
AUTOMATIC1111(stable diffusion webui)APIでTensorRT変換モデルを使う

SDモデルをTensorRTを使って変換する方法はここでは説明していません。
以下のものを参考にモデルの変換を行ってください。
書いてることはほぼ同じなので自分のわかりやすいものを見てください。
APIの入門記事を読むと理解しやすいです。
AUTOMATIC1111版sd web ui version: v1.6.0
事前確認
web ui のトップにSD Unetがあることを確認してください。
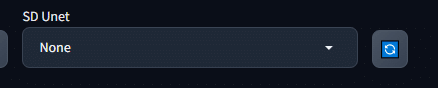
もしくはweb ui起動batファイルがあるディレクトリ内にconfig.jsonファイルにsd_unetが記載されているか確認してください。
webuiのAPI起動
API用にwebui-user.batをコピーして別の名前で作っておきます。
ここではwebui-api-user.batにします。
webui-api-user.batのset COMMANDLINE_ARGSにコマンドライン引数を追加します。
いつも使う引数に--apiを追加する
set COMMANDLINE_ARGS=--apiAPIのドキュメントが見たい方は以下の方法で確認できます。
起動したら黒い画面のコマンドプロンプトのRunning on local URL: http://127.0.0.1:7860に/docsをつけてアクセスしてください。
http://127.0.0.1:7860/docs

画像の生成
生成前にAIPを使ってオプションの設定を変えるだけで使えるので、i2iのやり方は省きます。
ローカルでする場合は仮想環境を作ることを推奨します。
venvを使った仮想環境の作り方
使用するライブラリ▼
pip install Pillow requestsモデル名とハッシュを含む一覧を出すコード
APIでSDモデルを使うのにモデル名とハッシュが必要になります。

http://127.0.0.1:7860/sdapi/v1/sd-modelsにリクエストし、自身が持っているモデルを取得します。
import requests
from pprint import pprint
url = "http://127.0.0.1:7861"
sd_models = requests.get(f"{url}/sdapi/v1/sd-models").json()
sd_models = [ i["title"] for i in sd_models]
# pprint(sd_models)
with open("sd_model.txt", '+w', encoding='UTF-8') as f:
f.write('\n'.join(sd_models))t2i
画像を生成する前にhttp://127.0.0.1:7860/sdapi/v1/optionsにリクエストする値を設定します。
model = "anim\pikasNewGeneration_v20.safetensors [6c509880a5]"
unet = "[TRT] anim_pikasNewGeneration_v20"
# ▲半角の空白。
option_payload = {
"sd_model_checkpoint": model,
"sd_unet": unet,
}
requests.post(url=f'{url}/sdapi/v1/options', json=option_payload)SDモデルとTensorRT変換モデルは合わせて使います
TensorRT変換モデルの名前の調べ方はstable-diffusion-webui\models\Unet-trtにある、使うSDモデルと同じ名前のanim_pikasNewGeneration_v20…を使います。
http://127.0.0.1:7860/sdapi/v1/txt2imgにリクエストする値を設定します。
promptにpuppy dog、stepsに10を設定します。
promptは好きにしてください
payload = {
"prompt": "puppy dog",
"steps": 10
}
response = requests.post(url=f'{url}/sdapi/v1/txt2img', json=payload)modelやunetは任意のものに変えてください。
あとは全体のコードを使って実行するだけで画像が生成されます。
全体のコード▼
import json
import requests
import io
import base64
from PIL import Image, PngImagePlugin
url = "http://127.0.0.1:7860"
# オプション設定
model = "anim\pikasNewGeneration_v20.safetensors [6c509880a5]"
unet = "[TRT] anim_pikasNewGeneration_v20"
option_payload = {
"sd_model_checkpoint": model,
"sd_unet": unet,
}
requests.post(url=f'{url}/sdapi/v1/options', json=option_payload)
payload = {
"prompt": "puppy dog",
"steps": 10
}
response = requests.post(url=f'{url}/sdapi/v1/txt2img', json=payload)
r = response.json()
for i in r['images']:
image = Image.open(io.BytesIO(base64.b64decode(i.split(",",1)[0])))
png_payload = {
"image": "data:image/png;base64," + i
}
response2 = requests.post(url=f'{url}/sdapi/v1/png-info', json=png_payload)
pnginfo = PngImagePlugin.PngInfo()
pnginfo.add_text("parameters", response2.json().get("info"))
image.save('output_t2i.png', pnginfo=pnginfo)この記事が気に入ったらサポートをしてみませんか?