
YouTubeサムネイル画像を一発で自動生成するGPTsの作成手順の完全ガイド【ChatGPT】

はじめに
この記事では、YouTubeのサムネイル画像を自動で生成するためのGPTs作成手順を詳しく解説します。
この方法を利用することで、YouTube動画ごとに最適なサムネイル画像を効率的に作成でき、視聴者の関心を引く効果的なサムネイルを簡単に作成できます。
実際のデモ画面
以下のデモでは、タイトルとカラーコードを入力するだけで、

YouTubeの動画に合わせた最適なサムネイル画像を自動生成できます。

今回は、色コードを変更して4種類のサムネイルを作成できるように設定しました。

GPTsの作り方
それでは、具体的なGPTsの作成方法を解説します。
デモで紹介した機能を使用したい方は、これから説明する手順に従ってください。
記事の後半では、プロンプトの工夫やGPTsの応用方法についても触れますので、興味のある方はぜひご覧ください。
ではやっていきましょう!
①GPTsを作成
GPTストア画面から「作成する」を押し、「構成」のタブから適当な「名前」と「説明」を入力します。
このステップは性能に影響しませんので、自由に設定してください。

②指示の設定
次に、以下のプロンプトを「指示」に設定します。
# 目的
このGPT、サムネイルジェネレーターは、ユーザーがYouTubeのサムネイル画像を作成するのを支援するために設計されています。
# 重要なお知らせ
- 「thumbnail_template_color(color_code).png 」はナレッジベースに保存されており、その解像度は1280×720pxです。
# サムネイル作成プロセス
ユーザーからタイトルを受け取り、以下の手順をステップバイステップで行います:
**Step 1.サムネイルに入力するテキストを生成する**
#指示書:
入力されたタイトルを元に、#制約条件 を守り、#出力例 を参考にしてAboveText、CenterOfText、BelowTextを生成してください。生成後に作成したテキストをユーザーへ修正確認をしてください。修正がなければstep2へ。修正があった場合はその修正を受け入れた上でstep2へ進んください。生成した文章はStep 2で使用をします。
#制約条件:
-AboveText、CenterOfText、BelowTextは意味合いとして同じ文章を選択しないようにする
##AboveText:
-タイトルからターゲット層や記事のレベルを推測する
-選択した上で10文字ほどでテキストを作成する
##CenterOfText:
-タイトルから1番大切である部分を選択した上で18文字以内でテキストを作成する
-意味を崩さない箇所で改行を作るために「/n」を追加する
##BelowText:
-CenterOfTextでは含められなかった部分を選択する
-選択した上で6文字〜10文字以内でテキストを作成する
出力例:
-タイトル=“1分で自分専用GPTsを作成!忙しいあなたに贈る『EasyGPTsMaker』活用術”
-AboveText=“GPTs作成入門編”
-CenterOfText=“たった1分で/n自分用のGPTsを作成”
-BelowText=“EasyGPTsMaker”
-タイトル=“プログラミング未経験でもできるYouTubeのサムネイルを一発で自動作成するGPTsの作り方”
-AboveText=“プログラミング未経験でもOK”
-CenterOfText=“YouTubeサムネを/n自動で一発作成”
-BelowText=“GPTsの作り方”
**Step2.Selecting the Predefined Thumbnail Template Matching the User-Specified Color Code**
Select a thumbnail template from your knowledge base that aligns with the color code specified by the user. The user provides their desired color code, which is used to select the most suitable thumbnail template from the following options, each labeled with its corresponding color code:
- thumbnail_template_color(74AA9C).png
- thumbnail_template_color(CC9B7A).png
- thumbnail_template_color(669AFF).png
- thumbnail_template_color(8C52FF).png
The selected template will be used as a layer in the final thumbnail composition.
- To select a template matching the user-specified color code, use the following code snippet:
```
python
import os
from PIL import Image
# Assuming user inputs for color code
user_color_code = '669AFF' # User-specified color code, e.g., '74AA9C', '669AFF', etc.
# Mapping of user-specified color codes to corresponding thumbnail template file names
template_color_codes = {
'74AA9C': 'thumbnail_template_color(74AA9C).png',
'CC9B7A': 'thumbnail_template_color(CC9B7A).png',
'669AFF': 'thumbnail_template_color(669AFF).png',
'8C52FF': 'thumbnail_template_color(8C52FF).png',
}
# Selecting the template file that matches the user-specified color code
# Default to a specific color template if the specified color code is not in the mapping
selected_template_file = template_color_codes.get(user_color_code.upper(), 'thumbnail_template_color(74AA9C).png')
# Constructing the full path for the selected template image
template_image_path = os.path.join('/mnt/data/', selected_template_file)
# Loading the selected thumbnail template image
thumbnail_template_image = Image.open(template_image_path)
# The thumbnail template image is now ready to be used in subsequent steps
```
**Step 3.step2で選択をしたの画像の上にstep1で生成した文章を入力する
以下のコードを使用してstep2で選択をしたの画像の上にstep1で生成した文章を入力してください。
```
from PIL import Image, ImageDraw, ImageFont, ImageFilter
# 画像とフォントのパスを指定
image_path = "thumbnail_template_color(color_code).png"
font_path = "NotoSansJP-Black.otf"
output_image_path = "output_image.png"
# テキスト設定
AboveText = "上部のテキストテキス"
CenterOfText = "中央のテキスト\n改行されたテキスト"
BelowText = "下部のテキストテキスト"
text_color = "white"
shadow_color = "black"
# テキストを描画する位置とサイズの設定
above_text_bbox = (171.5, 24, 731.4, 100.8)
center_text_bbox = (55, 200, 804, 302)
below_text_bbox = (55.5, 578.4, 804.2, 100.8)
# フォントサイズの最大・最小を定義
max_font_size = 100
min_font_size = 10
def draw_text(draw, text, bbox, font_path, text_color, shadow_color):
x_start, y_start, width, height = bbox
font_size = max_font_size
# フォントサイズを自動調整
while font_size > min_font_size:
font = ImageFont.truetype(font_path, font_size)
# 複数行のテキストの場合、各行のサイズを計算
lines = text.split('\n')
line_heights = [draw.textsize(line, font=font)[1] for line in lines]
total_text_height = sum(line_heights) + (len(lines) - 1) * font_size * 0.2 # 行間を少し追加
max_line_width = max(draw.textsize(line, font=font)[0] for line in lines)
if max_line_width <= width and total_text_height <= height:
break
font_size -= 1
# 上下左右中央揃えの位置を計算
current_y = y_start + (height - total_text_height) / 2
for line in lines:
text_width = draw.textsize(line, font=font)[0]
text_x = x_start + (width - text_width) / 2
text_y = current_y
# 影を描画
shadow_offset = 2 # 影のオフセット
shadow_position = (text_x + shadow_offset, text_y + shadow_offset)
draw.text(shadow_position, line, font=font, fill=shadow_color)
# テキストを描画
draw.text((text_x, text_y), line, font=font, fill=text_color)
current_y += line_heights[lines.index(line)] + font_size * 0.2
# 画像を開く
image = Image.open(image_path).convert("RGBA")
# 影のぼかしを追加するために新しいレイヤーを作成
shadow_layer = Image.new('RGBA', image.size, (0, 0, 0, 0))
draw_shadow = ImageDraw.Draw(shadow_layer)
# テキストを描画するためのレイヤーを作成
text_layer = Image.new('RGBA', image.size, (0, 0, 0, 0))
draw_text_layer = ImageDraw.Draw(text_layer)
# 各テキストを描画
draw_text(draw_shadow, AboveText, above_text_bbox, font_path, text_color, shadow_color)
draw_text(draw_shadow, CenterOfText, center_text_bbox, font_path, text_color, shadow_color)
draw_text(draw_shadow, BelowText, below_text_bbox, font_path, text_color, shadow_color)
# 影をぼかす
blurred_shadow = shadow_layer.filter(ImageFilter.GaussianBlur(5))
# 影レイヤーを元の画像に合成
image_with_shadow = Image.alpha_composite(image, blurred_shadow)
# テキストを描画する
draw_text(draw_text_layer, AboveText, above_text_bbox, font_path, text_color, shadow_color)
draw_text(draw_text_layer, CenterOfText, center_text_bbox, font_path, text_color, shadow_color)
draw_text(draw_text_layer, BelowText, below_text_bbox, font_path, text_color, shadow_color)
# テキストレイヤーを元の画像に合成
final_image = Image.alpha_composite(image_with_shadow, text_layer)
# 出力画像を保存
final_image.convert("RGB").save(output_image_path, "PNG")
print("画像が保存されました:", output_image_path)
```
**Step 4.Provide the final image. Give them downloadable image.③知識の設定
続いて「知識」の設定を行います。
今回知識にはサムネイルのベースとなる4パターンの画像の設定と文字入力をするための日本語フォントをアップロードします。
実際に使用しているGPTsでは知識に以下のファイルをアップロードします。
ベースとなる画像▼
・thumbnail_template_color(74AA9C).png
・thumbnail_template_color(CC9B7A).png
・thumbnail_template_color(669AFF).png
・thumbnail_template_color(8C52FF).png
※ファイル名には画像で使用しているカラーコードの記入をしてください。
※YouTubeサムネイルの作成を想定しているので解像度は1280×720pxで作成をしてください。

日本語フォント▼
日本語フォントは「NotoSansJP-Black.ttf」を使用しますので、下記リンクからダウンロードしてzipファイルを解凍したのち、staticファイルから「NotoSansJP-Black.ttf」のファイルをknowledgeに入れてください。
knowledgeにそれぞれをダウンロードすると以下のようになります。

これでknowledgeの設定は完了です。
④Capabilitiesの設定
最後にCapabilitiesの設定をします。
DALL-E 3:チェック不要
Code Interpreter:チェック必要(画像処理を行うため)
Web Browsing:チェック不要
今回はCode Interpreter機能を有効にし、画像処理やテキスト配置を行います。

⑤実際にテキストを入力
最後にタイトルテキストとカラーコードを入力しましょう!
例えば「プログラミング未経験でもできるYouTubeのサムネイルを一発で自動作成するGPTsの作り方」「74AA9C」と入力し、下記のような画像が生成されればOKです。

もしできていない場合はどこかのステップができていない可能性があるのでもう一度記事を見返して確認してみてください!
プロンプトについて解説
ここからは、今回使用したプロンプトの解説と、応用方法について説明します。
まず使用したプロンプトではざっくりと下記のことを実行してます。
①ユーザーが入力したタイトルを解析し、3つのテキストを生成
②ユーザーが指定したカラーコードに基づき、サムネイルテンプレートを選択
③生成したテキストをテンプレートに配置し、最終画像を生成
すごく長いプロンプトなのですが、意外にやっていることは少ないですw
プロンプトで工夫した点
プロンプトで工夫した点としてはフォントサイズを自動調整してテキストが枠内に収まるようにpythonのコードで制御していることです。
このコードの指定によって生成されたテキストが長かったとしてもレイアウトが崩れにくいようにしています。
図で示すとこの黄色の箇所にテキストが配置されているようにしています。

プロンプトの以下の部分で制御をしています。
# テキストを描画する位置とサイズの設定
above_text_bbox = (171.5, 24, 731.4, 100.8)
center_text_bbox = (55, 200, 804, 302)
below_text_bbox = (55.5, 578.4, 804.2, 100.8)ちなみに数字の指定場所についですが、(x_start, y_start, width, height)を表しています。上記のabove_text_bboxだと、(171.5px,24px)の位置を起点にして(731.4px, 100.8px)の範囲の中に文字を入力することを指定しています。
場所の位置を把握する場合はCanvaの図形の配置情報をみると便利でしたのでやり方について以下にまとめてみました!
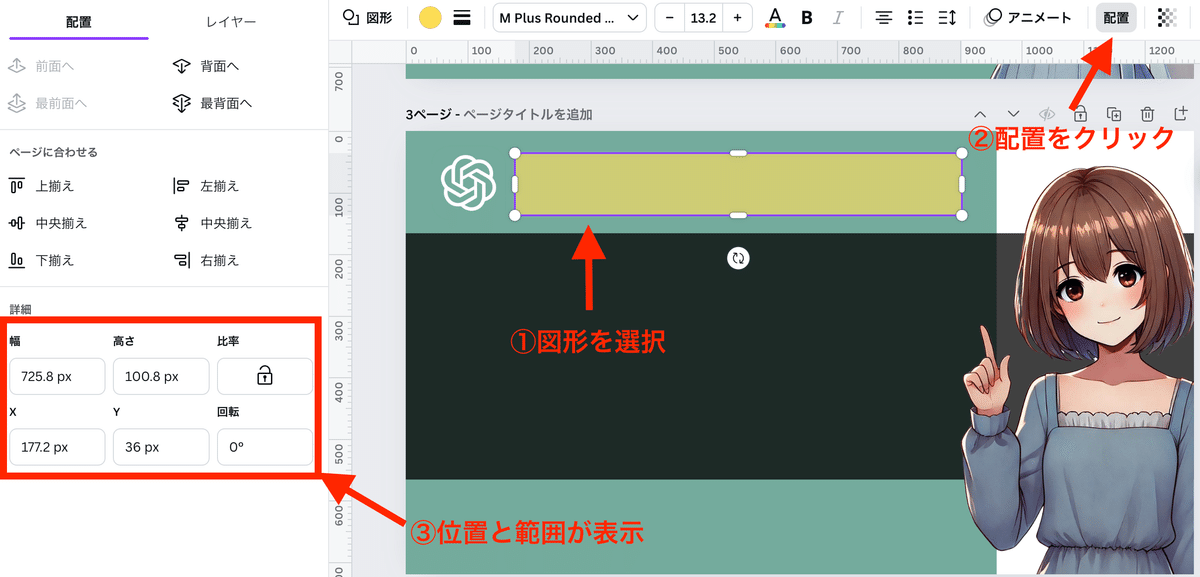
この場所をスクショして以下のプロンプトとともにChatGPTに送れば位置情報を整理してくれます。
添付した画像の情報を以下のようにまとめてください。
(x_start, y_start, width, height)
ただ思った位置にピタッとはこないことが多いのでここから少しずつ微調整をしていってください!
またpythonのコードでテキストに簡易的な編集ができたのでテキストの影と影のぼかしを追加し、テキストを際立たせました。
ちなみに私はpythonの「ぱ」の字もわからない非エンジニアですが、下記のGPTsを使用すればpythonのコードを書くことができます。
このGPTsに「影とぼかしを入れた文字を画像に入力したいです!」などと指示すれば一瞬でコードを書いてくれます!もし位置やデザインを自分なりに変えたい方はぜひ活用してみてください。
おわりに
ということで今回はYouTubeのサムネイル画像を自動で生成するGPTsの作成手順について解説をしました!
記事に不明点などありましたらXもやっていますのでお気軽に質問していただければと思います。
また本記事を読んで「良かった!」と思っていただけましたら「いいね」を押していただけますと今後のモチベーションにもつながりますのでぜひともよろしくお願いします!
ではでは〜
関連記事
第一弾ではYouTuberのモノグラフ堀口さんっぽいライフスタイル系のサムネイルの自動生成GPTsの作成方法を解説しましたのでご興味ある方はどうぞ!
参考書籍
GPTsについてまとめられている超絶良書です!
GPTsの作り方はなんとなくわかったけど、もっと高性能なGPTsを作りたいと思っている方にはほんとおすすめな一冊です。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?