Mac内のローカルで電子カルテ解析できますか? 〜日本語LLM(Swallow)を使ってみた〜

東工大と産総研の研究チームが発表した日本語機能拡張済み「Swallow」を使ってカルテ内容の要約や質問をしてみました。(「Swallow」は米国Meta社が開発した大規模言語モデルLlama 2をチューンしたものです。)
企業や研究期間では企業内データ、病院では患者データをChatGPTのようなLLMにデータを渡すこと無く、LLMを使ってみたいという要望があります。
解決策として、自前でサーバを用意する・Azure OpenAIのようなクラウドサービスを使うというものがあります。
どちらも個人で気軽に使いにくいため、MacでオフラインでLLM「Swallow」が使えるのかについて試してみました。
1.Swallow「日本語LLM」とは?
こちらのニュースを見てもらうのが良いと思いますが、Meta社のLlama2をチューンした日本語に強いLLMです。7B・70B・130Bと学習データの大きさによりいくつかバージョンがあるのですが、70Bという大きなモデルがローカルマシンで動くのかを試してみました。
この秋に非常に高価なMacbook Pro16を購入した理由の一つにローカルでのLLM開発環境というのがありましたので、やっとMacbook Proの真価が試せるときが来ました。
ちなみにRAM 96GBというモデルになります。(さすがに100万円超のモデルは躊躇してしまいましたw。)
2.MacでのローカルLLM動作環境
本気でLLMをローカルで動かすには研究用のサーバで環境を構築すれば良いのですが、まずは自分のMacbookでいろいろ試してみたいという希望があります。そのための環境として最適なのは、LM Studioです。こちらはGitHubなどで配布されている「gguf」ファイルをダウンロードして、ローカルマシン上で動かす事が出来ます。

Macで動くggufと動かないggufがあるので、いろいろダウンロードして試しています。ggufによっては、これはMacで動かないので、○○バージョンを使ってねとGitHubのRead meに記載してくれているものもあります。
3.Swallow 70Bのダウンロード
今回「swallow-70b-instruct.04_K_M-gguf(41.55GB)」というものをダウンロードしてみました。結構な容量なので、SSDに余裕がない方は難しいです。(その場合は、Macの容量を整理するか、7Bのモデルを試してみてください。)さらに誰でも試せないのはLM Studioの設定でモデルをRAM上に展開しておく、という設定にチェックを入れるには巨大なRAMが必要になります。素早く動くためには必要なことかと思っています。
LM Studioの検索窓で「Swallow」と入力して検索するだけで複数のモデルがリストアップされます。
4.LM Studioの設定
今回はLM Studioの使い方がメインではありませんので、詳細は記載しませんが、右側のカラムでLM Studioの動かし方をカスタマイズ出来ます。
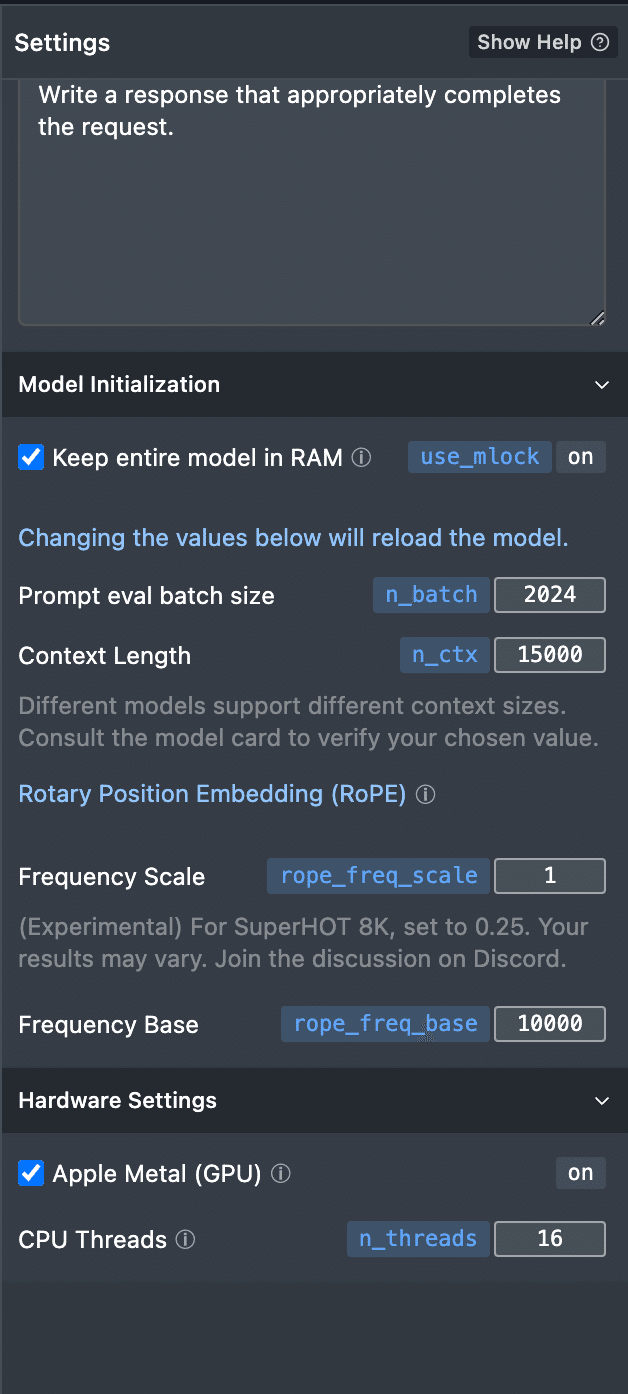
1)「Keep entire model in RAM」にチェックを入れる
RAM上にモデルを展開することでスピードを上げます。(多分上がると思っています。)
2)「Prompt eval batch size」の値を変更
一度にLLMに渡すデータのサイズを決定します。自分のPCのメモリサイズと相談してこの値を変更しておきます。まずはデフォルトのままでも良いのかもしれません。
3)「Context Length」の値を変更
デフォルトでは1500トークン(日本語だと1文字で2〜3トークンだとすると、500文字くらい?)になっています。長い文章をLLMに渡したいとすると、この値を大きくすることでより長い文章を解析してもらう事ができます。15000ってすごい大きいのですが、私のMacbook Proはこんなサイズでも動くようです。(ggufの再起動が必要なのですが、やや時間がかかります。)
4)「Apple Metal (GPU) 」にチェックを入れる
ここにチェックを入れないとCPUだけで解析する事になりますので、LLMのような並列処理が必要な解析はとても時間がかかるようになってしまいます。M1以上だったらチェックを入れておくべきかと思います。
5)「CPU threads」
これは変えなくても良いのかどうか?大きい方が良いかと思うのですが、最良設定については私も分かりません。
5.LLMモデルの読み込み
70Bのggufが読み込めるか不安でしたが、初回は5分くらいかかって読み込めました。バージョンによって起動しないモデルもあるのですが、起動もしてくれて動きました!

6.電子カルテデータ
医師国家試験の問題でも良かったと思うのですが、google検索で医学書院に「救急特有の流れに沿った4段階カルテ記載法(佐藤健太)」というページからカルテの内容を拝借させていただきました。こちらのスクショをMac OSの昨日であるOCRでテキストを抽出してLLMのプロンプトに投げ込みました。
7.SwallowとのChat内容は?
まずは「学習してください」としてカルテのコピペをしてみました。
次に「採血の異常値」について聞いてみましたが、救急外来のカルテなので採血結果はまだ出ておらず、正常値を教えてくれました。
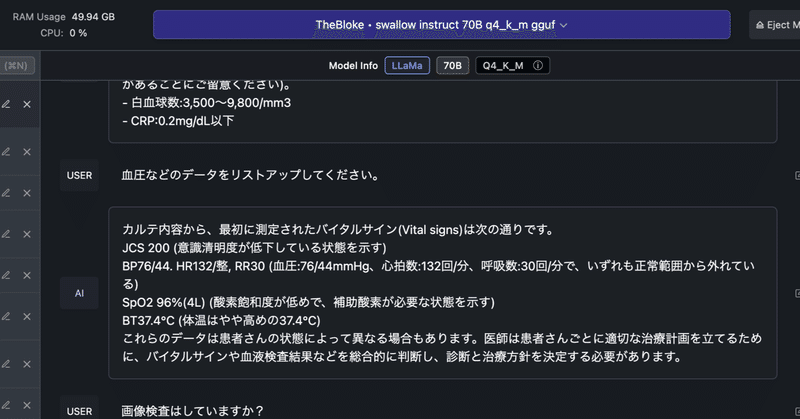
そして、「血圧などのデータ」という言い方で身体所見について聞いてみました。下の図にあるように結構良い返信をしてくれます。

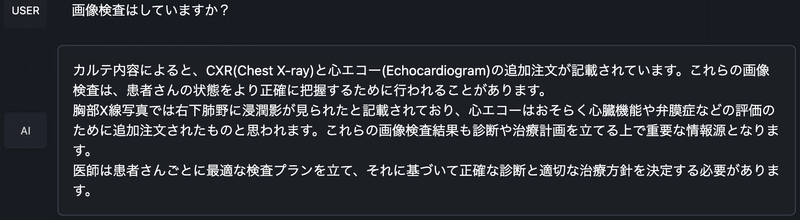
「画像検査をしているのか?」について聞いてみると、CXRという単語を胸部単純X線写真であることを理解してくれて、肺炎像が認められていると言うことを教えてくれます。
まとめ
研究用サーバにSwallowを展開しようとすると結構時間がかかると思うのですが、自分の(しかも年末で自宅に待機中)Macbook Pro上で70BのLLMが動くことに感動します。
この記事が気に入ったらサポートをしてみませんか?