
プログラミング未経験でもできるYouTubeのサムネイルを一発で自動作成するGPTsの作り方

はじめに
この記事ではGPTsを利用してライフスタイル系のYouTubeサムネイルを自動生成するGPTsの作り方について解説します。
このGPTsを使用することで、サムネイルを効率よく作成できます!
関連記事▼
実際のデモ画面
以下のようにサムネイルに入れたいテキストを入力するだけで、サムネイルを自動生成してくれます。

生成されたサムネイルはこちら。

YouTubeサムネイル自動生成GPTsの作り方
それでは具体的な作成方法について解説をしていきます!デモ画面で紹介をしたような機能を使いたい方はこれから解説することをそのまま実行してください。
「プロンプトがどうやって作られてるか知りてー!」
「これを応用して自分のチャンネルで使ってるサムネイルを作りてー!」
という方には記事の後半で詳しい解説を書きますのでそちらを見てください!プロンプトの中にはpythonのコードが含まれていますがプログラミングの知識が皆無の私でも作成できる方法を書きましたので参考にしていただければと思います。
①GPT Builderを作成
GPTストア画面から作成ボタンを押し、Configure画面でnameとDescriptionを設定します。

②knowledgeの設定を行う
続いてサムネイル作成に必要なknowledgeの設定を行います。
後でも解説をしますが、このYouTubeサムネイルの自動生成GPTsには
・日本語を入力するための日本語フォント
・DALL-E 3で生成したものに重ねる画像
の2点が必要になります。
日本語フォントは今回は「NotoSansJP-Black.ttf」を使用しますので下記リンクからダウンロードしてzipファイルを解凍したのち、staticファイルから「NotoSansJP-Black.ttf」のファイルをknowledgeに入れてください。
DALL-E 3で生成したものに重ねる画像については今回はcanvaで用意をしています。
今回は白い枠と黒いレイヤーをDALL-E 3で生成した画像に重ねたいので、そのデザインをcanvaで作成しダウンロードしたものをknowledgeに入れています。以下のような画像です。

注意点としては画像を保存する際は、必ず背景を透過した状態でPNG形式で保存してください。これをしないと適切に画像を重ねることができません。
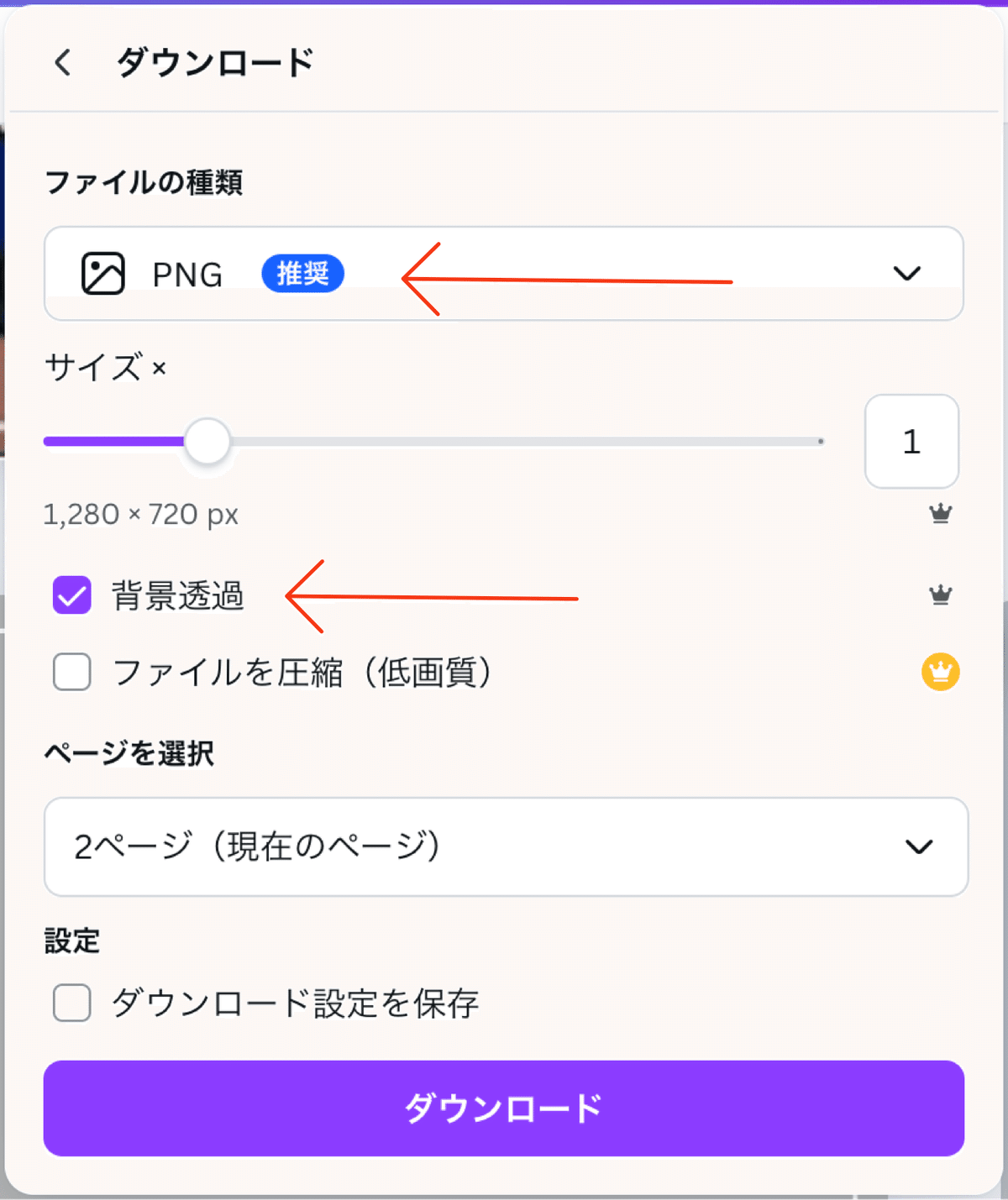
knowledgeにそれぞれをダウンロードすると以下のようになります。これでknowledgeの設定は完了です。

③プロンプトの設定
サムネイルの自動生成をするため以下のプロンプトをinstructionsに設定します。
以下の手順を必ずステップバイステップで実行をしてください。
①dalle3で入力された文章の画像を以下のスタイルで生成する
Style:
Soft and warm lighting
Stylish
Make it look like a photograph
Japanese
Size 16:9
②①で生成された画像を1280×720にリサイズをする
コードを以下のものを使用する。
```
from PIL import Image
def resize_image(input_path, output_path, target_size=(1280, 720)):
with Image.open(input_path) as img:
# リサイズ
resized_img = img.resize(target_size, Image.ANTIALIAS)
# 保存
resized_img.save(output_path)
```
③②で作成した画像の上にknowledgeにある1280×720pxのサイズの「white box.png」を重ねる。コードは以下のものを使用するものとする。
```
from PIL import Image
def resize_image(input_path, target_size=(1280, 720)):
with Image.open(input_path) as img:
resized_img = img.resize(target_size, Image.ANTIALIAS)
return resized_img
def overlay_image(base_image, overlay_image, position):
# オーバーレイ画像を重ねる
base_image.paste(overlay_image, position, overlay_image)
return base_image
def process_images(base_image_path, overlay_image_path, output_path, target_size=(1280, 720), overlay_position=(0, 0), overlay_size=None):
# リサイズされたベース画像を取得
resized_base_image = resize_image(base_image_path, target_size)
# オーバーレイ画像を開く
with Image.open(overlay_image_path) as overlay_img:
# オーバーレイ画像をリサイズ (必要に応じて)
if overlay_size:
overlay_img = overlay_img.resize(overlay_size, Image.ANTIALIAS)
# ベース画像にオーバーレイ画像を重ねる
final_image = overlay_image(resized_base_image, overlay_img, overlay_position)
# 最終画像を保存
final_image.save(output_path)
# 使用例
base_image_path = "/mnt/data/final_smartphone.png" # ベース画像のパス
overlay_image_path = "/mnt/data/final_image_with_overlay.png" # 重ねる画像のパス
output_image_path = "/mnt/data/final_output.png" # 出力画像のパス
# オーバーレイ画像のサイズと位置を調整
overlay_size = (1280, 720) # オーバーレイ画像のサイズをベース画像と同じに設定
overlay_position = (0, 0) # オーバーレイ画像の位置を左上に設定
process_images(base_image_path, overlay_image_path, output_image_path, overlay_position=overlay_position, overlay_size=overlay_size)
```
④入力された文章を元にサムネイルに挿入する3行の文章を#出力例 をもとに生成してください。生成された3行の文章は次のステップで使用をします。
- 1行目:** 入力テキストのコア・メッセージを英語で生成する。
- 2行目:**日本語のオリジナル入力テキスト。
- 3行目:**入力テキストを英訳したいもの。
#出力例:
- **Input Sentence:** "未来のテクノロジーが私たちの生活をどのように変えるかを考える。"
- ** 1行目:** "Future Technology"
- **2行目:** "未来のテクノロジーが私たちの生活をどのように変えるかを考える。"
- **3行目:** "Thinking about how future technology will change our lives."
⑤④で生成した3行のテキストを③で作成した画像に挿入してください。コードは以下のものを使用してください。
```
from PIL import Image, ImageDraw, ImageFont, ImageFilter
def add_embossed_text(draw, text, position, font, emboss_offset=1):
# エンボス効果のために白の影を追加
draw.text((position[0] - emboss_offset, position[1] - emboss_offset), text, font=font, fill="black")
draw.text((position[0] + emboss_offset, position[1] + emboss_offset), text, font=font, fill="black")
# 本来のテキストを白で描画
draw.text(position, text, font=font, fill="white")
def add_text_to_image(image_path, output_path, texts, font_path):
# 画像を開く
with Image.open(image_path) as img:
draw = ImageDraw.Draw(img)
# 各行のテキストのフォントサイズを設定
fonts = [
ImageFont.truetype(font_path, 35),
ImageFont.truetype(font_path, 70),
ImageFont.truetype(font_path, 35)
]
# 各行のテキストサイズを測定
text_sizes = [draw.textsize(text, font=font) for text, font in zip(texts, fonts)]
# 各行のテキスト間のスペース
line_spacing = 15
# テキスト全体の高さを計算
total_height = sum(size[1] for size in text_sizes) + line_spacing * (len(texts) - 1)
# 画像の中央にテキストを配置するための開始位置を計算
image_width, image_height = img.size
y = (image_height - total_height) / 2
for i, (text, font, size) in enumerate(zip(texts, fonts, text_sizes)):
# テキストの開始位置を計算
x = (image_width - size[0]) / 2
add_embossed_text(draw, text, (x, y), font)
y += size[1] + line_spacing
# 画像を保存
img.save(output_path)
# 使用例
image_path = "/mnt/data/final_smartphone.png" # 入力画像のパス
output_path = "/mnt/data/final_output_with_text.png" # 出力画像のパス
texts = ["これは1行目のテキストです。", "これは2行目のテキストです。", "これは3行目のテキストです。"]
font_path = "NotoSansJP-Black.ttf" # フォントファイルのパス
add_text_to_image(image_path, output_path, texts, font_path)
```
③最終画像を提供する。ダウンロード可能な画像を渡す。④Capabilitiesの設定
最後にCapabilitiesの設定をします。今回は「DALL-E 3」と「Code Interpreter」のみを使用するので、その2つの機能にチェックを入れて「Web Browsing」のチェックは外します。

⑤実際にタイトルを打ってみる
最後にタイトルを打って試してみましょう!下記のような画像が出力できてれいばOKです。もしできていない場合はどこかのステップができていない可能性があるのでもう一度記事を見返して確認してみてくださいー!

プロンプトの解説とプロンプトを0から作成する方法
ではここからは今回使用したプロンプトが何をしているのかとプログラミング初心者の私がどのようにプロンプトを0から作成したかを解説していきます!
改めて今回使用したプロンプトはこちらです。
以下の手順を必ずステップバイステップで実行をしてください。
①dalle3で入力された文章の画像を以下のスタイルで生成する
Style:
Soft and warm lighting
Stylish
Make it look like a photograph
Japanese
Size 16:9
②①で生成された画像を1280×720にリサイズをする
コードを以下のものを使用する。
```
from PIL import Image
def resize_image(input_path, output_path, target_size=(1280, 720)):
with Image.open(input_path) as img:
# リサイズ
resized_img = img.resize(target_size, Image.ANTIALIAS)
# 保存
resized_img.save(output_path)
```
③②で作成した画像の上にknowledgeにある1280×720pxのサイズの「white box.png」を重ねる。コードは以下のものを使用するものとする。
```
from PIL import Image
def resize_image(input_path, target_size=(1280, 720)):
with Image.open(input_path) as img:
resized_img = img.resize(target_size, Image.ANTIALIAS)
return resized_img
def overlay_image(base_image, overlay_image, position):
# オーバーレイ画像を重ねる
base_image.paste(overlay_image, position, overlay_image)
return base_image
def process_images(base_image_path, overlay_image_path, output_path, target_size=(1280, 720), overlay_position=(0, 0), overlay_size=None):
# リサイズされたベース画像を取得
resized_base_image = resize_image(base_image_path, target_size)
# オーバーレイ画像を開く
with Image.open(overlay_image_path) as overlay_img:
# オーバーレイ画像をリサイズ (必要に応じて)
if overlay_size:
overlay_img = overlay_img.resize(overlay_size, Image.ANTIALIAS)
# ベース画像にオーバーレイ画像を重ねる
final_image = overlay_image(resized_base_image, overlay_img, overlay_position)
# 最終画像を保存
final_image.save(output_path)
# 使用例
base_image_path = "/mnt/data/final_smartphone.png" # ベース画像のパス
overlay_image_path = "/mnt/data/final_image_with_overlay.png" # 重ねる画像のパス
output_image_path = "/mnt/data/final_output.png" # 出力画像のパス
# オーバーレイ画像のサイズと位置を調整
overlay_size = (1280, 720) # オーバーレイ画像のサイズをベース画像と同じに設定
overlay_position = (0, 0) # オーバーレイ画像の位置を左上に設定
process_images(base_image_path, overlay_image_path, output_image_path, overlay_position=overlay_position, overlay_size=overlay_size)
```
④入力された文章を元にサムネイルに挿入する3行の文章を#出力例 をもとに生成してください。生成された3行の文章は次のステップで使用をします。
- 1行目:** 入力テキストのコア・メッセージを英語で生成する。
- 2行目:**日本語のオリジナル入力テキスト。
- 3行目:**入力テキストを英訳したいもの。
#出力例:
- **Input Sentence:** "未来のテクノロジーが私たちの生活をどのように変えるかを考える。"
- ** 1行目:** "Future Technology"
- **2行目:** "未来のテクノロジーが私たちの生活をどのように変えるかを考える。"
- **3行目:** "Thinking about how future technology will change our lives."
⑤④で生成した3行のテキストを③で作成した画像に挿入してください。コードは以下のものを使用してください。
```
from PIL import Image, ImageDraw, ImageFont, ImageFilter
def add_embossed_text(draw, text, position, font, emboss_offset=1):
# エンボス効果のために白の影を追加
draw.text((position[0] - emboss_offset, position[1] - emboss_offset), text, font=font, fill="black")
draw.text((position[0] + emboss_offset, position[1] + emboss_offset), text, font=font, fill="black")
# 本来のテキストを白で描画
draw.text(position, text, font=font, fill="white")
def add_text_to_image(image_path, output_path, texts, font_path):
# 画像を開く
with Image.open(image_path) as img:
draw = ImageDraw.Draw(img)
# 各行のテキストのフォントサイズを設定
fonts = [
ImageFont.truetype(font_path, 35),
ImageFont.truetype(font_path, 70),
ImageFont.truetype(font_path, 35)
]
# 各行のテキストサイズを測定
text_sizes = [draw.textsize(text, font=font) for text, font in zip(texts, fonts)]
# 各行のテキスト間のスペース
line_spacing = 15
# テキスト全体の高さを計算
total_height = sum(size[1] for size in text_sizes) + line_spacing * (len(texts) - 1)
# 画像の中央にテキストを配置するための開始位置を計算
image_width, image_height = img.size
y = (image_height - total_height) / 2
for i, (text, font, size) in enumerate(zip(texts, fonts, text_sizes)):
# テキストの開始位置を計算
x = (image_width - size[0]) / 2
add_embossed_text(draw, text, (x, y), font)
y += size[1] + line_spacing
# 画像を保存
img.save(output_path)
# 使用例
image_path = "/mnt/data/final_smartphone.png" # 入力画像のパス
output_path = "/mnt/data/final_output_with_text.png" # 出力画像のパス
texts = ["これは1行目のテキストです。", "これは2行目のテキストです。", "これは3行目のテキストです。"]
font_path = "NotoSansJP-Black.ttf" # フォントファイルのパス
add_text_to_image(image_path, output_path, texts, font_path)
```
③最終画像を提供する。ダウンロード可能な画像を渡す。プロンプトの全体像の解説
今回使用したプロンプトではざっくりと下記のことを実行しています。
①入力されたテキストを元にdalle3で画像を生成
②生成された画像を1280×720pxにリサイズ(DALL-E 3では1792x1024pxの画像が生成されるがYouTubeサムネイルは1280×720pxのため)
③canvaで作った白い枠の画像を②の画像に重ねる
④入力されたテキストを元に3行のテキストを生成
⑤生成した3行のテキストを③で作成した画像に挿入
実は上記の日本語だけをGPTsのinstructionに入れてもGPTsがpythonのコードを実行してくれてサムネイルの生成はできるのですが、結構エラーが出てしまいます。
そこで今回はpythonのコードを入れこんだプロンプトをinstructionに入れてエラーを防いでいます。下記のような感じですね。
②①で生成された画像を1280×720にリサイズをする
コードを以下のものを使用する。
```
from PIL import Image
def resize_image(input_path, output_path, target_size=(1280, 720)):
with Image.open(input_path) as img:
# リサイズ
resized_img = img.resize(target_size, Image.ANTIALIAS)
# 保存
resized_img.save(output_path)
```「いやいやpythonのコードなんて書けねーよ!」という方もご安心ください。
pythonのコードもChatGPTに書いてもらいましょう。コードが1行も読めないし、書けない私でもできたので誰でもできると思います!
pythonのコードをChatGPTに書いてもらう方法
pythonのコードを書いてもらうために以下のGPTsを使用します。
このGPTsは指示すると指定したpythonのコードを書いてくれちゃいます!(すげえ)
例えばステップ②のDALL-E 3で生成された画像を1280×720pxにリサイズするコードを書いてと頼んでみた場合はこんな感じで返してくれます。

返してくれたコードをGPTsのinstructionにコピペして正しく実行ができてるかを確認。確認ができたら、次に書いてもらいたいpythonのコードをGPTsに指示して書いてもらってinstructionに入れて、、、の繰り返しを行うことでプログラミング初学者でも今回のようなプロンプトが書けてしまいます!
エラーが出てしまう場合
とは言ってもたまにできない場合があります。
そんなときもスクリーンショットや日本語でエラーの説明をpythonのGPTsに突っ込めば修正ができるのでエラーもへっちゃらです。
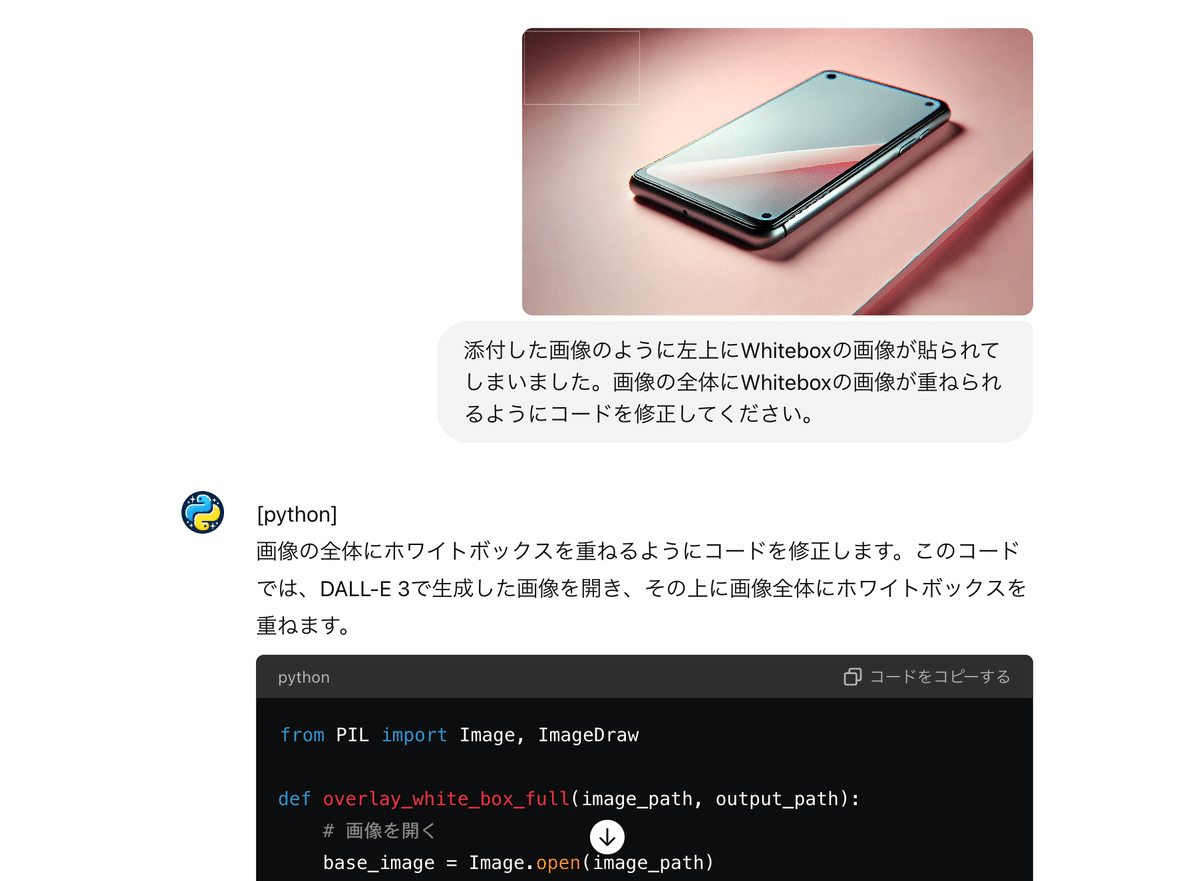
まとめ
ということでYouTubeサムネイルの自動生成のGPTs作成の解説は終わりです!今回のことを応用すれば色々なことが実現できると思いますのでぜひぜひご自身でGPTsの作成をしてみてください🙋そんな感じ!またね〜
関連記事
第2弾としてタイトルとカラーコードを入力するだけで4パターンのサムネイルを自動生成するGPTを作成しましたのでご興味のある方はぜひ見てみてください!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?