Rによる極値分析(rGEV)

1.rGEVモデル
rGEVモデルでは、各年の上位r個のデータを用いて一般極値分布を割り当てる。気象データを用いた極値統計では1年間をブロックとして極値を毎年取得して分析する。途上国の気象データ、特に降雨データは限られている。仮に20年間観測されても、20個のデータしか得られないと十分な精度が得られない。上位r個のデータを用いることで有意な分析を行うことができるかもしれない。
RのismevではrGEVモデルに当てはめて、rGEV(μ, σ, ξ) を対数尤度関数としてを用いてμ, σ, ξを算定する。これらが明らかになれば、以下によりT年の再現確率を求めることができる。

2.データの作成
神戸市のGEVと比較するために、1897年から2013年までの日降雨データをダウンロードした。日付と日降水量(mm)が元データ、これにYearを付した。港町として開けたので古いデータがある。このような貴重なデータがいつでも誰でも入手できることはすごい。
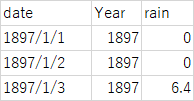
各年の上位5位までのデータセットをPYTHONで作成する。
全ての日データをデータフレームdfに入れ込み、yy年毎にデータをqueryで切り出し、降順に並べ替えて最初の5行を切り出す。
df.query('Year == @yy').sort_values('rain', ascending=False).head(5)
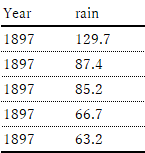
年毎に切り出した上位5つのデータを行としてdf_mx5.loc[yy]として付け加えていくと完成。
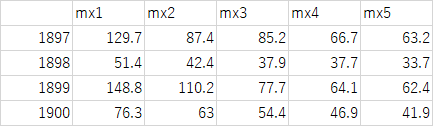
3.rGEVに対する当てはめ
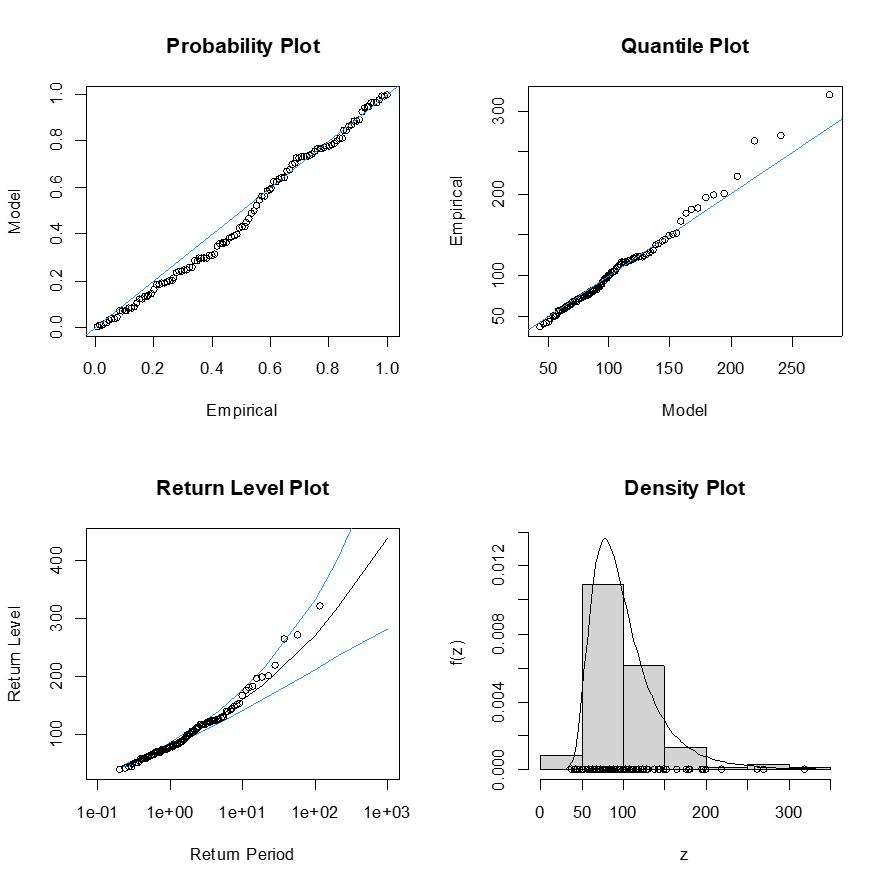
rlarg.fitにより、上位1~5までを当てはめた結果は表のとおり。
r=1の値はGEVと同じ。rが増えるに従って、μ, σ, ξの標準偏差は小さくなっていく。σが最小になるr=4についてグラフに示す・