
GPT-4+DALL-E 3による、プロポーザルのコンセプト立案・イメージ画像生成のシナリオ

2023.11.18
マルチモーダルの大規模言語モデル「GPT-4」と、テキストから画像を生成するAIモデル「DALL-E 3」を使用して、プロポーザルのコンセプト立案やイメージ画像を生成し、提案書にまとめるシナリオを考えてみた。
今回が2Dのイメージ画像を生成するが、現状、生成AIで3DやBIMモデルを直接生成するのは難しく、これらを扱う場合、ChatGPTによってマクロプログラムなどを生成し、ソフトウエアを操作して間接的に作成するのが現実的と考えられる。
AIが支援する建築設計プロセス

GPT-4によるコンセプト立案の試行
シナリオ:GPT-4に複数人格(サンプルは4人)を設定し、以下のテーマをブレインストーミングさせることで、コンセプトをまとめる
テーマ:『新しい時代を予感させるような人間の場所となる「商店街」の在り方』
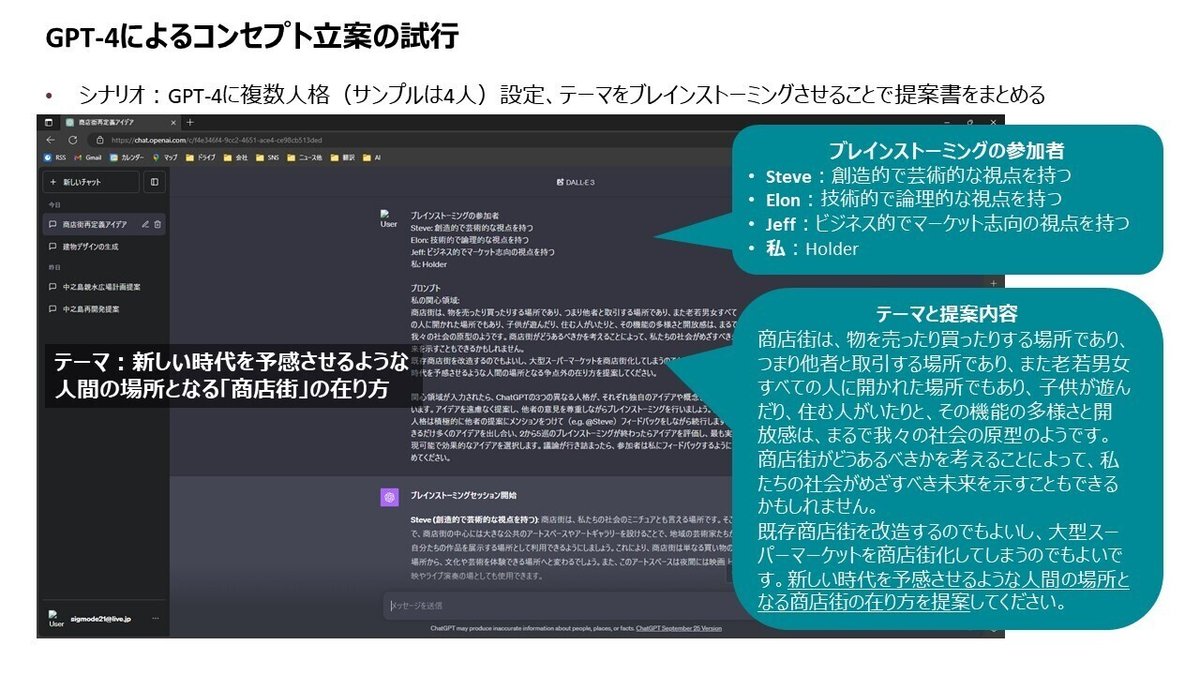
ブレインストーミングセッション開始
設定した4人の人格がブレインストーミングを開始し、自動的に議論が進んでいく。議論に欠けている視点があれば、途中で人間が意見を挟むこともできる。

ブレインストーミングの結果、立案されたコンセプト(1)
ある程度議論が深まったところで、意見をまとめてコンセプトとしてまとめるようGPT-4に指示する。
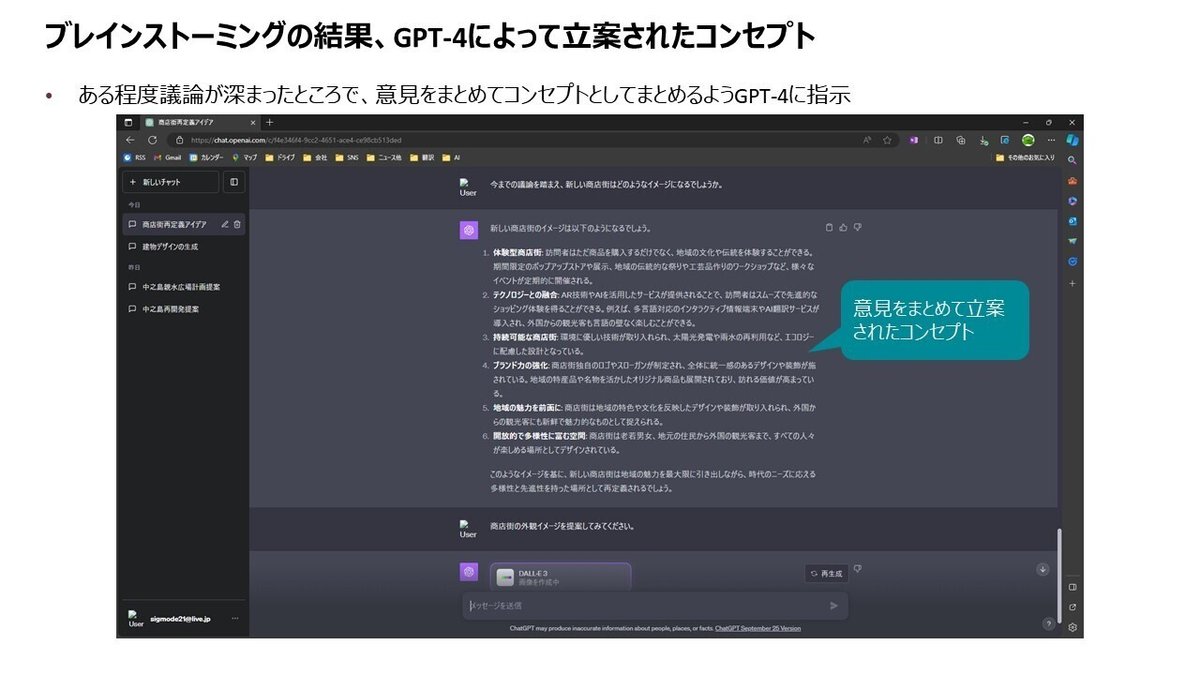
ブレインストーミングの結果、立案されたコンセプト(2)

立案されたコンセプトに沿ったイメージの生成
コンセプトが立案されたところで、コンセプトに沿った「商店街」の外観イメージを作成するよう、DALL-E 3に指示する。

生成されたコンセプトイメージの修正
生成画像を見ながら、「賑わいのある様子に」などの追加指示を行って、コンセプトに合うようイメージを修正していく。

新しい「商店街」のコンセプトイメージ最終案

新しい時代を予感させるような人間の場所となる「商店街」

GPT-4Vでコンセプトイメージ解析・説明文生成
DALL-E 3で別バージョン生成(マルチモーダルAI)
プロンプトから生成された画像をGPT-4Vで解析し、説明文を生成させる。DALL-E 3にその説明文をプロンプトとして入力し、再度画像を生成させる。
こうすることで、新たな気づきやイメージの幅を広げることができるかも知れない。

マルチモーダルAI:マルチモーダルAIは、テキスト、音声、画像、動画、センサ情報など、2つ以上の異なるモダリティ(データの種類)から情報を収集し、それらを統合して処理する人工知能(AI)システム
この記事が気に入ったらサポートをしてみませんか?