
文字起こしツール検証

はじめに
動画からの文字起こし、、有料サービスを使えばそりゃいくらでもやれるところはある。
だが今やAI全盛期。無料ツールも山ほどあるし、AIが聞いたら何でも教えてくれる。無料と有料の差もあるっちゃあるがそこまででもないというプロの話もよく聞く。
そこで「無料で文字起こしが出来ないか?」「自分でアプリつくれちゃえないかな?」と思ったので試してみた。
半日に及ぶ壮大な悪戦苦闘を残しておかないともったいない。ということで備忘録として残しておく。
手順
手順は下記を想定。
1:動画はすでに保存済。(mkvファイルだが)
2:動画からmp3に変換(HandBrakeとPremiereを使って対応。ここも改善ポイントだな・・)
3:mp3から文字起こしするツールを作る(Clova noteなどのかわり。)
この3を対応します。
無料の文字おこしがググってもchatGPTに聞いてもパッと出てこないので。
(制限があるものばかり)
1と2は先ほどnoteに記載したのでまずは3
文字起こしツールがないか?
ということで、さっそくchatGPTに聞いてみた。(ググったら自社商品への誘導ばっかだったんで・・・時間の無駄だった・・・。)

名前は知っているものばかり(Aikoはしらなかったが)
・Aiko
・Whisper
・Amazon Transcribe
・Otter.ai
・Googleドキュメントの音声入力
ということでAikoをまずは調べてみた。
1・Aiko

お・・おう。
確かに良さそうではある。でもこれ、App Storeのiphoneアプリなのね。
今回はPCでの作業前提なので却下。
2・google
次がgoogleさん。geminiがあるし、geminiにmp3放り込んで文字お越ししてもらえれば一番だね。と思って試したらダメ。
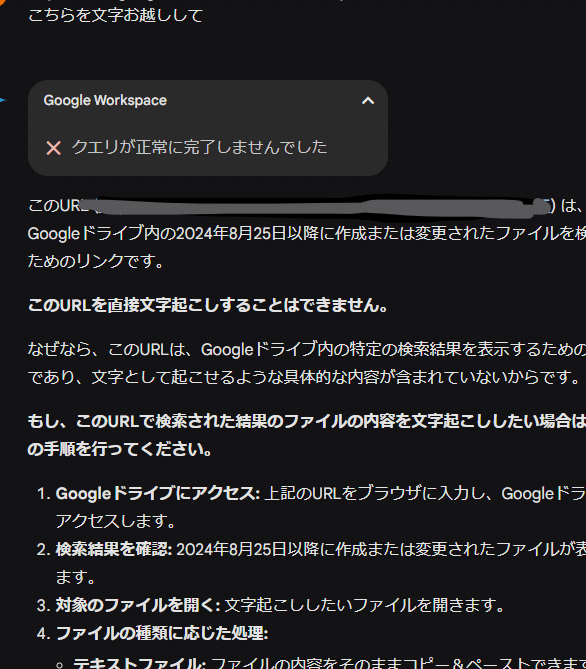
mp3ファイルのリンクを読み取り可能にしてもダメ。ちょっともうめんどくさくなってきた。
3・Otter.ai
で、Otter.ai

入れてみたけど‥いきなり英語だし。
日本語機能も弱そう;・・。なんでとりあえずやめ。
4・Amazon
次にみんな大好きAmazon。


5分のデモを試すだけ?それは使えないのでは??
とほんとは使えるのかどうかわからないけ度次を試すことに。
5:OpenAI Whisper
んで、最後にWhisper
なんとなく日本語の解説サイトを見てみたら、なんでも無料で使えるとのこと。しかもhuggingfaceで試せるとのことでやってみたら・・
mp3ファイルをあげてうまくいった・・・!!
ちょっとつかいたいひとはこれでいいんじゃね?と思います。
今回はPCからファイルをULするので、もうちょっと使い勝手よくしたい・・という思いのもと、これでもうちょっと掘ってみようと思った。
Whisperをローカルでカスタマイズして使えないか?

おなじみchatGPTさんに聞いてみた。簡単にGUIつくって、ボタン一つでできないかなと思ったら・・・できそうな返答。

whisperをcmdでインストール。
pip install openai-whisper torch
pip install tkinter # tkinterは通常Pythonに標準で含まれていますFFmpegはすでに対応済みだったんで今回は飛ばして、
Whisperを使った音声認識のコードを作れとのこと。
import whisper
# Whisperモデルをロード
model = whisper.load_model("base")
# 音声ファイルを文字起こし
def transcribe_audio(file_path):
result = model.transcribe(file_path)
return result["text"]上記をテキストファイルにコピペし、ファイル名を「wisper_transcribe.py」として保存。
あとはcdを使ってPythonが保存されている場所に移動し、
(「cd 」といれて、pythonが保存されているフォルダをドラッグ&ドロップでOK)
下記コマンドを入れて実行。
python whisper_transcribe.pyちなみにコード名は下記に変更。(gakuen.mp3と手打ちで入れ直し)
import whisper
# Whisperモデルをロード
model = whisper.load_model("base")
# 音声ファイルを文字起こし
def transcribe_audio(file_path):
result = model.transcribe(file_path)
return result["text"]
# 'gakuen.mp3' ファイルを文字起こし
file_path = "gakuen.mp3"
transcribed_text = transcribe_audio(file_path)
print(transcribed_text)
とやったら・・・うまく文字起こしできた・・!!
感動。
GUIにして素人(私)にもわかりやすくしたい。
ということで、「tkinterを使用してシンプルなGUIを作成します」を実行‥と思ったんだが、この「tkinter」を調べたところ・・・だいぶ古い規格とのこと。ならstable diffusion web uiのようなgradioとかがいいのかな?と思って調べてみたら、gradioかstreamlitがよさそう。
ビジュアル的にはstreamlitのほうがいいけど、手順がわかりやすいのはgradio、
更にシンプルなのがgradioなので今回はgradioでチャレンジ。
import gradio as gr
import whisper
# Whisperモデルをロード
model = whisper.load_model("base")
# 段落ごとに改行を挿入する関数
def format_transcription(text):
# 文の終わり(句点)で改行を追加
sentences = text.split('。') # 句点(。)で分割
formatted_text = '。\n'.join(sentences) # 各句点の後に改行を挿入
return formatted_text.strip() # 最後に余分な改行やスペースを削除
# 音声ファイルを文字起こしし、改行を追加
def transcribe_audio(file):
result = model.transcribe(file)
transcribed_text = result["text"]
formatted_text = format_transcription(transcribed_text)
return formatted_text
# Gradioインターフェースの作成
iface = gr.Interface(
fn=transcribe_audio,
inputs=gr.Audio(type="filepath"),
outputs="text",
title="Whisper 音声文字起こし",
description="音声ファイルをアップロードして、文字起こしを行います。段落ごとに改行を挿入します。"
)
# アプリの実行(ブラウザを自動で開く)
iface.launch(inbrowser=True)上記をコピペでテキストにコピーし、拡張子をpyに変えれば・・・

できちゃったよ・・。
試してみたらしかもきちんと動きました。
もちろんcmd打つのは嫌だと言ったら、「バッチファイルつくっちゃえばいいよ!」とのことで、下記をテキストにコピペし拡張子をbatに。
@echo off
cd /d %~dp0
python whisper_gradio.py
pauseするとこのバッチファイルをダブルクリックで開くようになりました。
あとは・・・改善箇所があれば対応していくだけか。
しかしいい時代になったもんだ・・というか・・・
ソフトメーカーはソフトメーカーで大変な時代だね・・。
この記事が気に入ったらサポートをしてみませんか?