
筑波大学オープンコースウェア(OCW)の機械学習の"note"をとった - 機械学習概論と単回帰(2)

用語メモ
平均二乗誤差
一つのデータに対する Error(誤差) は、
𝑡𝑖 が実測値。𝑤𝑥+𝑏 が予測式そのものなので予測値。
データがN点あり、計算処理のしやすさも考慮して絶対値で無く二乗値の平均誤差を求める。
これが平均二乗誤差。
この誤差を最小にする𝑤 と𝑏 を取るモデルが最良と言える。
最急降下法
平均二乗誤差を最小にする𝑤 と𝑏 を求める数学的な手法。
詳細後述。
argmin
数学記号。以下で𝑓(𝑥) を最小にする 𝑥 を求めなさいという問題。
argmin がサポートされてないっぽいので画像で。
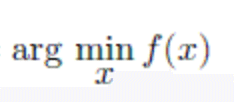
引用(講義ポイント)メモ
最急降下法の考え方。
前提
・関数𝑓(𝑥) は微分可能
・関数𝑓(𝑥) は凸関数

演習問題解説。


これは単回帰の場合で変数が一つなので非常に単純。実際の機械学習では変数を複数扱うので、ベクトルでの微分となる。
機械学習で扱う特徴量は全て数値ベクトルの形を取るが、実際に取得可能なデータ全てが数値の形になっているわけではない。
大まかにデータは3種類の形を取る。
・スカラ・・・スカラ・ベクトルで表される属性。要は元々数字のもの。年齢や収入、気温など
・順序属性・・・順序関係を持つ属性。数値ではないけどなにかしらの順序関係を持つもの。成績評価のA,B,C,Dなど
・カテゴリカル属性・・・順序関係も持たず数値でもない離散的な値を持つ属性。血液型とかグルーピングとか
機械学習で扱うには順序属性もカテゴリカル属性も数値属性に変換する必要がある。
順序属性は順序性を維持したままスカラ値(数値)に変換すればOK。
例えば、
A => 5, B => 4, C => 3, D => 2 など
カテゴリカル属性はよくあるのは 1-of-k変換(one-hot encoding) で表現する。
例えば血液型の場合は4種類あるので、2次元(2の二乗)ベクトルで表現する。
A => (0,0), B => (0,1), => O => (1,0), AB => (1,1)
属性値がN種類ある場合は 𝑘=log2𝑁
機械学習の性能評価のために使うデータに Adultデータ というものがある。
5万人弱の個人の様々な属性データが蓄積されており、その個人が年収5万ドルを超えるかどうか予測する。
実際に機械学習に取り組む前にデータをヒストグラムなりなんなりで可視化して見て欲しい。
例えば Capital Gain, Capital Loss というデータは非常にばらつき(偏り)が大きく、全体としての予測率を上げたい場合にはあまり役に立たないかもしれないと考えることができる。
理由は、一部の人を覗きほとんどが同じ属性を持っているため、その属性のせいで一部の人の予測精度が影響を受けたとしても大部分の人の予測精度は変わらないと予想できるから。
このように、自分が相手にしようとしているデータがどういう物なのかを把握することが重要。
この記事が気に入ったらサポートをしてみませんか?