PythonでVCPスクリーニング

初投稿です。
Pythonでミネルヴィニ先生のVCP(ボラティリティの収縮パターン)スクリーニングをしてみました。
ちなみにミネルヴィニ先生はこんな方です。
USインベスティングチャンピオンシップで優勝経験を持ち、『マーケットの魔術師【株式編】』でも取り上げられた“生ける伝説的トレーダー”のマーク・ミネルヴィニは、5年連続で3桁のリターンを上げ、年平均で220%、複利での総リターンは3万3500%に達した。
VCPとは
ミネルヴィニ先生が提唱するVCPとは、ある銘柄が急上昇する前の横ばい期間である「ベース」の左側から右側にかけてボラティリティが低下するチャートパターンのことです。(左側から右側とは、株価チャートの左側から右側、つまり過去から現在にかけて)
ミネルヴィニ先生は、このボラティリティの低下したところをTと呼んでおり、通常VCPのセットアップは2から4回のTが形成されると言っています。
なお、VCPは株価のボラティリティと併せて出来高が減少していることも条件となりますが、今回は株価のボラティリティのみでスクリーニングしています。
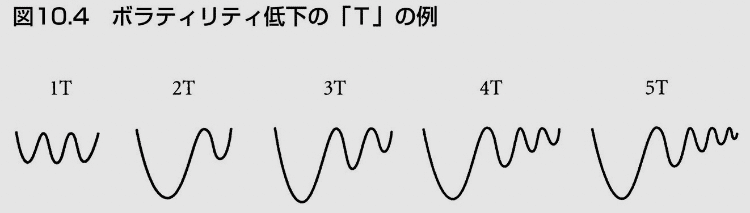
スクリーニング手順
今回、Pythonで挑戦したのは、このボラティリティの低下をスクリーニングすることです。
大まかな流れはこんな感じです。
yfinance(https://pypi.org/project/yfinance/)で180日間の終値データを収集
Numpyのpolyfitで10次関数に近似
極大値と極小値を順に並べ、それぞれの低下率を取得
2Tをスクリーニング(直近の低下率<直近より一つ前の低下率)
3Tをスクリーニング(直近の低下率<直近より一つ前の低下率<=直近より二つ前の低下率)
2Tもしくは3Tでトレンドテンプレート※に該当する銘柄を抽出
※機関投資家が買い集めをしている時期を特定するためのミネルヴィニ先生による基準
結果
2T判定された銘柄
['ARGX', 'ARTNA', 'AZPN', 'BANF', 'BMY', 'BTI', 'CNC', 'CSGS', 'CVI', 'CYTK',
'ESLT', 'FNKO', 'GO', 'IMXI', 'ITCI', 'LW', 'MGPI', 'MRCY', 'NTUS', 'POLY',
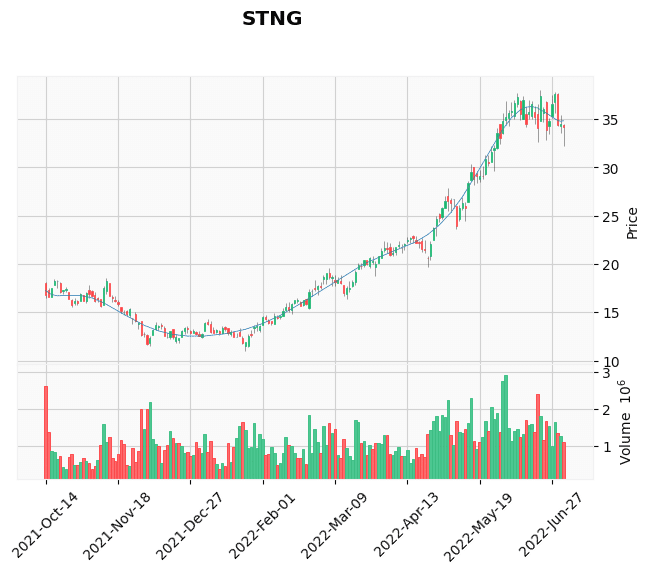
'POST', 'PRPH', 'RGP', 'SAFT', 'SAIL', 'STNG', 'SWCH', 'T', 'TEN', 'TMUS',
'TUFN', 'VIVO', 'VTRU']3T(以上)と判定されたもの
['BAH', 'CNR', 'EXLS', 'HUM', 'KNSL', 'LLY', 'MANT', 'MRK', 'MTOR', 'NPTN',
'NVO', 'PFIS', 'PSN', 'RENN', 'SIGA', 'SNEX', 'SWIR', 'Y']チャートで確認してみましょう。
それっぽく見えるもの
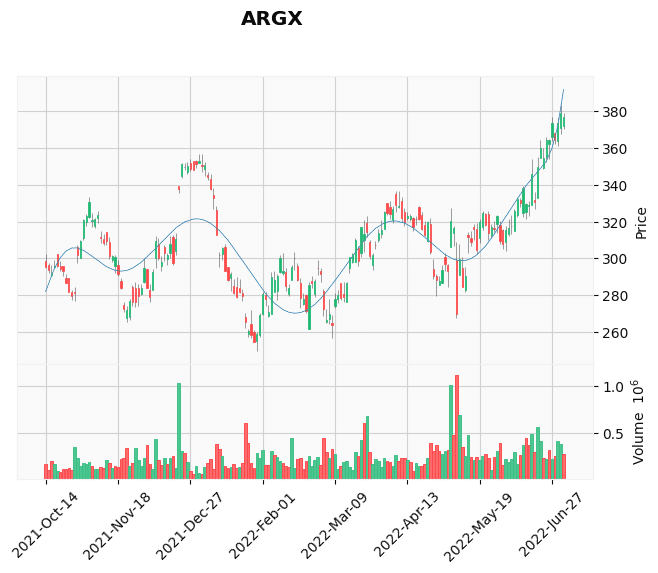
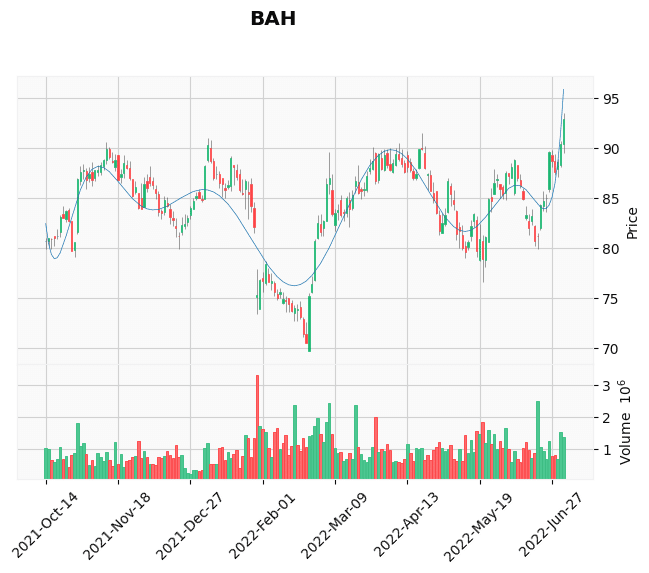
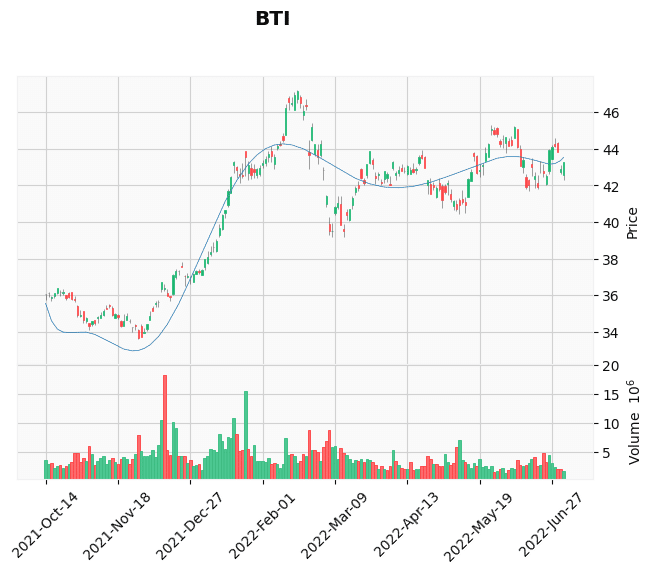
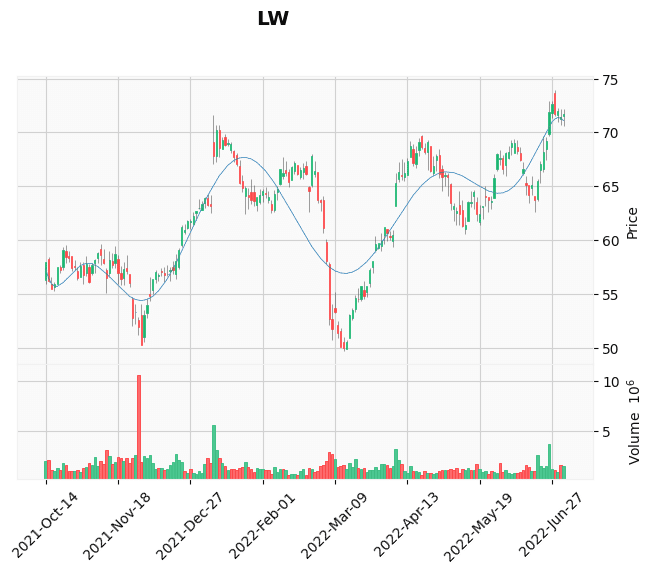
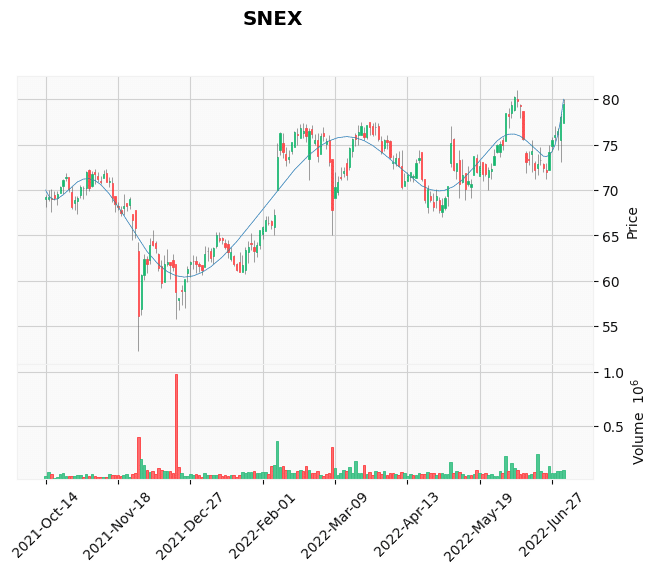

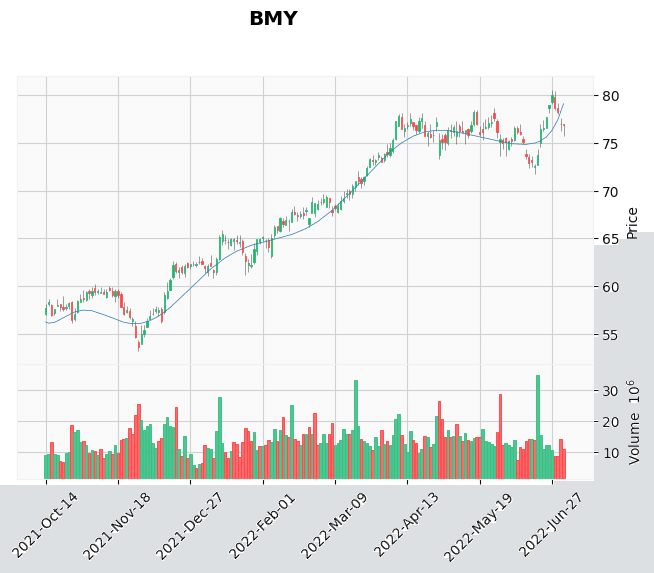
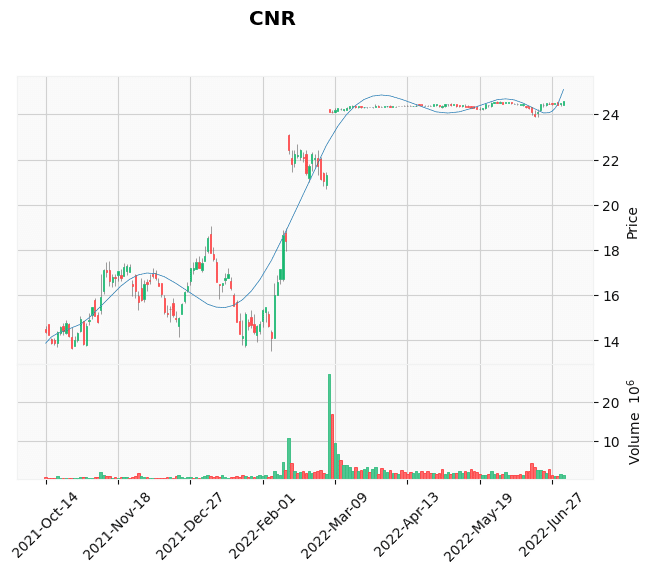
それっぽく見えないもの
全部のチャートはこちらのPDFから
感想
結果を見ると、それっぽく見えるものもありますが、すでにブレイクアウトしたものや右肩上がりのチャートなども含まれてしまっています。
直近2つの極大値(凸)の株価が例えば5%程度の範囲内という条件を付けてみると、水平な抵抗線でボラティリティが収縮するチャートパターンに絞れるかも知れません。
期間や何次関数に近似すれば精度が上がるかの検証や、週足でもやってみたいところですが、それはこれからという事で。
おまけ
プログラミング初心者なので恥ずかしいですが参考までにコードを載せておきます。変なところがあればこっそり教えてください……
上の結果はトレンドテンプレートでさらにソートしてるので、このコードではもっと多い銘柄が出るはずです。
import numpy as np
import pandas as pd
import numpy as np
from scipy import signal
df_365d = pd.read_excel('365price.xlsx', index_col=0) #Excelから株価情報を取得
vcp_t2 = []
vcp_t3more = []
ticker_list = list(df_365d.columns.values)
df_180d = df_365d[-180:] #期間の調整(180日)
#近似値計算
df_180d['date_no.'] = list(range(len(df_180d),0,-1))
df_app = df_180d.copy()
x = np.array(df_app['date_no.'])
for ticker in ticker_list:
y = np.array(df_app[ticker])
coe = np.polyfit(x, y, 10) #10次関数に近似
y3 = np.poly1d(coe)(x)
df_app[ticker] = y3
for ticker in ticker_list:
maxid = signal.argrelmax(np.array(df_app.loc[:,ticker])) #極大値のindex取得
minid = signal.argrelmin(np.array(df_app.loc[:,ticker])) #極小値のindex取得
app_maxlist = df_app.index[maxid[0]] #極大値の日付取得
app_minlist = df_app.index[minid[0]] #極小値の日付取得
applist = pd.concat([df_app.loc[app_maxlist,ticker], df_app.loc[app_minlist,ticker]]).sort_index() #極大値と極小値を1つのリストにしてソート
t_depth = []
if len(applist) >= 4: #極値が4以上(2T以上)
if applist[0] > applist[1]: #最初の極値が極大値の時
if len(applist) % 2 == 1: #極値の数が奇数の時
for i in range(0, len(applist)-1, 2):
t_depth.append(( applist[i + 1] - applist[i] ) * -100 / applist[i])
else:
for i in range(0, len(applist), 2):
t_depth.append(( applist[i + 1] - applist[i] ) * -100 / applist[i])
else:
if len(applist) % 2 == 0:
for i in range(1, len(applist)-1, 2):
t_depth.append(( applist[i + 1] - applist[i] ) * -100 / applist[i])
else:
for i in range(1, len(applist), 2):
t_depth.append(( applist[i + 1] - applist[i] ) * -100 / applist[i])
if (1 < len(t_depth) <= 2) and (t_depth[-1] < 5):
if t_depth[-1] < t_depth[-2]:
vcp_t2.append(ticker)
elif (len(t_depth) > 2) and (t_depth[-1] < 10):
if t_depth[-1] < t_depth[-2] <= t_depth[-3]:
vcp_t3more.append(ticker)
elif (t_depth[-1] < t_depth[-2]) and (t_depth[-2] > t_depth[-3]):
vcp_t2.append(ticker)
print(vcp_t2)
print(vcp_t3more)