『Google Cloud ではじめる実績データエンジニアリング入門』 の"note" 〜データ基盤とは? & BigQuery内部アーキ〜

いろんなウェビナーで宣伝しまくってるし、知り合いもサクっと読めて悪くないよってことだったので読んだよGoogleさん。
自分なりのメモ。
データ基盤に取り組む意義
経済産業省の『「DX推進指標」とそのガイダンス』では、以下の3要素をデジタルトランスフォーメーションに求めるITシステム要件としています。
1. データをリアルタイム等使いたい形で使えるか
2. 変化に迅速に対応できるデリバリースピートを実現できるか
3. データを、部門を超えて全社最適で活用できるか
データ活用を進めるうえでは、データ基盤として「早く、正しく、確実に」データを集める機能に加えて、「適切な権限管理のもとでデータ基盤が開放されている」という状態が重要だとわかります。
データ基盤の全体像(の中で自分が特にメモっときたいもの)
ETLとELT
対して、ELTはデータの抽出、取込み、変換という順番で処理します。
データパイプラインとワークフロー管理
ストリーミング処理を含むデータソースからデータ活用まで続く一連の流れをデータパイプラインと呼びます。データパイプラインは、あるデータソースの入力から別のデータソースへの出力まで、その間の必要な変換や加工処理の集合を指します。そのため、ETLやELTもデータパイプラインを構成する一要素となります。
例えばこんな感じ。10P目ぐらい
メタデータ管理
次に課題となるのがデータ基盤に保持されているデータの管理です。データパイプラインによって複数のデータソースから集められたデータを、データレイクやデータウェアハウスを経て利用するようになるため、いまダッシュボードで見ているデータは信頼できるデータソースから来ているデータなのか、これから使おうとしているデータは目的に合致した正しいデータなのか、といったことが気になってきます。つまり、データ基盤で管理されているデータに関するデータ、メタデータの管理が必要になります。
(中略)
テーブルやカラムに関する定義といった業務に関するビジネスメタデータとテーブルやカラムの属性やアクセス権限といったシステムに関するテクニカルメタデータの2つです。
BigQueryの内部アーキテクチャを理解する(の中で自分が特にメモっときたいもの)
ワーカー
クエリプランに基づいて数百〜数万ものワーカーによる分散処理を行います。実態はコンテナで動作する分散コンピュート環境で、クエリを走らせた瞬間だけ利用し、終了すると破棄されるプロセスを瞬時に行っています。
ネットワーク
Jupiterネットワークと呼ばれる独自のデータセンター内部ネットワーク
分散ストレージ
ストレージとコンピュートが完全に分離されており独立したスケーリングができることから、課金モデルもそれぞれ独立した利用分に対して行われます。
分散ストレージは選択されたリージョン内の複数ゾーンに自動でレプリケーションされ、高い耐久性を兼ね備えています。
このストレージは追記とスキャンに特化したストレージであるため、DWHの用途である「貯める、変更しない、消さない」という用途にパフォーマンスが最適化されています。
分散ストレージ内部ではCapacitorファイルというカラム(列)指向のファイルフォーマットにデータを圧縮し格納しています。
(中略)
複数のCapacitorファイルをテーブルメタデータとして束ねてBigQuery上ではテーブルとして表示しています。
分散インメモリシャッフル
これが Dremel(ドレメル) のことか!!
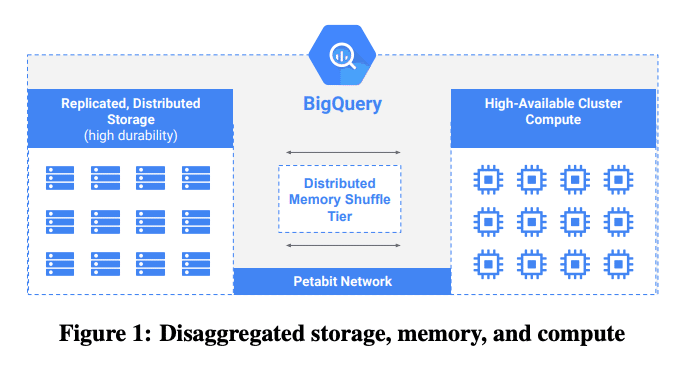
図2.8と書いている部分は本章冒頭のアーキ図参照。
分散処理の文脈で語られてきたのが、コンピュートとストレージの分離です。BigQueryでは、そこに加えて、2014年からさらにメモリを分離しています。
分散処理では、シャッフルと呼ばれるワーカー間におけるデータを移動する処理が発生します。
(中略)
BigQueryでは、図2.8に示す通り、このシャッフル処理を効率化し高可用性を担保するために、シャッフル処理をワーカーではなく、巨大な分散インメモリシャッフル基盤で行います。
このインメモリシャッフル機構を利用することによるさらなるメリットは、パフォーマンスを改善するだけでなく、特定のワーカーが障害にあってもすぐに動作を継続できることです。特定のワーカーに障害があった際に別のワーカーにその仕事を割り振り、再度この分散インメモリシャッフル機構により高速にデータを取り出すだけで済みます。
また、分散処理でよく発生する「特定のワーカーだけが、与えられたタスクの完了が予定よりも長くなっているため全体の処理時間も長くなってしまう」という問題に対応するため、BigQueryは余ったリソースを用いて処理の投機的実行を行います。例えばワーカーAとワーカーBに同じ処理をさせて、早く終わったほうを採用する、などです。これがうまく動作するのも、その処理対象データを素早くインメモリシャッフル機構から取り出せるためです。分散インメモリシャッフルこそが、BigQuryの屋台骨といっても過言ではないでしょう。
この記事が気に入ったらサポートをしてみませんか?