
似た顔や特定のポーズが作れるControlNet入門【SDXLもあり】

・似たキャラクターのAIイラスト作成
・特定のポーズの表現
・同じ絵のまま画像の拡大
などをするには、ControlNetが必要です。ControlNet前編と合わせて学んでください。Stable Diffusionの始め方編・使い方編はこちら。
■ ControlNetとは?何ができる? ■
■ ControlNetとは

ControlNetとは、画像生成AIを、よりコントロール可能にする画期的な機能です。似た顔や特定のポーズ表現などを、ある程度は思い通りにでき、AIイラストを作ることができます。
■ 何ができる?具体例を紹介
✓ イラストを維持したまま、色だけ変える


✓ 落書きから画像を生成する




✓ キャラクターに特定のポーズをとらせる


✓ キャラクターの顔を維持したまま、別の画像を生成する


✓ 画像をプロンプトとして使用する


✓ イラストを維持したまま、画像を拡大する




などができます。
テキストから高品質な絵が作れるようになったのが、第1の革命なら、ControlNetでAI絵をコントロールできるようになったのは、第2の革命です。
・第1の革命:テキストから高品質な絵の生成
・第2の革命:AI絵のコントロール
■ SDXLの説明

Stable Diffusion XL(SDXL)というのは、Stable Diffusionの最新バージョンのことです。開発元であるStability AIという会社が、2023年の7月頃にSDXL1.0を公開しました。
公開されたのは、けっこう前ですが、チェックポイントなどは最近ようやく増えてきた印象です。
Stable Diffusionの他のバージョンとしては、Stable Diffusion 1.5(SD1.5)がよく使われています。Stable Diffusionはよく「SD」と略されるので、SDXLやSD1.5といったらStable Diffusionのことだと思ってください。
詳しい内容は、始め方編で書いています。
現状のSDXLのデメリットは、同じ絵が出やすい点です。SD1.5と比べると、多様性が減ったと感じています。
以下は各モデル4枚ずつ生成した結果です。




例えば、SD1.5の方がSDXLより背景がランダムです。他にも、ステップ数/CFG/Clip skipなどのパラメータの影響は、SD1.5の方が現れやすいです。
・SD1.5:暴れ馬
・SDXL:動く石像
のように感じてます。
また、SD1.5の方が、AIグラビアみたいな可愛い顔の生成が得意なので、当分の間はSD1.5の需要は続きそうです。
とはいえSD1.5は、絵の破綻や崩れが多いので、本記事ではSDXLも使っていきます。今後はSDXLが主にアップデートされていき、標準となっていくはずなので、今のうちに慣れておくのが良さそうです。可能であれば、両方とも使ってみて比較してください。
■ ControlNetの始め方
始め方や基本操作は、こちらで解説しています。
■ Reference
Referenceでは、元画像に似た画像を生成することができます。例えば、同じキャラクターのまま、別の服装やポーズ、表情などを作ることが可能です。ただし現状では「ある程度は似てるかな」くらいです。
(Referenceは、簡易的なLoRAだと考えると、分かりやすいかもしれません。)
似た機能に、IP-Adapterというものがあります。後ほど解説しますが、両方とも試してみてください。

この画像では、元画像の犬に似た画像が生成されています。



この画像で使われたプロンプトは、「1girl, best quality」ですが、顔や服装が元画像に似ていることが分かります。
img2imgでも元画像に似た画像を生成できますが、ポーズを変えるなどの大きな変化を加えるほど元画像から離れます。ControlNetのReferenceであっても大きな変化を加えるほど元画像から離れますが、img2imgよりは元画像を維持しつつ別の絵を生成できます。

出典:[New Preprocessor] The "reference_adain" and "reference_adain+attn" are added

こちらも、元画像に似た人物画像が生成されています。ただし、よく見ると違うのが分かります。
使われたプロンプトは、「woman in street, masterpiece, best quality」です。ちなみに元画像は、Midjourneyで生成されたものです。

次は、私が生成していきます。Stable Diffusionで生成した画像を使うと、Stable Diffusionのモデルを使ったから似ているのか、ControlNetの影響で似ているのか分かりにくいので、フリー素材写真も使って試します。
顔だけを似せたい場合は、顔以外の情報ができるだけ少ない画像を選んでください。

ControlNetを使うには、Enableにチェックを入れて、タイプにReferenceを選択してください。Referenceは、Preprocessorのみで使えるので、モデルは不要です。

プロンプト:girl, face, photo, japanese
ネガティブ: adult, makeup, kimono, worst quality, bad quality
今回はControlNetの効果だけを見るために、元画像に関するプロンプトはなしで生成しました。例えば、ショートヘアや顔の特徴に関するプロンプトは入れていません。
Reference onlyを使い、Weightの値を変えながら生成しました。結果は、あまり似ていないです。他のモデルでも試しましたが、あまり似ていない結果になりました。
公式ページには、ReferenceはSDXLに対応していると記載されていますが、あまり効果がないです。

ControlNetなしで普通に生成した画像はこちらです。Referenceを使った方が、元画像の人物には似ていますが、見た目はまだ別人です。

プロンプト:girl, face, photo, japanese
ネガティブ: adult, makeup, kimono, worst quality, bad quality
Referenceは3種類あるので、試してみてください。ControlNetの作者は、reference onlyとadain+attnをオススメしています(参考)。
adainとadain+attnでは、画質が悪くなってしまいました。ただし、モデルやバージョンによっては、問題ないかもしれません。

プロンプト:girl, face, photo, japanese
ネガティブ: adult, makeup, kimono, worst quality, bad quality
こちらは、SD1.5系のモデルでReferenceを使った結果です。色々なモデルでも試しましたが、SDXL系のモデルより明らかに元画像に似ています。特にPreprocessorがreference_adain+attnでは、元画像にとてもよく似ています。
ControlNetをオフにして生成した結果は、以下のとおりです。

プロンプト:girl, face, photo, japanese
ネガティブ: adult, makeup, kimono, worst quality, bad quality
Referenceは、顔以外の用途にも一応使えます。

この服装を再現できるか試した結果は、以下のとおりです。

プロンプト:photo, girl, japanese, standing
ネガティブ:adult, makeup, kimono, Japanese clothes

プロンプト:photo, girl, japanese, standing
ネガティブ:adult, makeup, kimono, Japanese clothes
Control Weightの値を上げるほど、元画像に近づいてはいますが、あまり似ていないです。他のモデルでも試しましたが、服装を再現することはできませんでした。

プロンプト:photo, girl, japanese, standing
ネガティブ:adult, makeup, kimono, Japanese clothes, black
SD1.5では、少し似ていますが、元画像の再現までは達していないです。
プロンプト:girl, face, photo, japanese
ネガティブ: adult, makeup, kimono, worst quality, bad quality
以上の結果から、Referenceは、SDXLよりもSD1.5の方が効果が出やすいです。Referenceを使うことで、元動画の顔に似せつつ、新たな画像を生成することができます。ただし、服装や髪型を維持するのはあまりできないので、IP-Adapterを使ってください。
この元画像の顔のまま、以下のように「オフィス、スーツ」というプロンプトを入れて生成することが、上手く行っていません。

プロンプト:girl, standing, photo, japanese, office
ネガティブ:adult, makeup, kimono, worst quality, bad quality
Weightを上げるほど元画像に似ますが、プロンプトで表現したいことが出てきません。Weightを下げればプロンプトの効果が強まりますが、元画像の人物には似なくなります。
同じことを、イラスト系のモデルでも試します。

この元画像は、手描きイラストのフリー素材です。3種類のReferenceを使った結果が以下のとおりです。

プロンプト:girl

プロンプト:girl
イラストについても、SD1.5の方が効果が出やすいです。とはいえ、元動画の特徴を捉えている部分とそうでない部分があり、まだ納得できるほど元画像の再現はできていません。
今回はControlNetの効果だけを見るために、
・元画像に関するプロンプトなし
・元画像はAIイラストじゃない画像
という厳し目な条件で生成しました。
元画像の特徴に合うプロンプトを入れれば、さらに元画像に似せることができます。また、写真素材や手描きイラストよりもAIイラストを使った方が、元画像に似ます。そのため、現状ではReferenceを使うときは、
・元画像に関するプロンプトを入れる
・元画像はAIイラストにする
という風に使ってください。
■ IP-Adapter
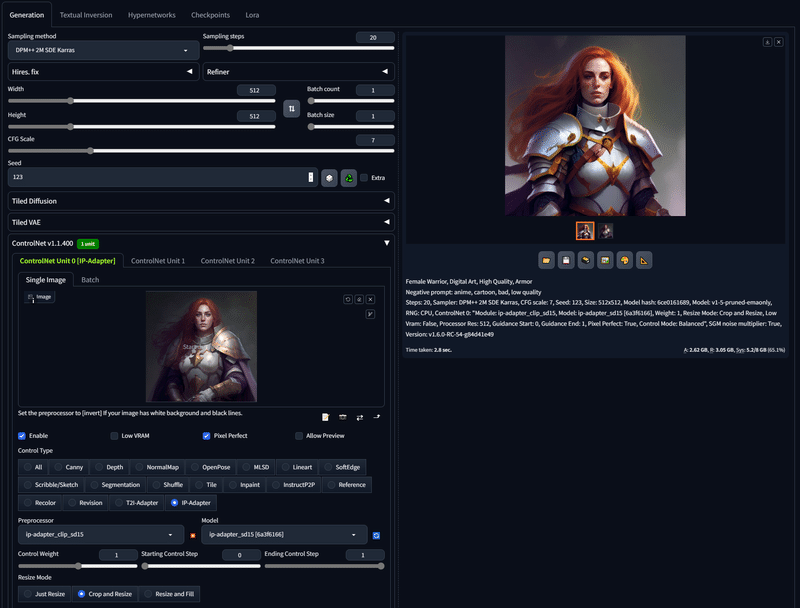

IP-Adapterでは、元画像をプロンプトの代わりとして利用し、元画像に似た新たな画像を生成できます。Referenceと似た機能です。
上の画像では、シンプルなプロンプトなのに、元画像に似た画像が生成されていることが分かります。

ControlNetを使うには、Enableにチェックを入れて、タイプにIP-Adapterを選択してください。IP-AdapterのPreprocessorとControlNetモデルは、それぞれSD1.5かSDXL用のものを設定してください。
チェックポイントで設定しているモデルに応じて、どちらかのバージョンが選択できます。例えばSD1.5のチェックポイント(モデル)を使っているなら、PreprocessorとControlNetモデルは、sd15と書かれたものが表示されて、SDXL用のものは表示されません。

プロンプト:girl, face, photo, japanese
ネガティブ: adult, makeup, kimono
Referenceのときと同じように、SDXLではIP-Adapterを使っても、元画像には似ませんでした。
また、ip-adapter_clip_sdxl_plus_vithというPreprocessorでは、変化がありませんでした。調べてみたところ、多くの人が使っているWebUIである「Stable Diffusion WebUI(AUTOMATIC1111)」では、現時点では機能しないようです。

プロンプト:girl, face, photo, japanese
ネガティブ:adult, makeup, kimono, worst quality, bad quality
同じことをSD1.5系のモデルで試しました。やはり、SDXLよりもSD1.5の方が、ControlNetの効果が現れやすいです。ただし、元画像の人物に似ているかは微妙なところで、同一人物とは言えなさそうです。髪型や服装は、けっこう似ています。
次は、この元画像の服装を、IP-Adapterを使って再現できるか試した結果です。

プロンプト:photo, girl, japanese, standing
ネガティブ:adult, makeup, kimono, Japanese clothes, black

プロンプト:photo, girl, japanese, standing
ネガティブ:adult, makeup, kimono, Japanese clothes, black
Control Weightの値を上げるほど、服装が元画像に似ているので、IP-Adapterの効果が現れていることが分かります。
ただし、ip-adapter_clip_sdxl_plus_vithというPreprocessorでは変化がありませんでした。調べてみたところ、多くの人が使っているWebUIである「Stable Diffusion WebUI(AUTOMATIC1111)」では、現時点では機能しないようです。
また、IP-Adapterの影響は大きいので、Control Weightの値が低くても、画像に効果が影響されやすいです。初期設定の1よりは、低めに設定するのがオススメです。
次は、イラスト系のモデルでも試します。
この元画像は、手描きイラストのフリー素材です。IP-Adapterを使った結果は、以下のとおりです。

プロンプト:girl

プロンプト:girl
プロンプトは「girl」だけなので、IP-Adapterの効果が現れていることが分かります。
ReferenceよりもIP-Adapterの方が、元画像に近い画像が生成されました。IP-Adapterの方が良い結果が得られることが多いので、基本的にIP-Adapterを使うのがオススメです。
□ IP-Adapterの使い道(Referenceの使い道)
IP-Adapterは、画像をプロンプトとして使うことで、元画像に似た画像を作ることができます。プロンプトだけでは思い通りにならない時や、プロンプトが思い浮かばない時に使ってください。

プロンプト:1girl, office, business suit, desk, short hair, computer, pc, monitor
ネガティブ:worst quality, bad quality, monochrome
IP-AdapterやReferenceは、同じキャラクター生成の方法として期待されますが、現時点ではまだ仕事では使えないレベルです。
ただし今回は、元画像がAIイラストではない外部の画像を使っています。そのため、モデルやプロンプトを元画像に近づけて使うことで、より似たキャラクターを作ることができます。

プロンプト:1girl, office, Black suit, desk, short hair, computer, pc, monitor, Black suits
ネガティブ:worst quality, bad quality, monochrome, white suit, white shirt
また、髪型を変えることにも、IP-Adapterは効果的です。


元画像1のキャラクターの髪を、元画像2の髪型に変えてみます。

img2imgのインペイントで、画像のようにマスクし、

ControlNetに髪型に関する画像を入れて、IP-Adapterを使います。画像をアップロードするには、「Upload independent control image」にチェックを入れてください。
・プロンプト
・Denoising strength
・Seed
などを調整することで、絵の崩れがないようにします。

このようにIP-Adapterを使い、髪型だけ変えることができました。特にプロンプトで表現するのが難しい髪型の場合に、効果的な方法です。

他には、img2imgのインペイントを使うことで、服装だけを変えることもできます。

服の部分をマスクし、

IP-Adapterで、画像のような服装を指定します。画像をアップロードするには、「Upload independent control image」にチェックを入れてください。

指定した服装とは少し異なりますが、雰囲気はある程度似せてくれます。
キャラクターを維持するという目的からは離れますが、元画像を色々変えることで、プロンプトだけで表現するのが難しい絵も作ることができます。具体例は、以下のとおりです。

IP-Adapterにお花の画像を設定することで、シンプルなプロンプト「1girl, standing, Flower Background」だけでも、以下のような結果になります。

プロンプト:1girl, standing, Flower Background
ネガティブ:monochrome, (worst quality, bad quality, low quality:2)

■ Tile / Blur
Tile / Blurは、今のところSDXL未対応なので、SD1.5系のモデルのみ使える機能です。

一応、「blur」というのが、Tileとしても機能します。そのため、SDXLでTileを使いたいときは、これを使ってください。

Tile/Blurでは、元画像の見た目を保ったまま、細部を改善しながら画像の拡大をすることができます。
Hires.fixでも画像拡大は可能ですが、元画像とは異なる画像が生成されがちです。元画像をできるだけ保ちつつ画像の拡大をしたい場合は、ControlNetのTileを使ってください。


これは、txt2imgの画面です。
ControlNetのTile/Blurを使うには、拡大したい画像を設定し、Control TypeでTile/Blurを選択します。

次に、Width/Heightで、拡大後の画像サイズを設定します。今回は、元画像が400×600サイズで、拡大後が800×1200サイズになります。もっと良い方法は、後ほどまとめて解説します。
あとは、PreprocessorやControl Weightを色々変えて試してみてください。ちなみに、Seedの固定はしなくても、元画像に近い画像が生成されます。
□ 4種類のPreprocessorの比較
Tile/BlurのPreprocessorは、4種類あります。どれを使っても良い結果が得られます。
この4種類の違いについては、公式の情報が少なくて、よく分かっていません。使っていて感じたことは、以下のとおりです。
・tile_resample:標準設定。元画像から少し変化する。
・tile_colorfix:元画像からの変化が少ない。
・tile_colorfix+sharp:パキッとした絵になる。最新のモデルであり、開発者のオススメPreprocessor。
・blur_gaussian:ボケ表現が入る。ポートレートのような感じ。





違いを見るために、Control Weightの値をやや高めの1に設定しています。通常は、0.8前後くらいで大丈夫です。
XYZ plotで比較表を作ったら、なぜかノイズが発生したので、個別に表示しています。
□ Hires.fixとの組み合わせ

ControlNetのTile/Blurは、Hires.fixと合わせて使うこともできます。Hires.fixを使うので、元画像に変化が加えられて元画像の絵からは離れてしまいますが、高品質化が期待できます。
Hires.fixも合わせて使う場合は、Width/Heightを元画像のサイズに設定してください。
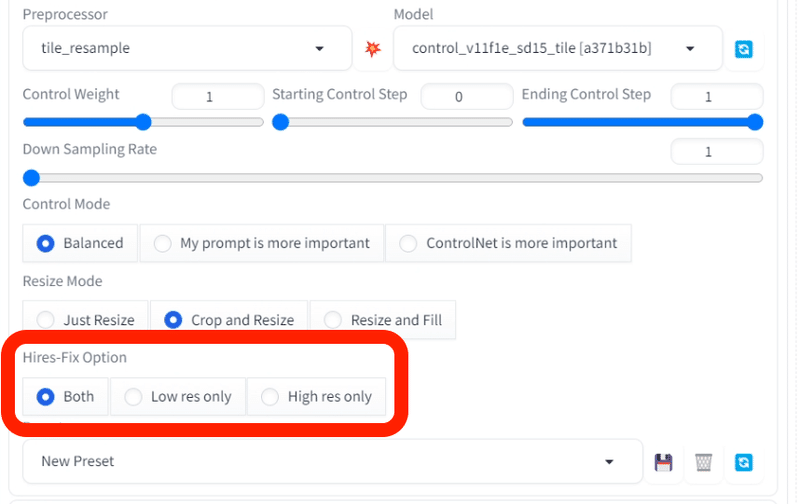
Hires-Fix Optionは、Hires.fixを有効にすると現れます。最近追加された機能であり情報が少なく、詳しい効果はよく分かっていません。
使ってみたところ、High res onlyの方が元画像に近いまま拡大でき、Low res onlyは元画像の絵からは離れました。
■ 元画像を保ったまま、画像を拡大する方法
SD1.5では、512×512サイズの画像でAIの学習が行われたため、このサイズから離れるほど絵の破綻や崩れが多くなりがちです。
そのため、画像のサイズを変えるには、まずWidth/Heightの値を512×512サイズ周辺に設定します。次に、そこからHires.fixを使うことで、簡単に高品質化しつつ画像のサイズを拡大する方法がよく使われます。
しかしHires.fixでは、拡大するときに元画像の絵が変わってしまうというデメリットがあります。また、GPUもけっこう消費するので、大きいサイズになるとGPU不足エラーが出てきます。私の環境では、1500×1500くらいになると、エラーが出てきます。
そこで今回は、元画像を保ちつつ、1500サイズよりも大きくする方法を解説します。
結論から言うと、元画像を保ったまま画像拡大するには、「ControlNetのTileと、img2imgのSD Upscale」がオススメです。
画像の拡大方法は、拡張機能を使う方法など他にも色々あるので試しましたが、拡大後の画質にはほとんど違いがなかったです。そのため、わざわざ拡張機能をインストールするよりも、今回紹介する方法が簡単でありオススメです。
□ img2imgのSD upscale
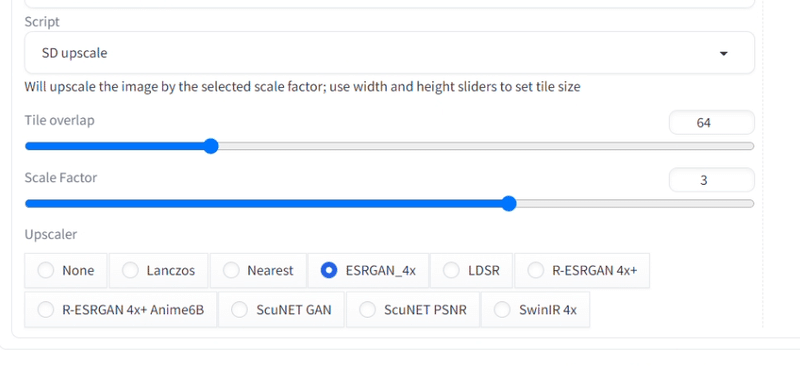
img2imgのScriptのSD upscaleを使うと、元画像を保ったまま画像を拡大できます。使い方は簡単で、
・Scale Factorで、何倍に拡大するかを設定
・Upscalerを1つ選択
するだけです。
SD upscaleは、画像をタイルに分割しつつ、そのタイルごとに拡大するという仕組みです。Tile overlapは、タイルに分割(細分化)した画像のつなぎ目をスムーズにするためのパラメータです。基本的に初期設定のままで大丈夫です。
Denoising strengthの値を上げるほど、高品質になりますが元画像と絵が変わります。値を下げるほど、元画像の絵を維持できますが、画像がぼやけます。画像を拡大するときは、0.5以下くらいで使っています。

Upscalerは色々ありますが、大きな違いはありません。以下が人気なので、私もこれらを使っています。Upscalerは、画像拡大時に使われる計算方法のことです。
・ESRGAN_4x
・R-ESRCAN 4x+
・R-ESRGAN 4x+ Anime6B
Upscalerによっては、インストールが必要なものもあり、最初の画像生成だけ時間がかかることがあります。
Scale Factorで、何倍に拡大するかを設定しますが、3倍以上くらい拡大したい場合は、2回に分けて画像拡大する方が絵の破綻が減ります。例えば、400×600サイズを4倍拡大したい場合、いきなり4倍にすると上手くいかないことが多いです。まずは2倍に拡大してから、拡大した画像をもう1度2倍に拡大するのがオススメです。
□ Extras

また、Extrasでも簡単に画像の拡大ができます。
・Resizeで何倍に拡大するかを設定
・Upscalerを設定
するだけです。Extrasでは、Upscalerを2つ使うことができます。
Extrasは、とても速く画像の拡大ができるのがメリットですが、画質は良くないので使っていません。



□ ControlNetのTileと、SD upscaleの組み合わせ
ControlNetのTileは、txt2imgでも使えますが、
・元画像と絵が少し異なる
・GPUの消費が多い
ので、img2imgで使うのがオススメです。

使い方は、先ほどのSD upscaleとほぼ同じで、ControlNetを追加するだけです。Enableにチェックを入れて、Tileを選択するだけで大丈夫です。
結果の比較は、以下のとおりです。

SD upscaleのみと比べると、画質はあまり変わっていません。ただし、ControlNetも併用することで、特に背景や服装の維持率が向上しています。

画像の拡大方法は他にも色々ありますが、試したところ画質はほとんど変わりませんでした。そのため、今回説明した「ControlNetのTileと、SD upscaleの組み合わせ」が簡単でありオススメです。
□ SDXLのTile/Blur
現時点では、Tile/BlurはSDXLに公式対応していません。

しかし、SDXL用のControlNetモデルは、公式以外からもけっこうアップロードされており、Tile/Blurも一応あります。
blurと書かれているので、Tileに対応しているのか分かりませんが、試したところ使えました。

これを1.5倍だけ拡大したのが、以下です。





SD upscaleのみと、ほとんど変わりませんが、ControlNetを使う方がパキッとしていて画像が鮮明です。いずれもGPUは、けっこうギリギリでした。
この記事が気に入ったらサポートをしてみませんか?