
『Google Cloud ではじめる実績データエンジニアリング入門』 の"note" 〜DWH構築〜

DWHとしてのBigQueryの基本操作
膨大なコンピュート環境を利用することで、データのフルスキャンを高速に実現しています。またインデックスを必要としないことで、インデックス管理の手間を削減し、どんな分析を行うか読めないデータであっても、高速かつ柔軟なアドホック分析ができます。
これは、セルフサービス型の分析基盤を志向して構築する際に重要なポイントです。とくに近年はデータマートをしっかりと作り込んで、それを定型レポートで見せるだけではなく、ユーザーにさまざまなデータソースを生データで渡して(中略)分析することがビジネス側の要求として多くあります。このような要求に対し、分析基盤チームやIT部門はセルフサービス型のデータ分析基盤をビジネス側に渡すという手法を取るようになってきています。
高可用性、Disaster Recovery計画
可用性の仕組み
99.99%というSLAを気にしておけば、自動的にゾーンレベルの障害まではサービスに影響することなく利用できます。
メンテナンス、クラスタアップデート
BigQueryのSLA条項には、「メンテナンスウィンドウを除く」という条文が存在しません。この理由は、先述したクエリ高可用性担保のしくみとマルチテナントという特徴を活かし、ユーザーに透過的にメンテナンスを行っているためです。ユーザーが使用していないワーカーにアップデートを徐々に割り当てていく(ローリングアップデート)ことで、ダウンタイムは発生しないしくみになっています。
Disaster Recovery計画
日本国内に東京リージョン、大阪リージョンが存在しており、この2つのリージョンと、オブジェクトストレージであるCloud Storageを組み合わせることでコストを抑えつつ、遠隔地におけるDRを実現できます。

(A)はBigQuery Data Transfer Serviceを用いたリージョン間データセットコピーです。最も簡単なDRの実現方法です。BigQuery DTSを用いることで、最短12時間ごとにデータを定期コピーできます。この場合、DRサイトの大阪リージョンのBigQueryのストレージにデータがコピーされ、すぐにクエリできる状態となるため、RTOはより短くできるでしょう。
(B)はCloud Storage を用いたDRです。(B-1)ではBigQueryからデータをエクスポートします。(B-2)で、東京と大阪のDual Refionクラスを用いることでDRを実現できます。ただし、Cloud Storageのコストが1リージョンのみと比べ役2倍かかることになります。そのため、(中略)Cloud Storage Transfer Serviceを利用し、転送後に東京リージョンのデータを削除することで、コストを抑えることができます。(B-3)で外部テーブルとして定義のみ行っておくことで、DR利用時のデータクエリを、BigQueryのストレージ料金ではなくCloud Storageのストレージ料金でさらに安価に利用できます。
用途別の影響隔離(タイトルがわかりづらいがスロット割り当てとかフラットレートの話)
スロットスケジューリングのしくみ
BigQueryはコンピュートの処理能力を抽象化したスロットという概念を持ちます。
(中略)
クエリプランのポイントとして、特筆すべき覚えておくべき点を3つ挙げます。
1. スロットのサイジングはあくまで主観的に決めるものであり、足りなければ動作しないものではない
2. スロットの最適化量はBigQueryが自動的に決定し、必ずしも多ければ早くなるものではない
3. クエリプランはクエリの実行中も動的に変化する
4. スロットスケジューリングにはフェアスケジューリングが働く
※3つといいつつ4つあるのは本の誤植ですかね??
「スロット消費時間」という項目があります。これはクエリを実行した際に、分散処理にかかった仕事の総量を示します。
「スロット消費時間」について、例を用いて説明します。
(中略)
4,000スロットで1秒を利用したい、という要求があったとします。ここに対し、利用できるリソースが2,000しかない場合、BigQueryはこれを2,000スロットを上限としたクエリとしてクエリプランを変更し、2秒で実行することになります。
(中略)
「時間あたりスロット消費量」×「かかった時間」=「スロット消費時間」
今回の場合:
(元のクエリプラン)4,000スロット×1秒=4,000秒[スロット消費時間]
(実際のクエリプラン)2,000スロット×2秒=4,000秒[スロット消費時間]
これが、先に説明したポイント「1.スロットのサイジングはあくまで主観的に決めるものであり、足りなければ動作しないものではない」です。
つまりスロット消費時間をかかった時間で割ればおおよその消費スロットがわかる。そして、スロットが足りなければ遅くなる。
フェアスケジューリング
良い絵があったのでお借りしました。

BigQueryで利用するスロットには、並列クエリが実行された場合にフェアスケジューリングと呼ばれるスロットを等価に並列クエリに割り振る仕組みが働きます。
(中略)
・クエリA:すべてのステージで要求5,000スロット
・クエリB:すべてのステージで要求2,000スロット、Aより本来早く終わる
(中略)
Aが先行してクエリを実行している最中にBが割り込んで来た場合を想定します。この場合、典型的なデータベースでは、すでにプランを立ててハードウェアのスケジュールをアサインしてしまっているため、クエリAによりブロックされて使えるリソースがなく、後続のクエリが実行されず、リソース待ちによって長時間待機状態になることがあります。しかし、BigQueryでは、フェアスケジューリングによりクエリプランを動的に変更し対応します。
具体的には、クエリAが先行して実行されている中、クエリBが実行された際にフェアスケジューリングが介入します。このフェアスケジューリングはクエリA、クエリBにそれぞれ均等にスロットを割り当て、処理を継続させます。そして、クエリBが終了し解放されたリソースに再度クエリAのタスクを割り当て、スループットを最大化します。
課金体系の選択 - オンデマンド課金とBigQuery Reservations
書籍内ではあまり詳しい説明はなかったが、BigQuery Reservation はフラットレートとは別。この辺は公式サイトの方がわかりやすい。
BigQuery Reservations は簡単にいうと、オンデマンド課金(もしくはフラットレート)と(フラットレートではない)定額課金をいつでも切り替える機能。
切り替えはコマンド、もしくはコンソールから行い、最低60秒単位に購入したslotに応じて課金される(Flex Slots)。Flex Slots を有効にしている間はオンデマンドによるクエリ容量による課金は発生しない(ただしslotが購入した分しか使えない)。
BIgQueryのデフォルトであるオンデマンド課金(クエリでスキャンしたサイズによる課金)は、プロジェクトあたりの同時実行スロットの最大数は2,000となっています。しかし、短期間であればリージョンで余っているリソースをベストエフォートで2,000スロットを超えて利用できます(バースト)。したがって、スモールスタートの場合はコスト効率性に優れると言えるでしょう。
スキャン量による課金は予測が難しく、予算を正確に管理したい場合も不向きと言えるでしょう。これらの課題を解決するのがBigQuery Reservationの機能です。
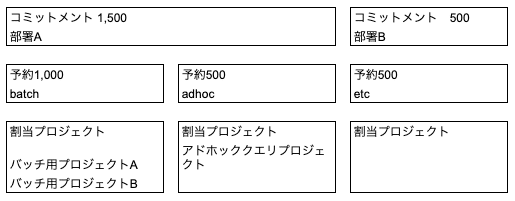
コミットメントはスロットを購入する単位です。スロットをFlex Slotsと呼ばれる秒課金から、月、年という長い単位の確定で購入できます。契約期間が長いほど、割引率は高くなります。
予約は購入したスロットに名前をつけてまとめる概念です。この予約どうしはリソース競合をしないため、ワークロード分離に利用できます。この図では、予約を用途で区切ることで、大事な処理を互いに影響しないように分離しています。例えば、図中ではadhocの予約単位の配下でどれだけリソースが使われようとも、batchには影響しません。
割当プロジェクトは予約に基づくプロジェクト、あるいはフォルダ(プロジェクトを複数まとめるための箱)です。この中に共存するプロジェクト内部でフェアスケジューリングが働きます。
BigQuery Reservationを利用して各予約を隔離することで、通常のDWHの分割と同様に、この分割によって各DWH間の待機リソースが無駄になるのではないかという不安を覚えるかもしれません。たとえば先の図でadhoc予約で1,000スロットを要求しているのに、batch予約では500スロットしか消費されていないといった場合です。
(中略)
BigQuery Reservationでは、デフォルトでアイドルスロットを有効活用する設定になっています。この場合、batch予約で利用していない500スロットをアイドルと判断し、不足しいてるadhoc予約に一時的にスロットを貸し出し、クエリプランを最適化します。
サイジング
大まかに以下の項目を確認しながら課金体系やBigQuery Reservationsのスロット数を決定するのがよいでしょう。
・目標とする値の例
・クエリの実行の長さ
・同時実行クエリの数
・待機クエリの数
・コスト
これらの情報は、BigQueryのさまざまなシステム情報を取得できるINFORMATION_SCHEMA、Cloud Monitoringの画面、あるいはBigQuery Admin Panelぁら確認できます。この目標が決まったら、以下のようなパラメータを決定することになります。
・目標に応じて決定するパラメータ
・スロットの利用量
・プロジェクトあたり同時実行クエリ数
・各種コストコントロールのためのカスタム制限
サイジング - オンデマンド課金の場合
スロットの利用量:オンデマンド課金の場合、スロットは先述の通りバーストを利用できます。そのため、基本的にはサイジングを行う必要はありません。
プロジェクトあたり同時実行クエリ数:デフォルトではユーザー保護の観点からクエリの最大同時数はプロジェクトあたり100と設定されています。
(中略)
同時実行数は変更せずにクエリをキューイングできます。クエリを実行する際に、デフォルトのinteractiveモードではなくbatchモードでクエリを実行することでキューイングされ、空きが出た際に処理を実行できます。
サイジング - BigQuery Reservationsの場合
スロットの利用量:クエリを実行してみて目標性能に足りなければ後から追加するというアプローチや、その逆も可能です。なお、コストパフォーマンスの観点から、自動で最適なスロット数をクエリに応じて提案するBIgQuery Slot Recommenderが2020年8月にプレビューでの提供を開始しました。
また、2020年8月には、スロットの上限を自動的に追加するBigQuery Slot Autoscalingもプレビューとして発表されています。これを利用することで、事前に予約に対して割り当てられたスロットを使い切った際に、自動的に最適なスロット数までFlex Slotsを利用してBigQueryの処理能力をオートスケールさせることができます。
プロジェクトあたり同時実行クエリ数:オンデマンド課金同様、クエリの最大同時数はプロジェクトあたり100に設定されています。
各種コストコントロールのためのカスタム制限:秒単位のスロット購入時、あるいはオートスケールの設定などを間違えないよう気をつけておけばコストが増えすぎる事象は発生しないでしょう。
ストレージのサイジング
BigQueryのストレージのベースとなるColossusのレイヤで担保されています。
(中略)
ユーザー側でディスクI/Oやディスク利用率などのサイジングを行う必要はありません。
目的環境別の影響隔離(開発、ステージング、本番と環境わかる話)
書籍の中でもほとんど内容なし。要はGCPプロジェクト分けろということ。
BigQuery Reservationsを利用した際にも、戦術の通りスロットを利用していなければ、他のプロジェクトから開発、ステージングといった優先度の低い環境のプロジェクトも利用できるため、無駄がありません。
テーブルを設計する
パーティション分割
絡むベースと取込み時間で分割の2種類があるが、カラムベースだけ覚えておけば良い。
パーティション分割は、カラムのデータ範囲でテーブルのテーブルのバックエンドのファイル(BigQueryストレージ内の物理的なファイル)を分割し、クエリ時のスキャン範囲を限定することにより、効率的なデータの読み出しをサポートします。
パーてぅション分割の特性としては、パーティションごとにデータの有効期限を設定できることも挙げられるでしょう。これを利用することで、テーブル自体はそのまま残すとしても、一定期間が過ぎたパーティションを自動的に削除し、コストを最適化できます。
クラスタ化
クラスタ化はパーティションの中で、指定したカラムを基準にデータを整理することで、さらに効率的にデータを読み出せる機能です。
これも良い図があったので拝借。

パーティションの場合、1つのカラムまでしか指定できませんが、クラスタ化テーブルでは、複数のカラムを指定できます。複数のカラムを指定する場合には、ソートの順番が反映されるため、同じカラム群でクラスタ化を行うにせよ、どのような順番でクラスタ化を行うかは1つの設計ポイントとなります。
DMLで大幅にクラスタ化されたカラムのデータが更新されると。このクラスタ化されたカラムのデータがバラバラになってしまいます。BigQueryではこれを、バックグラウンドで自動的に最適化する処理を定期的に行っています。
クエリエディタ右下にスキャン量が表示されます。この値は、パーティション分割の恩恵を受けて削減された、実際にスキャンされるデータ量と一致します。一方クラスタ化テーブルの場合、ここに表示されるサイズはパーティション分割テーブルの恩恵だけです。
(中略)
クラスタ化テーブルを利用する場合、少なくともこの--dry-runの値よりもスキャンは少なくなる、と覚えておけばよいでしょう。
マテリアライズドビューの利用
(1)自動更新(フリークエンシーキャップ、デフォルト30分)
(2)行の挿入は5分程度で反映(自動更新)
(3)自動更新/自動増分更新後に未反映のINSERT、ロード、ストリーミングインサートの追加データがある場合、クエリ時に増分のみベーステーブルから取得
(4)パーティションに対する操作があった場合には、マテリアライズドビューの該当パーティションのデータを無効化
要は、マテビューから取得できる分は取得し、ベーステーブルまで取りに行かないといけないデータはBigQueryが自動で判定しクエリコストを最適化する。
バックアップとリストア
タイムトラベル機能
機能的にはタイムトラベルしかない。通常であればバックアップが7日間というのは心許ないので、最後者に記載した別テーブル化かGCSエクスポートが必要。
タイムトラベル機能とは、BigQueryのあるテーブルを最大7日間まで(テーブル削除の場合は2日)任意のタイムスタンプの時間帯の状態に戻せる機能です。
テーブルへのリストアはCTASを使う方法と、上記のクエリ結果を別テーブルとして保存し、復旧対象テーブルの該当するデータDELETEしてからINSERTする方法があります。前者はタイムトラベルに必要なテーブルメタデータが一度消去されるため、それ以前のタイムトラベルができなくなってしまいます。そのため、本番環境で行う場合には後者のほうがよいでしょう。
長期にわたるテーブルバックアップなどについては、先に利用したタイムトラベルを利用して別テーブルとして定期保管するか、その結果をCloud Storageにエクスポートしておきましょう。
BigQueryにおけるトランザクションとパーティションを用いたDMLの最適化(とデータマート作成のベストプラクティス)
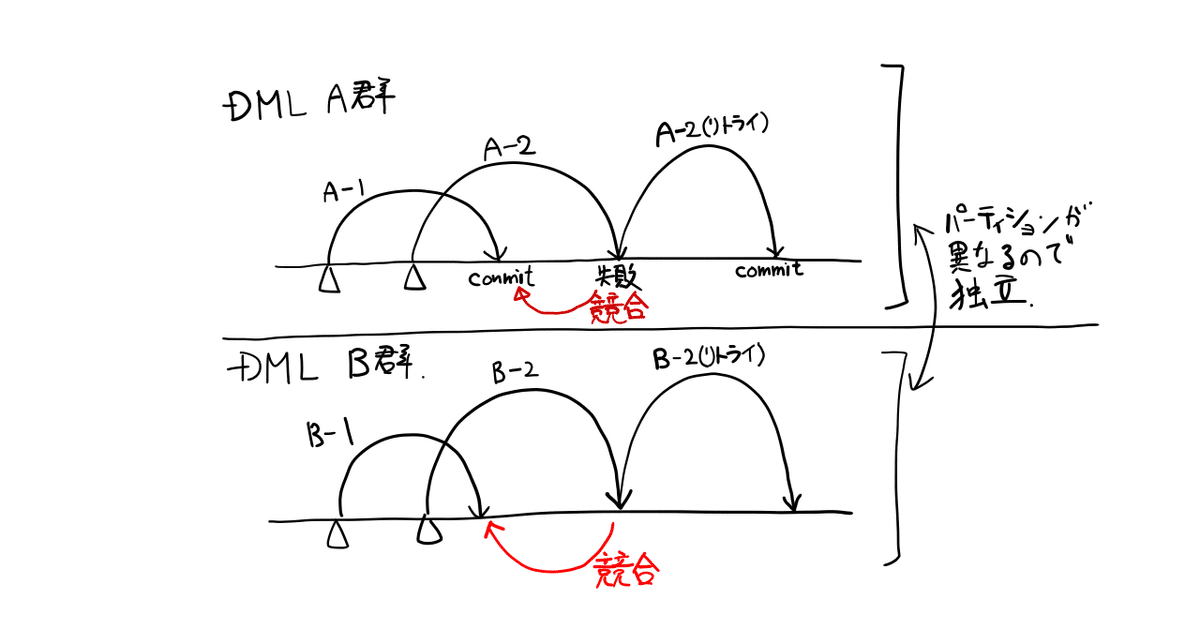
パーティションが違うDML Aの2つとBの2つはそれぞれ競合しません。

図はBigQueryにおけるデータマート作成の反映におけるベストプラクティスです。
DMLをまとめる/パーティションの利用
BigQueryはOLAP(Online Analytical Processing - 分析処理。反対にOnline Transaction Processing - トランザクション処理があり、一般的なアプリケーションにはOLTPが用いられることが多い)用途のデータベースです。
(中略)
変更DML(UPDATE、DELETE、MERGE)には無視できないオーバーヘッドがあります。一方、追記は得意なため、INSERTのオーバーヘッドは大きくありません。
変更DMLに対する最適化方法
以下の2つの最適化方法があります。
1. DMLをパーティション内でできるだけ大きなジョブとしてまとめる
2. データマートは更新ではなく洗い替えで実績データから処理をする:(中略)BigQueryの環境であれば、中間テーブルを気軽に作って破棄することもできるので、データマートを生成する際に1つのテーブルで多くの更新をするよりも、中間テーブルを次々にCTASで作成していくほうが相性は良いと言えるでしょう。
外部接続の最適化 - Storage API の利用と BI Engine の利用
Storage APIと呼ばれる、RPC経由でパラレルにデータを読み出すことにより高速にネイティブストレージからデータを読み出すAPIが備わっています。これはPythonライブラリであるpandas_gbqやgoogle-cloud-bigqueryなどを通して利用できるほか、Spark/Hadoopを利用してBigQueryのデータを読み出すためのBigQueryコネクタ、ODBC/JDBCドライバで利用できます。データ量が多い場合にはStorage APIを利用することで、スループットを最大化できます。
データマートジョブの設計最適化
先に説明された「DMLをまとめる/パーティションの利用」について具体的なユースケースで説明。
BIgQueryは差分更新ではなく「洗い替え」を行うことでパフォーマンスを最適化できます。設計の一例としては以下が挙げられます。
sales_recordsテーブル
・パーティション分割をsales_dateに設定し、売り上げ日ごとにスキャン可能にする
daily_sales_summaryテーブル
・パーティションをsales_dateに設定することで、BIツールからのフィルタリングに高速に対応する
・クラスタリングをstore_id, product_idに設定することで、フィルタリングに高速に対応する
・更新の際には、パーティション単位で洗い替えを行う
- daily_sales_summaryの該当日をWHERE指定しDELETEする
- sales_recordsテーブルから同日売り上げすべてのレコードをSELECTし再集計し、INSERTする
- 更新中の値を見せたくない場合は一時テーブルを挟んで上記の処理を行ってから、最後にCREATE OR REPLACE TABLE ... AS SELECT ... を実行することでdaily_amunt_soldデータマートを一括更新する
もしもより短い感覚でアップデートが必要な場合には、変更レコードを追記していくジャーナルテーブルを作成し、UNIONと分析関数であるrow_number()を利用して差分を格納したテーブルと現在のデータマートをMERGEすることもできます。メルカリ社のブログで詳細な方法が紹介されていますので、興味がある方はそちらも確認してください。