
データを伝える技術 第3回 データを編集する 後編

執筆:荻原 和樹
データの構造から可視化の方法を考える
データから最適な視覚表現を考えるとき、ひとつのヒントになるのがデータの構造です。時系列や地理など、データからは必ず何かしらの構造を見出せるはずです。データの「切り口」あるいは「軸」と言い換えることもできます。
データをどのように可視化するか行き詰まった時は、似た構造のデータを考えることでヒントが得られる場合があります。以前の連載ではデータの意味を考えることについて書きましたが、今回は構造に着目して可視化を考えてみます。
例として「関係性」を示すデータについて考えます。たとえば国同士の貿易に関するデータの場合、データ構造は「ある国と国の間で輸出・輸入が行われた金額」が基本となります。ちなみに財務省「貿易統計」によると、2021年11月における日本からの輸出額が最も多かった国は中国で1.6兆円、2番目はアメリカで1.3兆円でした。もっと細かく見ていくなら、品目別であったり、時系列であったり、あるいは詳しい地域であったりと、色々なカテゴリーに分けることができるでしょう。ただその場合も「国と国の間の輸出入の金額」という基本構造は変わりません。
この基本構造を少し抽象的に考えると「ある主体と主体の関係性」に関するデータであるといえます。主体Aと主体Bの間には100の数値で表せる関係があり、AとCは50、BとDは70、CとEは120……などと関係は無数に広がっていきます。このような構造は「ネットワーク構造」と名前がついています。少し専門的な言い方だと、主体は「ノード」、関係性を示す線は「エッジ」と呼ばれます。

さて、このネットワーク構造のデータは貿易だけでなく色々な分野で見ることができます。たとえば人と人との関係です。「自分の知人関係を知人、そのまた知人……とたどっていくと、6番目の知人に到達するころには地球上のすべての人がカバーされる」という、いわゆる「6次の隔たり」という言葉を聞いたことがあるかもしれません。Facebookが2010年前後に世界や日本で普及し、そのデータを開発者や研究者が入手できるように公開されたことで、このような人間関係をネットワークに見立てた分析や解釈が流行した時期がありました。現在でもFacebookやTwitterのフォロー関係から同様の分析を行なっている記事や学術論文などが見られます。
私自身も、そのころにネットワーク理論の本を読んで可視化を行なったことがあります。きっかけは東日本大震災でした。
震災の後、東京電力に対する莫大な賠償請求などが取り沙汰されるようになり、同社の株価は大幅に下落しました。ちょうど決算の直前だったこともあり、東電の株式を数多く保有していた企業が3月末の決算で特別損失を計上したというニュースを目にしました。それらのニュースでは東電自身の経営だけでなく、東電の株式を持っている企業、あるいは東電が株式を保有している関連会社などの経営にも深刻な影響があるのではないか、と考察されていました。
当時、ちょうど自分が仕事で日本の上場会社の株主に関するデータを扱っていたこともあり、企業間の株式保有関係を描写するのにネットワーク構造が使えないかと考えました。
しかし当然ながら「株式の保有関係を可視化するツール」など存在しないため、バイオインフォマティクス(情報生物学)の分野で使われていた「Cytoscape」(サイトスケープ)と呼ばれるソフトウェアを使うことにしました。Cytoscapeはカリフォルニア大学サンディエゴ校(UCSD)の研究者らによって開発・運営されているオープンソース(ソースコードが公開されており、誰でも自由に使える)のツールです。

元々は分子や遺伝子の構造などを可視化・解析するためのソフトでしたが、ネットワーク構造の分析は他のさまざまな分野でも応用可能なことから、先に挙げたような人間関係のデータなどにも応用され、今ではネットワーク構造のデータを扱う際に広く使われるソフトウェアとなっています。
株式保有も分子構造も、ノードとエッジの組み合わせという点では同じデータ構造です。これはデータに使えると考えて、株式保有のネットワークをCytoscapeで分析・可視化して記事にしました。

名義は編集部になっていますが、私が初めてデータ可視化で記事を書いたのがこの記事でした。マイナーなトピックなのでPVは鳴かず飛ばずでしたが、直後にスタンフォード大学やニューヨーク大学の教授から「面白いデータなので英訳してくれないか」と依頼があり、ビジュアライゼーションの可能性を感じたことを覚えています。
これ以外にも、企業間の取引などにネットワーク構造が使われることがあります。それぞれの企業をノード、取引額をエッジと見立てれば、まさにネットワークの要領で可視化が可能になります。たとえば企業の取引データを多く保有している帝国データバンクは、デザイン会社と共同で企業取引データを可視化するウェブサイト「LEDIX」を2018年に公開しています。LEDIXでは企業の経済活動による地域への貢献をテーマとしているため、可視化の際にはシンプルなネットワーク図だけでなく地図とオーバーラップさせた見せ方をしています。

ネットワーク構造のデータには他にも「フィクション作品における登場人物の関係」「映画の共演者関係」など、さまざまなケースで応用できます(どちらも私が実際に見たことのある事例です)。
世の中で公開されているデータは本当に色々な種類がありますが、抽象化していくと似たようなデータ構造をしている例が少なくありません。データ可視化において「見せ方」を決めあぐねる際は、構造から「似たデータ」を探して、応用できそうな事例を探してみるのもよいでしょう。
誠実にデータを伝えるためには
データ可視化において、デザインや実装などのクオリティと並んで重要なのが「誠実さ」であると私は考えています。データ可視化は、やろうと思えばかなり悪どい方法でユーザーの印象を操作することができてしまいます。そして悲しいことに、そのような事例は枚挙にいとまがありません。こう書くと綺麗事のように映るかもしれませんが、ユーザーが安心して使える誠実なデータを提供することで、中長期的にデータ活用や社会における可視化の普及が進むと考えています。
データ可視化における誠実さとは何でしょうか。「誤解を招かないようなデザインにすること」「可能な限り偏りを避けて合理的な結論を導くこと」などは当然の前提として、同じくらい重要なのが「ユーザーによる検証可能性を確保すること」です。具体的には、データソースを直接ユーザーが直接確認したり、データ可視化の加工方法や分析過程が妥当かどうか検証することです。
日本でもデータジャーナリズムという言葉が徐々に普及してきたとはいえ、まだまだ新聞やテレビの報道では「総務省によると」という一言でデータの出所が終わってしまう場合も少なくありません。これではユーザーが実際にデータを触ってみたくなっても出典が不明ですし、そもそも公開されているデータなのかどうかもわかりません。
この現状を踏まえて、「出所や加工の過程は明かせないけどきちんと分析したから信頼してほしい」というデータ可視化と「出所はここで、加工はこのような過程にしたから不安であれば検証してほしい」というデータ可視化では、やはり後者の方が会社やコミュニティ内でも、広く社会においても信頼されるのではないかと思っています。
ではユーザーの検証可能性を確保するにはどうするか。まず第一は、元データにアクセスできるようにすることです。ウェブであればリンクでデータソースに遷移するのが最も早いでしょう。元データがウェブにない場合は、スキャンしてファイルストレージ(たとえばGoogleドライブなど)のリンクを使うことも可能です。
画像や動画など、リンクを置くことができないメディアであれば、『出所:総務省「人口推計」より2022年1月1日時点の30〜39歳人口(2022年2月19日取得)』といった形で、出所となるデータの項目まで書いておくのがベターです。取得日を書くのは、後日データが修正されたり削除されたりといったケースに備えるためです。データを格納するファイルや、「ウェブ魚拓」といったサービスでウェブサイトのバックアップを取っておくと万が一の事態にも対応できます。
第二はデータの加工方法を明記することです。計算や集計方法、解析や可視化に使ったソフトウェアなどを説明します。もちろん手順を逐一書き記すのは手間ですから、「◯◯については手作業で修正した」といった表現を使うのも可能でしょう。目的は、データの出所と加工方法を見ればユーザーが自分で可視化を再現できることです。
第三に、継続的にデータ更新や修正を行う場合、その履歴を明記すること。たとえばSNSに貼られたスクリーンショットと現在のデータが異なる場合や、何度もリピートしてデータを見るユーザーのことを考えると、更新や修正の履歴はどこかで見られる方がよいでしょう。
履歴は必ずしも本文やデータ可視化のページから直接見られなくても構いません。たとえばページ末尾に「修正履歴はこちら」といったリンクをつけて、履歴の一覧は遷移先のページで表示させる、といった形でも問題ないと思われます。
これらの対応はユーザーのためだけでなく、データを可視化して公開する私たち自身にも役立ちます。報道のように、社会に広くシェアされるデータや図表は、しばしば一部を切り取られて言われのない非難を受けることがあります。もちろん正当な批判ならよいのですが、根拠なく偏向や捏造と断じられることも少なくありません。
そのようなケースにおいても、きちんとデータソースや加工の方法を明記しておけば、無責任な非難が出回ることをある程度防げますし、自分自身や会社に届くクレームに対しても「加工方法は明記している」と毅然とした対応を取ることができます(完全には防げないのが悲しいことですが)。
もう一点、出典や修正履歴などを明らかにするメリットは、データの二次利用が増えることです。
新型コロナのダッシュボードでは、上記で挙げたような対応を行い、厚生労働省から画像やPDFで公開されていたデータも再利用しやすい形で公開していました。修正履歴も「GitHub」というデータやコードを共有できるサイトですべてオープンにして、二次利用可能であることを明記していました。海外ではNew York TimesやGuardianといった大手メディアがすでに行なっている試みですが、おそらく日本の報道コンテンツとしては初めてだと思われます。
これにより、サイトそのものだけでなくデータも各所で使われることになりました。たとえばCiNiiやGoogle Scholarで検索すると複数の学術論文でデータが使われています。また、Googleは2020年夏から新型コロナの感染予測を公開していますが、トレーニングデータソース(予測の基礎となるデータ)の筆頭に東洋経済オンラインのダッシュボードを挙げています。

他にも私の記憶している限りではテレビ番組、雑誌、YouTubeや病院、そしてブログやSNSなどでデータが使われました。これらの影響を明確に数字で示すことは難しいですが、おそらくページ本体や東洋経済オンラインそのものへのアクセスによい影響を与えたであろうと想像しています。
ウェブサイトでデータ可視化を公開する場合、データやソースコードを隠すことは技術的に難しいものです。開発者用のツールを使えば、サイトのコードやデータはある程度覗くことができてしまいます(もちろんこれは合法です)。データを隠すことも不可能ではありませんが、開発効率やユーザーの利便性が著しく損なわれるのが現実です。「そのくらいならいっそのこと公開してしまえ」と考えて始めたGitHubでのデータ公開ですが、二次利用による認知度の向上は無視できないくらいに大きいというのが私の実感です。
これは報道だけではなくビジネスにおいても同様です。たとえば会社でデータ可視化のダッシュボードなどを使う中には、データに特別興味を持ってくれたり、あるいは自己流の分析を試してみたいユーザーもいるでしょう。そのようなユーザーに自分で触れるデータを用意すれば、ダッシュボードに対して新しい提案をしてくれたり、現場の仮説を自らデータで検証してくれるかもしれません。
なお、二次利用に際して忘れがちなのがライセンスの設定です。データを利用してもらう際には、「ここまでなら二次利用しても大丈夫、これは禁止」という規定を明記するほうが、後々のトラブルを避けるために有用です。データを使う側にとっても、許諾や料金が不要かどうかわからないデータを積極的にシェアしたいとは思わないでしょう。
ライセンスには、「この場合は要許諾」など独自に定義する方法と、既存のライセンス規約をそのまま援用する方法があります。新型コロナのダッシュボードでは「MITライセンス」という規定を使いました。MITライセンスとはマサチューセッツ工科大学(MIT)にて原文が作成されたライセンスで、誰でも自由にソースコードやデータを利用・改変してよい代わりに、利用する際は著作権者の明記を求めています。既存のライセンスには他にもCC(クリエイティブ・コモンズ)などがありますので、プロジェクトの方針によって選ぶとよいでしょう。
まとめると、誠実にデータを伝える過程において重要なことはユーザーによる検証可能性を確保することであり、無根拠な非難を未然に抑止したり、データの二次利用を促進するメリットがあります。世にあるすべてのコンテンツがこうなるべきだ、とまでは思いませんが、データの公益性や話題性などに応じて上記のような対応を取ることは、自分たち自身のためにもなるのではないかと考えています。
可視化「すべきでない」データ:炎上事例の紹介
データの編集においては「何を可視化するか」と同じく「何を可視化すべきでないか」を考えることが必要です。意見はさまざまあると思いますが、私は世の中にあるすべてのデータがオープンになるべきとは考えていません。前回の連載で挙げた差別や偏見につながる可視化に加え、公になることで特定の人々に不利益をもたらすデータもあります。
必要がないデータを可視化する分には「アウトプットがわかりにくくなる」だけで実害はないものの、センシティブな扱いが必要なデータまで無造作に公開するとトラブルを引き起こすことがあります。ここでは過去に起こったデータ可視化の「炎上」事例を2件挙げます。
1つ目はアメリカの事例です。2012年、ニューヨーク州の日刊新聞「The Journal News」が『マップ:あなたの近くの銃許可保持者はどこにいる?(Map: Where are the gun permits in your neighborhood?)』という記事を公開しました。記事ではGoogleマップの地図共有機能を使い、ニューヨーク州ウェストチェスター郡およびロックランド郡における拳銃の所持許可証を保有している人の氏名と住所およそ3.3万件を閲覧可能にしています。
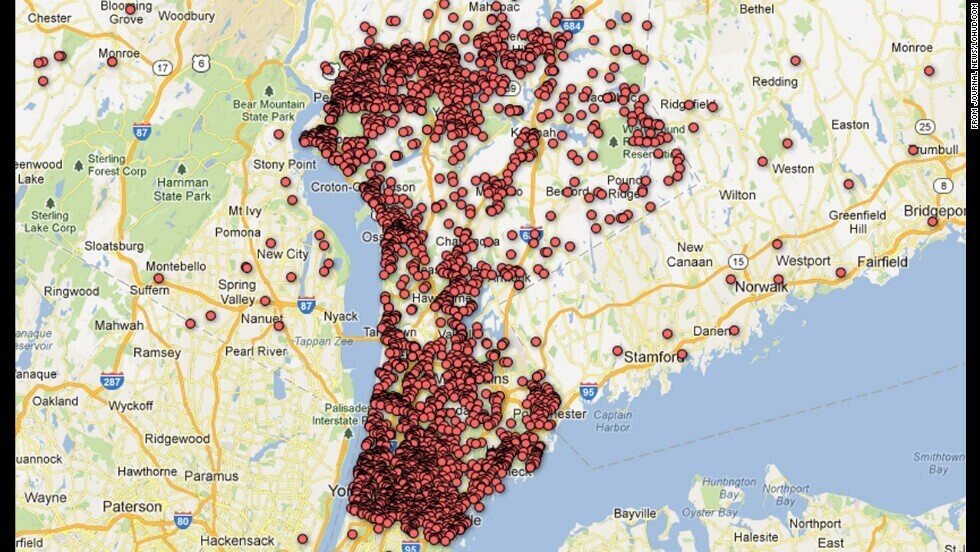
その2週間前にはコネチカット州サンディフック小学校において計26名が犠牲になった銃乱射事件が起きていました。記事はこれを受けて公開されたものです。データは両郡への情報公開請求によって取得され、New York Timesによるとページには100万件以上のアクセスがあったそうです。
しかしこのマップはプライバシーの侵害だとして厳しい批判に晒されました。当初The Journal News側は、銃保持者の情報は公益にかなった情報であるとしていましたが、批判はますます加熱し、ついには報復としてThe Journal Newsの編集部員やスタッフの氏名と住所が同じようにGoogleマップで公開されるまでに至り、記事は削除されました。
ウィスコンシン大学マディソン校のキャスリーン・カルヴァー助教(当時)はMediashift『The Journal Newsは銃保持者マップのどこで間違ったのか(Where the Journal News Went Wrong in Mapping Gun Owners)』にて、個別の氏名と住所を公開することは、たとえば銃の窃盗のターゲットになるといった害があると指摘した上で、同紙が主張する公益性を考えるのであれば、たとえば地区ごとに人数を集計するといった処理で簡単にリスクを最小化できたのではないかと論じています。
似た事例が日本にも存在します。2019年3月、『破産者マップ』と題されたウェブサイトが公開されました。The Journal Newsの事例と同じくGoogleマップを使ったこのサイトでは、自己破産を行った人の住所と氏名が閲覧できる状態になっていました。

自己破産者の情報は官報に掲載され、冊子形式またはインターネット上でも閲覧することができます。『破産者マップ』はこの情報を解析し、マップ形式にして公開したものです。
このサイトがSNSなどで話題になったのは3月15日ごろです。直後、マップに掲載された破産者向けの削除申請フォームが運営者によって設けられましたが、そこでも身分証明書の写しをアップロードするよう求めたり、「破産に至った事情」を200文字以上で提出させたりと理不尽な要求が目立ち、SNSでは「炎上」状態となりました。
マップの公開日時は判然としませんが、運営者と見られる「破産者マップ係長」を名乗るTwitterアカウント(以下、便宜的にこのアカウントを「運営者アカウント」と呼びます)によると、公開当初は「1日0アクセス、多くても5アクセス程度だった」ものが、3月17日には「1時間あたり230万アクセス」に達したとしています。
破産者マップの顛末は、当然ながら多くのメディアで批判的に紹介されました。また「破産者マップ被害対策弁護団」の発足、政府の個人情報保護委員会による行政指導などを経て、3月19日にはサイトが閉鎖。運営者アカウントでもその旨が告知されました。
なお騒動はこれで終わったわけではなく、2021年9月にはプライバシー権や名誉を侵害されたとして、破産者マップに氏名や住所を掲載された2人がサイト運営者に対して訴訟を起こしています。
さて、運営者アカウントは「破産者の住所や氏名の公表について、仮にプライバシーの侵害だというのであれば、破産者マップは官報と同等」「公開されている破産者の情報の表現方法を変えるだけで、これほど多くの反応があるとは思わなかった」「官報で公開するのと、グーグルマップで公開するのとでは何が違うんでしょうか?」などと発言し、自身の責任を繰り返し否定しています。
私自身は、データ可視化は「新しい情報かどうか」ではなく「何を伝えるか・何が伝わるか」が重要だと考えています。したがって、その可視化で使われるデータが他で公開されているかどうかにかかわらず、ユーザーにとって価値が発生したり、逆に今回の破産者マップのように悪い意味で話題になることもあるでしょう。きちんと使えば社会的に大きな意義があることの裏返しとして、悪意のある使い方をすれば特定の人々を傷つけることになります。
今回紹介した事例は2件とも個人情報に関わるものでしたが、それ以外にも前回解説した広島の原爆アート作品など、内容面で炎上する事例は少なくありません。「データを組み替えているだけだからこちらに責任がない」とは考えず、結果としてユーザーにどのような伝わり方を考えるかが重要です。
「面白い」データの探し方
続いて、「面白いデータの探し方」について考えてみます。「面白いデータ」とは抽象的な表現ですが、ここでは「役に立つ」「価値がある」「社会的に有意義」といった様々な要素を含んでいると考えてください。
私は「人が何となく思っていることをデータで裏付ける」のが面白いデータのひとつの条件だと考えています。仕事でも日常生活でも、多くの人は「これにはこんな傾向があるのでは」「この問題はここから起きているのでは」と、漠然とした疑問や推測を持っていると思います。しかし多くの場合は明確な根拠があるわけではないので、「何となくこうかもしれない」「今までの経験ではこれが多かった」といった私見にとどまることがほとんどでしょう。
こうした疑問や推測にデータで答えを出したり、あるいは裏付けたりすると、人に強い興味を持ってもらえたり、社会的に大きな反響があるものだと私は考えています。
この点で巧みなデータの選び方をした報道コンテンツが、Wall Street Journalが2015年に発表した『20世紀における感染症との闘い:ワクチンのインパクト(Battling Infectious Diseases in the 20th Century: The Impact of Vaccines)』です。
このコンテンツでは、Measles(はしか)、Hepatitis A(A型肝炎)、Mumps(おたふくかぜ)といった感染症の症例数が「ヒートマップ」と呼ばれる可視化手法で示されています。縦軸がアルファベット順に並んだ全米50州、横軸が時系列、各セルの色がその年における人口10万人あたりの症例数です(感染症ごとに症例数は異なるので、色と数字の対応はそれぞれ異なります)。「Vaccine introduced」とラベルのついた縦線は、その感染症に対するワクチンが導入された年です。

このデータ可視化コンテンツ自体は極めてシンプルなものです。データはピッツバーグ大学のプロジェクト・ティコ(Project Tycho)から取得し、Highchartsという名前のJavaScriptライブラリ(JavaScriptというコンピューター言語でグラフを描画するためのプログラム)でヒートマップを表現しています。ワクチン導入年の縦線を表示する以外は、ほぼライブラリのデフォルト設定のままで可視化を行なっており、コンテンツにはそれ以外の解説や解釈などは含まれていません。
当時のデータがどのように公開されていたのかはわかりませんが、仮にExcelやCSVといった表形式でデータが公開されていたなら、早ければ数時間でこの可視化を作ることができるでしょう。それにも関わらず、このコンテンツはビル・ゲイツがTwitterでシェアするなどして大いに拡散され、2015年のData Journalism Awardsにて、その年で最も優れた可視化作品に贈られる賞であるData Visualisation of the Yearを獲得しました。
この背景には、アメリカにおける根深いワクチン懐疑論があります。新型コロナのワクチンをめぐっては、その副反応を5G回線や磁力などと結びつける荒唐無稽な陰謀論が一部で流行しましたが、そのずっと前から「anti-vaxxer」と呼ばれる反ワクチン論者がアメリカでは社会問題となっていました。ワクチン反対論に影響された親が自分の子にワクチンを打たせない事例もあり、2014年末から2015年1月にかけてカリフォルニアのディズニーランドではしかの流行も起きていました。
ワクチンの意義や有効性が議論となる中で、この問題にデータで応えたのが今回のコンテンツです。副題「ワクチンのインパクト」が示すとおり、ワクチンが感染症に及ぼす効力について一目で理解できる強力な視覚的メッセージを与えています。
さて、ではこのような面白いデータを必要なときに取り出せるようにするにはどうすればよいか。私がおすすめするのは、日頃から「データの引き出し」を作っておくことです。どこにどのようなデータがあるのか、大まかでよいので頭に入れておけば、何かニュースを目にしたときや、新しい可視化手法について知ったときにデータと組み合わせることができます。
たとえば文部科学省が毎年公表している「学校基本調査」という統計があります。小学校や中学校など各種の学校における在学者数、進学率、教員数などを網羅した調査データです。このデータの存在が頭の片隅にあれば、たとえば進学率に関するニュース記事を読んだときや、「特別支援学校に通う生徒数はどのように推移しているのだろう?」といった疑問が浮かんだときに素早くデータにアクセスすることができます。
ここで大切なのは、可能な限り「項目名」まで網羅しておくことです。学校基本調査は、公式の説明では「学校教育行政に必要な学校に関する基本的事項を明らかにすることを目的として……昭和23年度より毎年実施しています」とされていますが、これだけでは具体的にどのようなデータが載っているのかわかりません。私自身、統計調査の名前と概要だけメモしておいて肝心の中身が詳しくわからず、その後まったく活用していない……といったケースが何度もあります。
そこで、「中学校 > 学校医等の数 > 学校薬剤師」「大学・大学院 > 大学院年齢別入学者数 > 国立・女 > 30〜34歳」といった、具体的な項目までメモしておくと、記憶にも残りやすく、組み合わせが浮かびやすいのではないかと思います。
ただ、さすがに学校基本調査のような大規模な調査データの項目を丁寧に網羅するのは手間です。多くの統計データはExcelなどの表形式で公開されているはずですから、表の一番上にある行あるいは一番右にある列を丸ごとコピーしてメモ帳に貼り付け、後から検索できるようにしておくだけでもよいでしょう。
行政機関の公開するデータが「わかりにくい」のは何故か
「行政機関の公開するデータはわかりにくい」とよく言われます。たしかに政府や地方自治体の公開するデータは、PDFファイルやExcelファイルなどの表だけで公開されているケースが多く、それも印刷を前提として罫線やセル結合などが混在し(これをネットジョークで揶揄して「神エクセル」などと呼ぶことがあります)、「見づらいデータ」の代名詞のごとく扱われています。
最近ではTableauなどのようなデータ可視化ツールやダッシュボードツールを使ってデータをグラフ形式で公開する事例も増えていますが、「わかりづらい」という印象を崩すまでには至っていないように感じます。実際、私も「使いやすい!」と話題になった事例は見たことがありません。
「行政機関には能力がないからわかりやすいデータ可視化が作れない」とは思いません。それよりも大きな理由は「行政機関はデータを編集できないから」であると考えています。
今までの連載では、ユーザーに伝わりやすいデータ可視化を作るためにはデータを選ぶ・絞ることが重要であると書いてきました。一方で、行政において情報を公開する場合の最優先事項は公平性と中立性です。統計データの中には社会的に注目度が高い・低いもの、経済や社会への影響度が強い・そうでないものなど様々あるでしょうが、「全体の奉仕者」たる公務員はそれを自分たちだけで判断できませんし、すべきではありません。
そうすると、この連載で説明しているような「ユーザーの目的を推測してデータを絞る」といった工夫ができません。データを絞ったり、メリハリをつけることができないゆえに、ダッシュボードが総花的になりがちです。同じ理由で「かいつまんで簡潔に説明する」といった工夫ができないことも影響しているでしょう。求められる「正しさ」のレベルが極めて高いため、わかりやすさを犠牲にせざるを得ないといえます。
さて、社会におけるデータ活用の話になると「行政もデータ活用を推進してデータをわかりやすく発信すべき」という意見が見られますが、上記の理由から私はこれに賛成できません。もちろん行政に求められる公平性を確保した上でわかりやすく伝えられるなら言うことがないのですが、現実的には他の方法を模索する方が合理的でしょう。
「他の方法」による解決策のひとつは、行政と民間の役割分担だと考えています。データをあまねく日本全国から収集・集計することは、権限の面でもコストの面でも民間企業には真似できない、行政機関の役割です。行政機関はこちらに注力し、可視化や活用といった側面はある程度民間に任せるのがよい。
好例が台湾のマスク在庫状況データです。新型コロナの感染が始まった2020年1月から2月にかけて、台湾では深刻なマスクの在庫不足に見舞われました。日本でもドラッグストアやスーパーマーケットなどにはなかなか入荷されない一方で、ネット上では高額で転売されていたのは記憶に新しいところです。
この状況を受けて、台湾の衛生福利部中央健康保険署が2月上旬にマスクの在庫状況を確認できるオープンデータを公開しました。CSV(テキストによる表)形式で30秒ごとに更新されるため、ほぼリアルタイムで在庫を把握することができます。このデータ提供はマスクの購入管理(健康保険カードを使ってマスクの購入枚数を管理し、週ごとの枚数が上限に達している場合はマスクを買うことができない)アプリの導入と同時に行われました。これにより、民間の企業や個人開発者がデータをマップなどで可視化する事例が数日で50以上できたとの報告もあります。
もし行政機関の力だけで可視化まで提供しようとしていたら、アプリやデータの導入はもっと遅れていたでしょう。その場合も、民間の作った事例より使いやすくなったかどうかはわかりません。行政が決めたものだけを使い続けるより、可視化の事例が数多くあれば、ユーザーは自分に適したものを選ぶことができます。
翻って本邦では、データの可視化まで行政機関で提供するものの肝心の生データは公開されていないケースも散見されます。データが公開されてもPDF形式だったり、存在するはずのデータがなくグラフを作る分だけしかデータがない場合もあります。行政と民間は同じアウトプットを作って競争するのではなく、うまく役割分担することが最終的な社会の利便性を高めると個人的には考えていますが、なかなか一足飛びには進歩しないのが現状です。
つづく