにもよりますが、「テスト生成は12以上、本番生成なら20以上推奨」が目安。私は30前後にすることが多いです。
スケール(CFGスケール)は直感的にわかりにくいですが、「プロンプトの再現度」に近い概念です。低スケールだと柔らかい絵画風になり、高スケールにするほどディティールが細かく描写され、AIがより厳密にプロンプト(ユーザーの指示)を再現しようとします。学習モデルごとにおすすめのスケール値が案内されていることが多いので、それを参考にして好みに調整してみましょう。
こちらは同じ設定のイラストで、スケールだけを1~28まで変化させたもの。モデルによってスケール値による影響はさまざまですが、低すぎても高すぎてもおかしくなる感じが伝わると思います。



ちなみに、こういう比較実験画像は「X/Y/Zプロット」というスクリプト機能で簡単に作ることができます。初めてのモデルで生成するとき、最適な設定を探るのに非常に役立ちますので、早めに習得しておきましょう。
⑤サンプリングアルゴリズム
AIがノイズ処理する際のアルゴリズムのことを「サンプラー(サンプリングアルゴリズム)」と言います。Euler a, Euler, LMS, Heun, DPM2, DPM2…とさまざまな種類があり、同じ学習モデル・SEEDでもサンプラーを変えると雰囲気がだいぶ変わります。人気なのは軽さとクォリティが両立した「DPM++ 2M Karras」と、少し重めですがクォリティに定評のある「DPM++ SDE Karras」。これも、学習モデル配布時におすすめのサンプラーが案内されていることが多く、AnimagineXL3.0では「Euler a」を使うと良い結果になるようです。
こちらはAnimagineXL3.0でサンプラーの比較実験を行ったときの画像。

同じプロンプト・設定でも、サンプラーによって全然違う画作りになることが分かると思います。右上のように崩壊してしまうサンプラーもありますが、それはそのサンプラーの性能が悪いわけではなく、モデルと相性が悪かったり、適切な設定値ではなかったりしたことが原因と思われます。
⑥SEED値
乱数を作成するときの最初の設定値のことをシード(種)値と言います。画像生成AIにおいては、生成画像ごとに割り当てられている「固有の背番号」のようなものと考えてみてください。全く同じプロンプト指示をしても、このSEED値が異なると違うイラストが生成されますし、同じSEED値を指示すると、プロンプトが多少変わっても似たイラストになります。以前生成したイラストと同じものを生成したいときは、プロンプトだけでなくこのSEED値を保存しておくことが必要になります。
生成するたびに同じイラストが作られてしまうと困るので、普通はseed値を固定したくありませんよね。seed値を毎回ランダムにするためには「-1」と入力するか、欄の横のサイコロボタンを押せばOKです。おおむね好みのイラストができたけれども、ちょっと変えたいとか、クォリティをアップしたいときに、このseed値が役に立つことになります。ちなみに、生成画像にはSTEP、スケール、seed値などの情報が保存されているので、画像そのものを取っておけばメモする必要はありません。

慣れてくると数百枚出力する設定で生成ボタンを押して外出することも増えてきますが、Seed値の設定を「-1」にするのを忘れていて、帰宅したとき全く同じ数百枚の画像と対面するはめに…というのがAIイラストあるあるです。(Seed値事故)
WebUIのインストール後にやるべきこと
恐らくこの記事を読んでいる方の多くはSDwebUI(かForge)を使っていると思います。日本語化や拡張機能の導入など、インストール前後にやっておくべきことは基本的にこちらの記事に書いてありますので、まずはこちらを参考にしてください。(Forgeも操作方法や画面の見た目はほとんど同じです)
UIの日本語化が済み、テスト生成が無事できるようになったら、「設定」タブから以下のように設定を変更することをおすすめします。
・「保存するパス」
画像の保存先を決める。デフォルトは「Output」フォルダだが、ストレージに余裕がなければSDwebUIと別のドライブに変えてもよい。そのままだと、text2imageやimage2imageなど、生成手法によって保存先が異なる設定になっている。
・「ディレクトリへの保存」
保存先に、さらにサブフォルダを作るか決める。「サブディレクトリに保存する」を選ぶと生成日ごとにフォルダ分けできる。
このほか、インストール時にやっておくと便利な設定やおすすめ拡張機能、大量に生成される画像とプロンプトの管理などについてはこちらの記事にまとめてあります。
学習モデルはどこで入手する?
さて、ここまでがStableDiffusionで画像生成するための基礎知識です。インストールがうまくいき、プロンプトやスケール値がどんなものか理解できれば、少なくとも「1girl,smile,sky」というプロンプトでイラスト生成することまではできるようになっているはずです。では、イラスト生成のクォリティに直結するモデル(checkpoint)やVAEなどをみなさんどこで入手しているのかというと、「HuggingFace」や「Civitai」といった海外プラットフォームが主な流通場所となっています。
「HuggingFace」は学習済みの機械学習モデルやデータセットなどを公開している米国発のプラットフォーム。下記のCIVITAIに比べてより技術者寄りで、アップデートや技術討論などが盛んに行われています。WebUI用の拡張機能などはこちらで配布されることが多いです。
「CIVITAI」はStable Diffusionのモデルをアップロードできる海外プラットフォーム。

こちらはHuggingFaceに比べてより一般ユーザー寄りで、多くのユーザーが学習モデルのほか、「LoRA」や「Textual Invarsion」と呼ばれる追加学習のファイルなどを公開しています。無修正の18禁画像などもバンバン出てきますので、表示設定や各モデルのライセンスをよく確認して、自己責任でご利用ください。
Civitaiのサインアップ方法や基本的な使い方は「LoRAでキャラ再現!15分でできる追加学習入門」で解説しています。

【注意すべきこと】NovelAIリーク問題
ここで一つ、画像生成ユーザーとして経緯を把握しておくべき事件があります。2022年10月、公開されたばかりの「NovelAI」のv1モデルが何者かにハッキングされ、ウェブ上に流出する事件がありました。(詳しい経緯はジャーナリスト・新清士さんの「画像生成AIの激変は序の口に過ぎない」および「AIの著作権問題が複雑化」参照)。
NovelAIの知的財産(営業上の機密)であり、本来はお金を払わないと使えないはずだったモデルがローカルで使えてしまうわけです。流出したCheckpointそのもの(以下リークモデル)を勝手に配布や販売したり、それを使ったサービスを提供したりすることは、NovelAI運営側に対する不正競争防止法違反や権利侵害となるリスクがあります。たまに勘違いされますが、NAIリーク問題はクリエイターへの著作権侵害の問題ではなく、モデルを開発した運営企業に対する権利侵害の問題ということです。
NovelAIコミュニティの皆さま
— NovelAI (@novelaiofficial) October 8, 2022
いつもNovelAIをご利用いただき誠にありがとうございます。
ご迷惑をおかけし申し訳ごぜいません。
2022年10月6日に弊社のGitHubとセカンダリリポジトリに権限のない第三者による不正なアクセスを許してしまいました。 https://t.co/FuIzzZSUQh
問題はここからで、学習モデルは別のものとマージ(融合)することができるため、その後リークモデルをマージしたとされる「Anything v3.0」を始め、無数の派生モデル(以下リークマージモデル)がウェブ上で公開されてきました。流出したのはSD1.5をベースにしたモデルですので、SD2.1系やSDXL系のモデルにはリークモデル混入の心配はありませんが、SD1.5系を利用する場合は注意する必要があります。
リークマージモデルかどうかは、配布者が「配合レシピ」を公開していて分かる場合もあれば、分からない場合もあります(例えばAbyssOrangeMixシリーズの一部にはリークモデルがマージされていることが明かされています)。リークモデルの二次派生モデルを、そうと知らずに別の人物がマージした三次モデルが配布されているケースもあるかもしれません。リークモデルにライセンスやパーミッションなどあるはずがないので、その派生モデルの法的な扱いは非常に不安定です。特にこうした学習モデルの商業利用を考える場合、権利関係が複雑化しており、自己責任が強く問われる現状になっています。
これまで最もポピュラーだったモデルはStable Diffusion1.5系であり、流通しているCheckpointや拡張機能も1.5をベースにしたものが多く、その中にリークマージモデルも多数混入している恐れがあるということです。学習モデル配布者の示しているライセンスやパーミッションを遵守するのは当然として、モデルの出自によっては自分で使用用途を判断し、リスクを勘案して自己防衛するしかないことを書き留めておきます。
◆後発モデルへの移行で終息へ
NAIv1モデルの流出から一年半が経過し、基盤モデルとなるStableDiffusionも様々な新モデルがリリースされてきました。2023年7月26日にリリースされたStable Diffusion XL(SDXL)は、これまでよりも多くのVRAMを要求する代わりにより高精細な生成が可能で、NovelAIも現在の「V3」はSDXLをベースにしたモデルです。
当初は移行がなかなか進みませんでしたが、「AnimagineXL3」「pony diffusionXL」などのSDXL系人気モデルが登場し、「Forge」によってVRAMが少なめのグラボでも快速生成が可能になったことで、SD1.5系からSDXL系への移行が進みつつあります。後発モデルには、1.5系モデルであるリークNAIをマージすることができません。流通しているモデル全体のレベルが上がることで、流出した古いNAIv1をいまさら悪用するメリットはなくなりますし、そもそも営業機密の漏えいや不正使用といった罪はいずれ時効を迎えますので、NAIリーク問題はこのまま終息していくとみられています。
実際にイラストを生成してみよう
さて、ここまでの基礎知識を覚えたら、あとは実行するだけ。一緒にCivitaiからCheckpointを入手して、テスト生成をやってみましょう。このテストでは、AIクリエイターの852話(hakoniwa)さんが配布されているSD1.5系のアニメ調モデル「SDHK v4.0」を使用します。

SDHKは、Nijijourney(v5)で生成されたAIイラストを使ってSD1.5をファインチューニングしたモデルで、リークNAIの混入の恐れがありません。
ファインチューニング 公開されている学習済モデル(この場合はSD1.5)に、独自に用意したデータを追加学習させて、より良いモデルにチューニング(調整)する手法のこと
【重要】ライセンスとパーミッションを確認しよう
「SDHK」をダウンロードする前に、Civitai上でライセンス欄を見てみましょう。

「CreativeML Open RAIL-M」とあります。これはStable Diffusionが採用しているのと同じライセンスですので、マイナーチェンジ版の「CreativeML Open RAIL++-M」と一緒に名前を覚えておきましょう。商用利用が可能かやクレジットの記載義務の有無など、やってよいこと、やってはいけないことが書かれていますので、こちらの邦訳サイトを参考にしながら、必ず内容を理解した上で利用するようにしてください。
ちなみに、こちらは「AnimagineXL3」のライセンス欄。「CreativeML Open RAIL-M」に加えて、右側にショッピングカートのようなマークがあり、クリックすると「やってよいこと、だめなこと」(利用許可=パーミッション)が表示されます。これはCivitai独自のもので、投稿者がライセンスに加えて利用制限をすることができる仕組みです。(※違う条件が加わったら、それって最早CreativeML Open RAIL-Mライセンスではないのでは?法的効果はあるのか?という指摘もなされています。ごもっともなのですが、トラブルの元ですので、Civitaiでダウンロードする以上はきちんと確認しておきましょう)

AnimagineXL3.0のパーミッションを見ると、「作成者のクレジットを表示せずにモデルを使用する」「このモデルを使ったマージモデルを使う」「有償の画像生成サービスを提供する」などが可能な一方、AnimagineXL3とそのマージモデルを勝手に販売したり、マージモデルにこれと異なるパーミッションを与えたりすることが禁じられていることが分かります。
さっそく生成してみよう
ライセンスとパーミッションを確認したら、さっそく画像生成してみましょう。リンク先からダウンロードしてきたsdhk_v40.safetensors(1.99GB)を使用しているwebUIの「models\Stable-diffusion」フォルダに放りこめば、左上のプルダウンメニューに表示されます(表示されない場合は横の青い更新ボタンを押しましょう)。VAEはさきほど紹介した「kl-f8-anime2」を使います。

※VAEのファイル名はデフォルトから短くしてあります
プロンプト欄には「1girl,upper body,smile,sitting,chair,sky,classroom,black hair,sailor uniform,masterpiece,extremely detailed CG,official art,high resolusion」、ネガティブプロンプト欄には「nsfw, extra fingers, deformed hands, worst quality, low quality, poor quality, bad quality」と入力します。キャンバスサイズは基本の512×512px、サンプラーは軽くて良質な効果が期待できる「DPM++ 2M Karras」、ステップは25、スケールは7。Seed値は「12345」、CLIP SKIPは「2」とします。
準備ができたら、右上の「生成」ボタンをクリック。
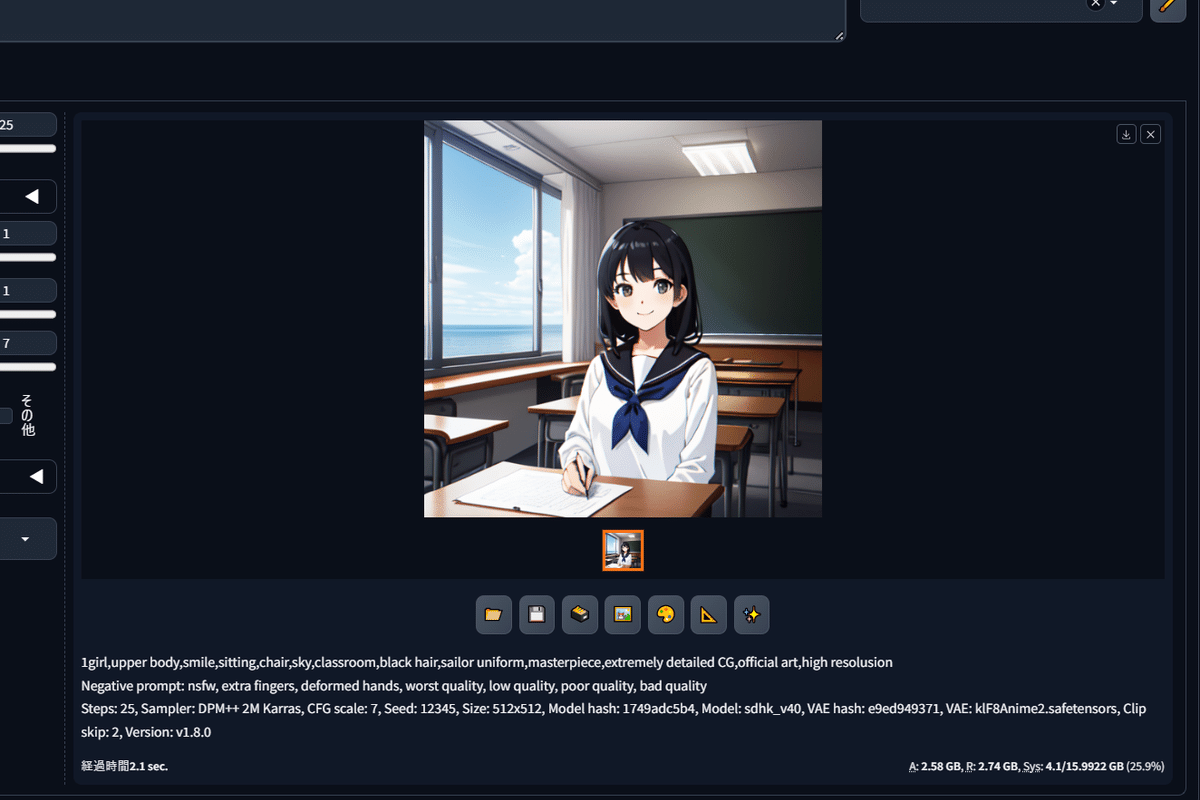
このような画像が表示されました。「セーラー服を着た黒髪の女の子が1人、笑顔で教室の椅子に座っており、空が映り込んでいる良質で高画質なCG」というプロンプト通りのものが描かれていますね。VAEやステップ、Seed値などの設定値が全て同じなら、皆様の生成環境でもほぼ同じものが生成されたはずです。(※使用するwebUIなどによっても微細な異同はあります)
より高精細にするには
さて、SDHKのCivitaiページをよく見ると、「Hires.fix」を使うことと、「NGH」というNegative Embeddingsを使うことがオススメされています。それぞれ、今後よく使うことになる機能なので覚えておきましょう。
「高解像度補助(Hires.fix)」 生成された画像を縮小してスケールアップ、縮小してスケールアップを繰り返すことで、より緻密にクォリティアップしてくれる機能。「Latent」系や「R-ESRGAN 4x+Anime6b」などさまざまな「アップスケーラ―」があり、それぞれ生成結果が変わる。
「NegativeEmbeddings」 Textual Inversionという技術で学習させたファイル(Embeddings)のうち、ネガティブプロンプトの用途として使用するもの。ネガティブプロンプトで「bad,ugly,…」などと指定するのと同様に、低劣な画像で学んだ追加学習ファイルを逆方向に作用させることで、生成結果を高品質にする。Embeddingsが全てこうしたネガティブプロンプト用というわけではなく、キャラ再現やポーズ再現用のEmbeddingsなどもある。
1.高解像度補助
Generation画面にある「高解像度補助」のタブを「◀」ボタンで開くと、このような画面が出ます。
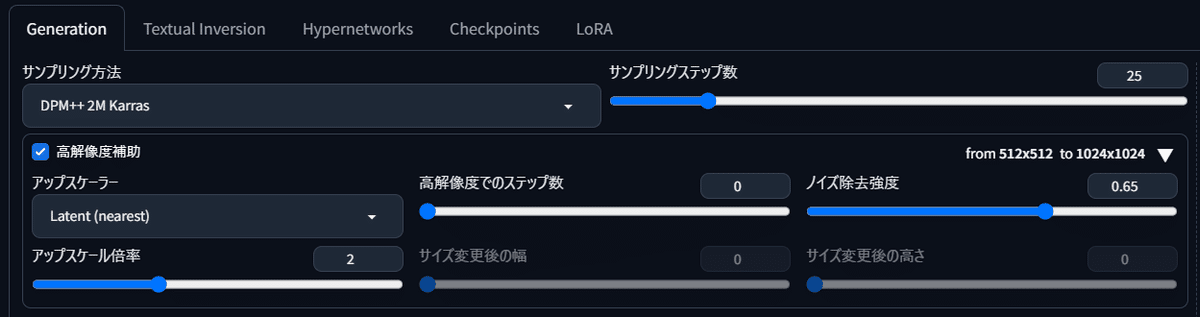
「アップスケーラー」タブをクリックするとさまざまな種類が表示されますが、ここでは「Latent(nearest)」を選択。ノイズ除去強度を0.65、アップスケール倍率を「2倍」にしましょう。こうすることで、「Latent(nearest)というアップスケール手法で生成画像を2倍の大きさに高解像度化する」ことができます。

さきほどの教室の女の子と同じ画像にしたいので、右下のリサイクルボタン「♻」を押して直前に生成した「シード値」(12345)を呼び出しました。これで生成したのが右の画像です。

全体の印象はおおむねそのままに、より高解像度化されたのが分かるでしょうか。そのかわり、本来意図していない位置に机やライトといったオブジェクトが生じており、必ずしも良い結果ばかりになるとは限りません。こうしたランダム要素を排除するため、黎明期では確率に任せて「ガチャ」をする(大量生成した中からよさそうなものをピックアップする)ことが一般的でしたが、その後Controlnetなどの登場やベースモデルの改善により、現在は必ずしも偶然に頼らなくても意図通りの表現ができるようになってきています。
2.NegativeEmbeddings
次に、「NegativeEmbeddings」を適用してみましょう。「NGH」は、852話さんが配布されているネガティブプロンプト用のNegativeEmbeddingsで、上記のリンクからダウンロードできます。webUIのインストールフォルダにある「embeddings」フォルダに入れ、同じファイル名をネガティブプロンプトに入力すれば動作します(ngh.safetensorsなら「NGH」と入れるだけ)。有名なものでは、他に「EasyNegative」「bad_prompt」などのtextual inversionがありますので、Civitaiで検索してみましょう。
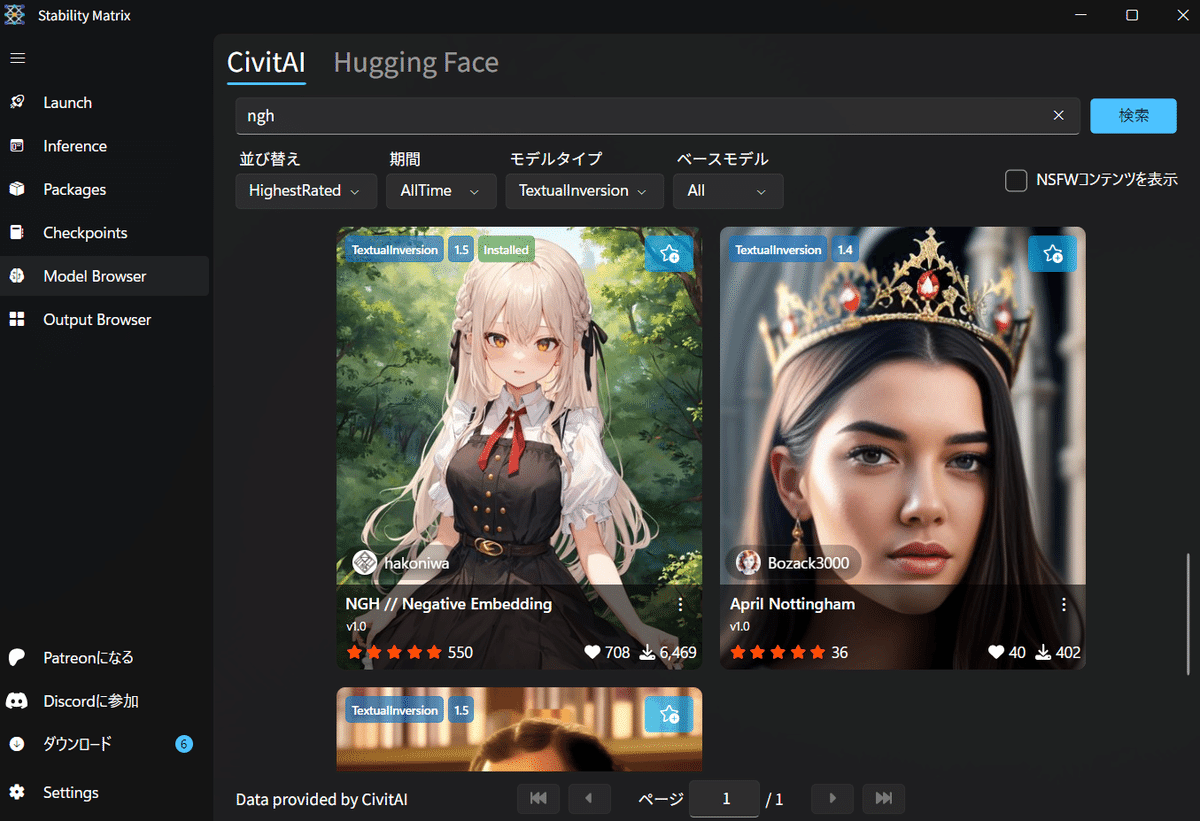
ファイルをembeddingsフォルダに入れたら、プロンプト欄のすぐ下にある「Textual Inversion」をクリックします。保存されているはずのNGHが出てこず、こうなってしまった場合は…

生成ボタンの右下にある更新ボタン(回転する矢印マーク)を押しましょう。
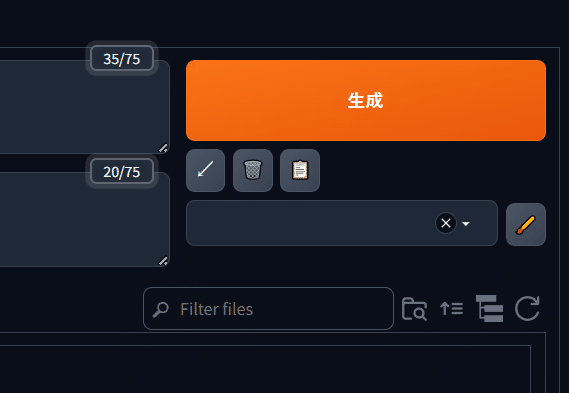
出てきたサムネイルをクリックすると、ネガティブプロンプトの右端に「NGH」が追加されました。この状態で生成してみましょう。
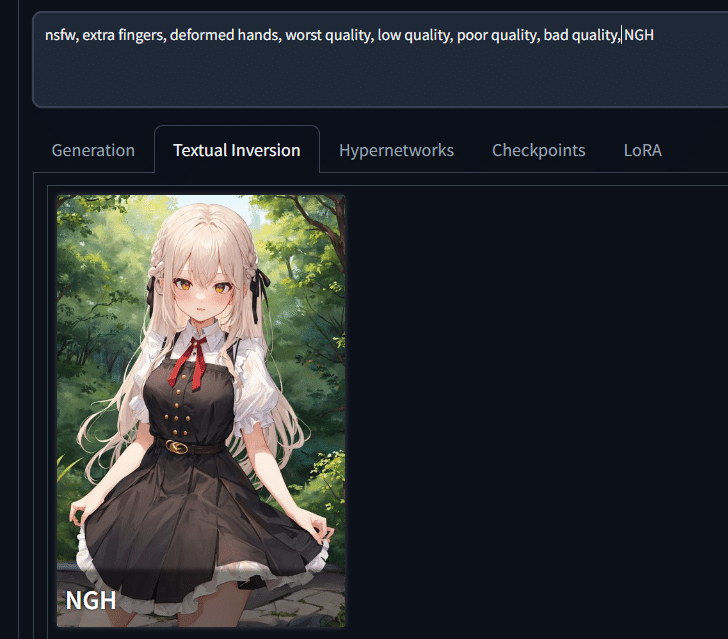
まず、高解像度補助はOFFでNGHを適用すると、次のような変化が。

高解像度補助とNGHを両方掛けると、このようになりました。

2枚をGIF画像で比較してみましょう。

こう見ると、確かに高解像度化はしているのですが、よく見ると背景の机は位置や形状がおかしいですし、教室の背後に黒板があるのもやや不自然です。これがAIイラストの弱点である「意図しないオブジェクトの生成」と「文脈の欠如」です。テキストベースの連想によって画像が作られるがために、「一見ちゃんとしているけどよく考えるとおかしいもの」が普通に出てしまうんですね。
たとえばこちらの画像は、一瞬美麗ですが、たくさんのミスがあります。すぐあとで解説するのですが、いくつ見つけられるでしょうか?

シンキングタイム!

はい、時間切れです。
こちらの画像をご覧ください。パッと見て分かるレベルでもこれだけありますし、もっと細かく見ていくとさらにたくさんの「おかしさ」が見えてきます。

破綻ではありませんが、「文脈上」おかしいこともあります。例えば、左右の腕に巻いているフリルが何なのかよくわかりませんし、左右でデザインが違っています。瞳の塗り方もアップでみると瞳孔が溶けていて少し不気味。海でこんな格好をしているのもよく考えるとおかしいですし、水平線もよく見ると、なんだか一直線でない気もします。
髪になぜ花?髪飾り?をつけているのでしょう。そのポーズの意味は?カメラ側には誰がいて、どんな状況なのでしょう?
ChatGPTは「それらしい嘘をもっともらしく並べるAI」と言われることがありますが、それなら画像生成AIも「それらしい嘘イラストをもっともらしく作ってくれるAI」です。どちらも生成物は一見して人間が作り出したものに酷似しているのですが、意味や意図のあるイラストに見せるには、人間の手助けが必要です。
AIイラストに見慣れるとこうした破綻に気づきにくくなってしまうのですが、ポン出し(適当なプロンプトでササっと生成しただけのAIイラスト)ならともかく、出来にこだわりたい場合はここから時間を掛けて微修正を繰り返すことになります。
こうした「意図しないオブジェクト」をAIで修正することもできます。例えば「LamaCleaner」は、キャンバス内の余計なものを簡単かつ自然に消すことができる機能です。
Adobe税を払っている方は、Photoshopの「生成塗りつぶし」を使うのもオススメです。
しかし、もっとも手っ取り早いのはやはり、画像編集ソフトで直接直してしまうことです。さきほどのような半分リアルタッチの画像は直しにくいですが、アニメ調になるほど加筆は容易になります。思い切ってペンタブとクリスタを買うと本当にAIイラストは面白くなるので、「自分は絵が描けないから…」と思っている人もぜひトライしてみてください。目にちょっと白いハイライトを入れたり、文字を入れたりするだけでも面白いですよ。
【コラム】画像サイズはとても重要
さきほどはさらっと「512×512pxで生成しましょう」と説明しましたが、この画像サイズをどうするかも絵作りと画質に大きく関わってきます。一般に、縦長のイラストには人物の全身像が描かれることが多く、横長のイラストには複数人数のバストアップが描かれることが多いのは想像できると思いますが、そうしたイラストで学習している学習済みモデルも、自然とキャンバスサイズによって描く構図が変わってくるのです。
キャラクターの全身図を描きたいなら「full body」などのタグを使いますが、縦長のキャンバスにしないと体の一部が見切れたり、不自然にかがんだポーズのイラストが出やすいことになります。こちらのイラストはすべて同じ設定でキャンバスサイズだけ変更したものですが、「靴まで収めた全身図を描いて」と指示したため、縦長のキャンバス以外は不自然なポーズでむりやり収めている感じが分かります。

キャンバスサイズは画質にも影響します。SD1.5系は512×512px、SDXL系は1024×1024pxの画像で学習しているため、これより大きくなりすぎても小さくなりすぎても上手に生成できず、画質が下がってしまいます。だいたい縦横のアスペクト比は4:3か16:9、大きくても3:2くらいにおさめておくと良いでしょう。(SD1.5系なら768x512くらい)
生成した画像は必ず取っておこう
さて、ここまでで少なくとも「好きなモデルをダウンロードして」「設定やプロンプトを考えて」「高解像度補助を掛けて画像生成する」という画像生成の基本まではたどり着きました。
ちなみに、StableDiffusionで生成された画像ファイルには、あなたが生成時に設定したSeed値やプロンプト、生成サイズといったあらゆる情報がちゃんと保存されています。
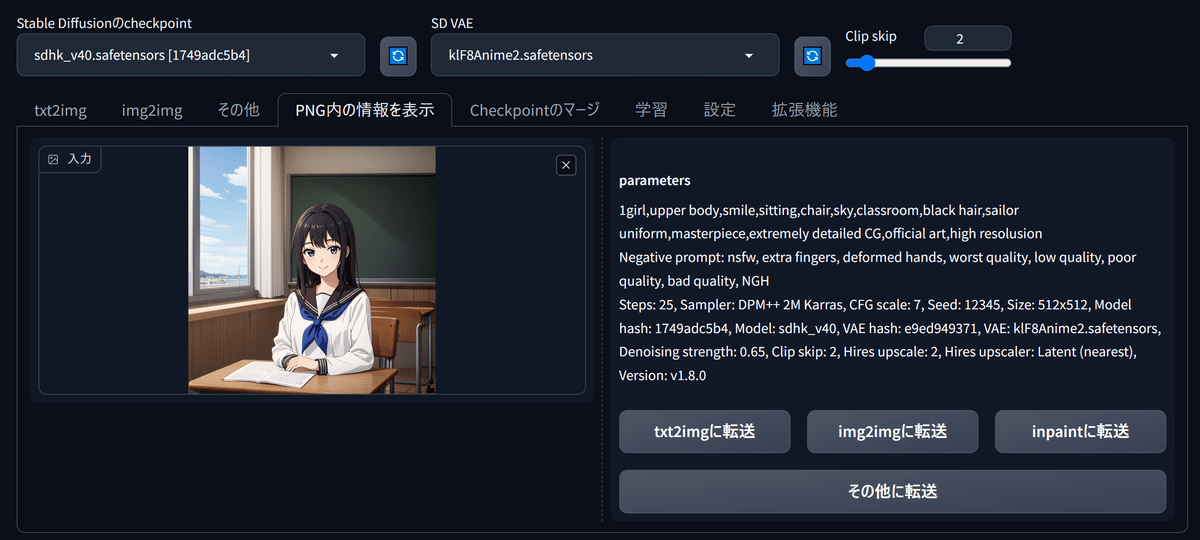
text2imageのタブの2つとなりにある「PNG内の情報を表示」タブで画像を読み込ませると、このように生成時の情報をいつでも呼び戻すことができ、ボタンひとつでtext2imageのページにすべての情報を飛ばすこともできます。こうすることで、好みの画像をちょっとだけ設定変更して、より意図通りにする…といったこともできるようになります。不要になったイラストも、あとでどんな役に立つかわからないので、削除せず大事にとっておきましょう。
pngを大事に取っておくべき理由はもう一つあります。AIイラストやそのユーザーに向けられている目は依然として厳しく、SNSなどに投稿していたら、「既存のイラストのパクリではないか」と突然疑われてしまうことがあるかもしれません。そういったときも、そのイラストのpngに内包されているプロンプトやseed値といった情報や、前後に生成したイラスト群がきちんと残っていれば、自分がそのイラストを試行錯誤しながら生成したことを示す証拠になります。

逆に、無断転載した人物に「自分こそが本来の生成者だ」と自称されたときも、投稿画像にExif画像が残っていなければ相手は同じ画像を二度と生成できないはずなので、自分が本来の生成者だと証明することができます。
image2imageしてみよう
さて、ここまで説明してきたのは、完全なノイズ画像からプロンプトを頼りにイラストを作る「text2image」のやり方でした。画像生成AIを使ったもう一つの生成法が「image2image」、つまりノイズ画像からではなく、参考となる画像をもとにイラストを作る方法です。細部の書き込みを増やすクォリティーアップに使えるだけでなく、構図を維持しながら別のイラストに変えることもできますし、自分の手描きイラストをAIに「清書」してもらうこともできます。
←手描き / AIに直してもらったもの→
— 賢木イオ🍀AIイラスト (@studiomasakaki) March 2, 2024
自分の何がズレてるのか、次からどうしたらいいのか、得られるものが多すぎるのよ pic.twitter.com/6GSggVrRui
実際にimage2imageをやってみましょう。まず、さきほどテスト生成した画像を、「PNG内の情報を表示」タブで読み込ませます。
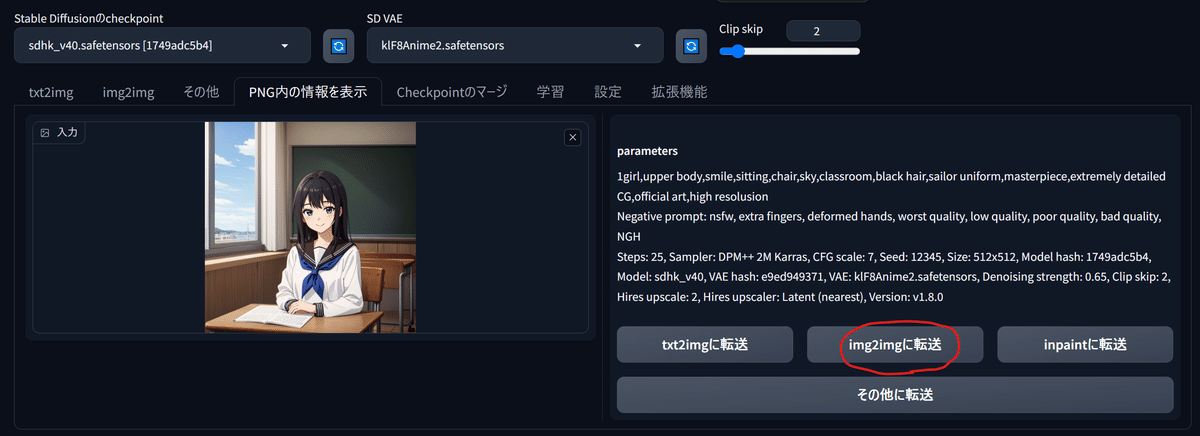
赤い丸をした「img2imgに転送」ボタンを押すと、この画像と生成情報がすべてimg2imgのタブに転送されます。

さきほどの画像は512x512pxを高解像度補助を掛けて2倍にしたので、そのサイズがデフォルト値として読み込まれています。画像サイズの設定は「Resize to」で縦横を数字で指定し直すこともできますし、「Resize by」で元画像の何倍、と指定することもできます。

ステップとスケールはText2imgと同じ意味。ノイズ除去強度は「どれくらいこの元画像を参照するか」を意味しています。「0.5」までならプロンプトをもとにちょうどよく仕上げてくれ、「1」だと全く違う画像に、「0」だと全く同じ画像になります。
image2imageアップスケール
まずは、さきほどの画像を「2倍」に拡大してみます。ただし、使うモデルは「SDHK」ではなくSDXL系の「AnimagineXL3」です。ノイズ除去強度は0.5(50%)なので、SDHKとAnimagineXL3のハーフ&ハーフのような感じで、しかも2倍サイズに高解像度化してもらえるはずです。

こちらが生成されたもの。元画像の間違いは完全に解消していませんが、SDXLベースの高精細さがしっかり生かされていることが感じられます。

さっきのはノイズ除去強度0.5でしたのでハーフ&ハーフな結果でしたが、ノイズ除去強度を変えると、混ぜ具合を変化させられます。


「1.0」はほぼ、始めからanimagineXLで生成したのと同じような結果になります。初めから2048x2048pxで生成すると崩壊してしまいますが、image2imageを使うとこのように崩壊を防ぎながらアップスケールをすることができるわけです。
プロンプトの一部変更
今度は、プロンプトの「smile」を「angry」に変えてみます。

元画像をプロンプトにしたがって「描き直す」わけですが、大きく構図を変化させない内容なら…

ほぼ同じイラストで、表情だけを変更することができました。
ただ、これを「ニヤっとわらっているTシャツ姿の男の子」に変えようとするとどうでしょうか。ノイズ除去を相当強めにしないと広範囲の描き直しはできないので、「0.8」でやってみると…

masterpiece,extremely detailed CG,official art,high resolusion」
このように、なんとか男の子に変えることはできました。ただ、やはりいろいろと不自然な部分はでてきてしまいますし、髪型なども元画像に引っ張られてしまうので、大幅な描き直しをするなら最初からやり直した方がよいでしょう。
アップスケールにはこのように、「img2imgを使う」「高解像度補助を使う」といった方法があり、ほかにもControlnetを使うなど、いろいろなテクニックが存在します。できるだけそのまま高精細にする方法のほか、画風を大きく変えたり、描き込みを増やしたり、線画だけは固定して塗りだけを入クォリティにしたり。この手法にどれだけ熟達しているかによってAIイラストの出来は大きく変わってきます。
プロンプト再現の上手なモデルAで生成し、リッチな描き込みをしてくれるモデルBでimg2imgアップスケールするのが個人的なオススメ。アップスケールについてはこちらの記事にまとめています。
「インペイント」で一部分だけi2i
さきほどは画面全体をimage2imageしましたが、イラストの一部だけに作用させる「インペイント」という機能もあります。これは、キャンバス上の良い部分は残して、気に入らない部分だけをピンポイントでレタッチ(修正)するimage2imageです。
このGIF動画は、顔以外のデザインをきちんと保持しながら、表情だけをインペイントで変化させたものの紙芝居です。画面全体にi2iを掛けると胸元のマークやリボンの形が変化してしまうので、インペイントによって差分を作っています。
ミナちゃん百面相
— 賢木イオ🍀AIイラスト (@studiomasakaki) March 6, 2024
こういうのが労力0でできるのがAIのよいところ pic.twitter.com/lkEUEticZW
NovelAIのインペイントに比べると、SDでのインペイントは操作がやや複雑ですので、使い方についてはこちらの記事をご参照ください。
さきほどの「百面相GIF」の作り方はこちらから。初めてインペイントをやるときはこの方法で挑戦してみると、感覚がつかめると思います。
NovelAI「V3」のインペイント機能は記事執筆時点で群を抜いており、表情変化だけでなく、服やポーズ、キャラごと変化させるなど、幅広い絵作りが可能になっています。こちらも解説記事が複数ありますので、ぜひ試してみて下さいね。
【重要】やってはいけないこと
img2imgの話までたどり着いたので、ようやくこの話ができます。画像生成AIはさまざまな不可能を可能にする夢のようなツールですが、法律上、またはモラル上やってはいけないことがいくつもあります。必ず下記を理解した上で使用するようにしてください。
1.他人の著作物のimage2image
画像生成AIユーザーとして、最大のタブーの一つが「他人が権利を持つ画像をimage2image(通称i2i)すること」です。AIイラストをめぐっては、他人が苦労して描いたイラストをi2iして自作品と称したり、「こっちのほうがうまい」と愚弄したりする悪質行為が何度も露見し、画像生成AIユーザー全体にとって大きなダメージとなっています。
二次創作でもこんなんされたら泣くわ pic.twitter.com/3Y7st4BuuR
— 山波つい (@tsuitate1572) January 22, 2023
i2iパクリはどんなに加工しても元絵を知っている人にはバレますし、明確な著作権侵害行為であり、訴訟に発展する恐れもあります。絶対にしないようにしましょう。i2iしていいのは、主に「自分でt2iした画像」「自分で描いた絵」「自分で撮った写真」「使用許可を取っている素材」と、それらを元に自分で加工した画像だけだと思って下さい。Google画像検索で出てきた画像をポンと放り込んでi2i・・・のようなことをしていると、いずれ大変なことになります。
AI生成物と著作権の関係をどのように理解すればよいかについては、文化庁が有識者を集めて議論を重ね、「素案」を作ってパブリックコメントも募集した上で、2024年3月に「AI と著作権に関する考え方について」という資料にまとめられました。

文化審議会の著作権分科会・法制度小委員会がとりまとめたもの。
非常に長大な内容の上、正確性を期すためにある程度著作権法の知識がないと何を伝えたいのか分かりにくい言い回しがたくさん出てきますので、まずは要点のみをまとめた「概要版」を読むことをオススメします。(※ここに示された考え方は、あくまで有識者が「現行法や過去の判例からはこう解釈するべきであろう」と示したもので、最終的には裁判官による司法判断に委ねられることも覚えておきましょう)
ポイントは、手書きだろうがAIだろうが、「他人の著作物に相当類似していて、それが偶然でなければアウト」ということ。これを「類似性」と「依拠性」と言います。たとえある著作物に依拠していても、そもそも似ていなければ著作権侵害ではありませんが、それでも他人の著作物のi2iはトラブルを巻き起こすので、手を出さないようにしましょう。
i2iパクリをめぐるこれまでの経緯は、こちらの全体公開記事でも紹介しています。パクリ行為だけでなく、2022年10月以降のAIイラスト技術の歩みも俯瞰できるつくりになっていますので、時間がある方はご一読ください。
2.クリエイターへの敬意のない言動
画像生成AIは絵心のない人でもハイクォリティなイラストを生成できる反面、苦労してイラスト技術を研鑽してきた人々にとっては、「これまでの努力を無にするもの」と思われても仕方のない技術です。ただでさえそうした背景がある上に、他人の作品のi2iや画風を模倣したLoRAを使った嫌がらせを行うユーザーが相次いで現れ、イラストレーターや漫画家、作家などクリエイターへの敬意に欠けた言動も繰り返されてきました。
FANZAやPixivといったプラットフォームでは、粗製濫造した作品を大量投稿する行為が散見され、ランキングやタグがAI生成作品ばかりになってしまう現象も。この問題は、のちにFANBOXやファンティアといった支援サイトでのAI生成コンテンツの投稿が禁止されることにつながってしまいました。(※ちなみに、AI生成の技術解説コンテンツは独自の創作性を持ったコンテンツとしてFANBOXの利用が認められています)
AIユーザーに対する世間の目は大変厳しいものがあり、クリエイターを軽んじるような言動は必ずトラブルを招きます。AIイラストを楽しめる日常を守るためにも、法的トラブルに巻き込まれないためにも、おのおのがラインを引いて行動することが大切だなと身にしみて感じています。
一方で、画像生成AIを利用した人物・企業に対し、SNS上で苛烈な言葉を浴びせる事案も相次いでいます。誰かの権利を侵害しているならともかく、画像生成AIを使っただけで誹謗中傷や攻撃のターゲットにしてよいという法はありません。文化庁の示した「考え方」に沿って利用している限り、必要以上に萎縮する必要はないと考えています。

3.無修正画像の投稿
これはちょっと違う方向からの注意事項。画像生成AIが生成するエロ画像は、性器のほとんどが無修正であることが多いです(逆に言うと、モザイク入りのものが出ることもある)。これは、日本以外の多くの国では性器にモザイクを掛ける習慣がなく、エロ画像を生成するために学習させた画像セットが無修正のものであることに由来しています。自分で楽しむぶんには良いのですが、投稿するときはかならず自分で修正するようにしてください。
日本国内において、性器が露骨に描写されているものは「わいせつ物」と解釈されています。たとえ投稿先が海外サイトであっても、日本国内から投稿した場合は、刑法175条の「わいせつ物頒布等罪」が成立します。(参考:FC2事件)
AnimagineXL3のようにHイラストの描写が得意なモデルだと、全年齢イラストを作るつもりのプロンプトでも、nsfwなイラストが生成されることがあります。SDwebUIの拡張機能でそうした画像が出たときはサムネイルが表示されないようにすることも可能です。

4.「本物」と見紛う画像の投稿
著作権以外にも、配慮しなくてはならない名誉権や肖像権、パブリシティー権などの問題があります。画像生成AIに習熟してくると、例えば追加学習によって特定のイラストレーターの画風をそっくり真似たり、実在する人物の「存在しない写真」を生成したり、児童ポルノと見紛うような精巧な「非実在児童」のnsfw画像を生成したりすることができるようになります。
これらに共通するのは、「本物」と見紛う画像であるということです。こうした紛らわしい画像を公の場に公開すると、著作権上の問題をたとえクリアしたとしても、全く別の文脈で法的トラブルを招くことが考えられます。法的にはいろいろ言えるのですが、実在の人物や商標がからむ場合、「自分がされたら怒るようなことはしない」のが、自分を守るために必要な行動だと思います。
また、画風の模倣については、よく「作風や画風はアイデアと同じで著作権保護されない」「著作権保護されるのは表現(上の本質的特徴)だけだ」ということが言われます。これは事実ではありますが、画風模倣LoRAを作ったときに、画風だけでなく著作権保護された「表現」まで模倣できてしまうことが往々にあります。画風と表現の境界線は訴訟で争われない限りはっきりしたことは言えませんので、「自分が模倣しているのは画風だけだから合法だろう」と言っても通らないことがあることだけは覚えておきましょう。
よく聞く「LoRA」って何?
さて、「やってはいけない」ことを語る上で触れておきたいのが「LoRA」の存在についてです。既存のキャラクターや有名絵師の画風を再現できる技術として、これから画像生成に触る方でも耳にしたことがあるのではないでしょうか。
AIが学習していない概念を後付けで学習させることを「追加学習」と言いますが、この追加学習の方法として特によく知られているのが「LoRA」や上位版とされる「LyCORIS」などの技術です。キャラクターの目のデザインだけを変えたり、ポーズや構図を指定したり、描き込みを増やしたり、逆にフラットな塗りに変えたり、線画にしたり、画風を変えたりーと、アイデア次第でありとあらゆる絵作りができるのがLoRAの利点です。

「マイナス適用」すると逆に描き込みを増やすことができる(左)
これは数十枚程度の教師画像とテキストのペアを自分で学習させることで実現でき、出来に「うまい・下手」がありますが、素人でも作ることができます。Civitaiなどでこうしたモデルの公開が盛んに行われており、自分で学習させなくても、他のユーザーが作ったモデルをダウンロードして使用することが簡単にできます。
一方で、この技術により理論上あらゆる画像生成が可能になるわけですから、当然「本物に見える画像」の生成もできてしまいます。たとえば特定の有名人の写真を追加学習させたLoRAで不名誉なニセ写真を作ったり、特定イラストレーターの過去の作品を追加学習させて本人の名前付きで頒布したりといった行為は、トラブルを呼び込むばかりか、刑事事件や民事訴訟に発展する恐れもある危険な行為です。
先述したとおり、確かに画風は著作権保護されませんが、自分が学習させたLoRAが作品群に共通する本質的表現まで模倣できてしまった場合、教師データのダウンロードなどが著作権侵害になりうることが文化庁の「考え方」でも示されています。ウェブ上で共有されているLoRAを使って生成だけをする場合でも、あまりに特定著作物に類似している画像が出てしまい、それを私的利用の範囲を超えて利用すれば(SNSに投稿するなど)、著作権侵害になり得ますので、生成されたものをよく見て、公共の場に出してよいものかを考えることが身を守る上で重要となります。

Controlnetでできるようになったこと
23年2月に登場したcontrolnetも、LoRAと並んで非常に重要な拡張技術です。入力画像の「要素」を抽出して生成に生かすことができる技術なのですが、「Canny」や「Depth」「Scribble」などさまざまな種類があり、使いこなすと次のようなことが可能になります。










記事中で検証した一部の作例です。Controlnetの基礎的技術を使っており、AI補正を強めに掛ける場合と、弱めにして絵柄を保持する場合の2種類の設定値に分けて検証しています。 pic.twitter.com/22L7DLfzv1
— 賢木イオ🍀AIイラスト (@studiomasakaki) October 16, 2023
Tile:元画像の線画をできるだけ動かさないようにAI補正
長くなるのでこのあたりにしておきますが、Controlnetが登場する23年2月まで、こうしたことは一切できませんでした。プロンプトを練りに練って「お祈り」するか、あとはimg2imgでポーズを作るしかなかったのです(これがi2iパクリが横行した理由のひとつ)。現在はここまで自由度が広がっているので、嫌がらせ目的でなければそうした迷惑行為をする必要性もなくなってきています。
スタジオ真榊では、こうしたControlnetやインペイントを駆使したテクニックの研究を日夜行ってきました。きっとお役に立てると思いますので、ご興味がありましたらぜひこれまで積み重ねてきたControlnet研究の記事も読んでみてくださいね。

中級者になるために
ここまでの内容がだいたい飲み込めたら、ある程度好きなイラストを生成できるようになっていると思います。最初は好みの学習モデルを探したり、エッチな画像を作れるか試してみたり、プロンプトを勉強してみたり、スケールやステップ、サンプラーにこだわってみたり、LoRAを使ったイラストに挑戦してみたりと、触っているほどに上達していくことと思います。
今読んで頂いているこの記事「AIイラストが理解る!」には画像生成を始める上で最低限必要な知識を詰め込みましたが、重要なのは「画像生成で何をしたいか」だと思います。推しキャラの絵を生成したいのか、手描きイラストの補助にしたいのか、TRPGに使うのか、漫画を作ってみたいのか、目的はさまざまだと思いますが、思ったとおりの絵を生成するためには、プロンプト知識や加筆、インペイント、Controlnetや追加学習、NovelAIなど他のモデルの活用、高品質なアップスケールといった知識が必要になるはずですので、これまでの記事が役に立てばと思います。
「たくさんありすぎて何から読めば良いか分からない」という方が多いと思いますので、下記に読んで欲しい順番で主要記事を並べました。これらを流し読めば、だいたいAI絵で何ができるか、自分のやりたい事を実現するにはどんな機能を使えばいいかが理解できるはずです。
作例紹介
2024年以降の作例紹介です。いずれもキャラクターLoRA未使用

NovelAIv3使用。加筆修正+エフェクト加工(カラー調整)

NovelAIv3使用。バイブストランスファーi2i作例

AnimagineXL3.1使用。トンチキi2i(天秤)、Controlnet、V3インペイント等

Animagine3.1使用。1p作品だったが、のちに漫画シリーズに。
終わりに
画像生成のワークフロー、つまり何のUIで何のモデルを使い、どんな設定で生成してどうアップスケールするかは、人によってさまざまです。そして、同じ人でも、時期によってどんどんその方法は変わっていきます。2024年3月現在の私の生成フローはと言えば、ローカルはAnimagineXL3.0かそのマージモデルを使用し、NovelAI、Nijijourney、DALL-E3を組み合わせて、主にV3インペイントやControlnetを活用して絵作りをしていく手法がメインです。
こちらの記事にも書きましたが、私が画像生成AIに取り組んできたモチベーションは「理想のスレミオ(水星の魔女のキャラクター)が見たい!」に尽きているので、意図通りのポーズや表情、構図にするべくControlnetや手描き技術との掛け合わせ方を重点的に研究してきました。
が、どの技術がその人にとって「使える」かは千差万別です。現時点で言えば、まず最初に触れてほしいのはNovelAIv3とそのインペイント技術です。Controlnetでしかできなかったさまざまな部分修正が意図通りにできる超機能ですので、NovelAIのプロンプト手法とともに覚えておくと、SDとの組み合わせで一気にやりたいことができるようになるはずです。
一番AIイラストのクォリティそのものが上がるのは、結局優れた学習モデルを入手することと、画風に合ったアップスケールの手法を身につけることです。性能のよい学習モデルはツイッターやDiscordなどですぐ話題になるので、アンテナを貼っておくと良いでしょう。24年3月現在で言えばAnimagineXL3が人気を集めており、SDXLで生成が可能な環境であれば最初の選択肢になろうかと思います。

ここまで長い文章を読んでくださり、ありがとうございました。最後に、スタジオ真榊のツイッターアカウントを貼っておきます。最新情報はこちらでお知らせしているので、ぜひフォローしてみてくださいね。これを読んでくださったあなたが、素晴らしいAI生成ライフを送れることを祈っています。
今からAIイラストを覚えたい方向けに、これまで得た知見を3万字のnoteにまとめました。プロンプト辞典と120本の枝記事で、これだけ読めばAIイラストの基本は網羅できるはず。もちろん無料です!
— 賢木イオ🍀AIイラスト (@studiomasakaki) March 8, 2024
AIイラストが理解る!StableDiffusion超入門【2024年最新版】A1111、Forge対応 https://t.co/1h95VGgz8B pic.twitter.com/oySJ8wmiX9