
[Transfomerを理解する①]位置エンコーディングについて

本日からTransformerについて勉強した内容を、「Transformerを理解する」シリーズとして整理していきたいと思います。
私自身、理系でも数学が得意でもないので、そういった方でも理解できるようになるべくわかりやすく書きたいと思います。
素人のため、間違ってる箇所が確実に発生するかと思います。あくまでも、Transformerとは何かをイメージするための参考としていただければ幸いです。
位置エンコーディングとは
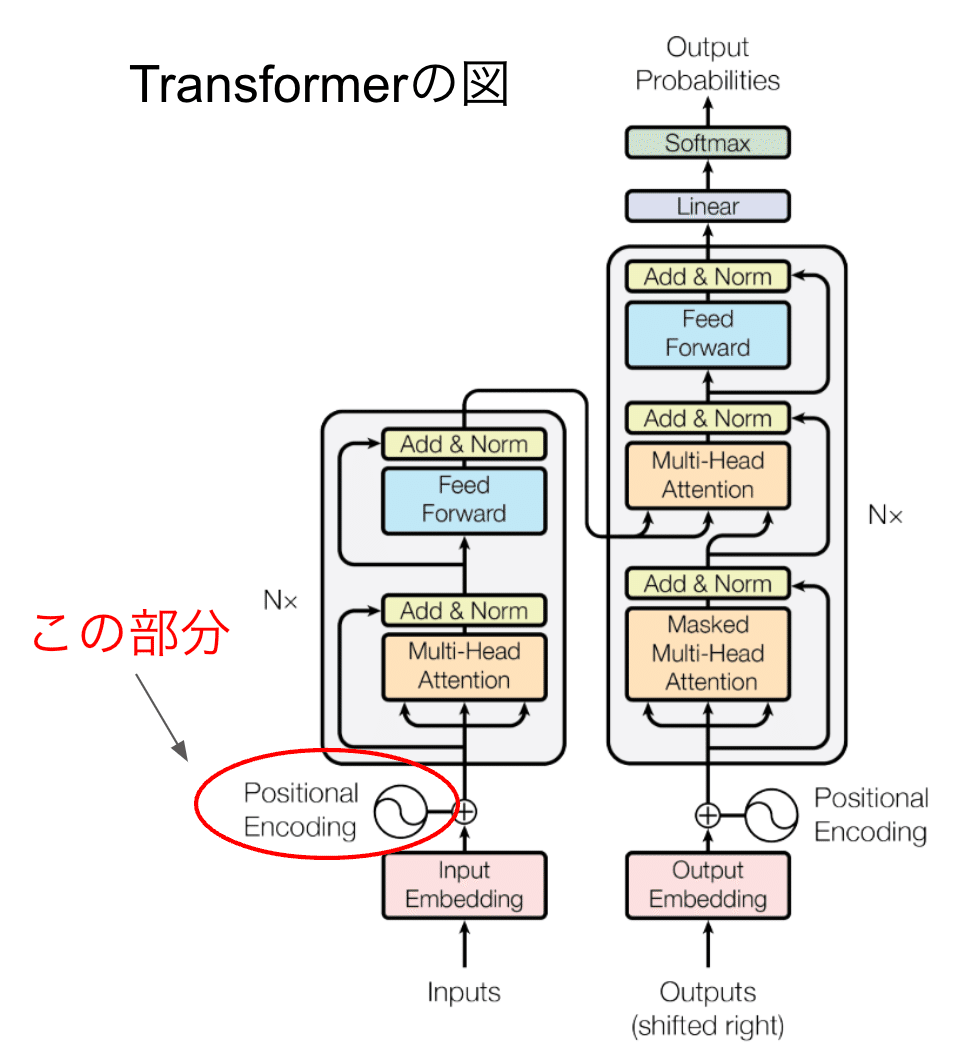
よく見るTransformerの図の、赤丸の箇所が「位置エンコーディング」です。
存在理由は、以下です。
単語の順番(位置)を表現するため
位置エンコーディングの詳細に入る前に、その前工程のインプットとインプットembeddingについて解説します。
InputとInput Embedding(意味ベクトル)

インプット(図のInputs)は入力文章で、Input Embeddingはそれがベクトル化(畳み込み)されたものです。

「私の猫」という文章を入力した場合、まずそれが「私」、「の」、「猫」という最小単位に分けられます。これはトークンと呼ばれます。
トークンにわけることを「トークナイゼーション」と言います。
トークナイゼーションについては別の記事で詳しく書くかもですが、ここでは簡単にざっくりと説明します。
これは事前にモデルを訓練することで、単語とベクトルのペアを作っておきます。
全単語収録された辞書で、意味欄にはベクトルという数字の羅列が並んだもの、くらいに思っておけばOKです。

行われたことは以下の3つです。
「私の猫」という文章を入力
モデルがトークンに分ける(「私」、「の」、「猫」というトークン)
D次元のベクトルに変換
仮に5次元のベクトルだった場合、以下の図のようになります。

ここまでが、Input embeddingです。
これに、位置情報を追加することが、位置エンコーディングになります。
位置エンコーディングの詳細
意味ベクトルに、位置情報を付与する役割です。

位置エンコーディングの数式
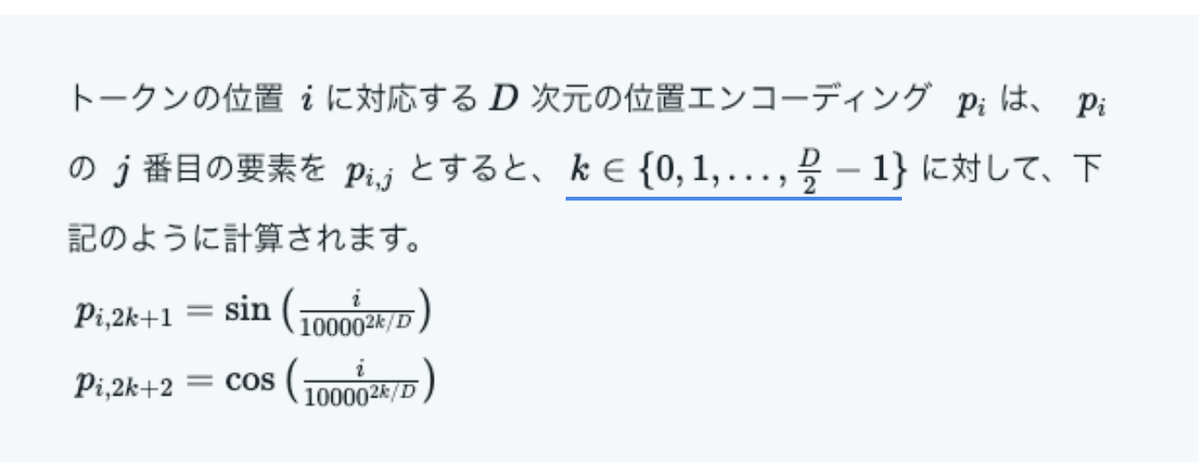
位置エンコーディングは、数式で書くと以下のような内容です。
トークンの位置 $${ i }$$ に対応する $${ D }$$ 次元の位置エンコーディング $${ p_i }$$ は、$${ p_i }$$ の $${ j }$$ 番目の要素を$${ p_{i,j} }$$ とすると、$${ k \in \{0, 1, \ldots, \frac{D}{2} - 1\} }$$ に対して、下記のように計算されます。
$${ p_{i,2k+1} = \sin \left( \frac{i}{10000^{2k/D}} \right) }$$
$${ p_{i,2k+2} = \cos \left( \frac{i}{10000^{2k/D}} \right) }$$
急に雲行きが怪しくなってきました・・・(笑)。
1つ、1つ、見ていきます。
入力インデックス(i)とモデルの次元数(D)
青い下線の部分から説明していきます。

まず $${ i }$$は、入力文のトークンの順番(インデックス)になります。
「私」・・・1番目
「の」・・・2番目
「猫」・・・3番目
となります。
次に$${ D }$$は、畳み込みの次元数になります。今回、5つの数字でトークンを表現しましたので、5になります。
例) $${ 私 = [0.53,0.23,0.97,0.76, 0.13] }$$ ←5つの数字から構成されるベクトル = 5次元

ちなみに、この畳み込みの次元数はモデルによって異なります。
GPT-4のような大規模モデルは、数万次元にもなるようです(つまり、トークン1つに数万個の数字が並ぶベクトル)。
位置エンコーディング
次は以下の青線部の説明です。

まず、 $${ p_i }$$ は、位置エンコーディングのことです。PositionのPだと思います(多分)。
意味ベクトル(畳み込み)に、位置情報を付与する役割です。それを位置エンコーディングと呼んでいます。
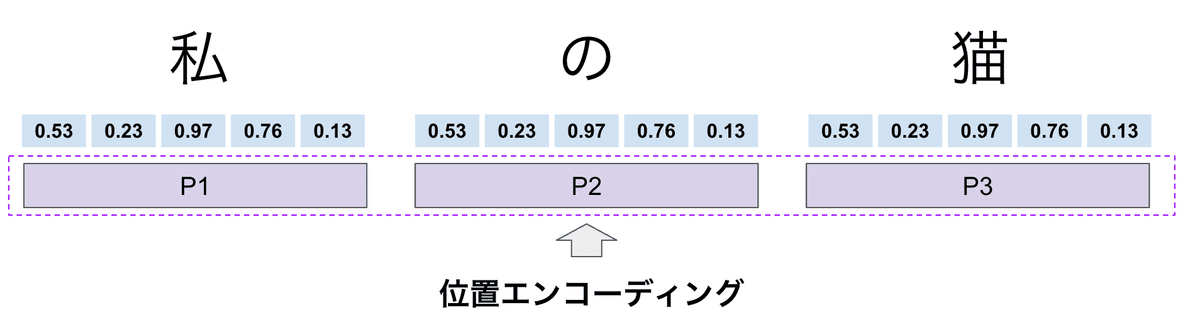
またここ出てくる $${ j }$$ 番目というのは、次元$${ D }$$ の位列を表しています。
一つの言葉のベクトルの数字の順番です。
なので、必然的に次元数と同値となります。

$${ p_{i} }$$はトークンの順番たったので、 組み合わせた$${ p_{i,j} }$$ は下の画像のようになります。

トークンの中のベクトルの要素の位置を、$${ p_{i,j} }$$ で表していたのでした。
Sin Cosを半分ずつ振るテクニック
次に、下の青い下線について解説します。
結論だけ言うと、これは単に$${ p_{i,j} }$$ に均等に$${ \sin(x) と \cos(x) }$$をあてがうためのテクニックです。
$${ k \in \{0, 1, \ldots, \frac{D}{2} - 1\} }$$ について、変数$${ D }$$があります。
今回の例文、「私の猫」は5次元のベクトルでした。
なので、Dに5をいれます。
と思いましたが、奇数だと都合が悪いことに気が付きました笑。 素人でスミマセン。
なので6次元だった場合を考えます。(理由はあとでわかります)
$${ k \in \{0, 1, \ldots, \frac{D}{2} - 1\} }$$ の $${ \frac{D}{2} - 1 }$$ の Dに6を入れると、
$${ 6/2 - 1 =2}$$ で、$${ k \in \{0, 1, 2\} }$$ となります。
$${ p_{i,j} }$$の中身
ここから、いよいよ $${ p_{i,j} }$$ の中身の数式の説明に入ります。

ここで、以下の式を再度眺めてみます。
位置エンコーディング:
$${ p_{i,2k+1} = \sin \left( \frac{i}{10000^{2k/D}} \right) }$$
$${ p_{i,2k+2} = \cos \left( \frac{i}{10000^{2k/D}} \right) }$$
すると、左の項に、 $${ 2k+1 }$$ 、$${ 2k+2 }$$ と$${ k }$$ が出てきます。
これは、$${ j }$$ の部分に$${ 2k+1 }$$ (と $${ 2k+2 }$$ )を入れてね、ということです。
$${ k \in \{0, 1, 2\} }$$ だったので、$${ k }$$をそれぞれ代入すると、
$${ 2k+1 \in \{1, 3, 5\} }$$
$${ 2k+2 \in \{2, 4, 6\} }$$
となります。 $${ j }$$ の部分の話なので、
下図のように、各要素の順番が交互にあらわれます。

次に右辺です。
$${ p_{i,2k+1} = \sin \left( \frac{i}{10000^{2k/D}} \right) }$$
$${ p_{i,2k+2} = \cos \left( \frac{i}{10000^{2k/D}} \right) }$$
下図のように、$${ j }$$ の部分に、サイン,コサインが交互に入るようになりました。

sin、cosは実数なので、下図のように値が決まります。

最後に加算する
最後に、入力トークンの意味ベクトルと足し合わせます。
加算するために、D(次元)を揃えたんですね。

Transformerの図の、プラスマークは、そのまま足し合わせることを表していました。
なぜこんなことをするのか
一体何でこんな複雑なことをするのか。
理由は、以下のことを達成したいからです。
畳み込みベクトル(意味ベクトル)に位置情報を付加したい
次元がどれだけ大きくなっても、一意の位置情報ベクトルにしたい
位置ベクトルを大きくしすぎてはいけない
逆に、小さすぎても困る
1についてはこれまで書いたとおりです。次元数個の位置エンコーディング(ベクトル)を加算しました。
2.次元がどれだけ大きくなっても、一意の位置情報ベクトルにしたい
さきほど、ChatGPT-4は数万次元とありました。これ全てに位置情報をつけたいわけですが、しかもそれがユニークなものである必要があります。
Sin Cosの値は、 $${ -1 < y < 1 }$$の間で値が繰り返されるので、ことなる位置情報を生成するのに便利だ、とのことです。

また、P(i)は実数の固定値の為、常に一意となります。

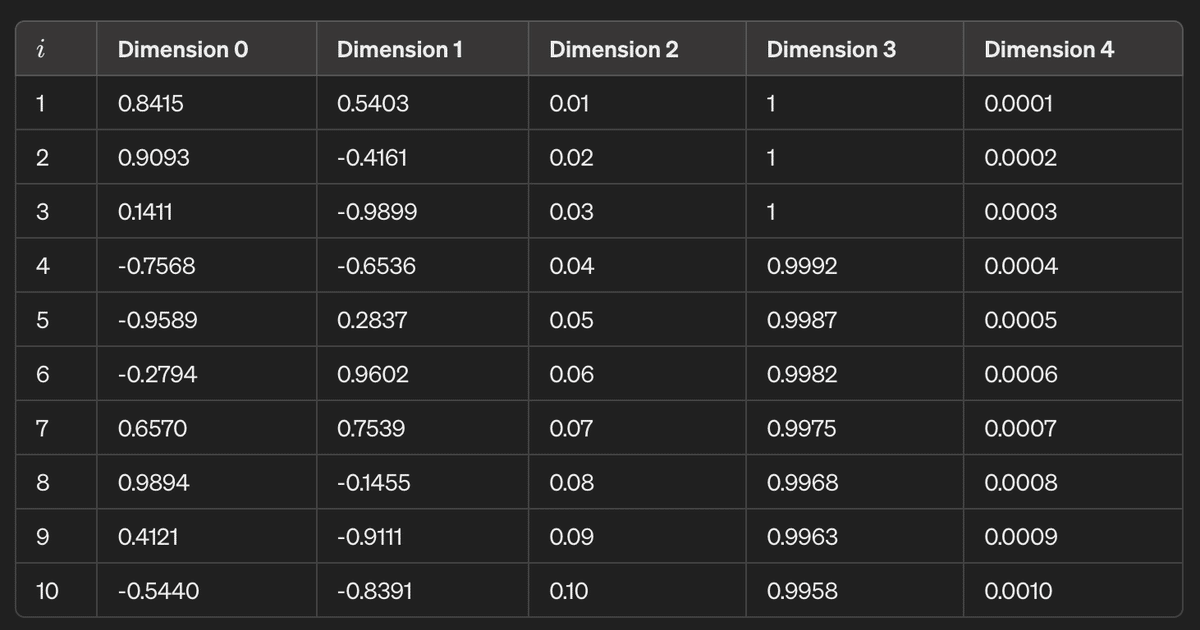
以下の画像は、D=5、iが10までの位置エンコーディングの実数値となります。
3.位置ベクトルを大きくしすぎてはいけない
次に3については、以下の記事が大変わかりやすかったので大いに参考にさせていただきました。
インデックスを足すのを最初に考えた時、普通に1、2、3‥という順番を使えばいいじゃん、と思いました。
ただそうすると、長文だとどんどん値が大きくなってしまいます。
10,000単語の入力だと、10,000という値の位置情報が加算され、大きくなりすぎて意味情報が打ち消されてしまいます。
ここで、Cos、Sinの出番です。Sin、Cosは単位円上の-1から1の値をとります。

4.逆に、小さすぎても困る(表現に特徴が出ず役立たず)
$${ p_{i} }$$の式の中に、謎の10,000という数字が有りました。

これによって、次元によって周波数の波の振動が変わります。
高次元になればなるほど、周波数が高くなって、振動が多くなります。
また、SInとCosは位相が $${ π/2 }$$ ずつずれています。これも、多用な位置情報としての情報価値が大きくなるようです。
ちょっと完全にはこの部分を理解しきれていない気がします。
またどこかで理解が深まったら、追記していきます。
まとめ
位置エンコーディングは意味ベクトルの成分ごとに位置情報を付与する
SinとCosという異なる位相と、周期性という特徴を利用している
ということでした。
最近はChatGPTのおかげで、これまではお手上げだった数式も理解しやすくなりました。いろいろなグラフやコードも生成仕放題、Google Colabで実行し放題です。
完全に学習革命が起きたと感じています。
というわけで、次回以降もTransformerの記事を上げていきたいと思います。
いつになるかわかりませんので、フォローしていただきお待ち下さると幸いです!
この記事が気に入ったらサポートをしてみませんか?