
AIイラストをコントロールできるControlNetの網羅解説|Stable Diffusion

※ 2024/1/14更新
この記事は、「プロンプトだけで画像生成していた人」が「運任せではなくAIイラストをコントロールして作れるようになる」という内容です。漫画や同人制作に必要なControlNet技術の基本が身に付きます。SDXL編と合わせて学んでください。
初心者の方は、こちらの動画版へ。より詳しく、分かりやすく解説しています。noteだと無料視聴できます。
■ ControlNetとは?何ができる? ■
■ ControlNetとは

ControlNetとは、画像生成AIを、よりコントロール可能にする画期的な機能です。似た顔や特定のポーズ表現などを、ある程度は思い通りにでき、AIイラストを作ることができます。
■ 何ができる?具体例を紹介
✓ イラストを維持したまま、色だけ変える


✓ 落書きから画像を生成する




✓ キャラクターに特定のポーズをとらせる


✓ キャラクターの顔を維持したまま、別の画像を生成する


✓ 画像をプロンプトとして使用する


✓ イラストを維持したまま、画像を拡大する




などができます。
テキストから高品質な絵が作れるようになったのが、第1の革命なら、ControlNetでAI絵をコントロールできるようになったのは、第2の革命です。
・第1の革命:テキストから高品質な絵の生成
・第2の革命:AI絵のコントロール
■ この記事の使い方 ■
この記事では、ControlNetの解説をします。
特に、以下のControlNet機能は便利なので、優先的に学んでください。
・IP-Adapter
・Tile
・OpenPose
Stable Diffusion初心者の方は、始め方編と使い方編を先に学んでください。
講義の内容は、以下のとおりです。学ぶ順番の参考にしてください。
✓ 1.ControlNetの始め方
✓ 2.線画の維持ができるCanny機能を学びつつ、ControlNetの設定の解説
✓ 3.似たキャラクターを作れる、ReferenceやIP-Adapterと、その応用方法の紹介。
✓ 4.元画像を維持しつつ画像拡大する方法の解説(Tile)
✓ 5.特定のポーズ表現の解説(OpenPose)
✓ 6.その他のControlNet機能の解説
便利そうな機能があれば、実際に試しながら学んでください。
■ ControlNetの始め方・インストール方法 ■
■ ローカル環境の方はこちら
□ ControlNetのインストール方法

GitHubのControlNetの開発者のページに行き、「Code」をクリック → URLをコピーしてください。

コピーしたURLを、画像の位置に貼り付けて、インストールボタンをクリックしてください。


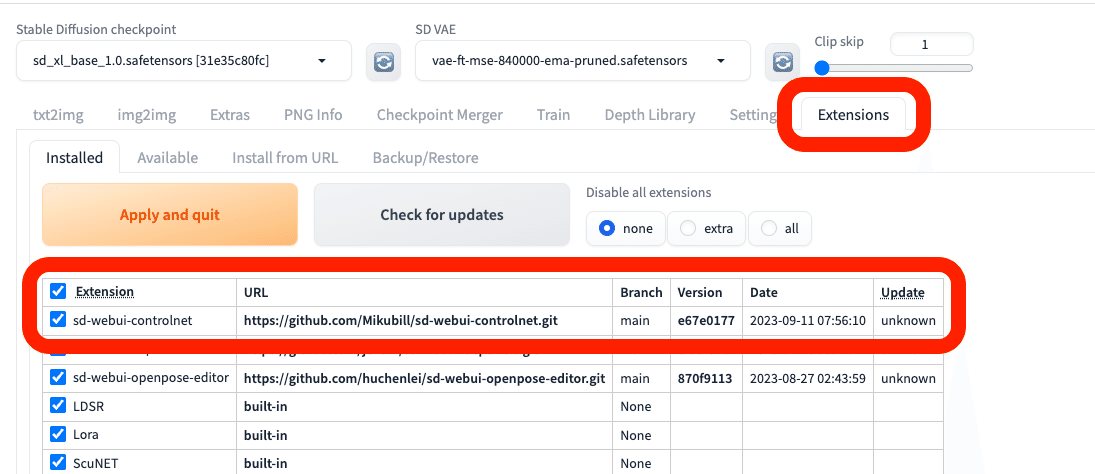
「Installed」に移り、「Apply and quit」をクリックしてください。Stable Diffusionは停止するので、再起動してください。

これで、ControlNet環境のインストールは完了です。ControlNetの欄が、追加されます。
□ ControlNet用のモデルをインストールする
モデル(チェックポイント)と同じように、ControlNetにも専用のモデルが必要です。

ControlNetの開発者のページに、必要なモデルをダウンロードできるサイトが紹介されています。
ControlNetモデルを入手できるサイトは、似ているサイトが多いです。他サイトでは、データが古かったりするので気をつけてください。
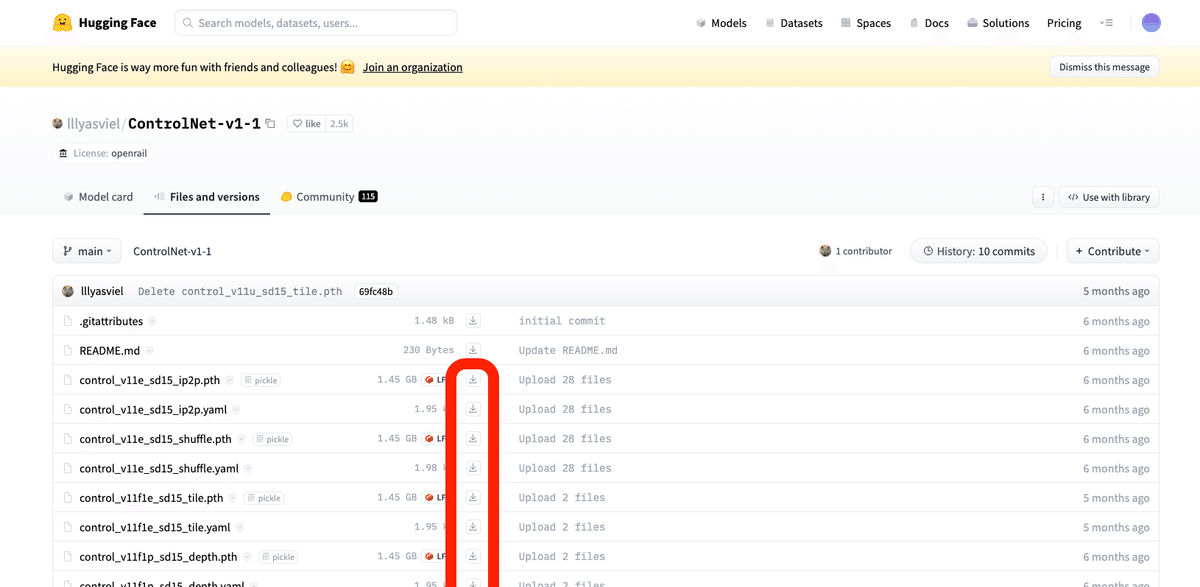

「pth」ファイルを全てダウンロードしてください。
容量が大きいので、有名なものだけを使いたい方は、
・OpenPose
・Tile
・IP-Adapter
をダウンロードしてください。これらはよく使います。

SDXL系のチェックポイントを使う場合は、こちらのサイトからControlNetモデルをダウンロードしてください。(現時点では、SD1.5版のControlNetの方が効果が反映されやすいので、SD1.5の使用をオススメします。)
ダウンロードするファイルは、拡張子が以下のものです。
・safetensors
・pth
SDXL用のControlNetモデルは、種類が色々あり、どれを選んだら良いか初心者には分かりづらいと思います。以下が有名でよく使われるので、オススメです。(容量に余裕がある方は、全てインストールして使ってください。)
・ip-adapter_xl.pth(SDXL用のIP-Adapter)
・kohya_controllllite_xl_blur.safetensors(SDXL用のTile/Blur)
SD1.5用のControlNetは、llyasvielさんが多くを開発しましたが、SDXL用のControlNetは色々な開発者が開発したものが公開されています。SDXLで他のControlNetも使いたい方は、他の開発者のControlNetモデルを使う必要があります。
smallなど軽量版もありますが、容量がキツキツじゃなければ、fullをインストールしてください。
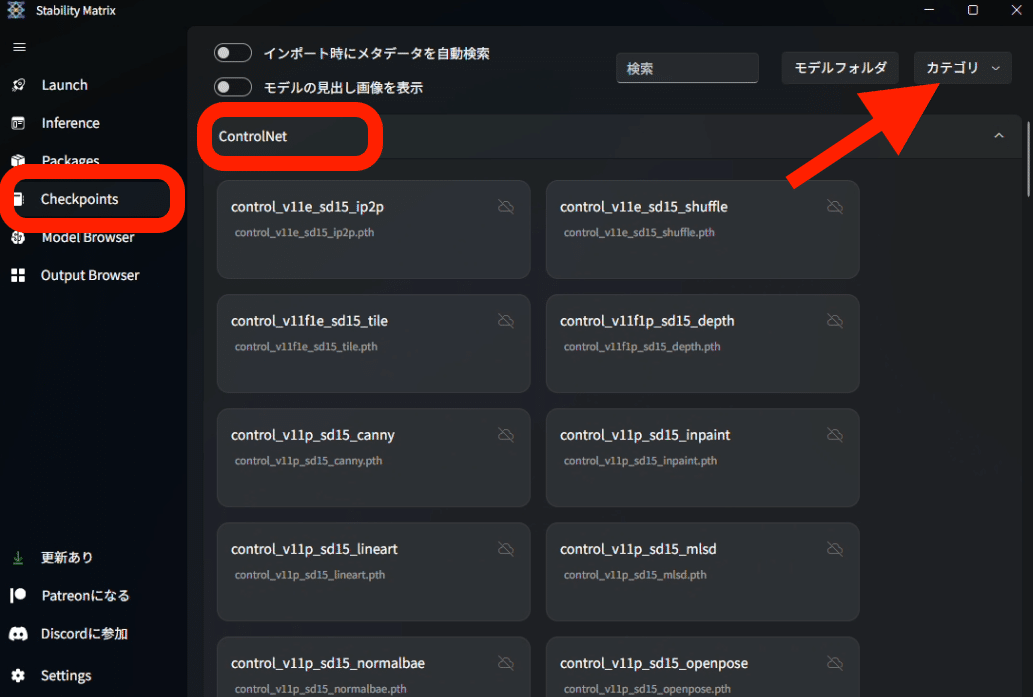
保存する場所は、StabilityMatrixの左側でCheckpointsを開き、ControlNetのところにドロップしてください。ControlNetがない場合は、カテゴリからControlNetにチェックしてください。

あるいは、StabilityMatrix → Data → Models → ControlNet に保存してください。
StabilityMatrixを使っていない方は、 stable-diffusion-webui → extensions →sd-webui-controlnet → models に保存してください。
後は再起動するだけで、インストール完了です。
■ Colab環境の方はこちら(Googleドライブと連携しない方)
こちらを使っている方は、

ControlNetの欄にチェックを入れるだけで大丈夫です。ControlNetモデルのインストールは、自動で行われます。
■ Colab環境の方はこちら(Googleドライブと連携)
TheLastBenさんが開発した「Googleドライブと連携したColab版」では、ControlNetは初めからインストールされているので、ControlNet環境のインストールは不要です。
インストールされていない方も居るかもしれないので、やり方は一応書いておきます。
GitHubのControlNetの開発者のページに行き、「Code」をクリック → URLをコピーしてください。
コピーしたURLを、画像の位置に貼り付けて、インストールボタンをクリックしてください。
「Installed」に移り、「Apply and quit」をクリックしてください。Stable Diffusionは停止するので、再起動してください。
これで、ControlNet環境のインストールは完了です。ControlNetの欄が、追加されます。
□ ControlNet用のモデルをインストールする
モデル(チェックポイント)と同じように、ControlNetにも専用のモデルが必要です。
ControlNetの開発者のページに、必要なモデルをダウンロードできるサイトが紹介されています。ControlNetモデルを入手できるサイトは、似ているサイトが他にもあります。データが古かったりするので、気をつけてください。
SD1.5のチェックポイントを使う場合は、こちらのサイトからControlNetモデルをダウンロードします。IP-Adapterのみ、SDXL用のサイトにあります。
ダウンロードするファイルは、拡張子が「pth」のものです。yamlファイルは、不要になりました。
容量が大きいので、有名なものだけを使いたい方は、
・OpenPose
・Tile
・IP-Adapter
をダウンロードしてください。
SDXL系のチェックポイントを使う場合は、こちらのサイトからControlNetモデルをダウンロードしてください。(現時点では、SD1.5版のControlNetの方がオススメです)
ダウンロードするファイルは、拡張子が以下のものです。
・safetensors
・pth
SDXL用のControlNetモデルは、種類が色々あり、どれを選んだら良いか初心者には分かりづらいと思います。以下が有名でよく使われるので、オススメです。(容量に余裕がある方は、全てインストールして使ってください。)
・ip-adapter_xl.pth(SDXL用のIP-Adapter)
・kohya_controllllite_xl_blur.safetensors(SDXL用のTile/Blur)
SD1.5用のControlNetは、llyasvielさんが多くを開発しましたが、SDXL用のControlNetは色々な開発者が開発したものが公開されています。SDXLで他のControlNetも使いたい方は、他の開発者のControlNetモデルを使う必要があります。
smallなど軽量版もありますが、容量がキツキツじゃなければ、fullをインストールしてください。

保存する場所は、sd → stable-diffusion-webui → extensions →sd-webui-controlnet → models です。チェックポイントを保存する場所とは違うので、注意してください。
後は再起動するだけで、インストール完了です。
■ ControlNetの使い方一覧 ■
■ 基本設定
ここでは、元画像の線画を維持できるCanny機能を使いつつ、ControlNetの基本設定を学びます。
□ Enable
Enableは、ControlNetのオン/オフを切り替えるところです。ControlNetを使うときは、忘れずにチェックしてください。チェックをしているときだけ、ControlNetが有効になります。
□ Low VRAM
GPUのVRAMが不足している場合に、チェックを入れると、エラーが解消されることがあります。基本は、チェックしなくて大丈夫です。
□ Pixel Perfect
Pixel Perfectについては、よく分かりません。
Pixel Perfectは、ControlNetが自動的に最適なPreprocessor解像度にしてくれる機能です。オンにすることが推奨されているので、ControlNetを使うときは、毎回チェックを入れてください。
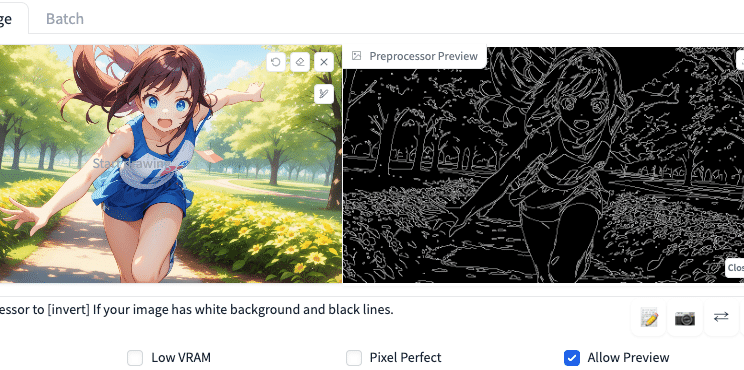
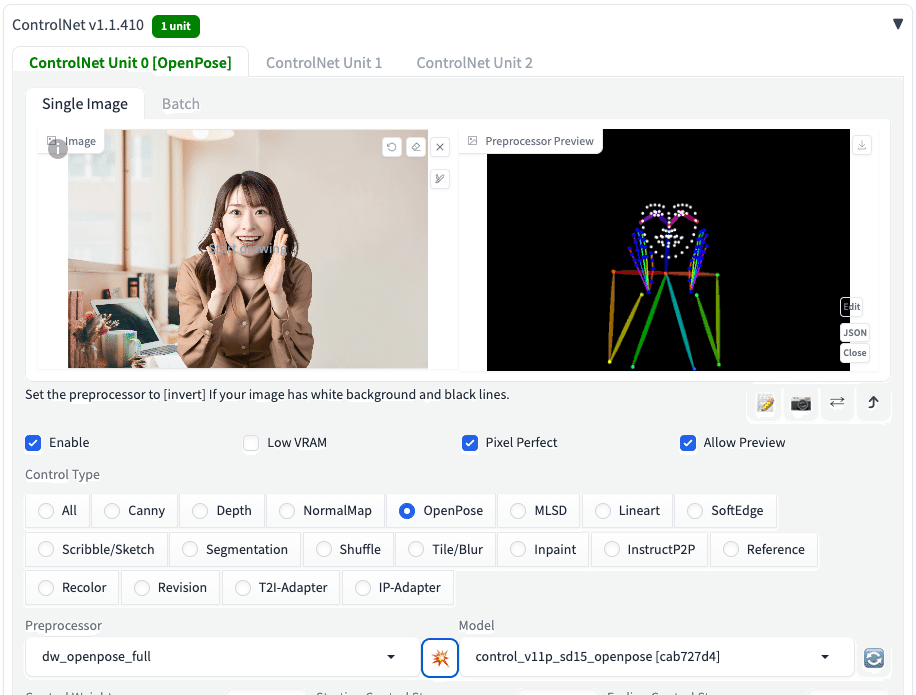
□ Allow Preview
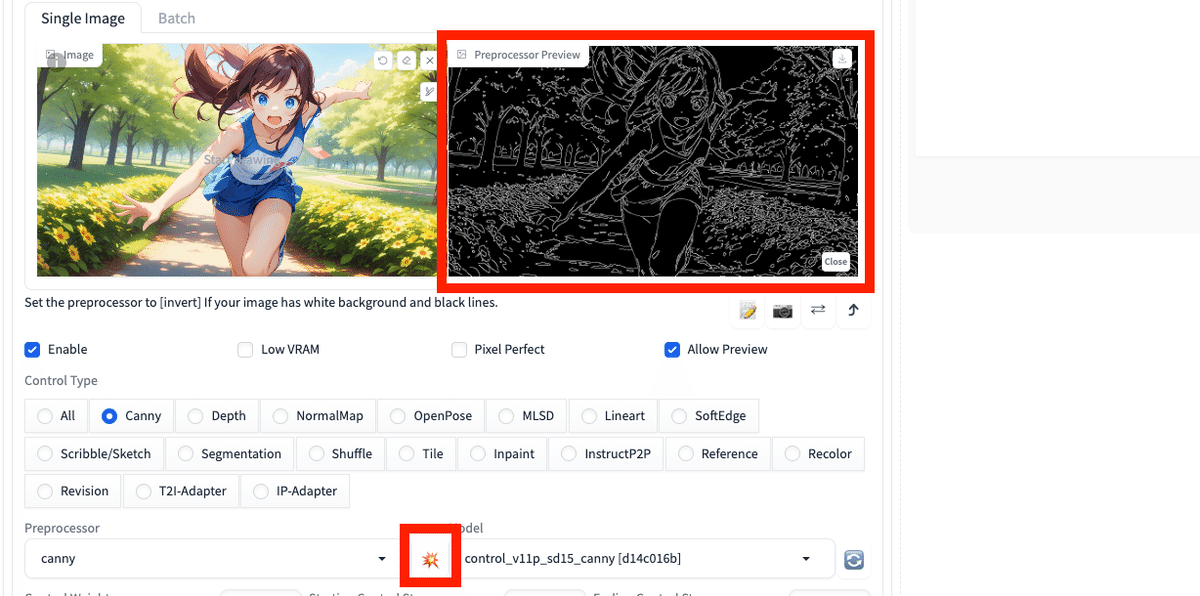
Allow Previewは、Preprocessorのプレビュー画像を表示する機能です。爆発マークのアイコンとセットで使います。この爆発アイコンをクリックすることで、Preprocessorのプレビュー画像が表示されます。
今回のCannyの場合、プレビュー画像とは、左の元画像から抽出された、右の白黒画像のことです。
こちらは、基本はオフで大丈夫です。後で説明しますが、ControlNetがどういう処理をするのか、確認したいときに使います。
□ Control Type
これから詳しく説明していきますが、Control Typeを選択すると、Preprocessorとモデルを自動で設定してくれます。
モデルがインストール済みでないと設定が反映されないので、事前にモデルはインストールしておいてください。
□ Preprocessor
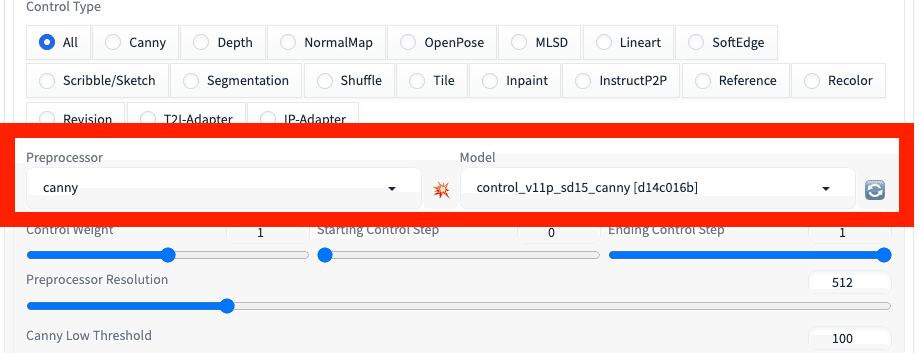
ControlNetは、元画像からキャラクターのポーズなどをコピーできる機能ですが、Preprocessorはその処理をするための「準備(下ごしらえ)」をするところです。
Preprocessorは、元画像の特徴を抽出して、ControlNetのモデルが機能しやすいように前処理をします。
Preprocessorでされた前処理は、Allow Previewにチェックを入れて、爆発アイコンをクリックすると表示されます。元画像の右に表示されている白黒画像が、Preprocessorでされた処理です(PreprocessorがCannyの場合)。
□ Model(モデル)
ControlNetは、元画像からキャラクターのポーズなどをコピーできる機能です。そして、元画像からどんな特徴を抽出して、新たな画像を生成するのかを設定するところが、モデル欄です。
チェックポイントの方のモデルと似たようなものですが、ControlNet専用のモデルをインストールしておく必要があります。
また、モデルは、Preprocessorとセットで設定します。ControlNetで何をするのか設定するには、最初にPreprocessorとモデルを設定します。
■ ControlNet一覧と使い方 ■
これから実際にControlNetを使っていきます。
■ Canny
Cannyでは、元画像の輪郭を抽出し、その線画をもとに画像を生成することができます。普通は生成するたびに一貫性のないランダムな画像が生成されますが、Cannyを使うことで同じ輪郭線のまま別の画像が生成されます。
例えば、「絵はほとんど完成しているけど、色だけ変えたい場合」などに有効な機能です。
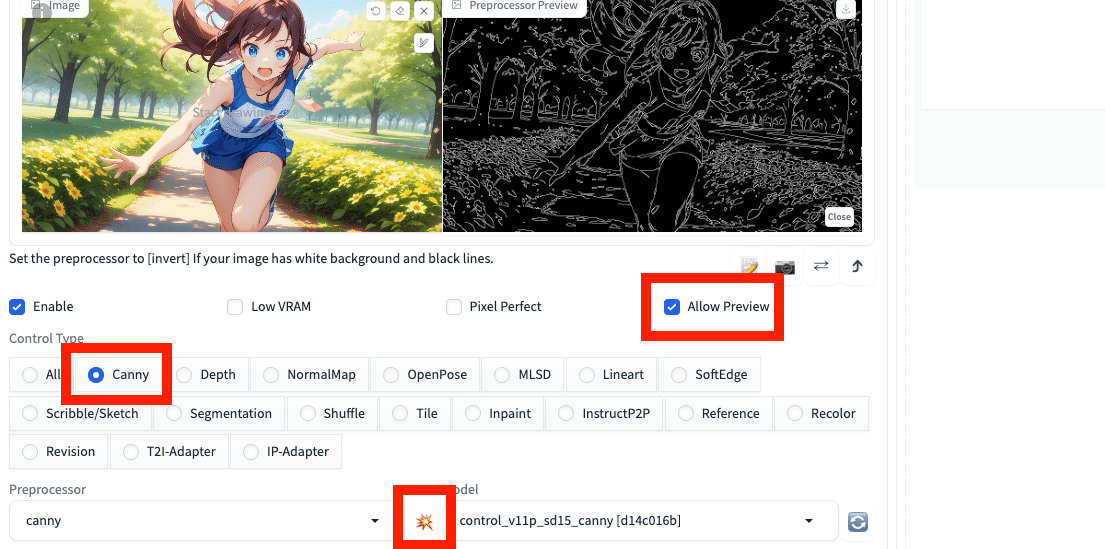
Cannyを使うときは、Control TypeでCannyを選択してください。
Allow Previewにチェックを入れて、爆発アイコンをクリックすると、Cannyで抽出された線画が表示されます。これは毎回表示する必要はないです。確認したい場合のみ、爆発アイコンをクリックしてください。


プロンプトなし
SD1.5
Cannyは線画情報のみを抽出するので、色情報は引き継がれません。そのため、Cannyは基本的にtxt2imgではなくimg2imgで使います。
後ほど解説する、Cannyと似ている機能の
・Lineart
・Softedge
も同じように、img2imgで使います。


プロンプト:girl, photoreal, park, Color Filters
ネガティブ:adult, makeup, nsfw, dyed hair, skirt
SDXL
txt2imgでは、元画像と同じプロンプトを使っても、こんな感じです。
img2imgで、Cannyを使ったのが以下です。

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
ちなみに、Seedは固定していません。Seed固定なしでも、ここまで元画像と似せることができます。
□ Control Weight
次に、ControlNetの効き具合を調整できる、パラメータについて説明します。
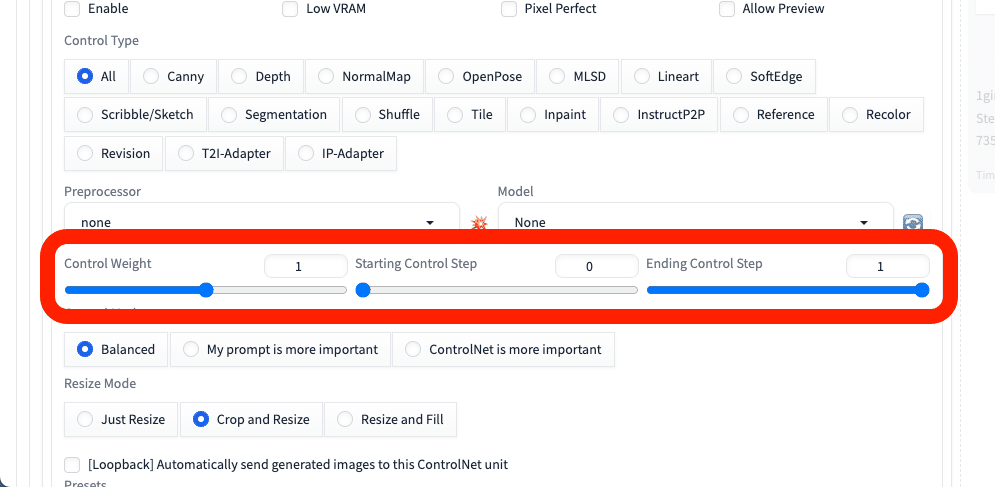
Control Weightは、ControlNetの影響力を調整するところです。値が大きいほど、元画像の特徴が反映されます。
プロンプトの強調と同じようなものだと思ってください。例えば「 (Prompt:1.2)」とすると、1.2倍だけ強調されます。



プロンプトなし

プロンプトなし
実際に生成した結果がこちらです。
プロンプトはそのままで、Control Weightだけ変えて生成しました。値が小さいほど、元画像から離れていることが分かります。
プロンプトなしでも、ここまで再現度が高くて、正直驚きます。
Cannyは線画情報のみを抽出するので、色情報は引き継がれません。そのため、Cannyはtxt2imgではなく、img2imgで使うのがおすすめです。

プロンプト:blond hair , blue eyes
色を変えるには、「カラフル」や「アニメカラー」などのプロンプトで全体の色指定をするか、髪色や服の色をプロンプトで個別で設定します。
ちなみに、線画の白黒画像が、白線に黒背景になっていて、人間が絵を描く場合と逆になっています。これはAIが、線画を白黒反転させた方が、読み取りしやすいかららしいです。
他の画像でも試しました。

プロンプトなし

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
□ Starting Control Step / Ending Control Step
こちらのパラメータは、ほとんど使わないので、軽く紹介します。
Starting Control Stepは、ControlNetが効き始めるタイミングを設定するところです。
ステップ数が20の場合、Starting Control Stepを0.5に設定すると、最初の10ステップはControlNetなしで生成されて、残りの10ステップがControlNetありで生成されます。
Control Weightと同じように、ControlNetの影響度合いを調整したいときに使ってください。
同様に、Ending Control Stepは、ControlNetが効き終わるタイミングを設定するところです。
ステップ数が20の場合、Ending Control Stepを0.5に設定すると、最初の10ステップはControlNetありで生成されて、残りの10ステップがControlNetなしで生成されます。
Control WeightやStarting Control Stepと同じように、ControlNetの影響度合いを調整したいときに使ってください。基本的に、Control Weightだけで事足りる場合が多いです。
□ Canny Low / High Threshold
こちらのパラメータも、ほとんど使わないので、軽く紹介します。

Cannyでは輪郭線が抽出されますが、輪郭線をどれくらい細かく抽出するか設定するところが、「Canny Low/High Threshold」です。
Canny Low/High Thresholdの値が小さいほど、より細い輪郭線まで抽出されるので、輪郭線は多くなります。逆に値が大きいほど、はっきりとした輪郭線のみが抽出されるので、輪郭線は少なくなります。
・Canny Low Threshold以下の値の輪郭線は無視される
・Canny High Threshold以上の値の輪郭線は反映される
・上2つの間の値は、無視されたり反映されたりする
らしいです。(参考)

Canny High Threshold : 200

Canny High Threshold : 200

プロンプトなし
生成した画像はこちらです。左の縦軸は、Canny Low Thresholdです。

Canny High Threshold : 110

Canny High Threshold : 250

プロンプトなし
生成した画像はこちらです。左の縦軸は、Canny High Thresholdです。
輪郭線が読み取られていない部分があるときは、Thresholdを低めに設定して、輪郭線をできるだけ読み取られるように設定してください。
もちろん、自分で線画を描いて追加しても大丈夫です。
使い分けとしては、
・元画像の線をたくさん残したいときは、Canny Low/High Thresholdを低めに
・元画像の線を減らしたいときは、Canny Low/High Thresholdを高めに
・AIに任せたいときは、Canny Low/High Thresholdの間隔を広めに
設定してください。
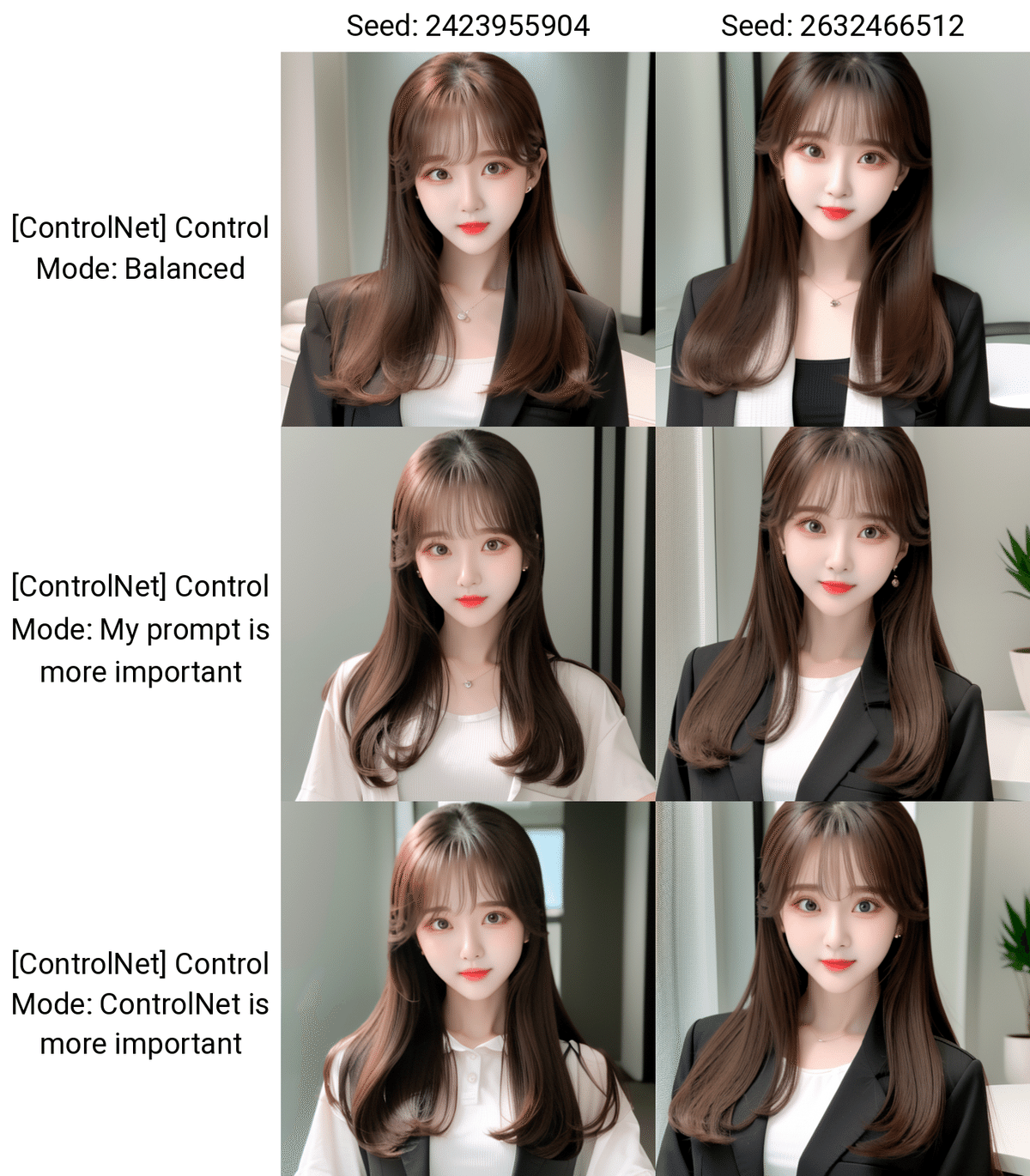
□ Control Mode
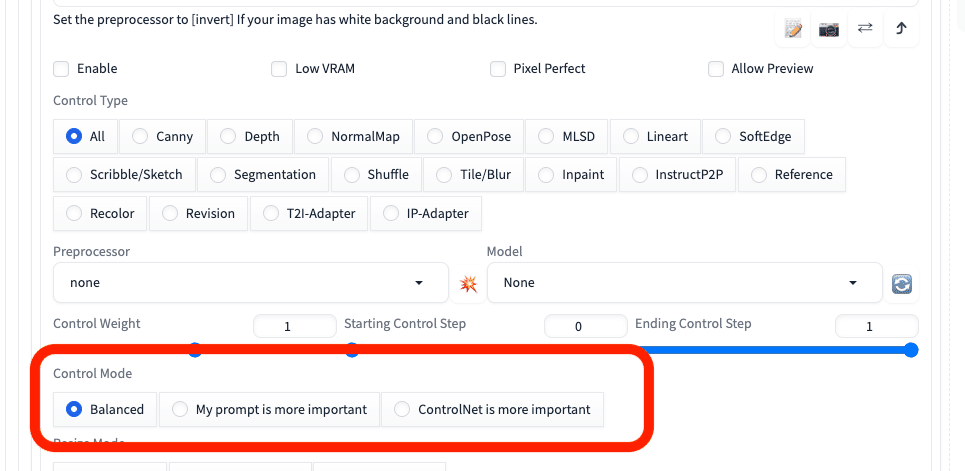
Control Modeは、プロンプトとControlNetのどちらを重視するか、設定するところです。
Balanced:名前の通り。バランスモード
My prompt is more important:ControlNet(元画像)よりもプロンプトが反映されやすくする
ControlNet is more important:ControlNet(元画像)に忠実にする
こちらも、Control Weightと同じように、ControlNetの影響度を調整するときに使います。こちらは、Weightと違い、3種類から選ぶだけなので楽です。基本的に、Balancedモードが1番うまく行っているので、初期設定のままで大丈夫です。
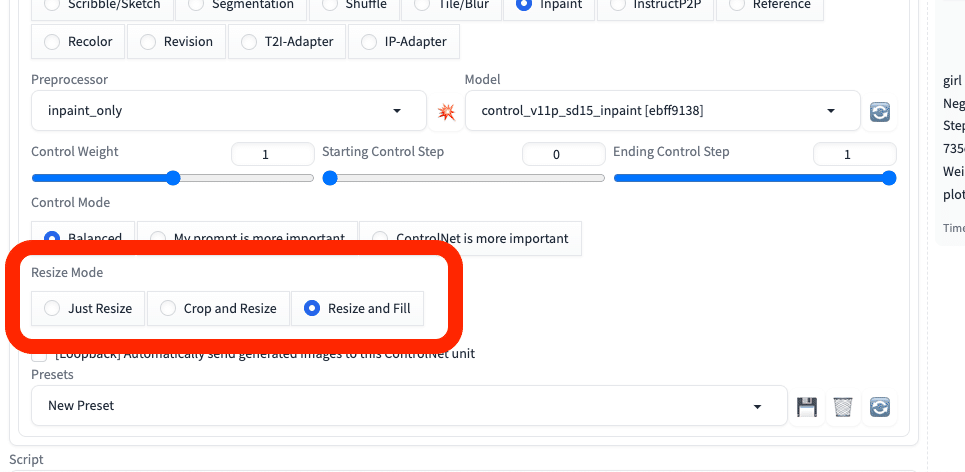
□ Resize Mode
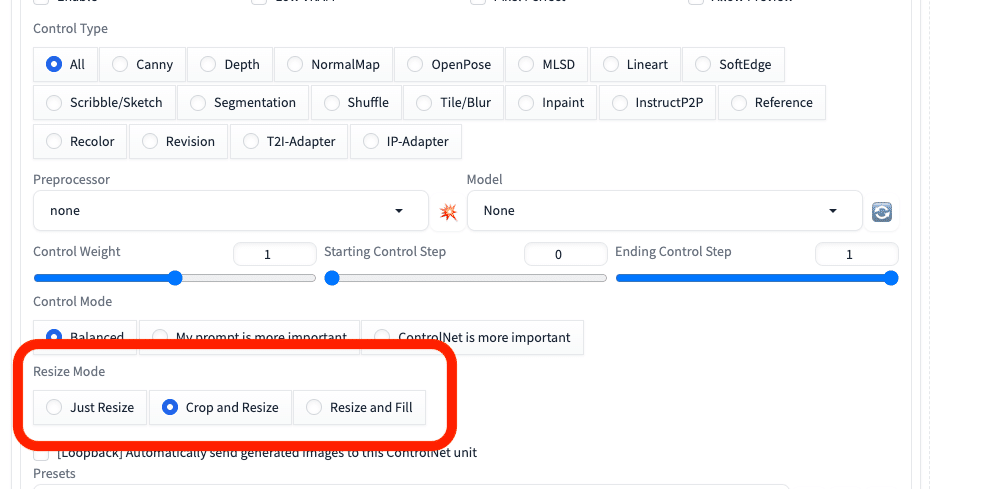
Resize Modeは、画像サイズを調整するところです。元画像と生成される画像のサイズが、異なるときに設定します。初期の「Crop and resize」で大丈夫です。
元画像と生成される画像のサイズが同じであれば、設定は不要です。
基本的に、元画像と
・同じサイズ
または
・同じ比率
になるように、画像サイズを設定してください。そうすれば、Resize Modeの設定は、どれを選んでも同じになります。

※画像の品質は、関係ありません。



Just resize – 元画像の縦横比を無視して、そのまま画像サイズを変更するので、歪むことがあります。
Crop and resize – 元画像の縦横比を保ったまま、画像サイズを変更します。このとき、はみ出した部分はカットされます。
Resize and fill – 元画像の縦横比を保ったまま、画像サイズを変更します。このとき、足りない部分はAIが補完してくれます。
□ Cannyの使い道
Cannyは、色だけ変えたいときに便利です。
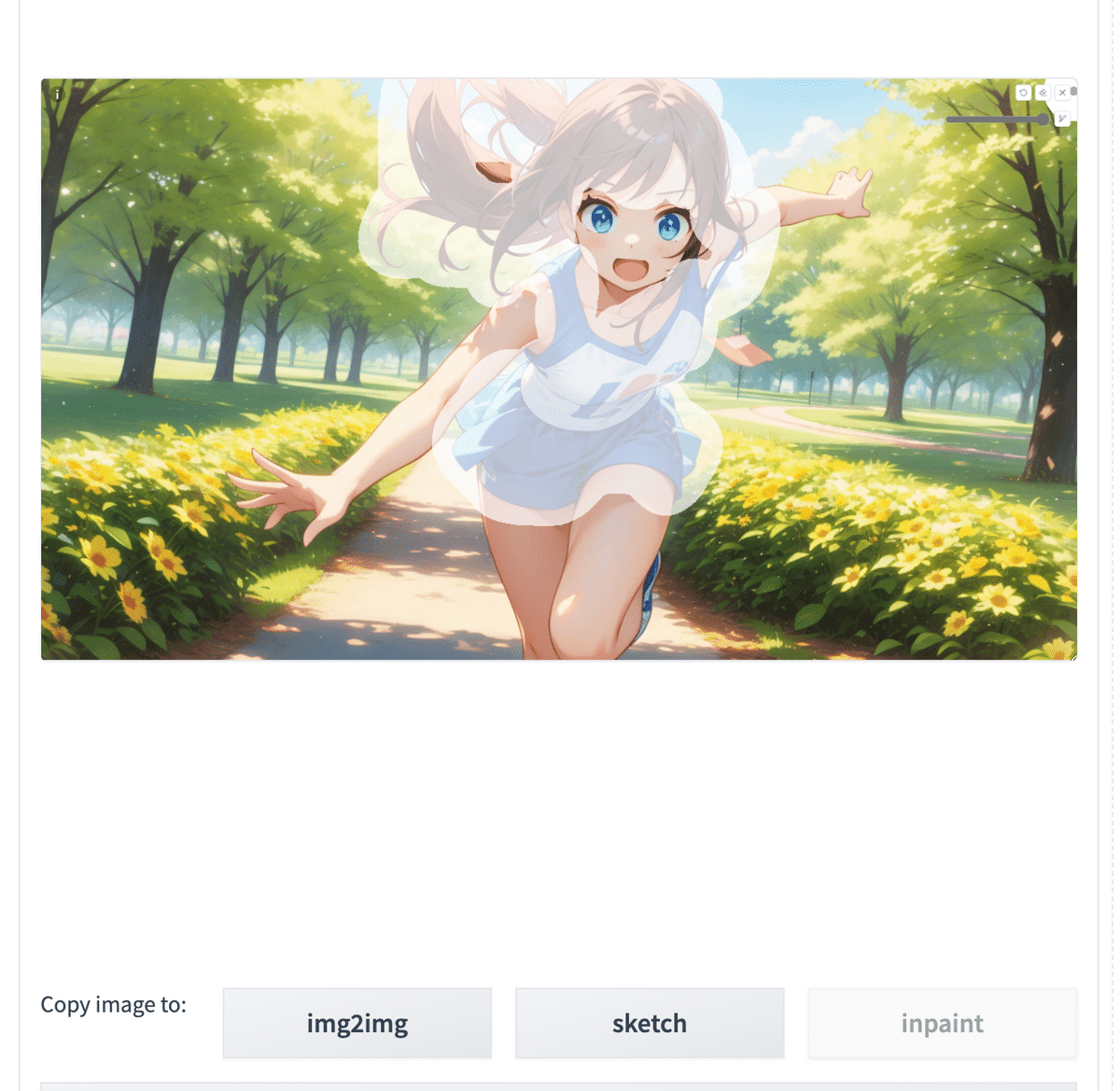

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii, blond hair, red dress
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii, blond hair, red dress
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
Cannyを使うと、線画をもとに画像を生成してくれるので、元画像の維持率がとても高いです。img2imgのみよりも正確に元画像を再現してくれます。輪郭を変えたくないときに、Cannyはおすすめです。ただし、色情報は引き継がれないので、基本的にimg2imgと併用して使ってください。
少し変わっていいならimg2img、ほぼ変えずに編集したいならControlNetとimg2imgの組み合わせを使ってください。また、少し変わっていいなら、Scribbleを使う方法もあります。Scribbleについては、後ほど解説します。
また、一部分だけを変えたい場合、他にもControlNet InpaintやIP-Adapterなどの方法があります。これについては後ほど or 別の動画講義で解説します。
■ Reference、IP-Adapter、Tileはこちら
・似たキャラクターを作れるReference/IP-Adapter
・元画像を維持しつつ画像の拡大ができるTile
は、上の記事で解説しています。
■ Lineart

Cannyと似た機能には
・Lineart
・SoftEdge
・Scribble
があります。今回は、Lineartの紹介をします。
Lineartでは、画像から線画を抽出し、それに基づき画像生成することができます。使い方はCannyと同じです。






プロンプトなし

プロンプトなし
Cannyと同じく、元画像の輪郭を精度よく保っているのが分かります。
img2imgと併用すると、Lineartでの大きな違いは見当たりません。
Lineartは、Cannyと比べると、線画が人間の絵に近いです。そのため、絵が描けて自分の線画を使いたい場合や、線画を修正したい場合は、CannyよりもLineartがおすすめです。線画を使う方法は、次で説明します。

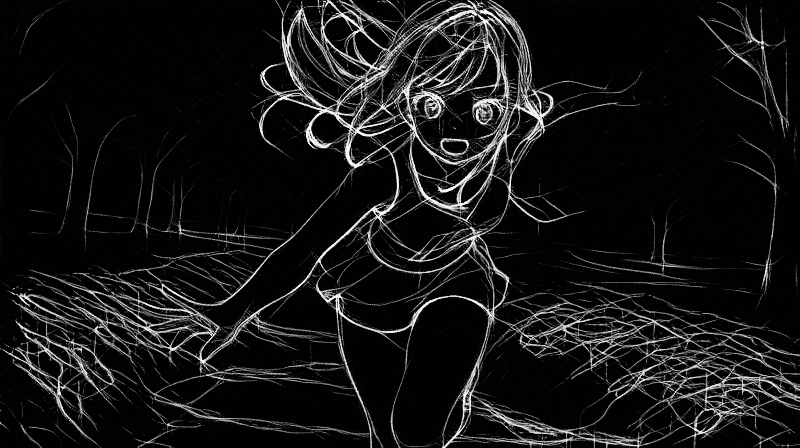




プロンプトなし

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
lineart_realisticが良いなと思いましたが、あまり違いはありません。好みで選んでください。
□ Control Weight(Lineart)

プロンプトなし
Weightの値を上げるほど、元画像の輪郭に近づくことが分かります。リアル系の画像をイラストっぽく仕上げるには、Weightの値を低めに設定するのがおすすめです。

プロンプトなし
□ lineartとlineart_animeの比較
Lineartにはモデルが2つあるので、その比較をしてみます。

プロンプト:1girl, long sleeves, looking at viewer, open mouth, smile, upper body
ネガティブ:low quality

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
何回か試してみましたが、モデルはLineartの方が良いです。lineart_animeモデルの良さは分かりませんでした。リアル系、イラスト系とわず、Lineartがおすすめです。
□ Lineartの使い道
Lineartの使い道は、Cannyと同じです。


どちらも、それなりに上手くいきました。ControlNetは、髪型と服装をほぼ変えなかったのに対し、img2imgはどうしても少し変わってしまいます。
少し変わっていいならimg2img、ほぼ変えずに編集したいならControlNetとimg2imgの組み合わせを使ってください。
また、線画が描ける方は、画像のように色塗りに使うことができます。
□ 自分で用意した線画をControlNetで使う方法

絵が描ける方は、自分で描いた線画を使うこともできます。
人間は白背景に黒い線で絵を描きますが、AIは黒背景に白い線で描いたものを絵として認識するみたいです。そのため、描いた絵は白黒を反転させる必要があります。
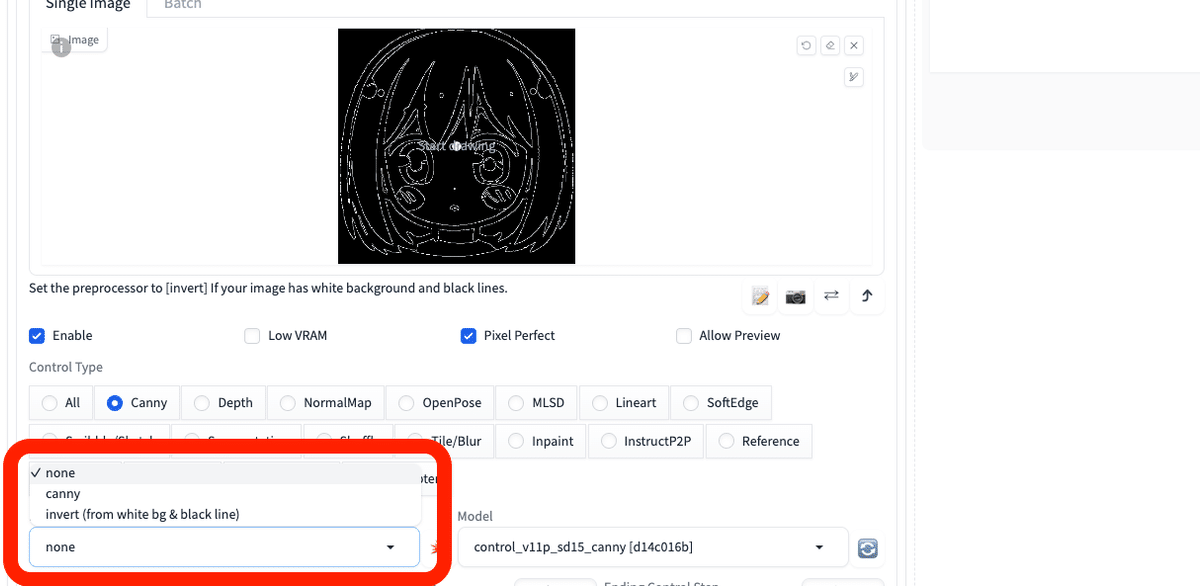
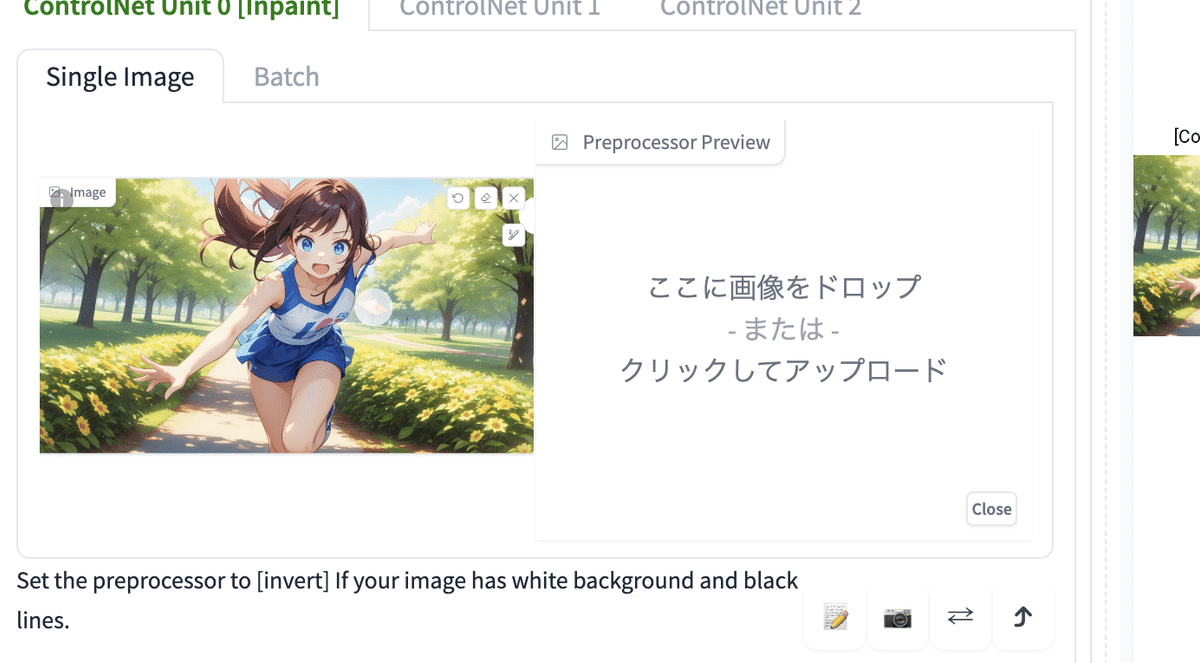
黒背景の白線の線画を使うときは、既に前処理されている状態なので、Preprocessorを「none」に設定します。

白背景の黒い線の線画を使うときは、Preprocessorを「invert ( from white bg & black line )」に設定します。
あとはプロンプトで色情報などを追加し、生成するだけです。
・Canny
・Lineart
・SoftEdge
・Scribble
全て同じやり方です。





後で説明するものも含まれていますが、抽出された線画を見ると、手描きで修正しやすいのは、Lineartかなと思います。
■ SoftEdge
SoftEdgeでは、元画像の輪郭を抽出し、画像を生成することができます。
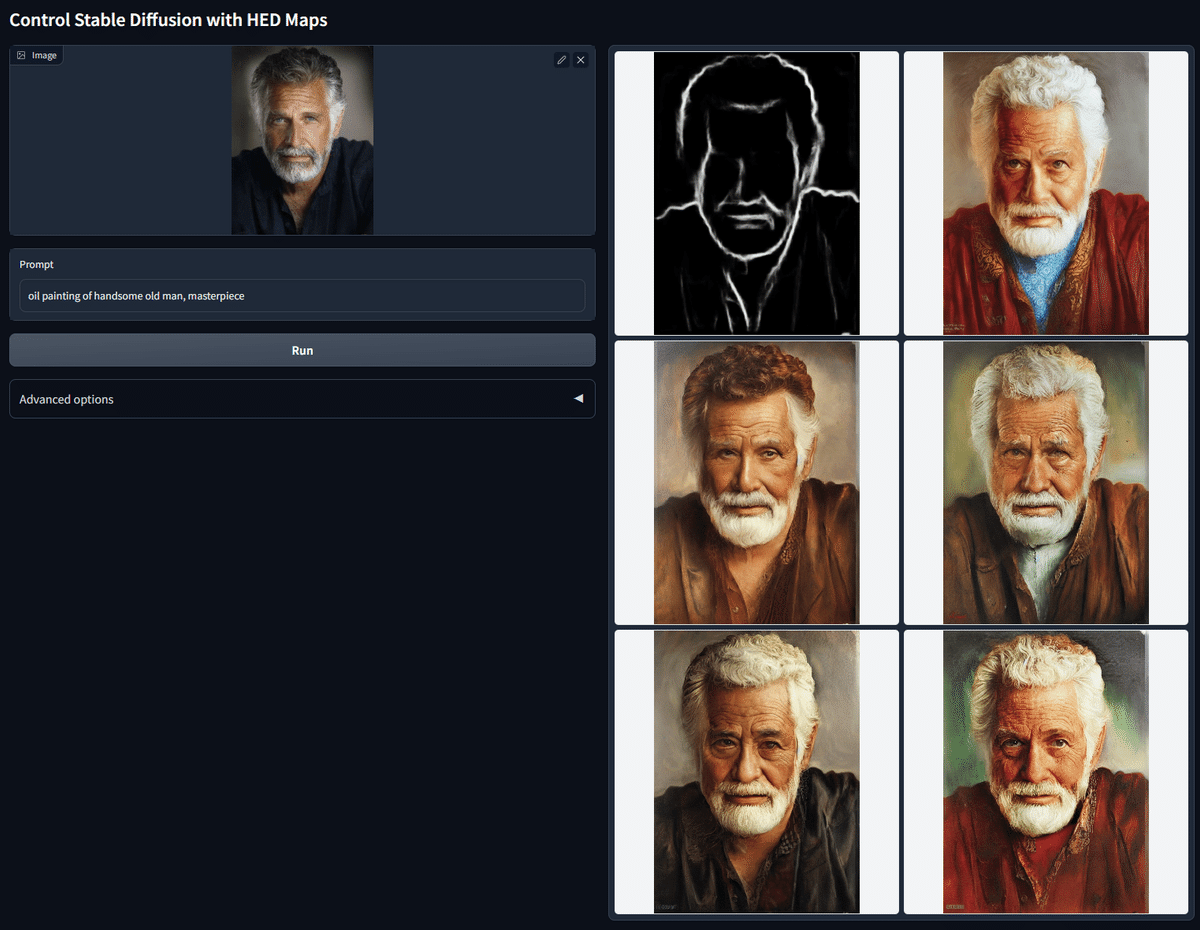
これは、元画像からSoftEdgeで線画を抽出し、その線画をもとに油絵にしています。

こちらは、元画像のロボットの線画をSoftEdgeで抽出し、その線画をもとにサイバーパンクな雰囲気にしています。
SoftEdgeは、CannyやLineartと比べると、線画に太さがあるのが特徴です。おそらく、線の太さ分だけ、AIに自由度を持たせているのかなと思います。とはいえ、CannyやLineartと同じように、元画像に近い画像が生成されます。





プロンプトなし

プロンプトなし
抽出された線画を見ると、後2つは例えば顔パーツの線画がありません。そのため、少し変更を加えたい場合は、後2つを選ぶのが良さそうです。





プロンプトなし

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
□ Control Weight(SoftEdge)

プロンプトなし

プロンプトなし
□ SoftEdgeの使い道
CannyやLineartと同じように、img2imgと併用し、画像の色を変えるのが良さそうです。やり方は同じなので、今回は省略します。先ほどのものを参考にしてください。
絵が描ける方は、もちろん自分の線画を使い、色塗りをさせたり、絵柄を変えたりすることが可能です。これもCannyやLineartと同じです。
■ Scribble/Sketch
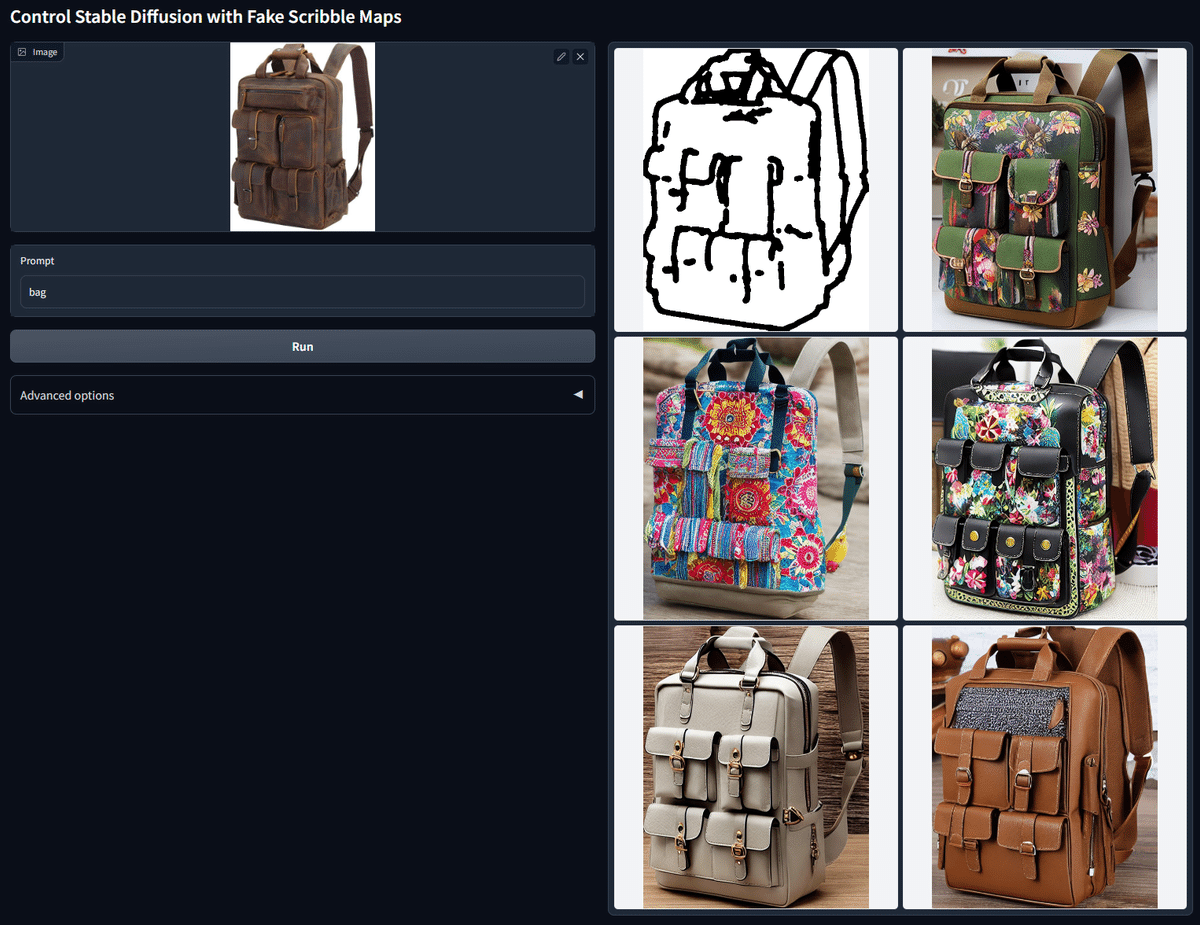


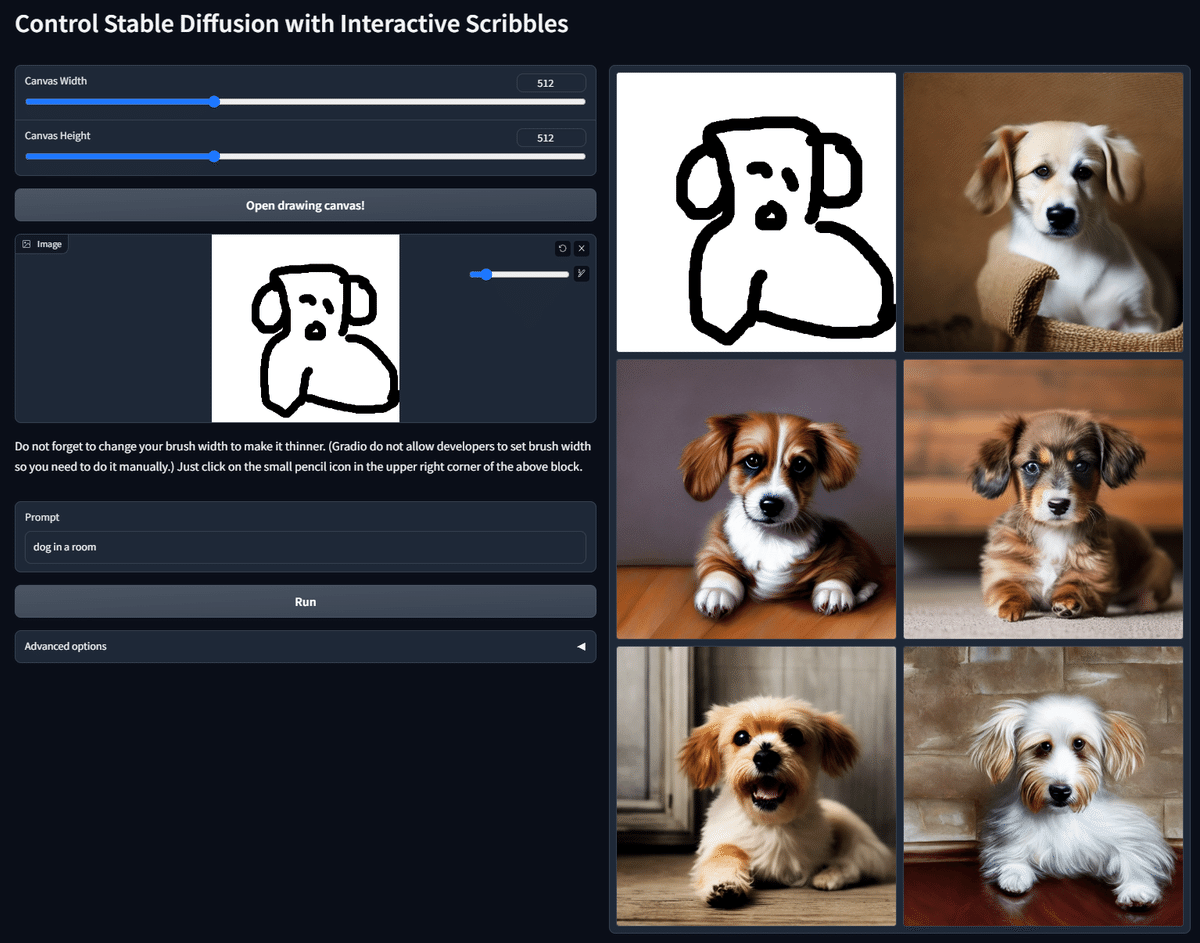
Scribble/Sketchでは、元画像の輪郭を抽出し、画像を生成することができます。
さらに、Scribble/Sketchでは、雑な線画や落書きからでも高品質な絵を作ることができます。
よくScribbleとだけ呼ばれるので、この記事でもScribble/SketchはScribbleとだけ記載します。





プロンプトなし

プロンプトなし
抽出される線画は太いですが、その太さの分だけAIが良い感じにイラストを仕上げてくれます。生成されるイラストの線画が、太くなるわけではありません。




プロンプトなし

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
CannyやLineartと比べると、元画像から離れた絵になります。
□ Scribbleで、落書きから画像生成

プロンプト:a man , solo, chibi , naturally curly hair, white hair, blue goggles on the head,Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
Scribbleでは、落書きのようなイラストからでも、いい感じの画像を生成してくれます。
・絵は下手だけど、描きたいことが決まっている
・プロンプトでは、描きたいものが中々出てくれない
ときに、とても便利な機能です。
Scribbleは、元画像の輪郭の抽出もある程度正確に行うので、Weightを上げるほど元画像の輪郭に近づいているのが分かります。


プロンプト:Surfer woman, ocean, sandy beach, blue sky, clouds
ネガティブ:low quality
雲の手描きが下手だったので、おかしくなったりしていますが、だいたい手描きの意図を汲んでくれています。


プロンプト:Surfer woman, ocean, sandy beach, blue sky, clouds
ネガティブ:low quality
・白背景
・黒背景
でクオリティは変わりませんでした。
□ Scribbleの使い道
Scribbleは、落書きから画像生成するときに、とても便利です。
・ある程度、描きたいことが決まっている
・プロンプトで描きたいものが中々出ない
ときにScribbleを使ってください。
また、Scribbleで抽出される線画は、
・Canny
・Lineart
・SoftEdge
などと比べると、やや雑です。そのため、元画像を維持するというよりは、元画像の輪郭をやや保ちつつも、絵に変更を加えたいときに、Scribbleは有効です。
□ Canny / Lineart / SoftEdge / Scribbleの比較
この元画像を、「金髪、赤いワンピース」に変更するというのを、4つのControlNetで試します。
何回か生成すれば、img2imgでも上手くいきますが、元画像とは変わってしまいます。


元画像をほぼ変えたくないなら、Canny / Lineart / SoftEdgeを使ってください。元画像から少し変わっていいなら、Scribbleやimg2imgを使ってください。
■ ポーズ&シルエット編 ■
以下の3つを解説します。
Depth
NormalMap
OpenPose
■ Depth(深度)
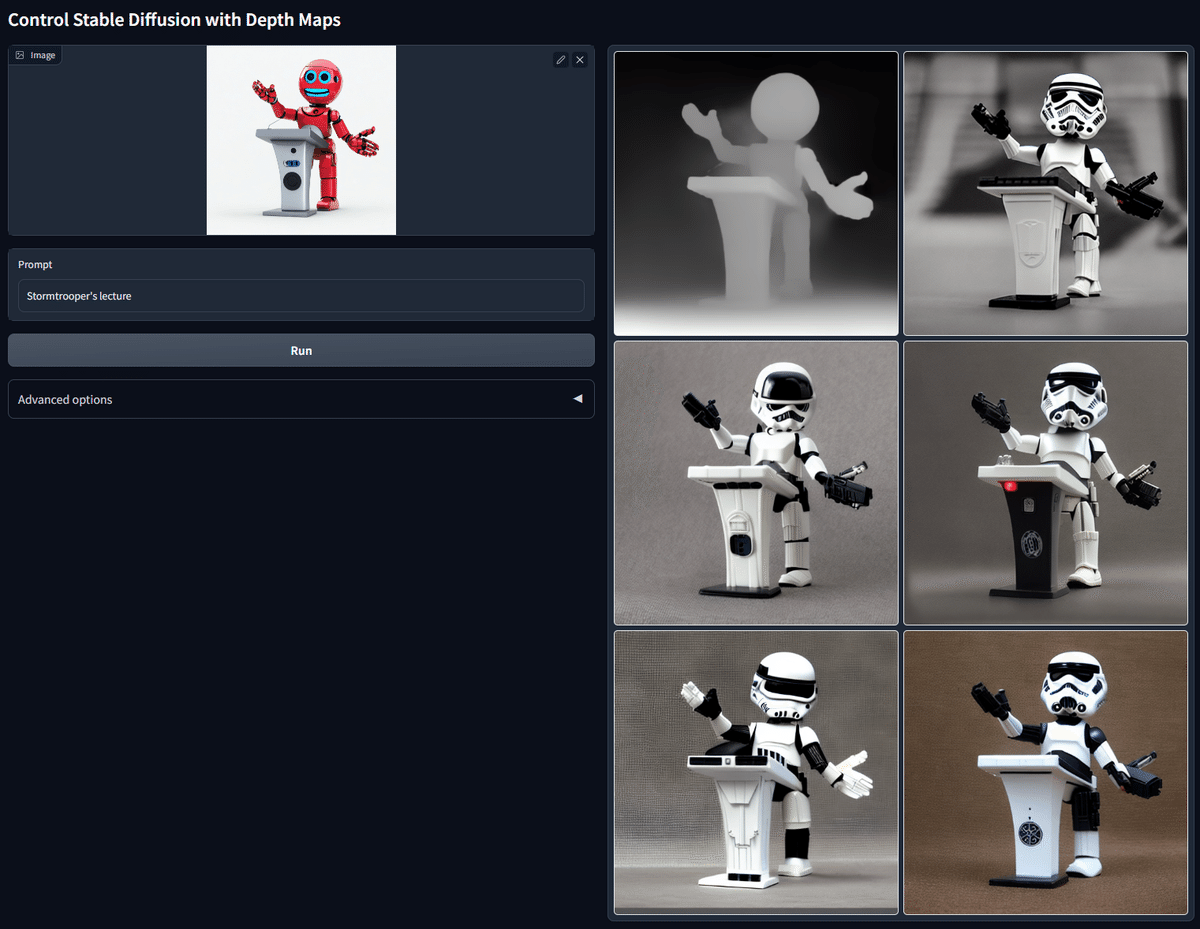

Depthは、元画像の深度情報を抽出し、同じ構図の画像を生成できます。深度情報は、近くにあるほど白く、遠くにあるほど黒く表示されます。
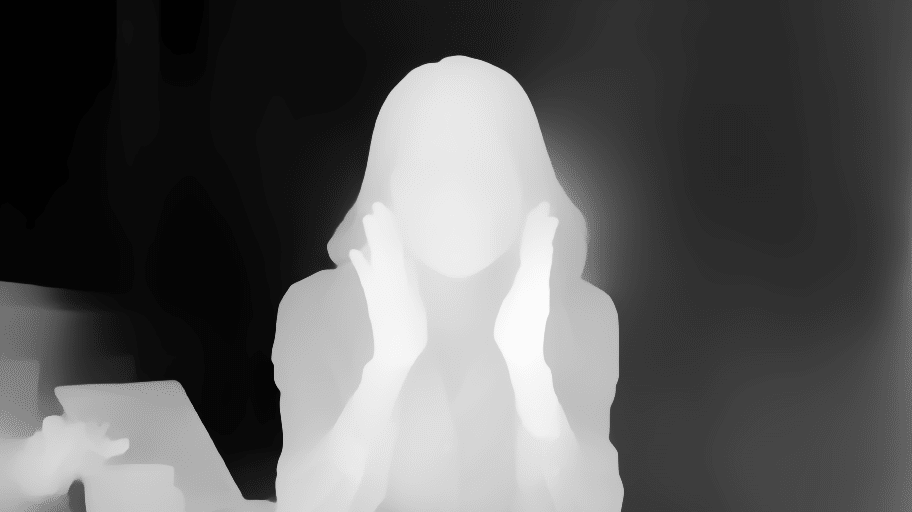




プロンプトなし

プロンプトなし
DepthにはPreprocessor(前処理)が4種類あります。
Depthでは、主にシルエットが抽出されます。輪郭が抽出されるCannyやLineartと比べると、細かい部分が再現されていないことが分かります。とはいえ、だいたいのポーズは再現してくれるので、ポーズは同じにしたいけど顔などの細かい部分を変えたいときにDepthは便利です。





プロンプトなし
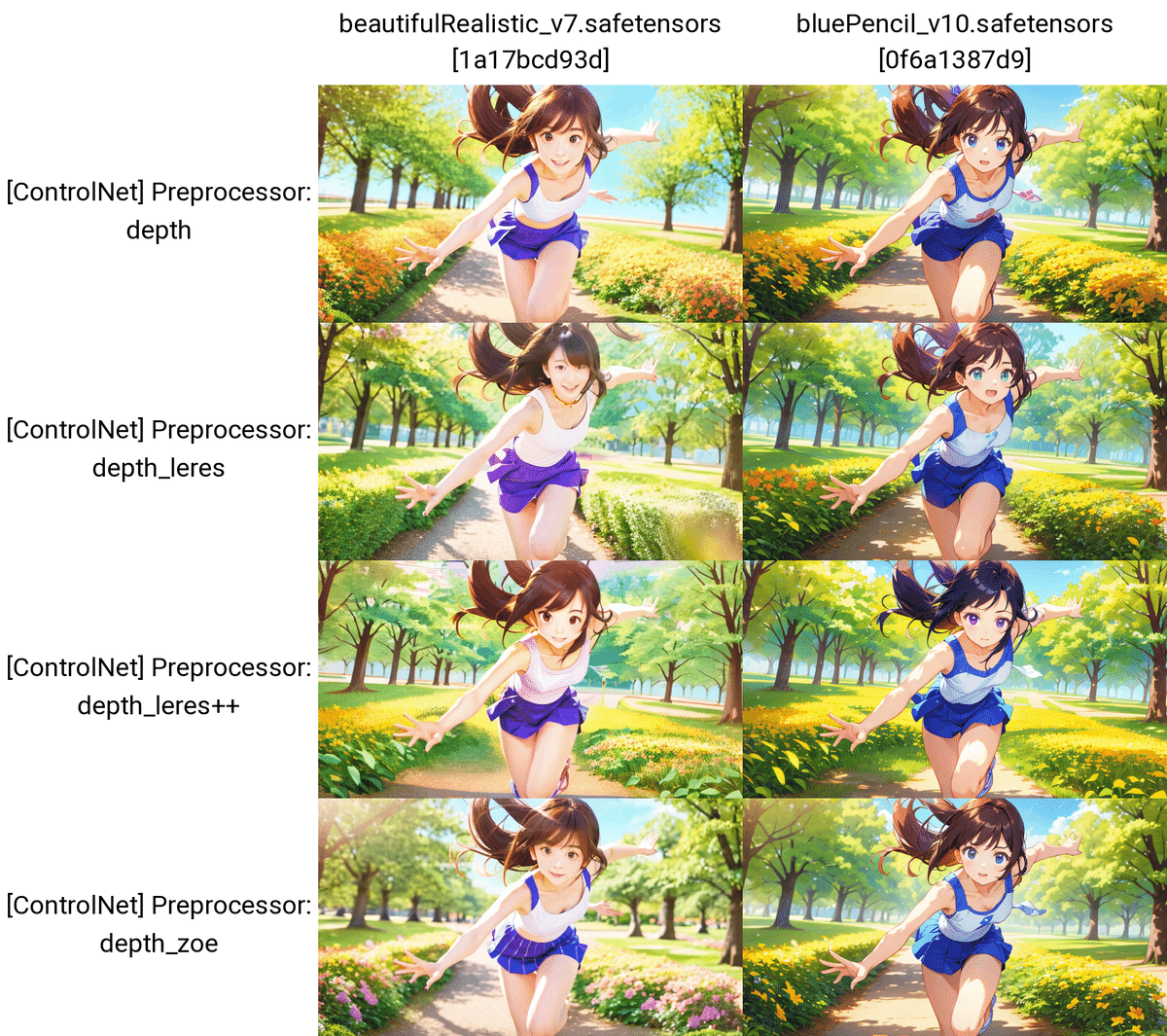
プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
□ Remove Near % と Remove Background %




Remove Near % と Remove Background %は、Control Weightと同じように、Depthの影響度を調整したいときに使います。
Depth Mapでは、
・白い部分が近く
・黒い部分が遠く
を表しています。
Remove Nearは、近くの部分を削除します。




Remove Backgroundは、遠くの部分を削除します。背景を消したいときは、Remove Backgroundの値を上げてください。
□ Depthの使い道

プロンプト:a man , solo, naturally curly hair, white hair, blue goggles on the head,Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask

プロンプト:a man , solo, naturally curly hair, white hair, blue goggles on the head,Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
顔などの細かい部分は元画像から維持せずに、ポーズなどのシルエットだけを維持して画像生成をしたいときに、Depthは有効です。
私が生成した画像のように、元画像の女性から、ロングヘアの男性に変えることができています。
人物のシルエットだけ引き継ぎ、背景を引き継ぎたくない場合は、先ほどのRemove Backgroundを使ってください。


Hires.fixあり
プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask

Hires.fixあり
プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
■ NormalMap(法線マップ)
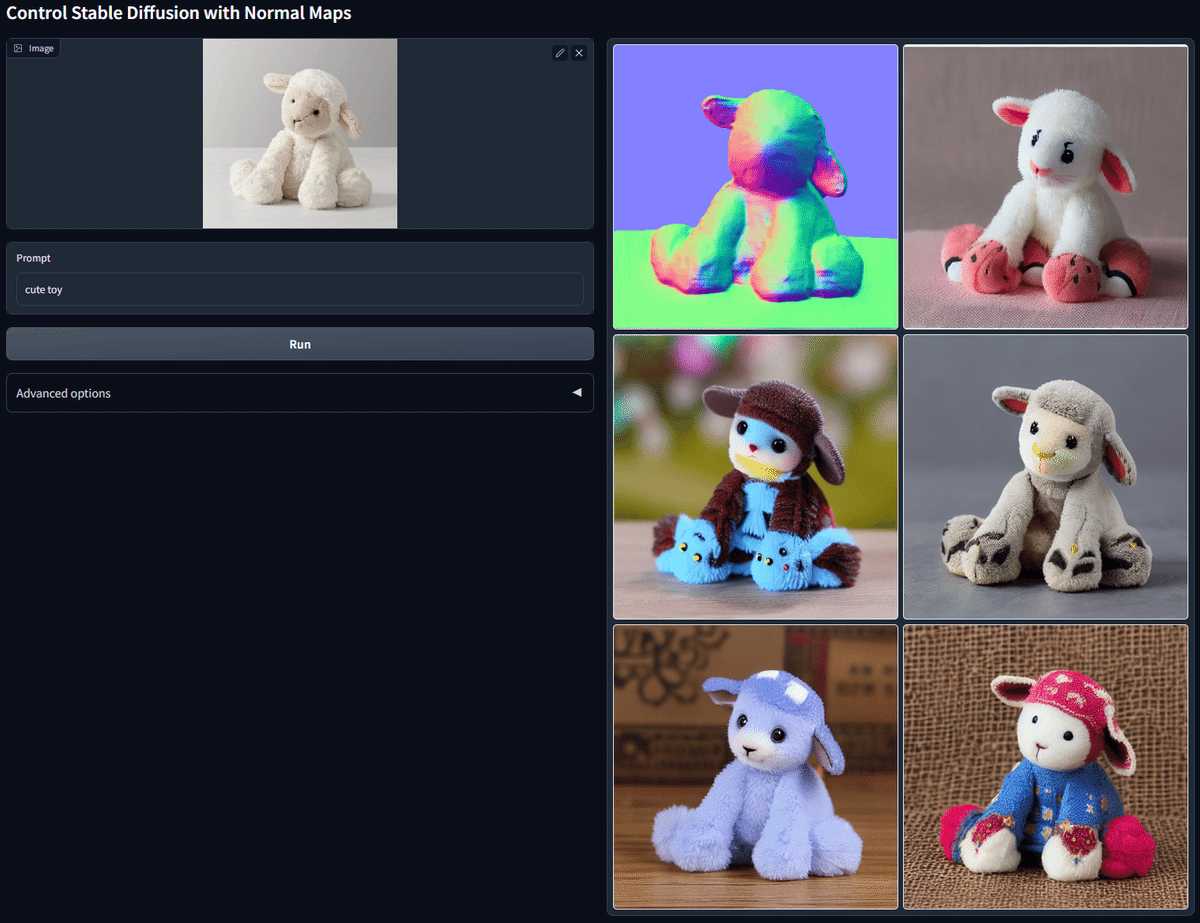

NormalMapでは、画像の凹凸情報を抽出し、新たな画像を生成することができます。NormalMapは、3DCGでよく使われる技術です。
NormalMapは、Depthよりも細かい部分まで抽出しますが、Depthと同じような機能だと思って大丈夫です。



プロンプトなし

プロンプトなし
NormalMapには、Preprocessorが2種類ありますが、normal_midasは、旧バージョンのNormalMapであり、改善されたものがnormal_baeです。実際にnormal_baeの方が、精度が良いので、こちらを使ってください。
NormalMapはDepthと似ていています。CannyやLineartほど元画像の輪郭線は引き継がれないので、顔などの細い部分は変わってしまいますが、ポーズやシルエットは元画像から引き継ぐことができます。

プロンプトなし

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
□ NormalMapの使い道


プロンプト:a man , solo, naturally curly hair, white hair, blue goggles on the head,Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask

プロンプト:a man , solo, naturally curly hair, white hair, blue goggles on the head,Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
NormalMapの使い道は、Depthと同じです。
顔などの細かい部分は元画像から維持せずに、ポーズなどのシルエットだけを維持して画像生成をしたいときに、NormalMapは有効です。
Hires.fixで画像サイズを上げました。

■ OpenPose


OpenPoseでは、画像からポーズ情報を抽出し、それに基づき画像を生成することができます。線画やシルエット、背景などを除いて、ポーズだけを抽出するのが特徴です。
キャラクターのポーズや表情だけコントロールしたいときに、OpenPoseはおすすめです。


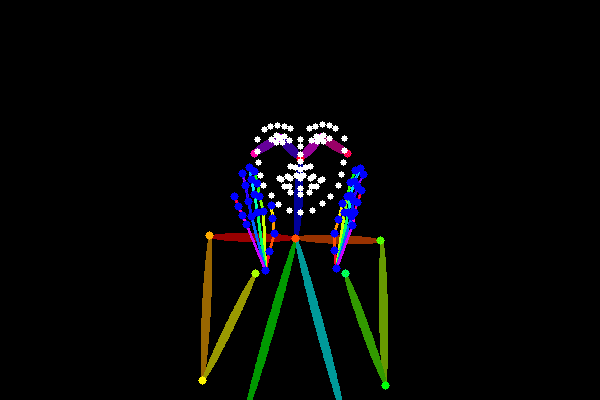

プロンプトなし

プロンプトなし
プロンプトなしで生成すると、こんな感じです。

プロンプトなし

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
OpenPoseは、元画像から表情とポーズは保ってくれますが、それ以外は維持しません。これはimg2imgなので、元画像とけっこう似ていますが、CannyやLineartと比べると、服装や背景、髪型などが大きく変わっていることが分かります。
□ OpenPoseの種類と違い
OpenPoseは、いくつか種類があります。


dw_openpose_full:全身+顔(表情)+手。最新版。
openpose:全身
openpose_hand:全身+手
openpose_face:全身+顔(表情)
openpose_faceonly:表情
openpose_full:全身+顔(表情)+手
最新であり、精度が高い傾向にあるのが、dw_openpose_fullです。基本的にdw_openpose_fullを使ってください。
手や表情がいらない場合は、編集画面で消すこともできます。編集方法は、後ほど解説します。
□ OpenPoseの棒人間から画像を生成
まずは、ControlNetで抽出された画像、
・Cannyなら、白黒の線画
・OpenPoseなら、棒人間
の保存方法について解説します。
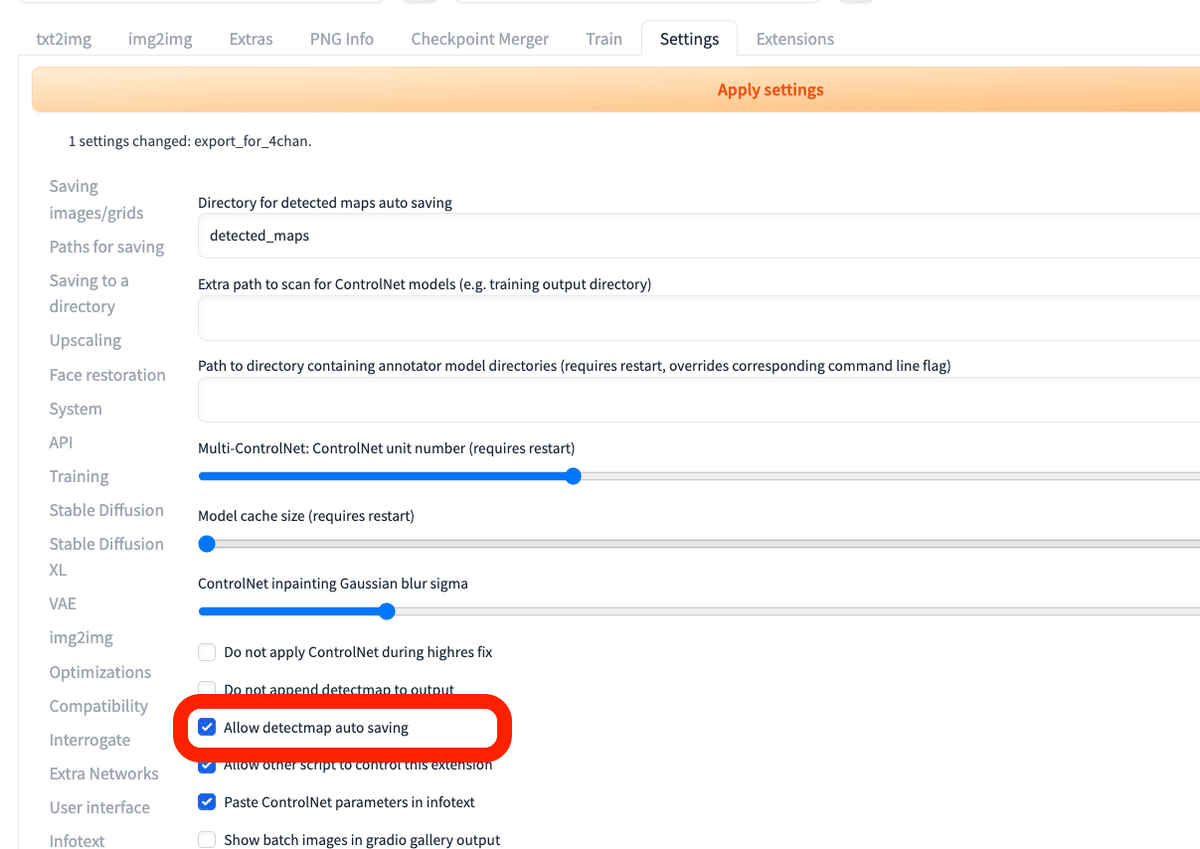
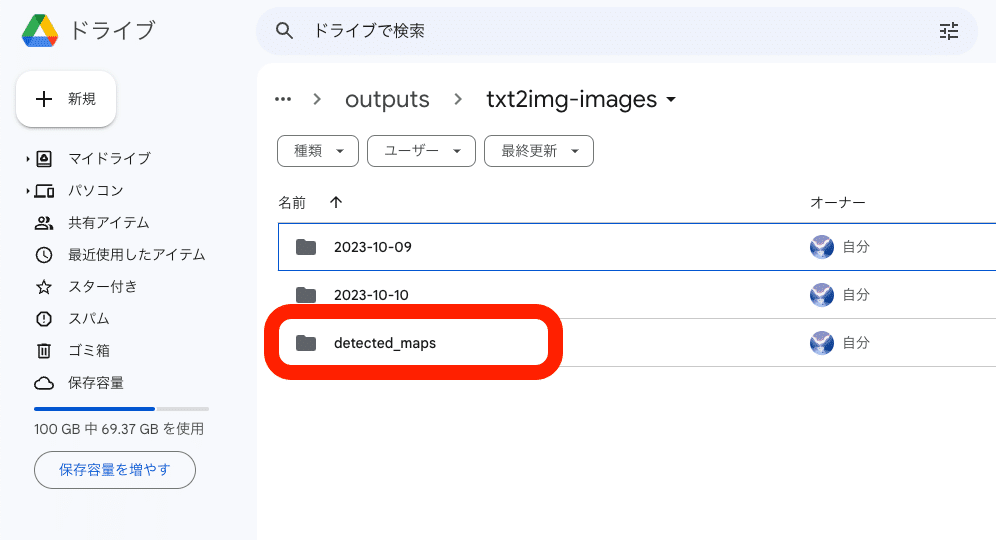
何か画像を使ってOpenPoseで画像生成をすると、棒人間の画像は、outputs → txt2img-images → detected_maps の中に保存されていきます。
OpenPoseで説明していますが、Cannyなどの他のControlNetでも、設定は同じです。
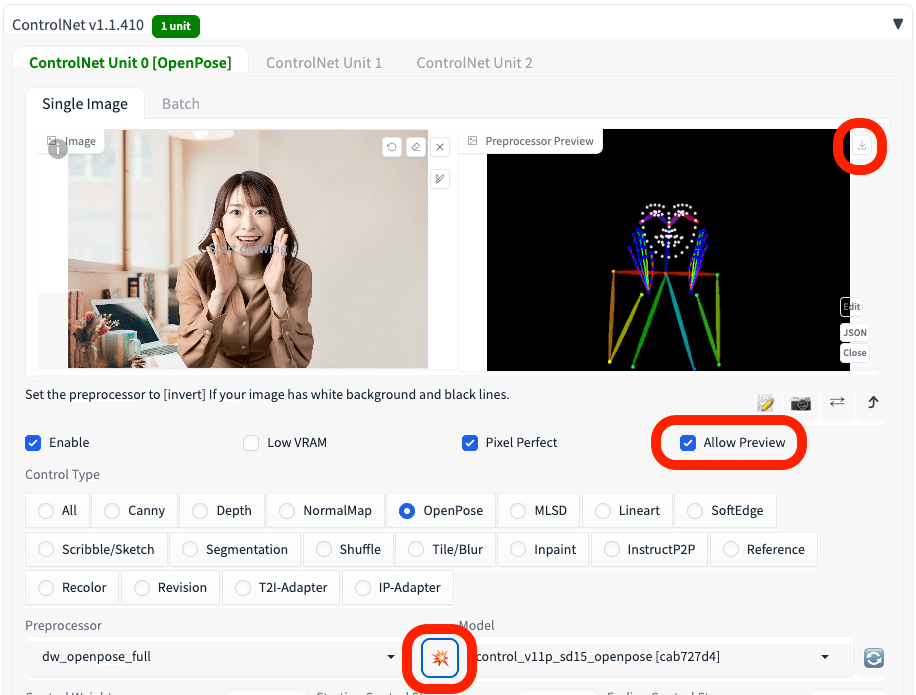
あるいは、Allow Previewにチェックを入れて有効化し、爆発アイコンをクリックすると、OpenPoseの前処理が行われて、棒人間が表示されます。棒人間の画像は、右上からダウンロード可能です。
OpenPoseで説明していますが、Cannyなどの他のControlNetでも、設定は同じです。



このように、棒人間から、画像を生成することができます。棒人間やポーズの探し方については、後ほど説明します。

棒人間を使うときは、Preprocessor(前処理)が終わっている状態なので、Preprocessorはnoneに設定してください。あとの設定は同じです。
現状では、OpenPoseを使ったとしても、手指はなかなか上手く行きません。元画像からOpenPoseで出力される棒人間の精度は良いのですが、棒人間から生成される画像の精度はあまり良くありません。特に有名ではない手の形やポーズを、OpenPoseだけで再現するのは今の時点では難しいです。
□ ポーズの探し方①画像生成して、良かったポーズから抽出
ポーズの探し方は、
① 画像生成して、良かったポーズから抽出
② Google検索して、画像からポーズを抽出
などがあります。また、
③ Civitaiで配布されてるものをダウンロードして使用
④ OpenPose Editorを使う
⑤ 3Dポーズサイト / アプリから作成
することもできます。④と⑤は自分でポーズを編集 / 作成する方法です。
まずは、① 画像生成して、良かったポーズから抽出 について解説します。

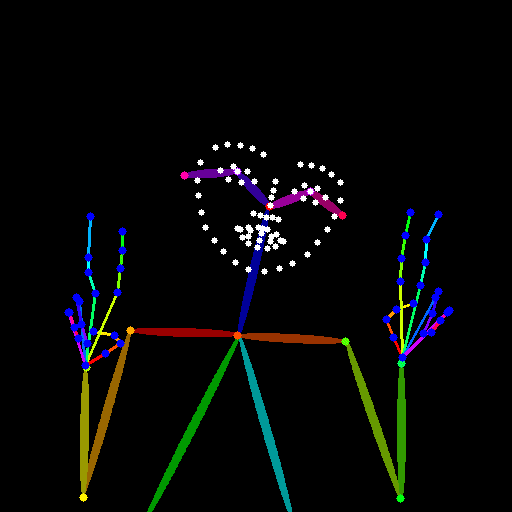
・笑顔
・ピース
が読み取られています。

プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
笑顔やピースというプロンプトは入れていませんが、OpenPoseによって画像に反映されているのが分かります。プロンプトを追加すると、さらに反映されやすくなります。
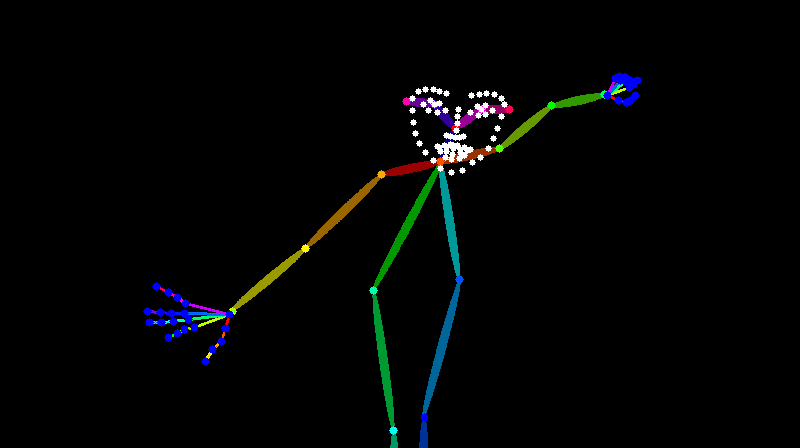

プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask

プロンプト:a man , solo , chibi, naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask


デフォルメが強いと、ほとんど表情が読み取られないので、注意してください。
□ ポーズの探し方② 画像検索して、ポーズを抽出
2つ目は、Google検索などで良さそうなポーズを探し、Stable Diffusionで棒人間のポーズを抽出する方法です。




ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask

ポーズに関する言葉は入れていませんが、ポーズが再現されています。もし上手くポーズが出ない場合でも、プロンプトを入れることで出やすくなります。




プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask

プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes, angry
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes, angry
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
こちらは、OpenPoseだけで怒り顔にならなかったので、プロンプトに「angry」を入れました。細かい表情の表現は、OpenPoseを使ったとしても、まだ難しいです。表情に関しては、プロンプトで調整してください。




□ ポーズの探し方③ Civitaiで配布されてるものをダウンロードして使用
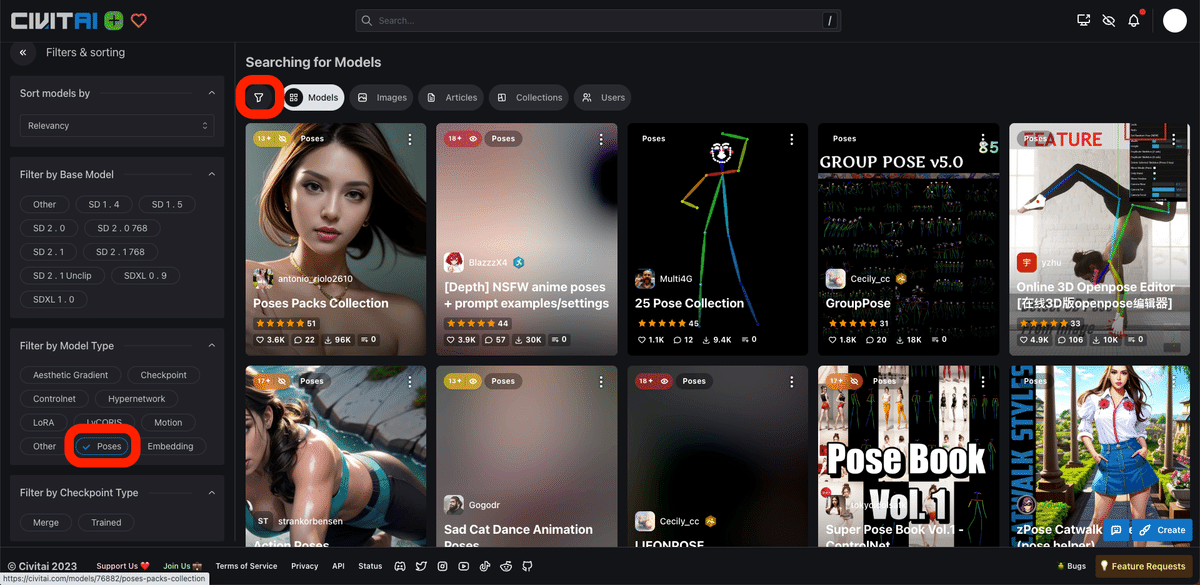
Civitaiでは、直接、棒人間のポーズをダウンロードできます。
ポーズを探すときは、画像のように、検索設定をポーズに絞ると探しやすいです。

また、posesと検索しても、棒人間を探すことができます。ただし、他の別用途のデータも表示されるので、間違えないように注意してください。左上に「poses」と書かれているものが、OpenPose用の棒人間のデータです。
配布されているポーズはまだ少ないので、紹介だけにとどめておきます。
□ ポーズの探し方④ OpenPose Editorを使う
OpenPose Editorのインストール

OpenPoseの棒人間は、Stable Diffusionで編集することもできます。OpenPose Editorは、抽出された棒人間のデータを微調整したいときに便利です。
このエディター画面を開くには、まずOpenPose Editorをインストールします。

「sd-webui-openpose-editor」こちらのサイトを開き、緑色の「Code」ボタンをクリック → URLをコピーしてください。

次に「Extensions」→「Install from URL」をクリック

先ほどのURLを入力したら、「Install」ボタンをクリックしてください。
最後に、「Installed」→「Apple and quit」をクリックしてください。これでインストールは完了です。
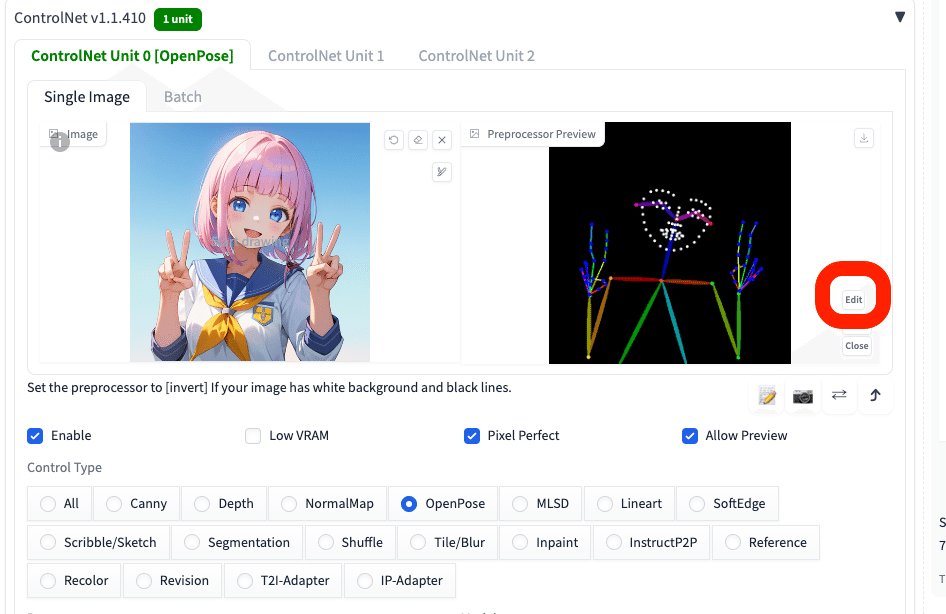
爆発マークを押すと表示されるプレビュー画像に、「Edit」ボタンが現れます。
OpenPose Editorの使い方
Editボタンをクリックすると、Editorが開きます。

関節の丸い点をクリックしながら動かすと、棒人間の一部を移動することができます。
棒人間の丸いところにカーソルを合わせると、矢印が十字矢印に変わるので、そのときに右クリックすると、棒人間を部分的に非表示にすることができます。これは、command + Zキーなどで戻すことができないので、

左側の目のアイコンで、表示 / 非表示を変更してください。
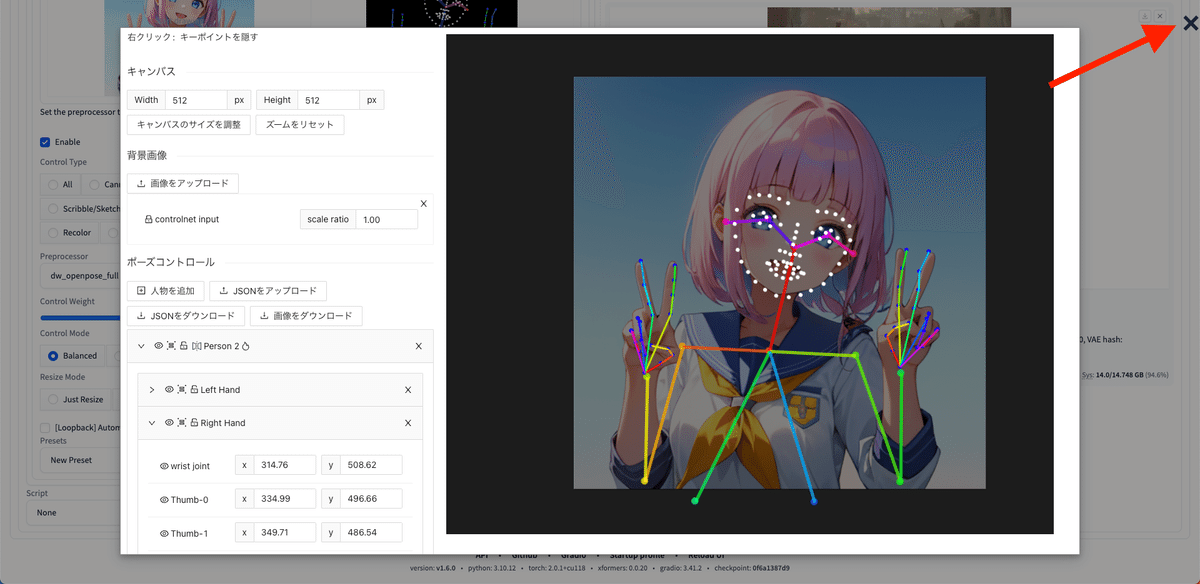
操作を全てリセットしたいときは、右上のバツボタンをクリックしてください。もう1度Editorを開くと、最初からやり直すことができます。

画面の何もないところをドラッグすると、まとめて選択できます。左側の目のアイコンでも、まとめて表示と非表示が可能です。
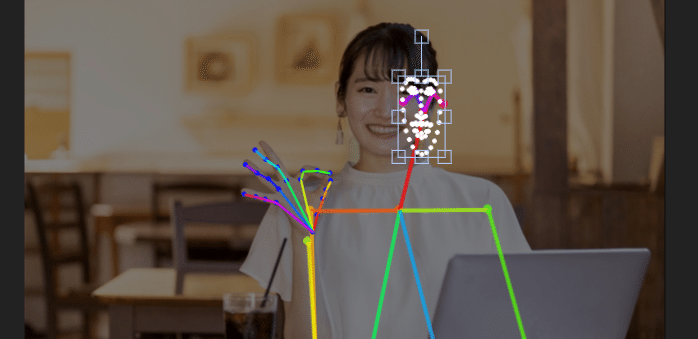
このように幅を狭くすると、顔の「斜め横向き」を表現できます。

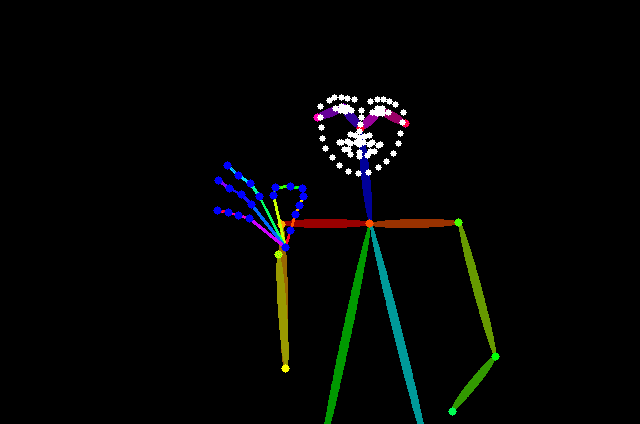


プロンプトは「1girl , simple background」のみなので、OpenPoseよって顔の向きをコントロールされているのが分かります。

編集したポーズは、右上の部分からダウンロード可能です。
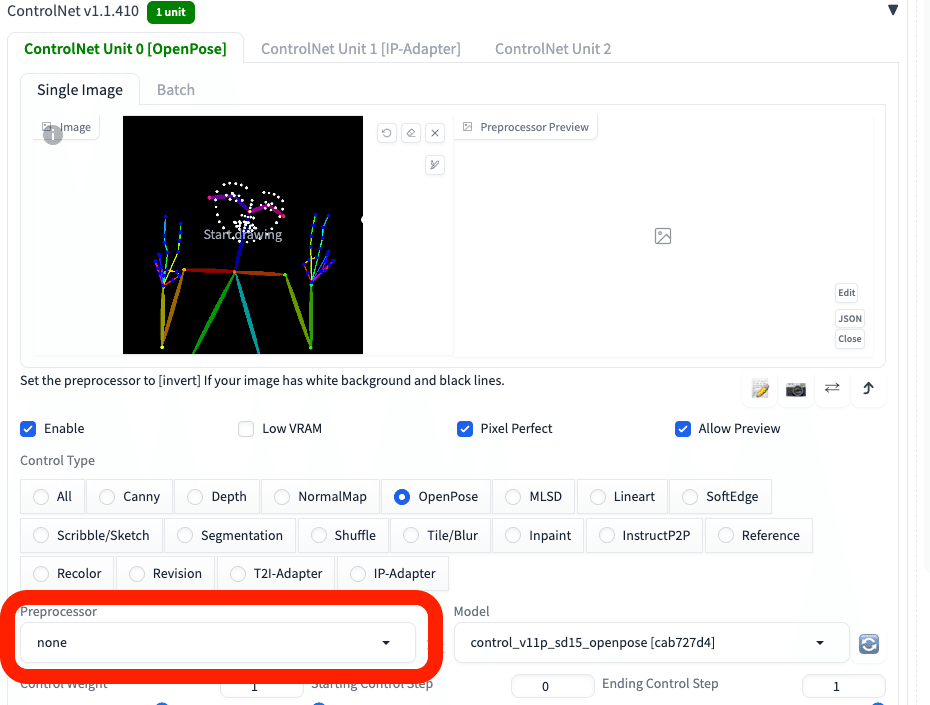
棒人間のポーズを使うときは、前処理された状態なので、Preprocessorをnoneに設定して使ってください。
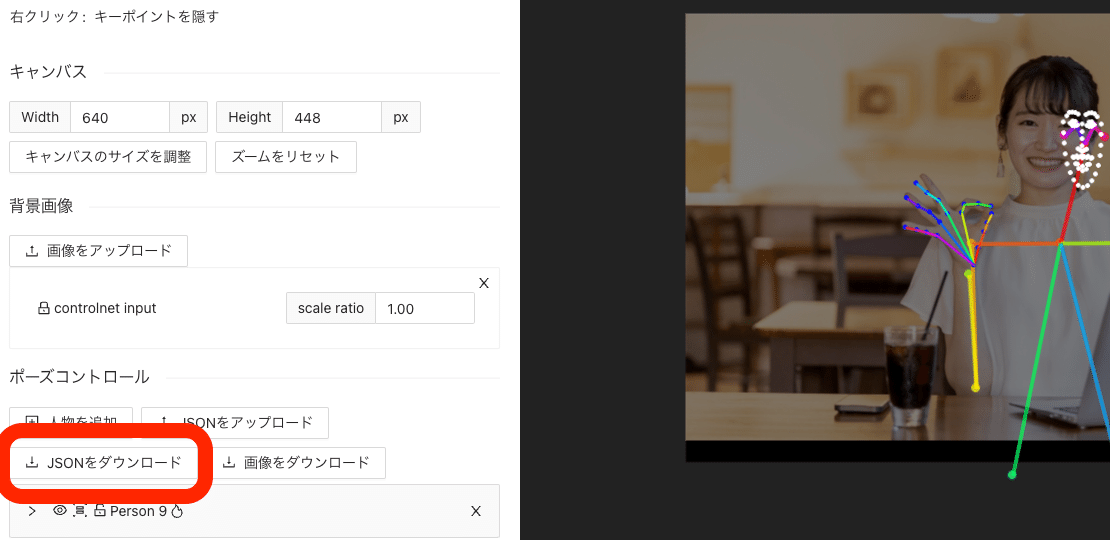
保存するとき、棒人間を後で編集したい場合は、「JSONをダウンロード」をクリックしてください。
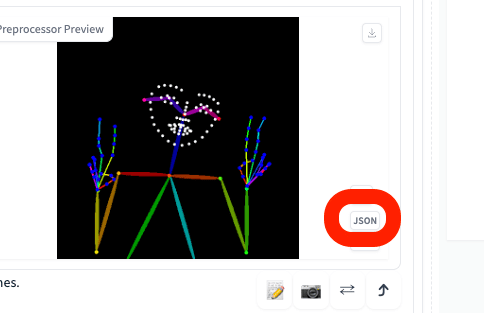
保存したJSONファイルは、JSONボタンをクリックして再利用することができます。

すぐに使う場合は、「ControlNetにポーズを送信」をクリックしてください。
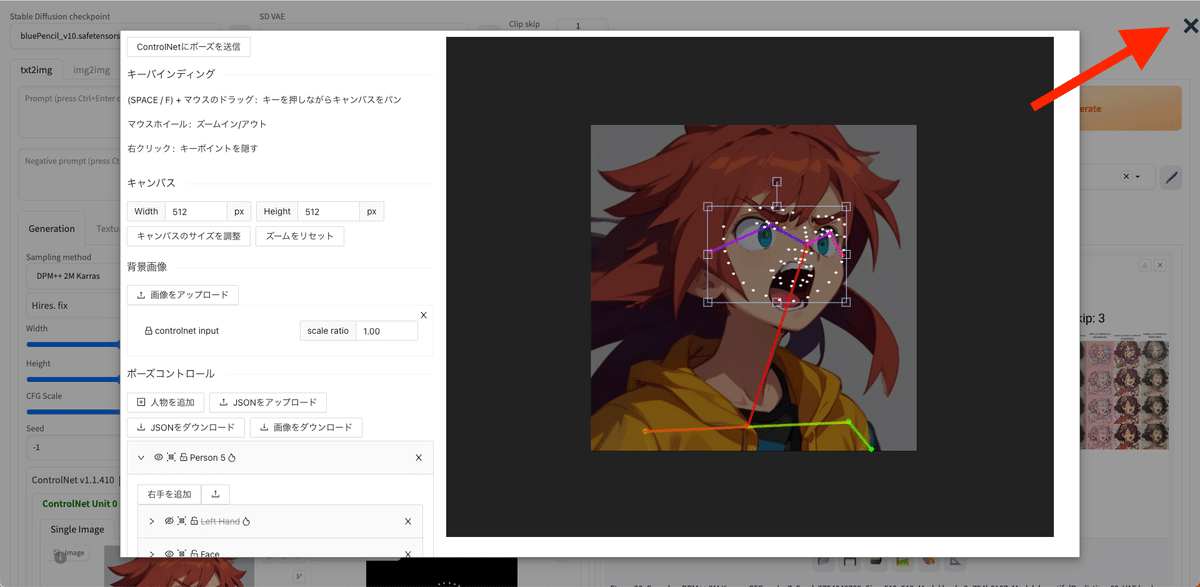
右上のバツをクリックすると、リセットされて編集前に戻ってしまうので、注意してください。最初からやり直したいときは、バツをクリックしてください。
□ ポーズの探し方⑤ 3Dポーズサイト / アプリから作成
3Dポーズサイト / アプリで、オリジナルのポーズを作ることもできます。ただし、慣れが必要だったりして難しいので、上級者向けの方法です。
1つ目:OpenPose Editor(GitHub)

1つ目は、OpenPose Editorというサイトです。

このサイトの良い点は、ポーズの手足を
・OpenPose
・Depth
・Nomalmap
・Canny
で保存できるところです。
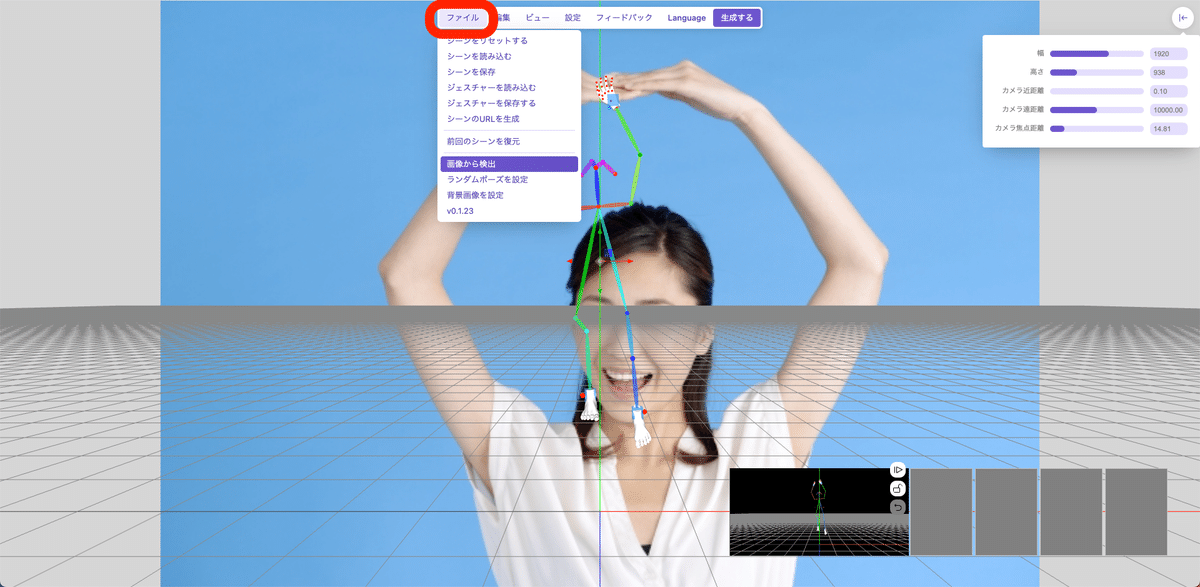
また、ファイル → 画像から検出 で、画像からポーズを取ってくれます。ただし、この精度はイマイチかなという感じです。私の使い方が間違っているかもしれませんが。
いちおう紹介しておきました。
2つ目:PoseMy.Art
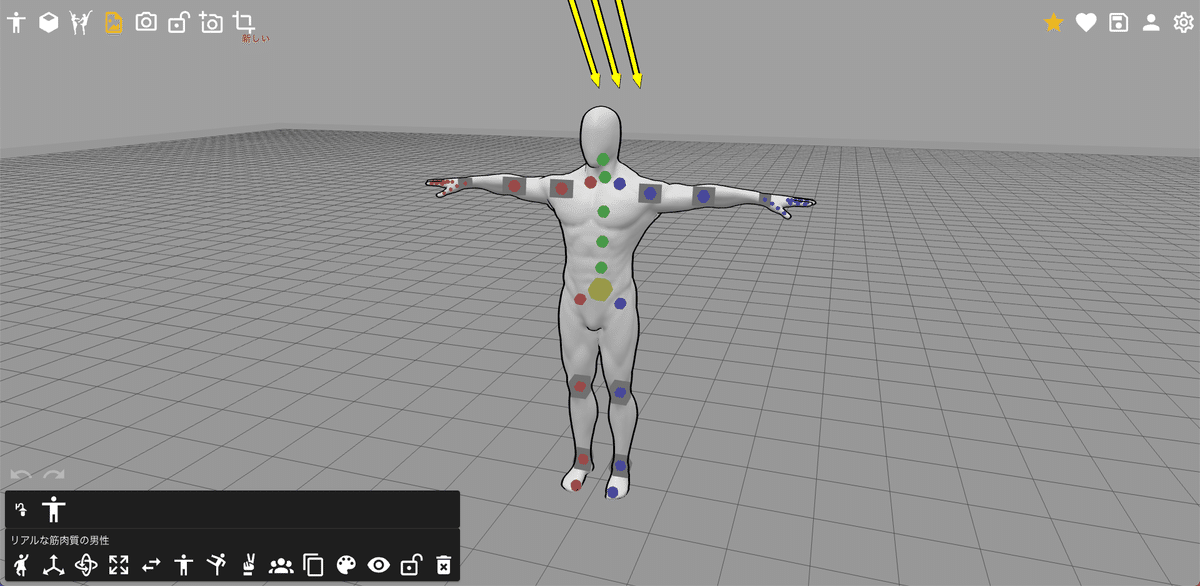
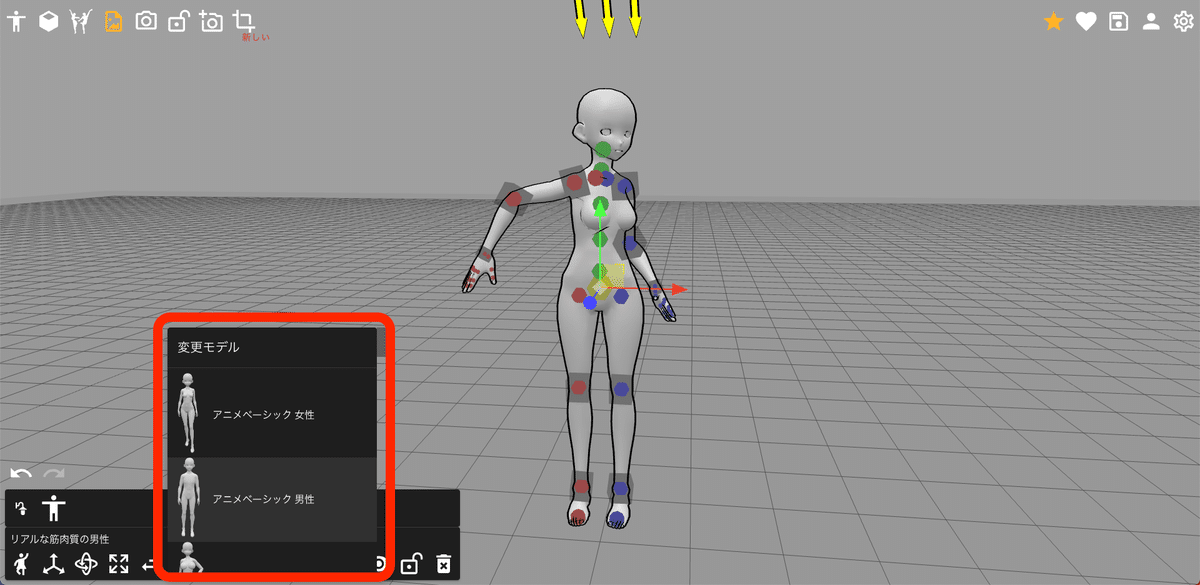
2つ目は、PoseMy.Artです。モデルは、アニメっぽいものから、筋肉質のモデル、ちびキャラモデルなど、色々あります。

自由にポーズをとらせることはできますが、操作するのは、慣れるまで難しいです。

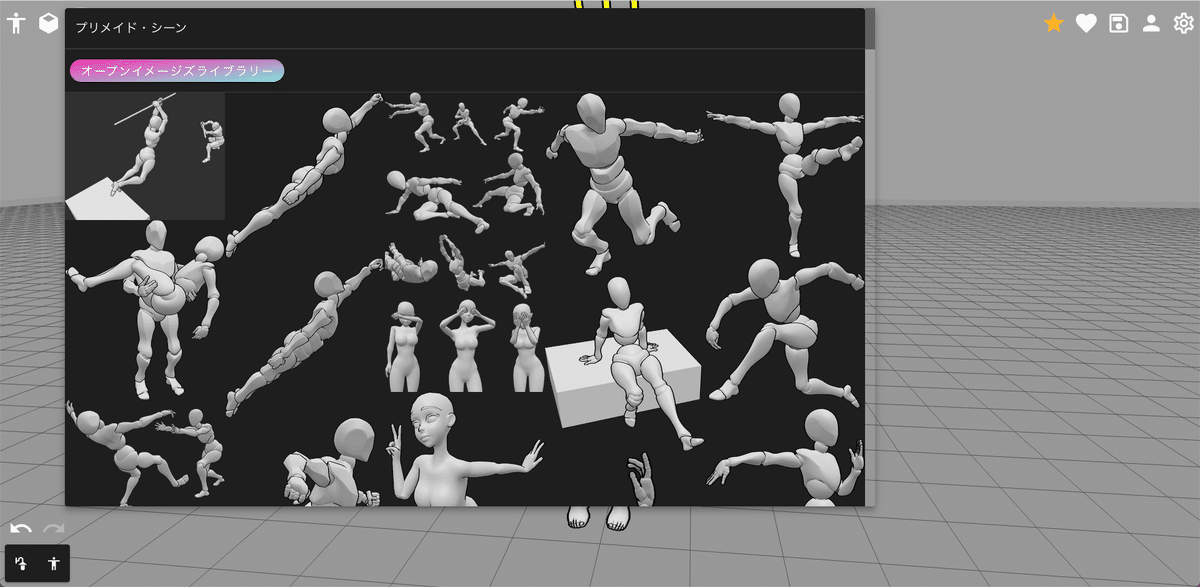
初心者の方は、テンプレートを使うのがおすすめです。
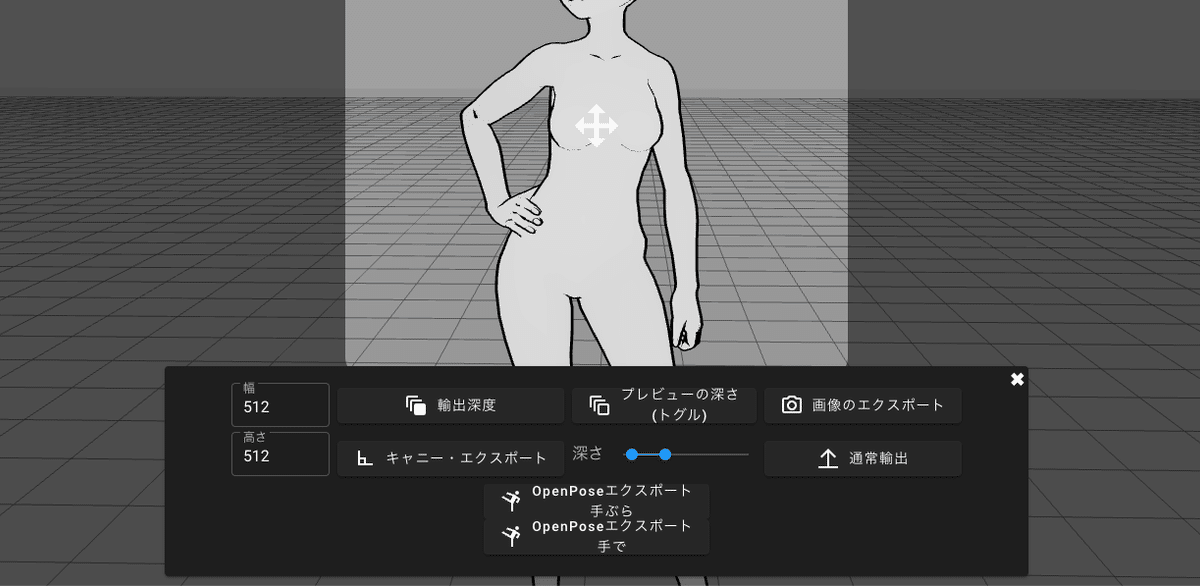

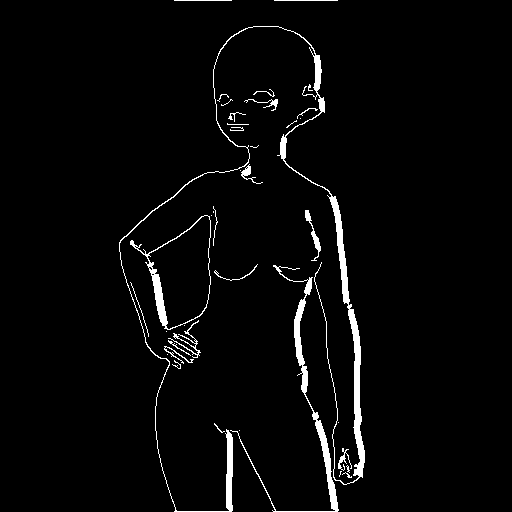
好きなポーズを選んだら保存します。DepthやCanny画像も保存することができます。
3つ目:Magic Poser


次は、Magic Poserです。Web版もありますが、iOSとAndroidがメインみたいです。
iPadで少し触ってみた感じ、とても直感的に操作できて、モデルも動かしやすかったです。
有料版になると色々なモデルを使えるみたいですが、ポーズのテンプレートは無いみたいなので、ポーズは自分で作る必要があります。
4つ目:イージーポーザー


操作が少し分かりづらくて、難しかったです。
課金すると、色々なポーズをとらせることができます。
□ OpenPoseの使い道
・線画を維持するCannyやLineart、SoftEdge
・シルエットを維持するDepthやNormalMap
・ポーズや手指、表情を維持するOpenPose
OpenPoseは、線画やシルエットは元画像から引き継がないので、利用できる幅がとても広いです。女性の画像から抽出したポーズでも、男性のポーズとして使うことができます。
プロンプト:a man , solo, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab, black eyes, angry
ネガティブ:low quality, glasses, black background, Goggles on eyes, girl, mask
ただしOpenPoseを使ったとしても、手指や細かい表情の再現はまだ難しいです。


プロンプト:1boy, fist pump, combat sports, match venue
ネガティブ:low quality, monochrome, low-glamour, plain clothes
さらにIP-Adapterと組み合わせることで、同じキャラを保ちつつ、特定のポーズをとらせることができます。IP-Adapterについては、別の動画講義で説明するので、詳しい内容はそちらを確認してください。
□ 追記 キャラクター設定画の作り方
・IP-Adapter(またはReference)
・OpenPose
でキャラクターの設定画を作ることができます。前者に関しては、この記事の後半部分を読んでください。動画講義は、OpenPoseとは別のものになります。



まずは、3Dポーズアプリで、顔の角度を変えてOpenPoseを出力します。シルエットまで引き継ぎたい場合は、DepthやCannyも保存してください。

次に、IP-AdapterとOpenPoseを設定します。Control Weightなどの値を調整してください。

プロンプト:(a man:1.2) , face, smile, black hoodie,white background, (look ahead:1.3), (slant eyes, sharp eyes:1.2)
ネガティブ:EasyNegativev2, low quality, (poor eyes:1.2), troubled eyebrows, (look here, looking at the camera:1.3), (Drooping eyes:1.2)
この後ControlNetのTileで拡大


完璧ではないですが、現時点でも、これくらいなら可能です。
■ 背景・建物編 ■
■ MLSD



MLSDでは、画像から直線を抽出し、画像を生成することができます。部屋や建物など、背景画像を生成したいときに、MLSDはおすすめです。






MLSDは、画像から直線を抽出しますが、曲線は抽出されません。そのため、プロンプトで変えられる部分は、主に元画像の直線の部分以外です。
他の画像でも試してみました。




MLSDでは、曲線は無視されるので、少し人が入っている画像でも背景画像を出力することができます。
MLSDで抽出される直線の量を調整したい場合は、Control Weightの値などを調整してください。Control Weightの値を下げるほど、プロンプトの影響が現れます。
□ MLSDの使い道






MLSDは、主に背景画像をつくりたいときに使えますが、直線部分がないと効果を発揮しません。
上の画像は、水面との境界部分が抽出されただけです。生成された画像のクオリティは悪くないですが、類推される部分が多くなり、プロンプトの影響が多くなります。
これを逆手に取って、湖と山の境界線を手描きで作り、MLSDとして使うこともできます。川と土、海と空などの境界の場所をコントロールしたいときに活用できそうです。
■ Segmentation


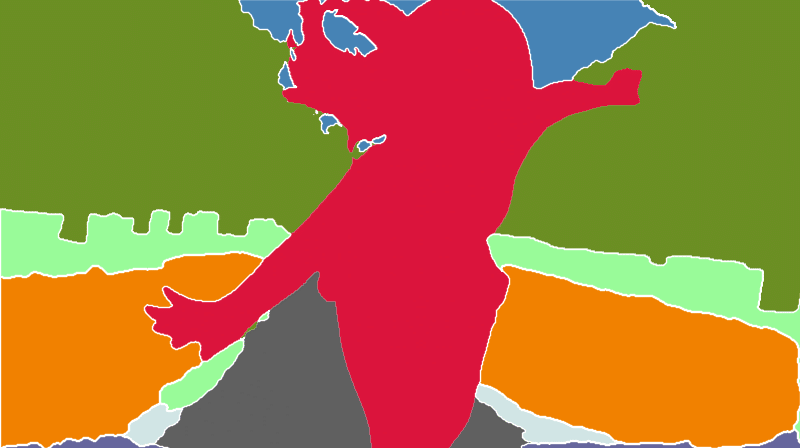
Segmentationでは、元画像から物体を抽出して分類し、その情報をもとに画像生成することができます。
分類された物体は、「何の物体であるか」が色で分けられています。そのため、描きたいものを特定の構図に固定することが可能です。「どこに何を描くか」が明確に決まっている場合は、Segmentationがおすすめです。
CannyやDepthなどの他のControlNetタイプよりも、何が描かれているかを細かく指定できるのがSegmentationです。ただし、奥行きなどは苦手らしいです。





プロンプトなし

low quality
Segmentationは、あまり精度は高くないと感じています。
Segmentationには、Preprocessorが3つあります。精度は高い方から、以下のようになります。
・seg_ofcoco(oneformer_coco)
・seg_ofade20k(oneformer_ade20k)
・seg_ufade20k(segmentation)
seg_ofcocoがおすすめです。

ADE20Kは150色、COCOは182色で分類されており、それくらいの物体識別能力があるみたいです。
Segmentationは、キャラクター単体よりも、背景ありのキャラクターや背景をコントロールしたいときにおすすめです。色分けすることにより、描きたいものと場所をコントロールできます。ただし、Stable Diffusionだけでは完結せず、画像編集ソフトなどを使う必要があるため、やや面倒です。




プロンプト:1girl, run
ネガティブ:low quality, bad anatomy
元画像から物体を読み取って生成してくれるとはいえ、やはりプロンプトを入れてあげないと、クオリティが高い画像は生成されません。
正直、Segmentationのクオリティはあまり高くありません。

□ Segmentationの応用
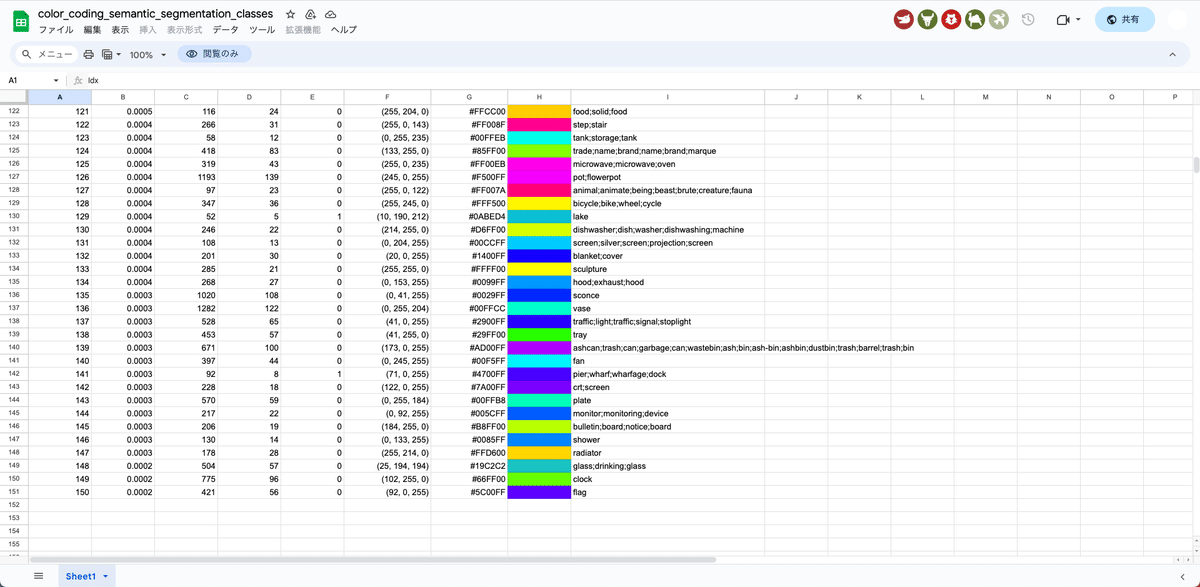
Segmentationの色情報は、こちらのGoogleスプレッドシートに詳しく書かれています。
必ずしも、厳密に指定の色にする必要はありません。ある程度色を塗り分けられていれば、指定された色じゃなくても物体を分けて生成してくれます。

編集するために、「ファイル」→「コピーを作成」をクリックしてください。
次に、自分が描きたいものを表す色情報をコピーします。「#00FFEB」などです。
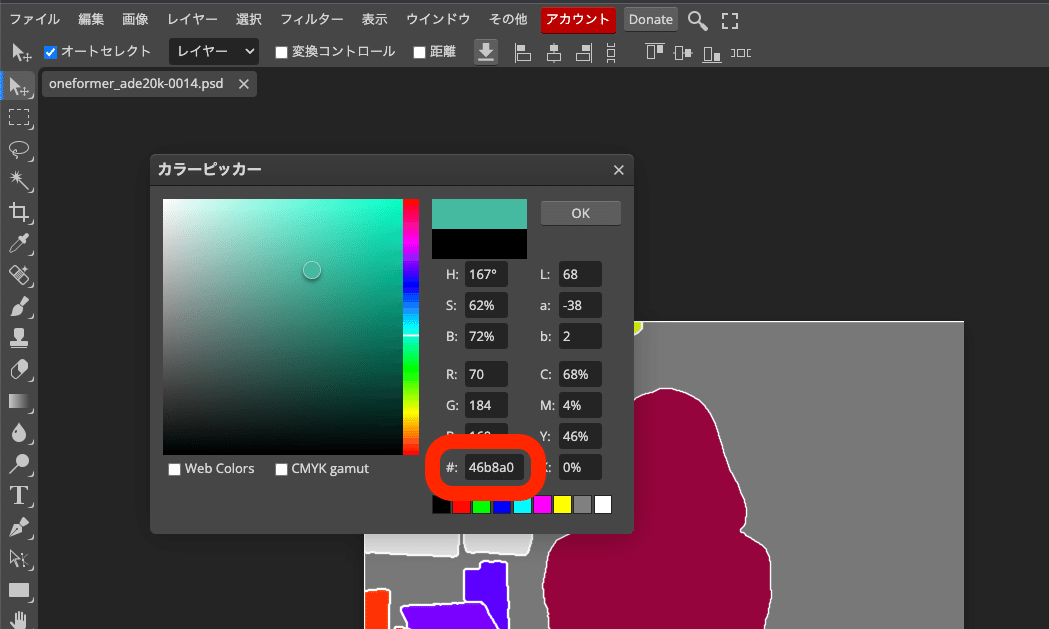
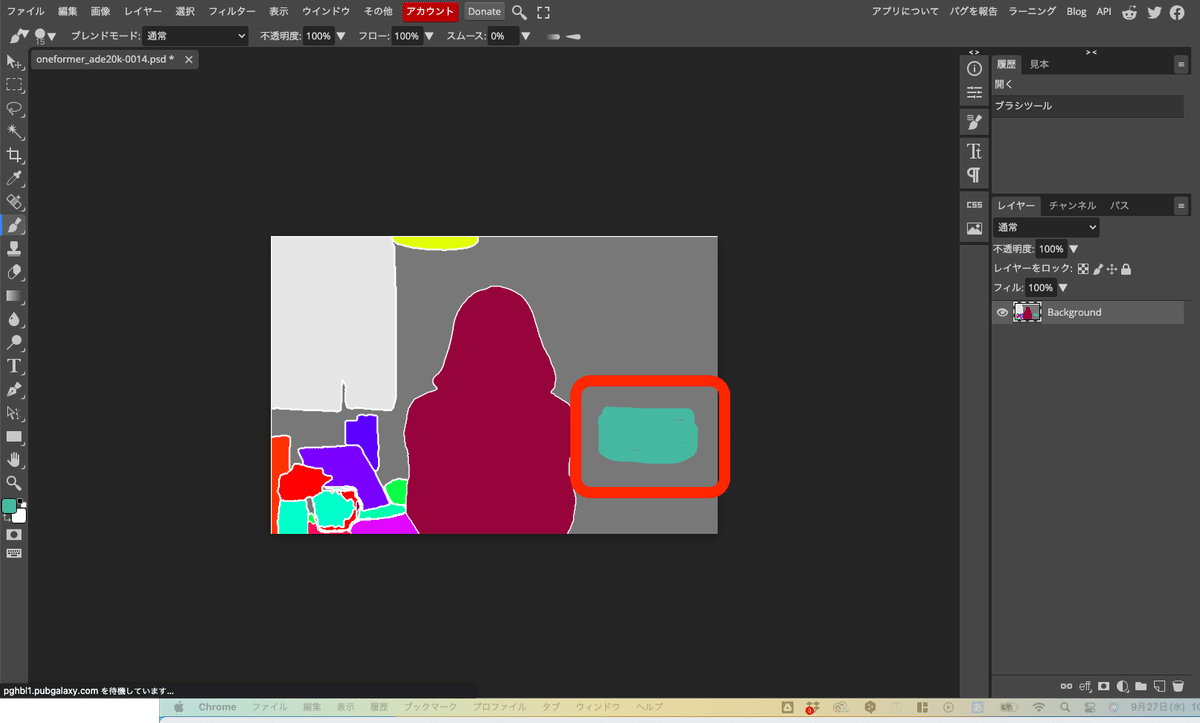
色コードを設定し、後は描くだけです。

画像を設定し、Preprocessorを「none」にし、画像生成をします。


プロンプトなしでも、時計とバッグのようなものが追加されました。ただし、指定したものが描かれなかったり、絵のクオリティ低いので、プロンプトは書いてください。
□ Segmentationの使い道
プロンプトなし
プロンプトなし
背景についてCannyやLineartと見比べると、Segmentationのクオリティはあまり高くないと感じます。そのため、必ずしもSegmentationを使う必要はありません。ただしSegmentationの場合は、上手な線画が描けなくても、物体を色分けするだけで簡単に出せるという再現性はあると思います。
特に背景について、
・何を描きたいか
・どの場所に描きたいか
が既に決まっている場合、Segmentationの使用を選択肢に入れても良いと思います。
■ 変化を加える編 ■
■ Inpaint(SD1.5のみ)
Inpaintでは、髪や服装、表情などの画像の一部を変更し、画像を生成することができます。
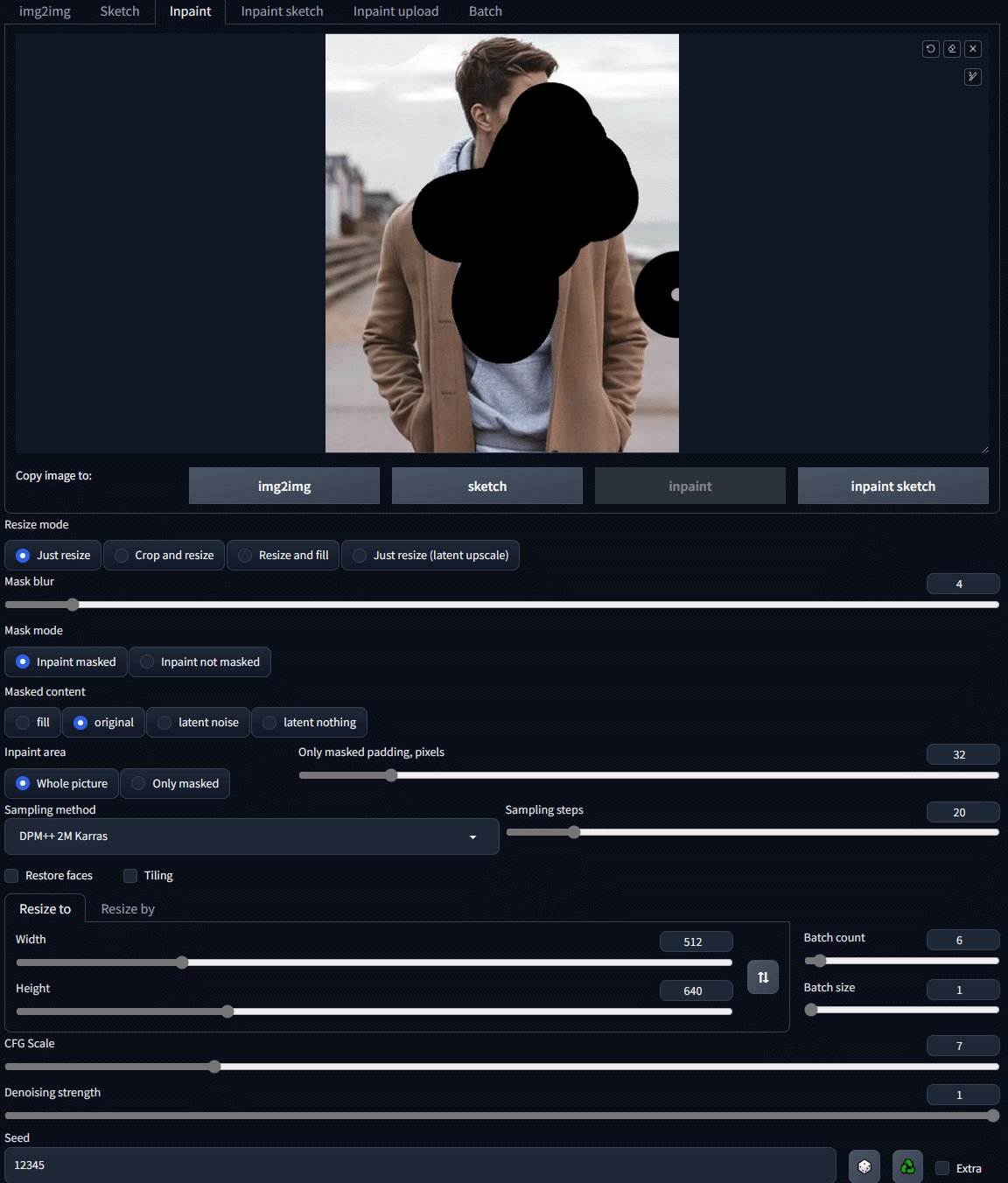

img2imgのインペイントのみ(ControlNetオフ)

img2imgのインペイント&ControlNet

img2imgのインペイントのみ(ControlNetオフ)
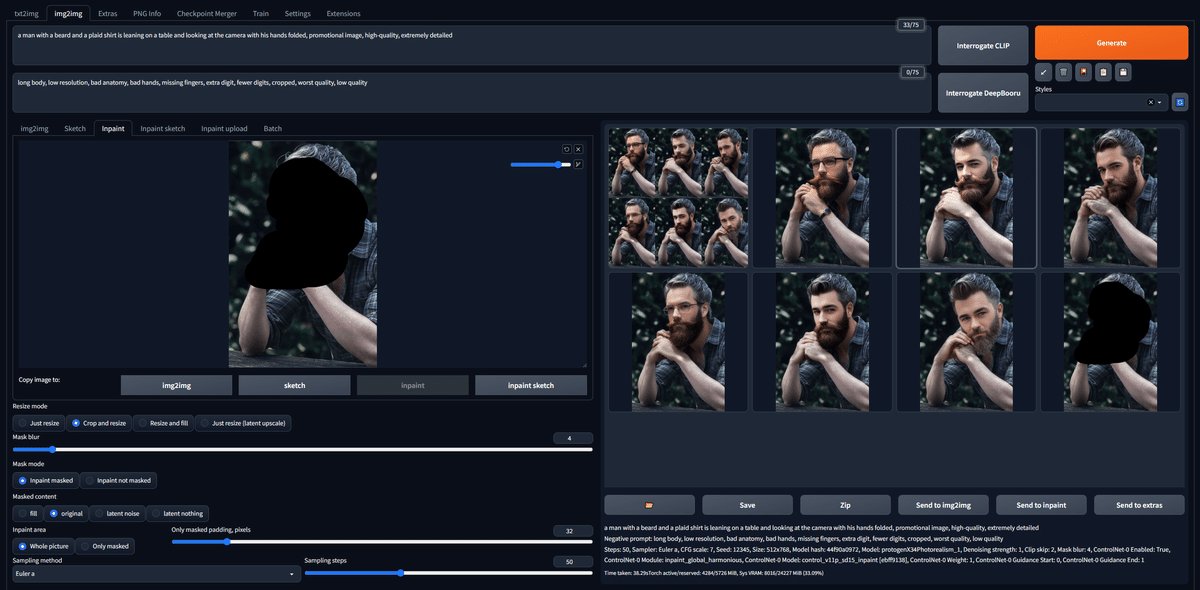
img2imgのインペイント&ControlNet


もちろん、このように背景にも効果的です。


プロンプト:girl , upper body , cute , smile
Seed固定
横軸のinpaintは、「inpaint_global_harmonious」のことです。
Weightが0.1だと、インペイント付近の境界が目立ちますが、それ以降は上手くいっています。
表情を変える程度だと、Weightの値は低めで良さそうです。

プロンプト:girl , upper body , cute , angry, teeth
ネガティブ:low quality , nude , cross-eye
Seed固定

ネガティブ:low quality , nude , cross-eye
Seed固定
こちらは、
・img2imgに元からあるInpaint
・ControlNetのInpaint
を使いました。結果は、これに関してはControlNetとほぼ変わりませんでした。
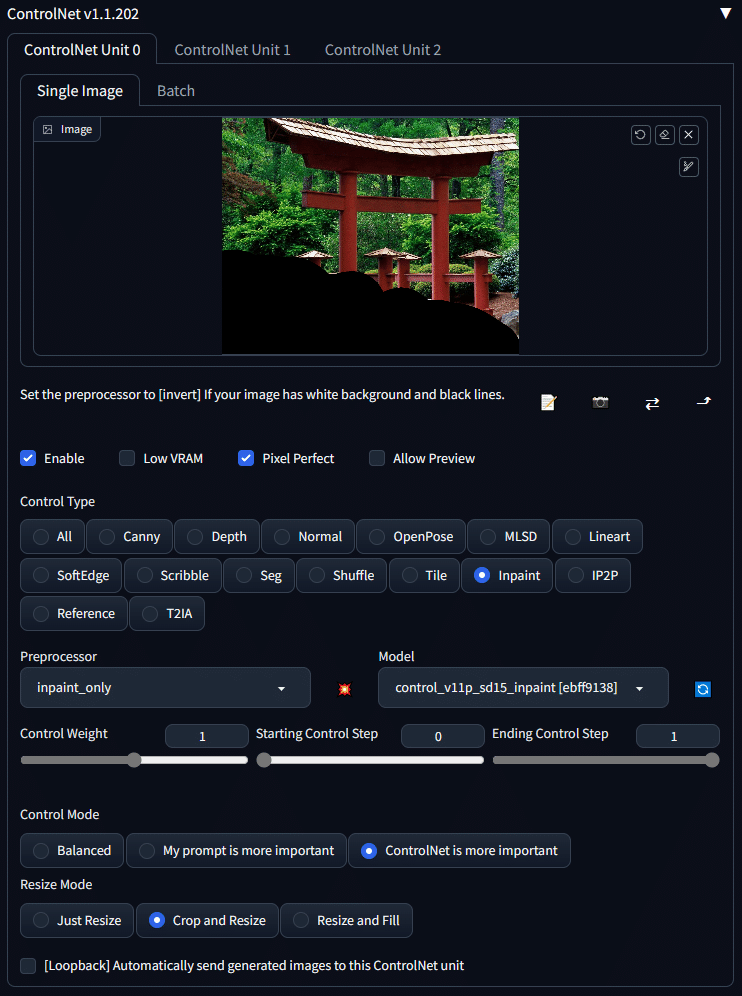
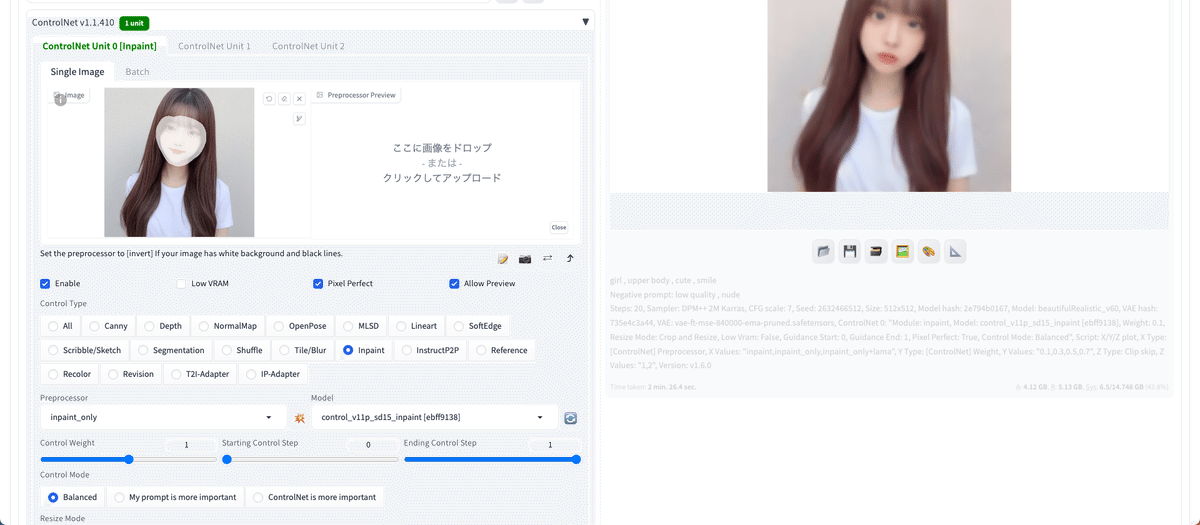
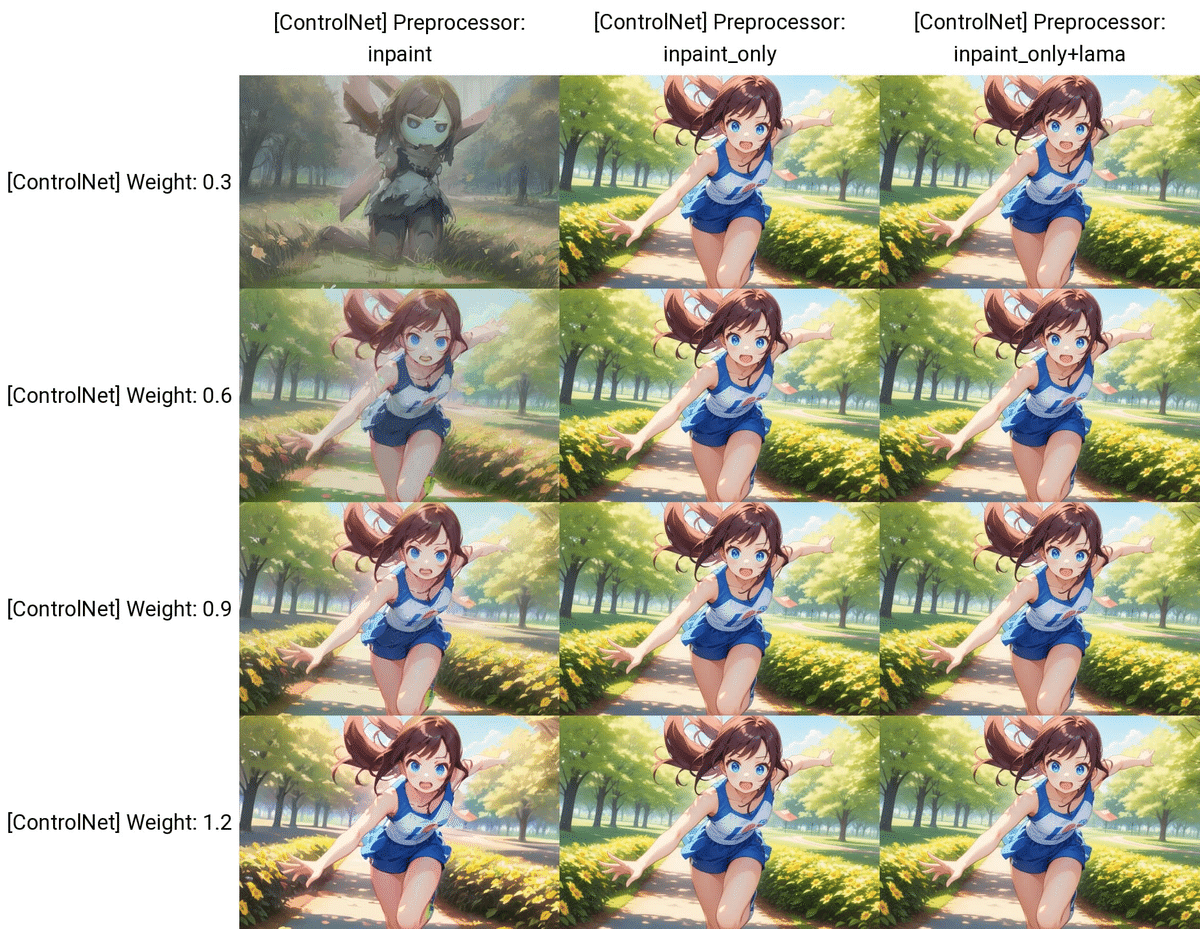
ControlNetのInpaintは3つあり、その特徴は、以下のとおりです。
inpaint_global_harmonious:マスクしていない部分もAIが調整するので色味が変わる
inpaint_only:マスクした部分のみ変更する
inpaint_only+lama:マスクした部分のみ変更する。特に物体の除去に適している
inpaint_global_harmoniousでは、色味が変わる特徴があります。個人的には、 inpaint_only か inpaint_only+lama がおすすめです。
他の画像でも試しました。


img2imgのInpaintは悪くはありませんが、絵の破綻はControlNetのInpaintよりも起きやすいです。
・img2imgのInpaint
・ControlNetのInpaint
これらはどちらも、元の画像に変化を加える機能です。元画像の線画を変えないまま、色だけを変えたい場合は、CannyやLineartなどを使ってください。
□ Inpaintで何かを追加する


img2imgでは、画像の中に何かを追加しようとしても、あまり追加してくれません。これは
・img2imgのInpaint
・ControlNetのInpaint
のどちらでも同じです。画像の中に何か追加したいときは、txt2imgでのControlNetのInpaintを使うのがおすすめです。
□ Control Inpaintで不要物の除去

この画像の左胸あたりに、余計なものが入ってしまったため、これをInpaintで除去します。

不要物をマスクします。今回は、プロンプトを何も入れずに生成しましたが、画像のように上手くいきました。不要物が無くなっているのが分かります。

左腕部分の服のほつれを直しました。
不要物の除去は、毎回うまく行くわけではありませんが、何度か試したり、プロンプトを変えることで修正が可能です。
□ ControlNetのInpaintでアウトペイントする


inpaint_only

inpaint_only+lama
ControlNetのInpaintは、アウトペイントにも使うことができます。
ControlNetのアウトペイントは、txt2imgのControlNetを使います。img2imgの方のControlNetでは、上手くいきませんでした。
また、アウトペイントでは、Resize Modeを「Resize and Fill」にします。これで、画像サイズを変えた分の余白を埋めてくれます。
境界部分が目立つこともあるので、パラメータで調整します。

プロンプト:girl , standing , cute
ネガティブ:low quality , nude
Seed固定
どれも境界部分が目立ちますが、以下のimg2imgのアウトペイントよりは、ControlNetの方がクオリティは高い印象です。

プロンプト:girl , standing , cute
ネガティブ:low quality , nude
Seed固定

プロンプト:girl , standing , cute
ネガティブ:low quality , nude
Seed固定
img2imgのアウトペイントは、アウトペイントの方向を上下左右の4つ選ぶことができます。しかし、精度はあまり良くありません。
他の画像でも試しました。

Control Modeは、ControlNet is more importantの方が上手くいきました。特に、inpaint_only+lamaが良いですね。
アウトペイント機能は、ControlNetのおかげで、とても改善しました。しかし、発展途上でもあると感じたので、もう少し開発を待った方が良さそうです。
■ InstructP2P (Instruct Pix2Pix)

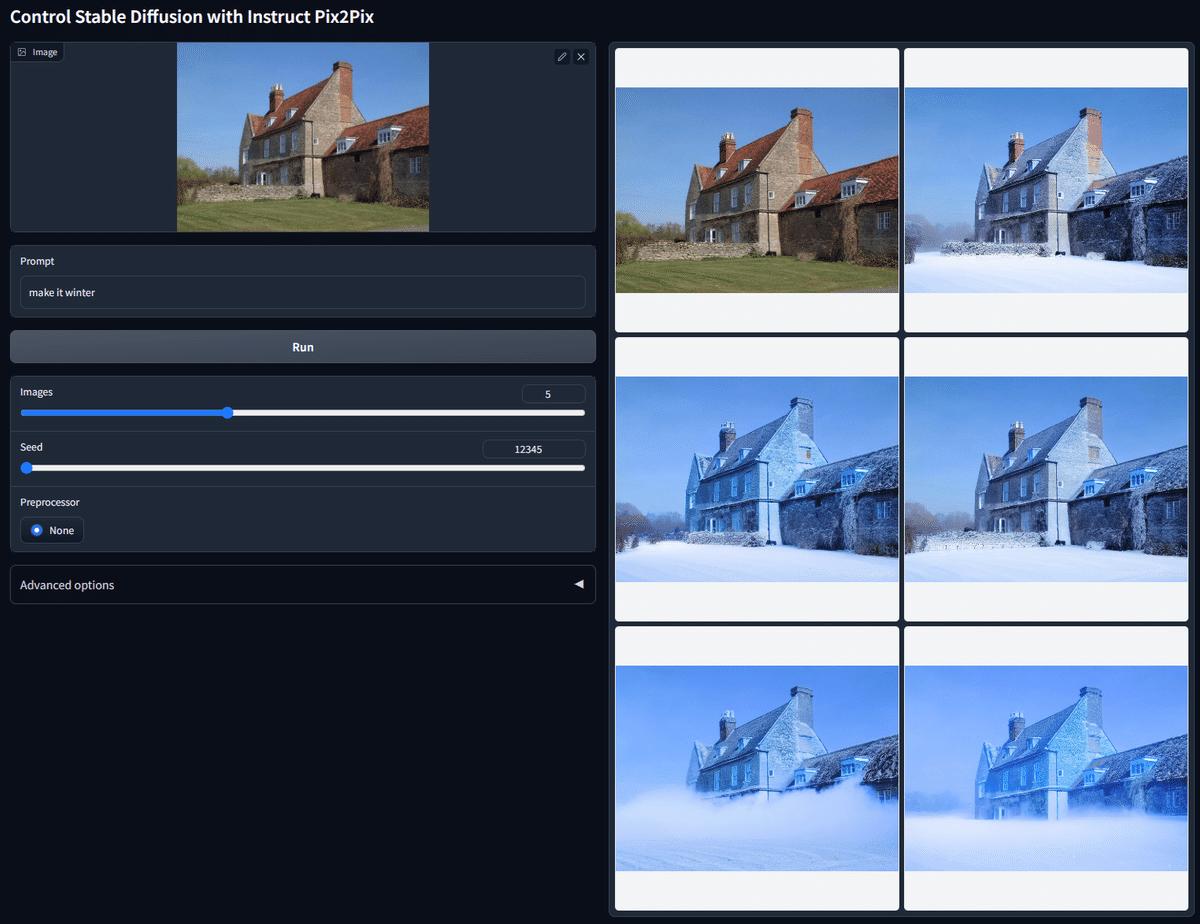

InstructP2P(Instruct Pix2Pix)では、元画像の一部を指示した内容に変更し、画像生成することができます。上の画像を見てもらえれば、どんなことができるか、だいたい分かるはずです。InstructP2Pは、元画像の全体を大胆に変えたいときに便利です。
一方で、元画像の一部だけ微調整したい場合には、InstructP2PよりもInpaintなどの方が向いています。例えば、キャラクターの見た目を保ったまま一部だけ微調整したい場合は、CannyやInpaint、Referenceの方が有効です。
InstructP2Pでは、Preprocessorは不要なので「none」で大丈夫です。InstructP2Pでは、プロンプトは「Xにして」のように入力します。

プロンプト:Make her angry
右は元画像のSeed
txt2imgでは、元画像から離れてしまい、使い物になりませんでした。img2imgでは、元画像をある程度保てていますが、怒り顔にするのは上手くいっていません。InstructP2Pというよりは、Stable Diffusionで、表情を変えるのはまだ難しいです。

プロンプト:Put glasses on her
右は元画像のSeed
こちらは、メガネをかけさせました。

プロンプト:Put her in a business suit
右は元画像のSeed

プロンプト:Put her in a business suit
右は元画像のSeed
ビジネススーツを着せました。元画像と同じSeedを使った方は、ほとんど変化がなかったです。一方で、Seedを固定しないと、元画像と顔が変わってしまうので、InstructP2Pは扱いが難しいです。
Seedを固定すると、なぜか画像がガビガビになってしまうのが気になりました。


プロンプト:Make her angry
右は元画像のSeed

プロンプト:Make her angry
右は元画像のSeed

プロンプト:Put glasses on her
右は元画像のSeed
イラスト系は表情が変わりやすいですが、元画像からは離れるので、一貫性は期待できません。

ちなみに、txt2imgのInstructP2Pでもインペイントできますが、インペイントした範囲以外もなぜか変更を加えられます。しかし、img2imgのインペイントを使うと、インペイントした範囲内で変更してくれます。画像の一部だけを変更したいときは、img2imgのインペイントと合わせてInstructP2Pを使ってください。

□ Multi ControlNet
InstructP2Pでは、元画像から大きく変更されます。キャラクターなど、あまり変えたくない場合は、Multi ControlNetを使うのがおすすめです。
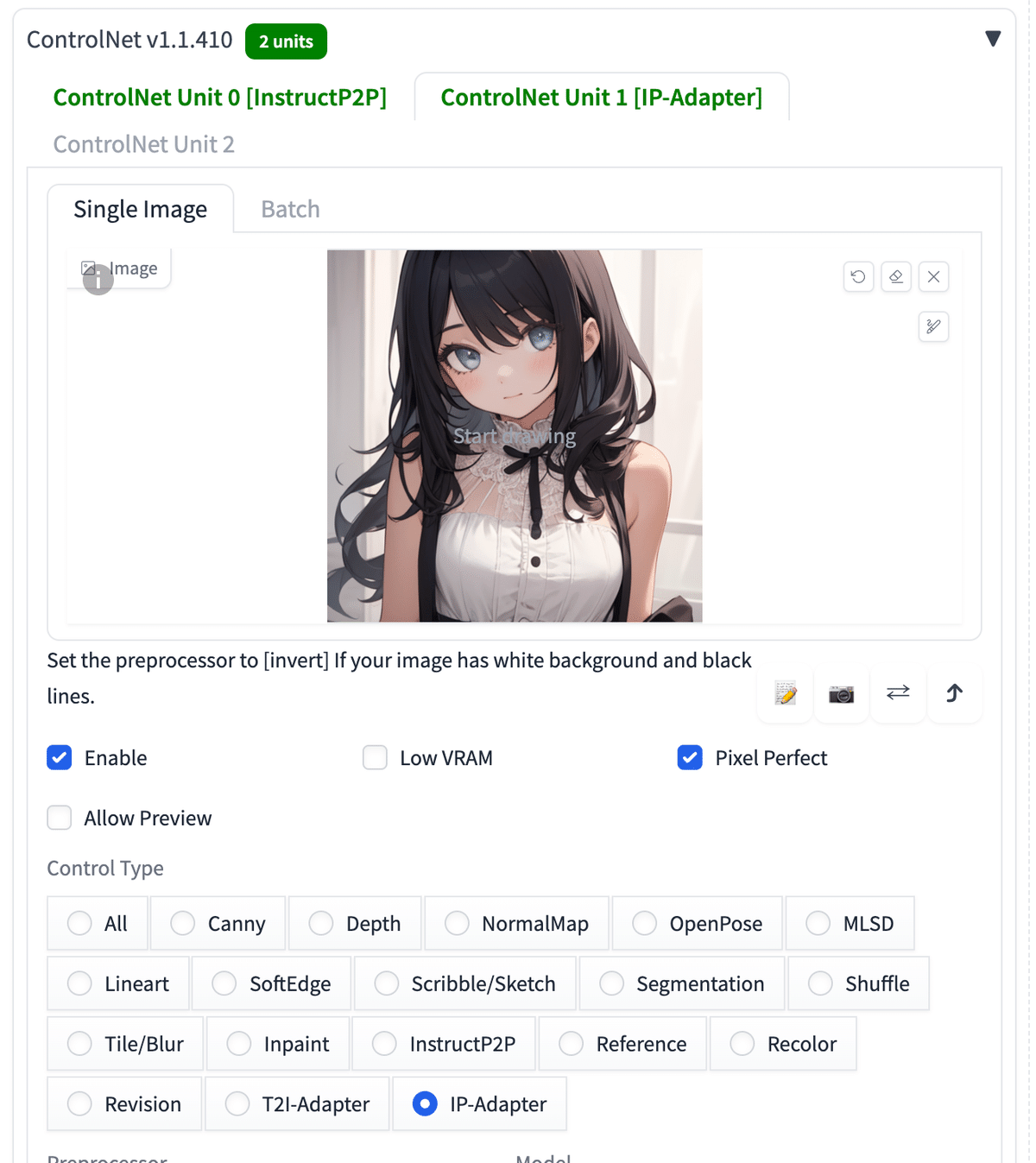
例えば、このように
・ControlNet Unit0にInstructP2P
・ControlNet Unit1にIP-Adapter
を設定しています。影響度合いは、それぞれのControl Weightなどを調整してください。
IP-Adapterは、別の動画で説明しますが、元画像の特徴を維持しつつ新たな画像を生成できるControlNetです。

プロンプト:Make her angry
ネガティブ:low quality, ugly
右は元画像のSeed

プロンプト:Put her in a business suit
ネガティブ:low quality, ugly
右は元画像のSeed

プロンプト:Make her angry
ネガティブ:low quality, ugly
右は元画像のSeed

プロンプト:Make her angry
ネガティブ:low quality, ugly
右は元画像のSeed
InstructP2Pだけよりも、Multi ControlNetの方が上手くいきました。同じキャラを保ったまま変更を加えるには、
・Seedの固定
だけではなく、
・インペイントで部分的に変える
・Multi ControlNetで、IP-Adapterを使う
などの工夫が必要です。
□ InstructP2P (Pix2Pix)と、ControlNetのInpaintの比較
リアル系の表情の表現は、AIではまだ難しいので、服装の変化で比べます。
InpaintとInstructP2Pのどちらも、インペイントしていますが、InstructP2Pではマスクした範囲以外も変わってしまいました。

プロンプト:Put her in a business suit
ネガティブ:low quality, ugly
右は元画像のSeed
プロンプト:Put her in a business suit
ネガティブ:low quality, ugly
右は元画像のSeed

プロンプト:Put her in a business suit
ネガティブ:low quality, ugly
右は元画像のSeed
服装をスーツに変更するという試みを、ControlNet InpaintとInstructP2Pで比較しました。Inpaintでは、顔の変化が少ないですが、InstructP2Pでは顔も顔以外の変化も大きいです。

プロンプト:Make her angry
ネガティブ:low quality, ugly
右は元画像のSeed

プロンプト:Make her angry
ネガティブ:low quality, ugly
右は元画像のSeed

プロンプト:Make her angry
ネガティブ:low quality, ugly
右は元画像のSeed
イラスト系では、リアル系よりも表情の表現がしやすいので、怒り顔を試しました。
こちらも、InstructP2Pの方が、ControlNet Inpaintよりも変化が大きかったです。変化が大きいと、その分、キャラが別人になってしまったり、絵が破綻することが増えます。そのため、InstructP2Pは、元画像を保ったまま変更するというよりは、全体をざっくり変えたいときに便利だと感じました。微調整したいときは、ControlNet Inpaintの方がおすすめです。
■ Shuffle


Shuffleでは、元画像を一旦グニャグニャに溶かし、それを元に新しい画像を生成できます。



このようにShuffleでは、元画像から大きく離れた画像が生成されます。元画像と全く異なるという訳ではなく、要素は少し残したまま画像生成されます。今回だと、元画像と色合いが近いです。


□ Shuffleの使い方
今までの比較のために同じ画像を使いましたが、Shuffleでは人物画像を元画像として入れることはあまり効果的ではありません。正解は1つではないので、ヒントになりそうな事を残しておきます。



プロンプト:1girl
ネガティブ:low quality
プロンプトが「1girl」だけなのに、元画像の特徴がある高品質な画像が生成されます。
普通はこのような画像生成するためには、色々とたくさんのプロンプトを書く必要がありますが、それをShuffleが代わりに行ってくれるイメージです。
Weightの値は、上げると絵が破綻するので、控えめにしてください。



プロンプト:1girl
ネガティブ:low quality



プロンプト:1girl
ネガティブ:low quality
元画像に「白い画像」を使うと、簡単に白背景の画像を生成することができます。
□ Shuffleとimg2img
元画像から離れた画像が生成されるShuffleですが、img2imgと合わせて使えば、一貫性を保ったまま画像生成をすることができます。
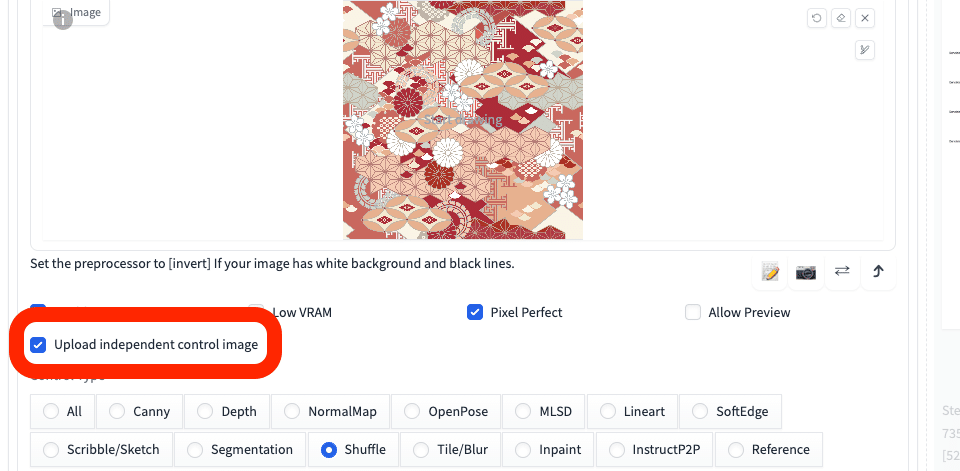

プロンプト:1girl
ネガティブ:low quality
プロンプト:1girl
ネガティブ:low quality
txt2imgのときと比べると、元画像を保っているのが分かります。ただしShuffleは、コントロールするのが難しく、扱いづらいと感じます。

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw

プロンプト:A beautiful girl running towards the camera with her hand stretched out. She has a gentle but powerful expression and a cute appearance. The background is a sunny park with trees and flowers. kawaii
ネガティブ:(worst quality, low quality:1.3), (monochrome, grayscale, poorly eyes, (bad hands:1.2), watermark, username:1.2), nsfw
Seed固定
□ Shuffle番外編

ちなみに、Preprocessorは「none」にして生成しても、それなりに良い結果が得られます。

また、プロンプトを入れずに生成しても、元画像の雰囲気を保った別の画像が得られます。フリー素材づくりに役立ちそうです。
■ 一貫性の保持編 ■
■ Reference

出典:[New Preprocessor] The "reference_adain" and "reference_adain+attn" are added


出典:[Major Update] Reference-only Control

Referenceでは、元画像の見た目を保ったまま、画像生成することができます。例えば、同じキャラクターのまま、別の服装やポーズ、表情などを作ることが可能です。
(Referenceは、簡易的なLoRAだと考えると、分かりやすいかもしれません。)

プロンプト:girl , standing , cute , business suit , office
ネガティブ:low quality , nude
右は元画像と同じSeed。左はランダム
Referenceを使えば、Seedの固定なしでも、元画像に近い画像を生成することができます。
とはいえ、似ているか微妙な部分もあり、絵の破綻も目立ちます。特にリアル系では、後で紹介するIP-Adapterの方がおすすめなので、そちらも読んでください。
Referenceには、Preprocessorが3つあります。特にリアル系では、reference_adain+attnが1番よかったです。

プロンプト:girl , standing , cute , business suit , office
ネガティブ:low quality , nude
右は元画像と同じSeed。左はランダム
これは、img2imgのみで、ControlNetは使っていない画像です。
img2imgでも、元画像に近い画像はある程度生成できますが、「元画像とは別人かな」という印象です。服装や場所などの変更を大きくするほど(Denoising strengthを上げるほど)、元画像の人物からは離れてしまいます。Seedを固定しても、元画像の人物とは違う顔になりがちです。

プロンプト:1girl, office, business suit,sitting
ネガティブ:low quality
右は元画像と同じSeed。左はランダム
イラスト系では、リアル系と比べると、元画像のキャラに近くて破綻も少ない画像が生成できました。

プロンプト:1girl, office, business suit,sitting
ネガティブ:low quality
右は元画像と同じSeed。左はランダム
ちなみにimg2imgだと、元画像に引っ張られてしまいます。絵を変えたい場合、Referenceはtxt2imgで使ってください。
□ Referenceの使い道
Referenceの使い道は、とても多いです。
同じキャラで色々な絵を作りたいとき、ControlNetが出る前までは、
・Seed固定
・img2img
くらいしか方法がありませんでした。どちらも、元画像からポーズを変えるなどの大きめの変更をすると、キャラが元画像から離れてしまい、一貫性を保つのは難しかったです。
そこで、例えば
・元画像のキャラを保ちつつ
・ポーズも保ちたい
場合は、
・Reference
・OpenPose(またはDepth、Scribbleなど)
のように組み合わせるのが効果的です。
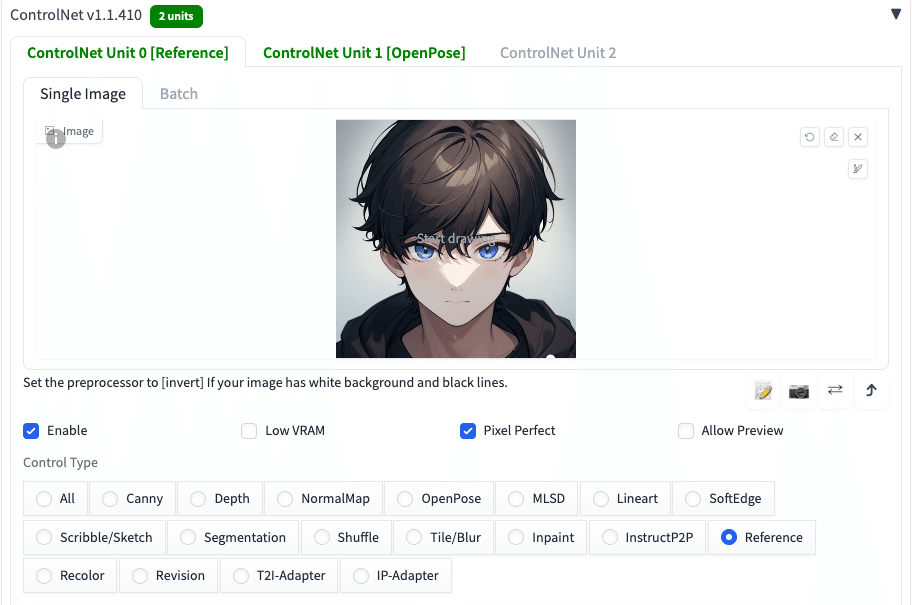


プロンプト:1boy, fist pump, combat sports, match venue
ネガティブ:low quality, monochrome, low-glamour, plain clothes
このように、ある程度、元画像のキャラを保ったまま、特定のポーズを取らせることができています。
別の画像でも試しました。
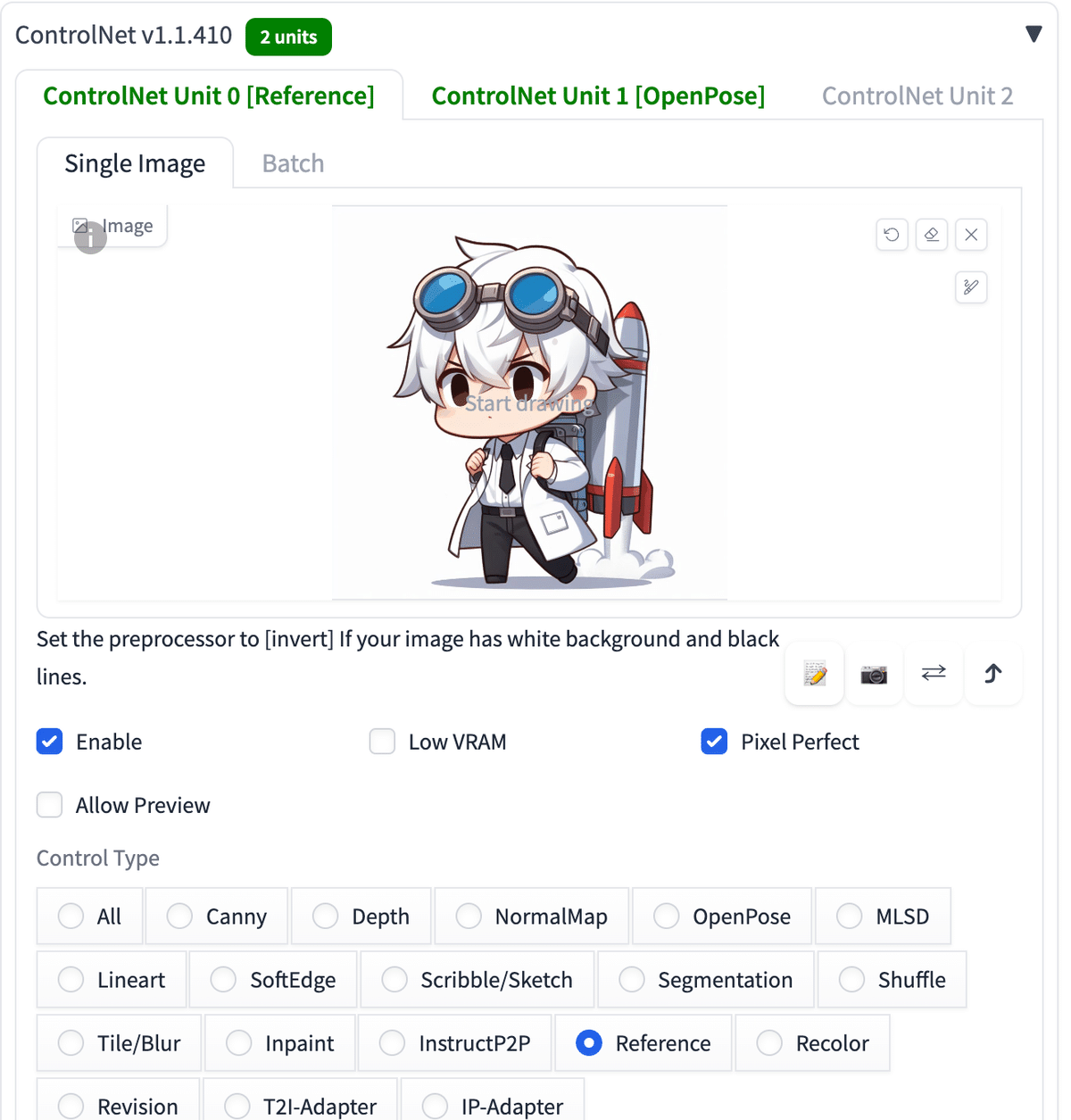


プロンプト:a man , upper body, chibi , naturally curly hair, white hair, (blue goggles on the head:1.2),Experiments in the school science lab
ネガティブ:low quality, glasses
こちらは、Scribbleで、キャラのシルエットを引き継がせました。
落書きから絵を作ってくれるScribbleですが、WeightなどでControlNetの影響度を上げるとCannyやLineartに近くなります。「シルエットを引き継ぎたい」くらいの場合は、あまりWeightを上げないのがおすすめです。
シルエットならDepthも効果的ですが、今回の場合は、Scribbleの方が上手くいきました。
■ IP-Adapter




プロンプト:1girl, standing
ネガティブ:low quality, nude

プロンプト:1girl, standing
ネガティブ:low quality, nude
IP-Adapterでは、元画像をプロンプトの代わりとして利用し、元画像の特徴を維持しつつ新たな画像を生成できます。Referenceと似た機能です。
上の画像では、プロンプトは「1girl, standing」だけで、和室を連想させる言葉は入れていません。しかし、和室の画像が生成されています。このことから、元画像がプロンプトのように機能しているのが分かります。

プロンプト:girl , standing , cute , business suit , office
ネガティブ:low quality , nude
右は元画像と同じSeed。左はランダム
完璧ではありませんが、元画像の人物と似ている、別の絵を生成できています。
IP-Adapterでは、Weightの値が低くても、ControlNetの効果はけっこうあります。Weightの値を上げても変化は少なかったです。

プロンプト:1girl, office, business suit, sitting
ネガティブ:low quality
右は元画像と同じSeed。左はランダム

プロンプト:1girl, office, business suit, sitting
ネガティブ:low quality
右は元画像と同じSeed。左はランダム
破綻が少しありますが、キャラ自体は、元画像と似ています。
□ ReferenceとIP-Adapterの比較
ReferenceとIP-Adapterは似ているので、比較してみます。
プロンプト:girl , standing , cute , business suit , office
ネガティブ:low quality , nude
右は元画像と同じSeed。左はランダム
プロンプト:girl , standing , cute , business suit , office
ネガティブ:low quality , nude
右は元画像と同じSeed。左はランダム
リアル系の画像では、
・Referenceは破綻が多い
・IP-Adapterの方が、画像のクオリティが高い
印象です。とはいえ、この2つは重要かつ頻繁に使う機能なので、両方とも試してみてください。
プロンプト:1girl, office, business suit,sitting
ネガティブ:low quality
右は元画像と同じSeed。左はランダム
プロンプト:1girl, office, business suit, sitting
ネガティブ:low quality
右は元画像と同じSeed。左はランダム
イラスト系では、どちらも元画像のキャラに似ていると感じました。好みの問題かなと思います。
□ IP-Adapterの使い道
IP-Adapterの使い道は、Referenceと同じです。


プロンプト:1boy, fist pump, combat sports, match venue
ネガティブ:low quality, monochrome, low-glamour, plain clothes
Seed:1

プロンプト:1boy, fist pump, combat sports, match venue
ネガティブ:low quality, monochrome, low-glamour, plain clothes
Seed:1
結果は、それなりに上手くいきました。元画像のキャラにより近いのは、IP-Adapterでした。試してみてください。
ControlNetを2つ使う場合、Control WeightなどでControlNetの影響度を調整する必要性が増えます。例えば、Weightが大きすぎると、プロンプトの内容が反映されなくなってしまいます。
□ IP-Adapterの応用
ControlNet InpaintとIP-Adapterを組み合わせる方法を説明します。
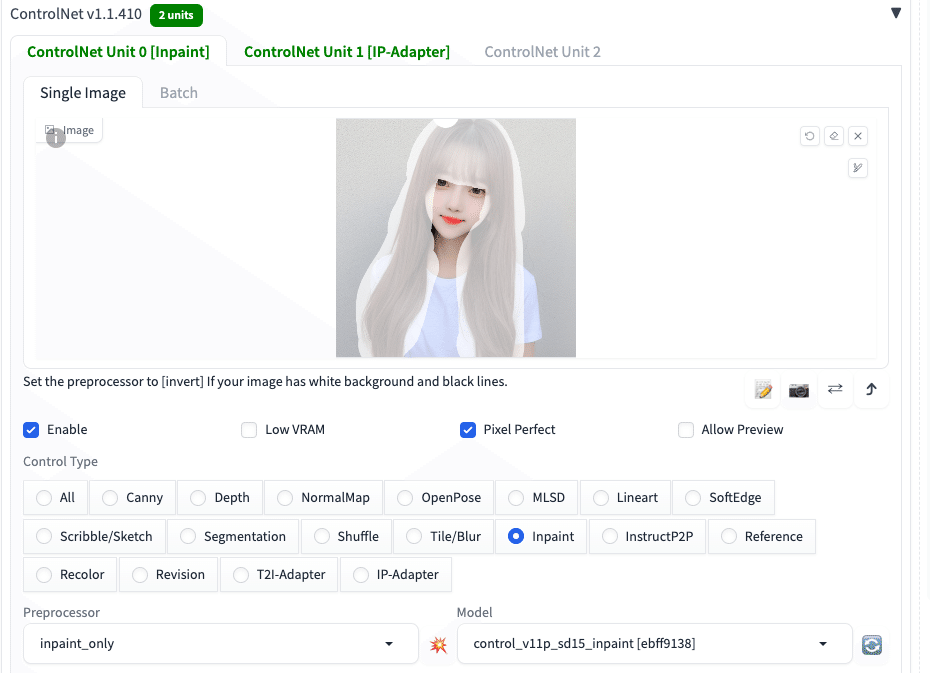
まずは、Inpaintで変えたい部分をマスクします。
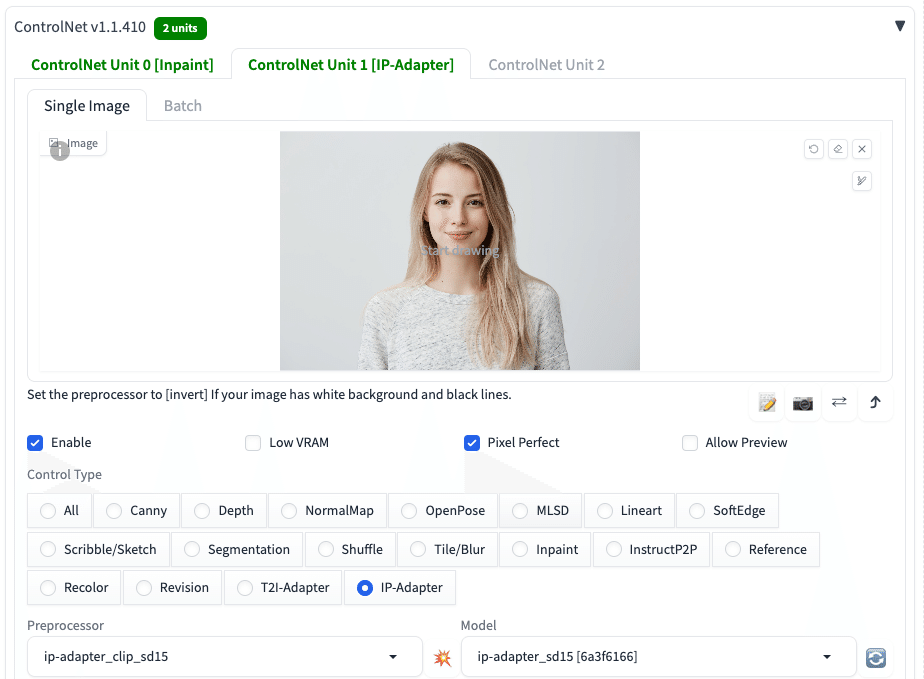
次に、プロンプトの代わりとして、画像をControlNetに設定します。

プロンプト:1girl, upper body
ネガティブ:low quality
前髪が無くなり、髪色も変えることができました。
こんな感じで、髪型だけ変えたいときに、IP-Adapterを応用できます。この方法は特に、
・プロンプトが思い浮かばない
・プロンプトが画像に反映されない
ときに効果的です。IP-Adapterでは、画像をプロンプトとして使うことができます。

プロンプト:1girl
ネガティブ:low quality
右は元画像と同じSeed。左はランダム
こちらは、img2imgのInpaintです。こちらでも可能ですが、ControlNetよりも多くの微調整が必要になり、やや面倒です。
破綻している画像もあるので、パラメータで調整してください。

プロンプト:1girl, upper body
ネガティブ:low quality
ちなみにReferenceだと、こんな感じです。これに関しては、IP-Adapterの方が優秀です。

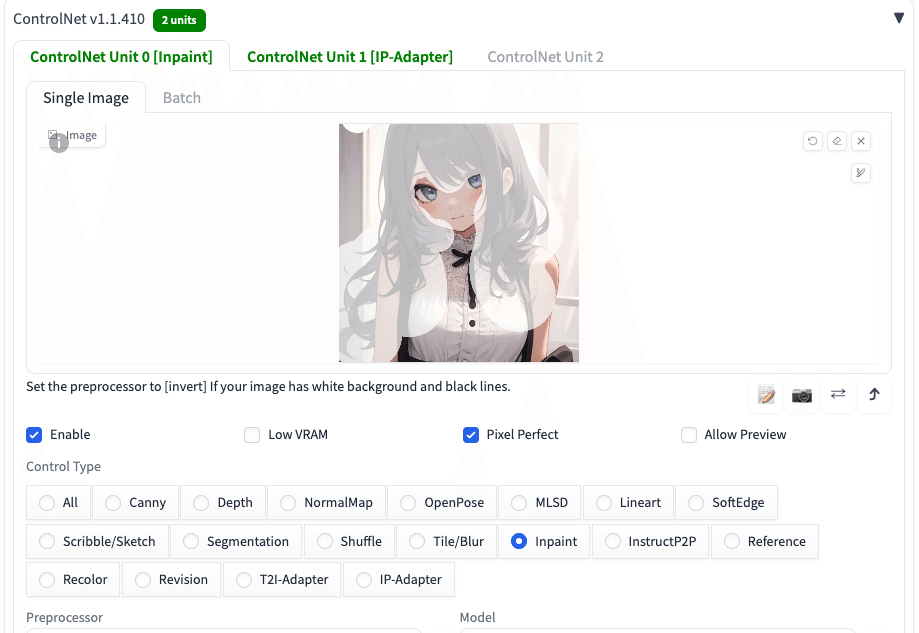

プロンプト:1girl, upper body
ネガティブ:low quality
こちらもやりたいことは、まぁまぁ成功しています。
この方法は、髪型の名前が分からないときなどに、とても有用です。

プロンプト:1girl, upper body
ネガティブ:low quality
こちらも、Referenceだと上手く行っていません。
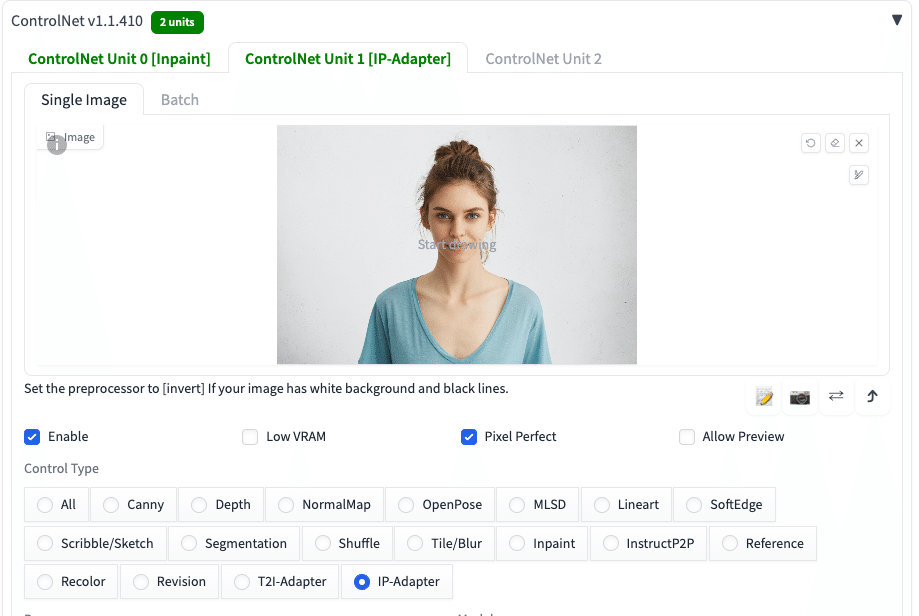

プロンプト:1girl, upper body
ネガティブ:low quality
髪型が、元画像と大きく異なると、上手くいきませんでした。髪型は、できるだけ近いものを選んでください。
次は服を変えてみました。

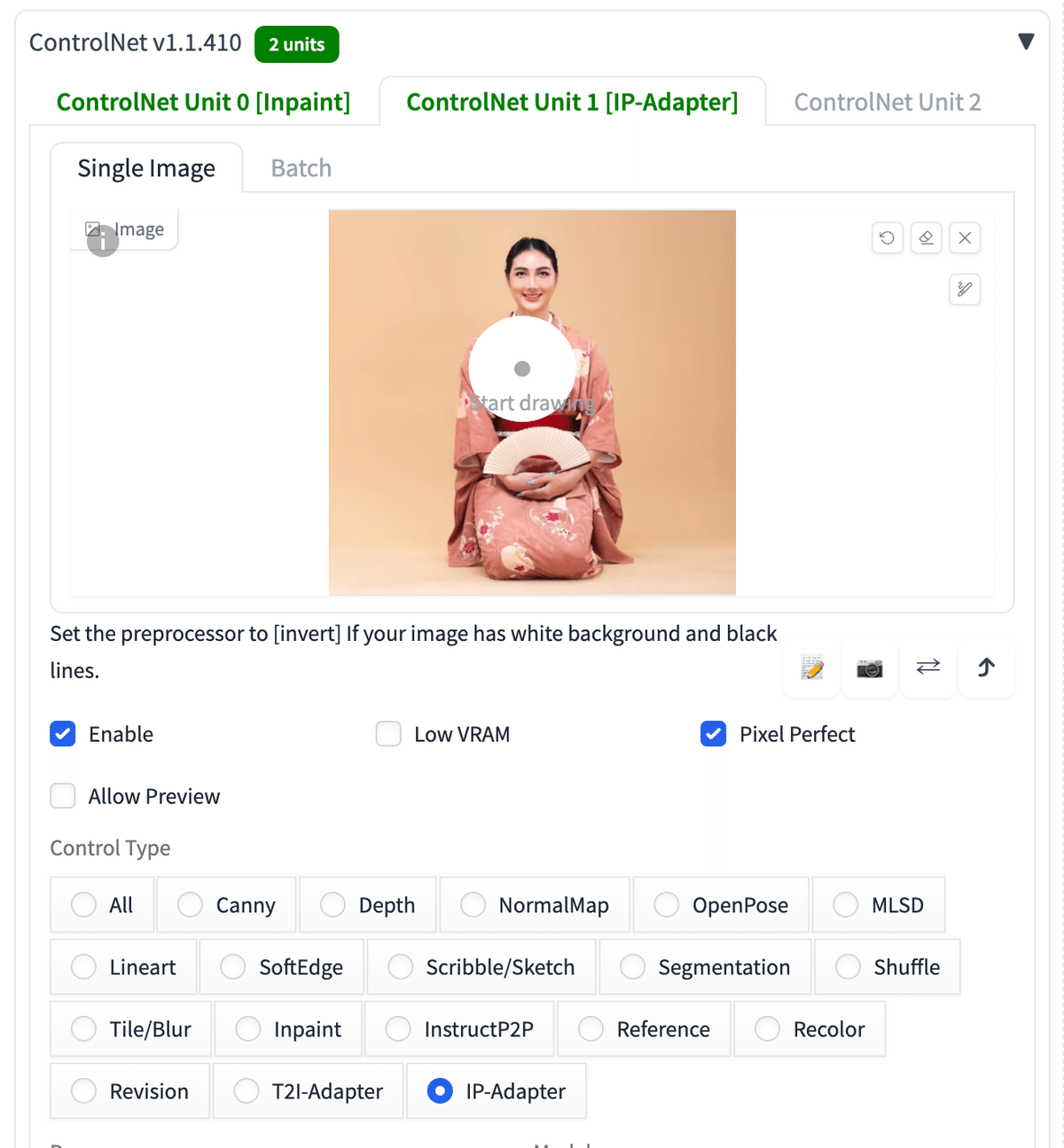

プロンプト:1girl, upper body
ネガティブ:low quality
このように、2つの元画像の構図が異なる場合は、上手く行かせるのは難しいです。今回の例では、服の画像は、元画像の人物に近いポーズ / 姿勢のものを、できるだけ選んでください。
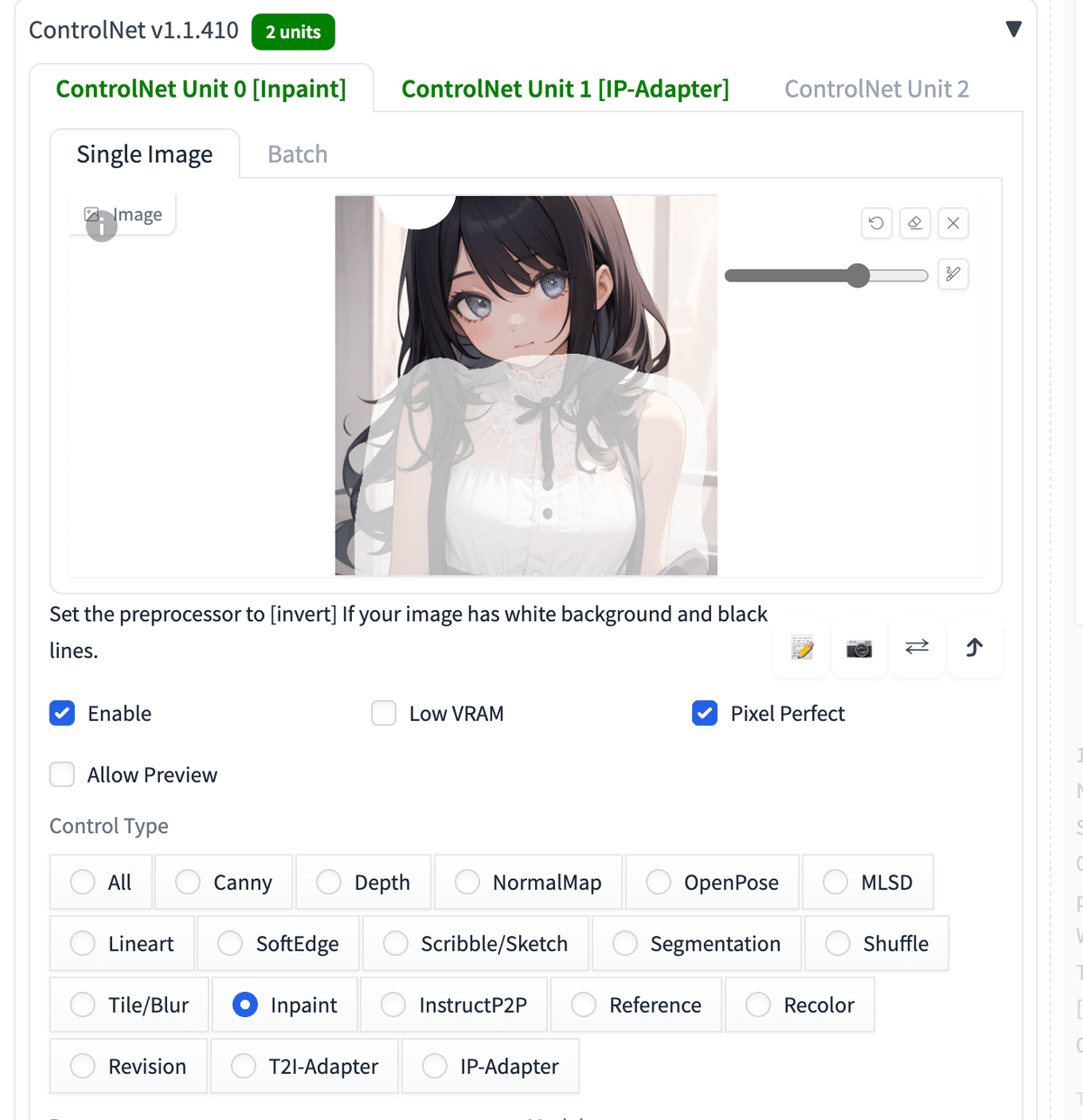

プロンプト:1girl, upper body
ネガティブ:low quality
ちなみに服に関しても、ReferenceよりもIP-Adapterの方が上手くいきました。
□ 他の例と、参考サイト
他の例として、開発者のページを紹介しておきます。

こちらは、img2imgに女性の画像を設定し、ControlNetに海岸や小石の画像を設定し、画像生成したものです。
結果は、女性の形をした海岸になったり、女性の雰囲気のある石が並べられたりしています。

こちらは、もとの画像の顔だけをimg2imgのInpaintでマスクし、ControlNetに上の2つの画像をそれぞれ設定したものです。
結果は、元画像のインペイントした部分だけが、ControlNetに設定された画像の特徴を反映しています。
■ Tile / Blur
Tile/Blurでは、元画像の見た目を保ったまま、細部を改善しながら画像の拡大をすることができます。
Hires.fixでも画像拡大は可能ですが、元画像から離れた画像が生成されがちです。
元画像をできるだけ残し、画像の拡大をしたい場合は、ControlNetのTileを使ってください。
この画像を2倍のサイズに拡大しました。

Seed固定
プロンプト:girl , upper body , cute
ネガティブ:low quality , nude
(以下全て同じ)



元画像とほぼ同じまま、画像の拡大ができています。
私が試したところ、元画像に近かかったのは、tile_colorfixでした。好みで選んで構いませんし、パラメータでも微調整可能です。
Seed固定

Seed固定なし
ちなみに、Seed固定は必要ではないみたいです。

プロンプト:1girl, standing, smile
ネガティブ:low quality, monochrome,plain background
これを2倍に拡大しました。

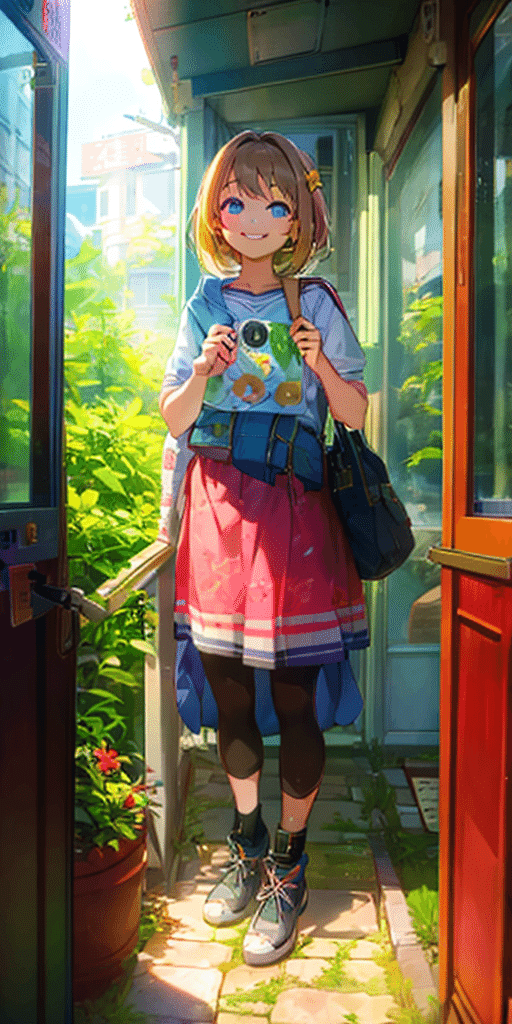
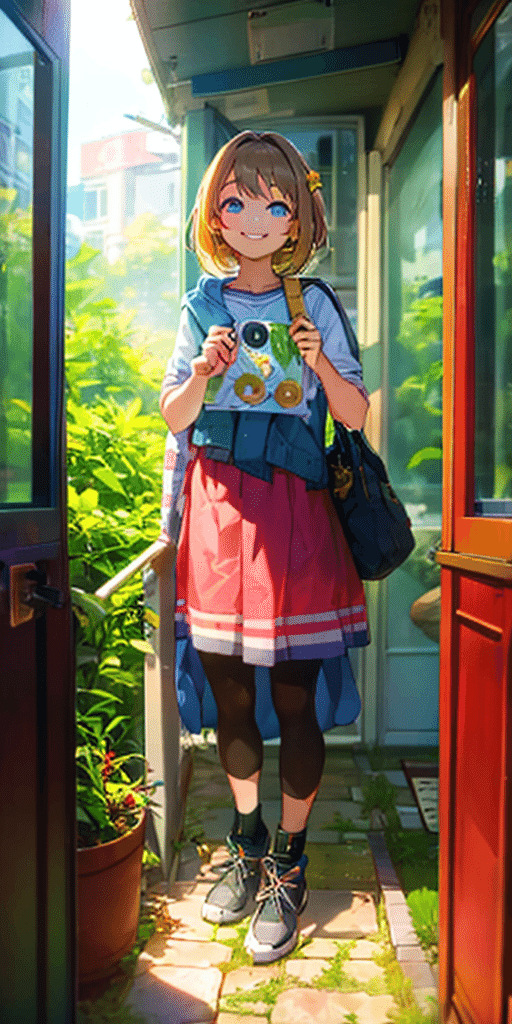
それぞれ一長一短あります。
・Hires. fix:画像の品質は良いが、元画像とは別の絵になってしまっている
・Tile:元画像と同じ絵を保てているが、画像の品質が少し劣る
とはいえ、今のところ、元画像の絵と同じまま画像を拡大するには、ControlNetを使うのが良さそうです。
■ その他 ■
■ Recolor
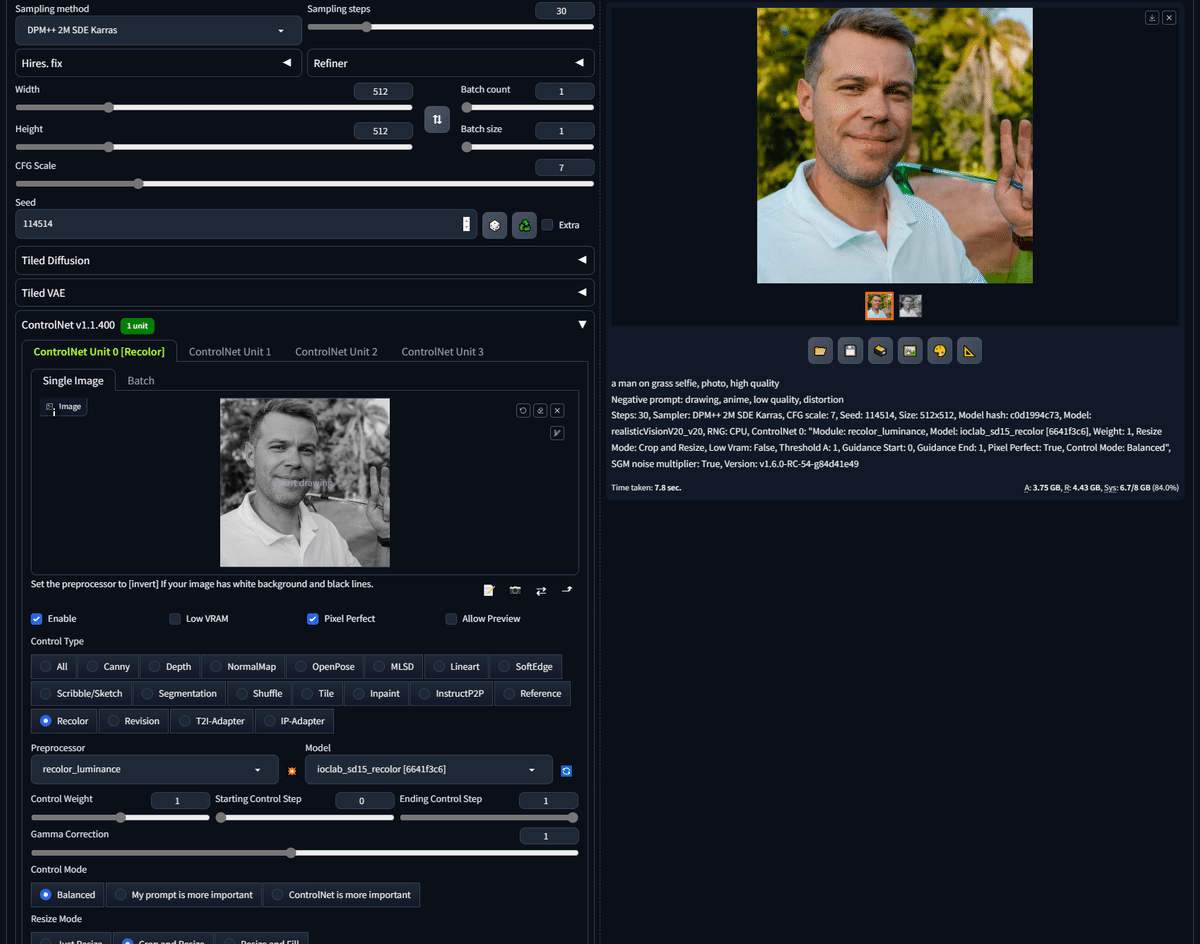
Recolorでは、元画像に合う色を自動で割り当てて、画像を生成することができます。
開発者のサイトを見た感じでは、白黒の画像に色を付けるのが、主な用途みたいです。白黒画像の場合では、上の画像のとおり、プロンプトに色情報は必ずしも必要ではないようです。
私も試してみましたが、なぜかエラーが出てしまい、生成できませんでした。アップデートを待つことにします。
白黒画像に色を付けたいという方は、あまり居ないと思うので、Recolorを使う機会は少ないと思います。実際に情報も少ないです。
色を割り当てたり変えたりする機能はたくさんあるので、Recolorに拘る必要はありません。
■ Revision

Revisionでは、元画像の特徴を持ちつつ、新たな画像を生成できます。
上の画像の開発者のサイトでは、Revisionを使い、プロンプトなしで生成されたものです。元画像から、わずかに変わっています。
Revisionは最近追加されたこともあり、情報が全然ありません。
■ T2I-Adapter
T2I-Adapterについては、よく分かりません。ControlNetと似た機能らしいです。ControlNetよりも生成速度が3倍ほど速いと言われています。
ただし情報が少なく、現在では使っている人もほとんど見かけません。そのため、当分の間は、ControlNetを使っておけば問題ないと思います。
ControlNetの基本については、以上です。全て試してもらえれば、基礎力は十分で、あとは応用していくだけです。ControlNetの応用編については、また別の動画講義で解説していきます。
この記事が気に入ったらサポートをしてみませんか?