x2010-成果物:SOX指数の時系列予測

「このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています」
はじめに
2023年12月下旬から、Aidemy Premiumにて「データ分析コース3ヶ月」を受講しました。
今回、成果物課題として「SOX指数の時系列予測」をテーマとした課題の作成を行いました。
Aidemy Premiumの受講を決めたのは、還暦を迎える2024年に前職で培った品質管理のスキルをブラッシュアップさせることを目的にデータ分析の学び直しを決意し、短期間で結果が出せるプログラムがあるAidemy Premiumの受講を決めました。
今回の成果物課題を通じて感じたことは、改めてデータ分析の世界が好きなんだという感覚と、今の自分ではここまでしかできないという限界感と未来の可能性を感じることができた感覚で、久しぶりに「無知の知」を痛烈に味わうことができました。
その結果、「データ分析」そのものが好きなのではなく、目的(未来予測、戦略立案)を達成するために手段として「データ分析を使うこと」が好きであるという自分の強み・価値観を認識することができました。
未熟な点も散見されると思いますが、一読いただけますと幸いです。
1.目的
ⅰ)時系列予測を用いて、SOX指数の予測値と実測値の乖離について分析を行う事
ⅱ)乖離があった場合、乖離の理由/根拠について考察を行う事
ⅲ)乖離の理由/根拠について考察に対し、今後の課題(対策)を考える事
2.用いた手法、予測に使用した銘柄の紹介
1)手法の紹介
・GoogleColaboratoryにてPython3を使用
・時系列予測を用いて、月次ベースで一定期間のSOX指数を予測し、同じ期間の実測値と比較をした。その上で、予測値と実測値の乖離がどの程度あるかを検証し、検証結果に対して考察を行った。
2)指数の紹介
・フィラデルフィア半導体指数【SOX指数】
・SOX指数は、半導体製品を生産する企業の株価の動きをまとめたもので、この業界の健康状態を反映している。日々の生活で欠かせないスマートフォンやパソコンなど、多くの電子機器に半導体が使われていることを考えると、この指数の動きを理解することは、非常に価値があると言える。
3.コードの解説
1)指数データを取得するためのプログラム作成
「SOX指数の時系列予測」を行うために、「https://jp.investing.com/」から指数データを取得し、これを基にして今後のコードを組み立てていく。
#1)指数データを取得するためのプログラム作成
!pip install mplfinance japanize-matplotlib2)ローソク足チャートの設定
時系列予測をグラフとして可視化した上で予測値と実測値の乖離について調べたいので、日付と時間の操作、金融データの可視化、日本語でのグラフ表記、データ分析、および効率的なループ作成を行うためのライブラリやモジュールをインポートするためのコードを作成した。
from datetime import datetime
import mplfinance as mpf
import japanize_matplotlib
import pandas as pd
import itertools3)データの準備
取得した指数データを含むCSVファイルをGoogleドライブに取り込み、列名を英語に変更して、日付をインデックスとして設定し、確認のため最終的なデータフレームを表示させた。これにより、データ分析や可視化を行う前にデータを適切な形式に整理することができた。
df = pd.read_csv('https://drive.google.com/file/d/1SpQZtoE0ihthXRtpCWzFsA_PAvOiy-Ac/view?usp=sharing')
df.rename(columns={'日付け': 'Date'}, inplace=True)
df.rename(columns={'終値': 'Close'}, inplace=True)
df.rename(columns={'始値': 'Open'}, inplace=True)
df.rename(columns={'高値': 'High'}, inplace=True)
df.rename(columns={'安値': 'Low'}, inplace=True)
df.rename(columns={'出来高': 'Volume'}, inplace=True)
df.rename(columns={'変化率 %': 'Rate'}, inplace=True)
df.set_index('Date', inplace=True)
df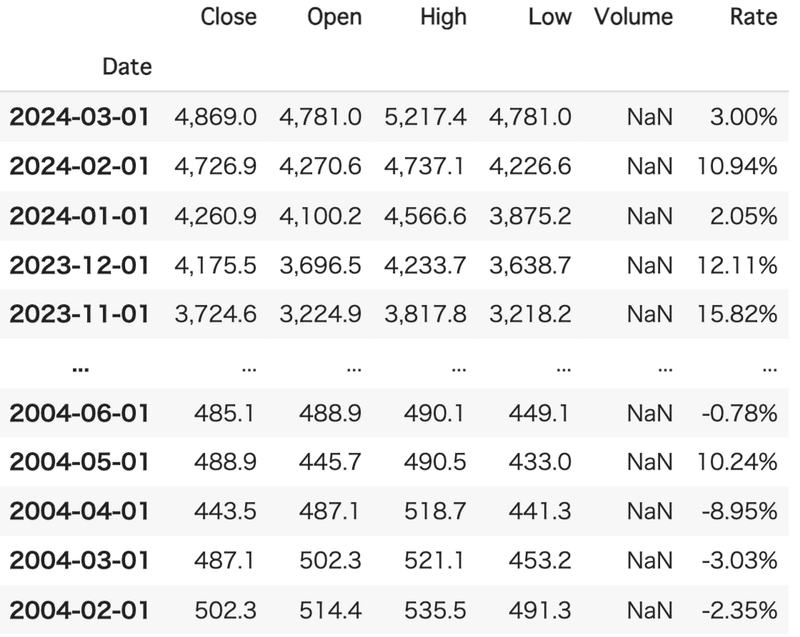
次に、日付データの形式変更、数値データのクリーニングと変換を行った。
このコードによって、金融データの日付は適切な形式に変換され、価格データ(終値、始値、高値、安値)はカンマが除去され数値型に変換される。
これにより、このデータを用いたさらなる分析や可視化が容易に行えるようになる。
# 'Date' 列を日時型に変換し、データフレームのインデックスとして設定
df.index = pd.to_datetime(df.index)
df['Close'] = df['Close'].str.replace(',', '') # カンマを削除
df['Close'] = pd.to_numeric(df['Close'], errors='coerce')
df['Open'] = df['Open'].str.replace(',', '') # カンマを削除
df['Open'] = pd.to_numeric(df['Open'], errors='coerce')
df['High'] = df['High'].str.replace(',', '') # カンマを削除
df['High'] = pd.to_numeric(df['High'], errors='coerce')
df['Low'] = df['Low'].str.replace(',', '') # カンマを削除
df['Low'] = pd.to_numeric(df['Low'], errors='coerce')4)移動平均線の計算、チャートグラフの出力
前節でグラフを出力・設定するためのコードとデータをクリーニングするコードを作成したので、この節ではチャートグラフで価格の推移の指標として使用する「移動平均線の計算」と、実際にチャートグラフをグラフを出力するコードを作成した。
ここまでが、時系列予測を行うための事前準備となり、次の5節ではこの出力したデータをもとに、時系列予測を行う。
#3)移動平均線の計算、チャートグラフの出力
# 対象期間は、2004/2/1∼2024/3/1
# 移動平均線の計算
df["SMA25"] = df["Close"].rolling(window=25).mean()
df["SMA50"] = df["Close"].rolling(window=50).mean()
df["SMA75"] = df["Close"].rolling(window=75).mean()
# チャートグラフの出力
import matplotlib
%matplotlib inline
# チャートグラフの表示設定
df_start = df.loc[datetime(2004,2,1).strftime("%Y-%m-%d"):]
df_start.fillna(0, inplace=True)
df_start.sort_index(inplace=True)
mpf.plot(df_start, title="SOX_index", type="candle", mav=(25, 50, 75), xrotation=0, datetime_format="%Y/%m", tight_layout=False, volume=False, figratio=(19,9), style="yahoo", ylabel="Index")
add_day_ave = [
mpf.make_addplot(df_start["SMA25"], panel=0, color="b", width=1, alpha=0.7),
mpf.make_addplot(df_start["SMA50"], panel=0, color="g", width=1, alpha=0.7),
mpf.make_addplot(df_start["SMA75"], panel=0, color="r", width=1, alpha=0.7)
]
mpf.plot(df_start, type='candle',datetime_format='%Y/%m',xrotation=0, tight_layout=False, volume=False, figratio=(19,9), style='yahoo')
df.loc[datetime(2002,2,1).strftime("%Y-%m-%d"):]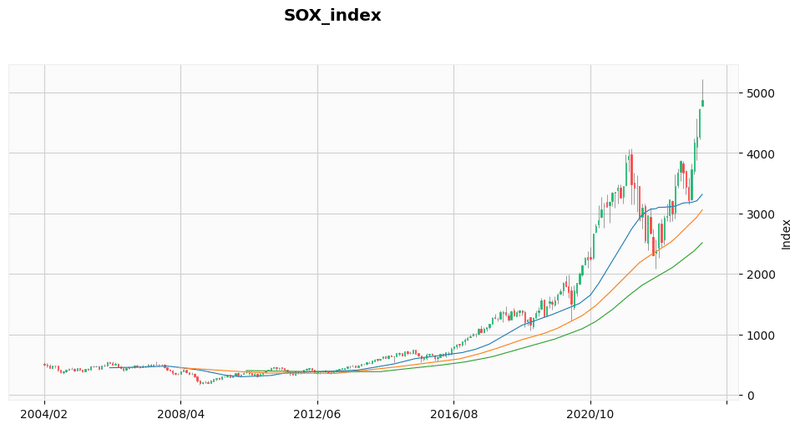
5)時系列予測
この節では、実際に時系列予測を行った。
今回については、自分の時系列予測に対する理解が浅い事を理由として、時系列予測を6段階に分けて、整理した。
5-1: 時系列予測を設定
予測のためのコードを入力、実際に予測をする範囲を設定した。
(予測範囲は、2023/04~2025/03で設定)
#5-1:時系列予測を設定
# 時系列予測のコード
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from pandas import datetime
5-2: 予測範囲を出力
前段階を踏まえて、予測範囲の出力した。
時系列で予測する営業月は12ヶ月で設定した。
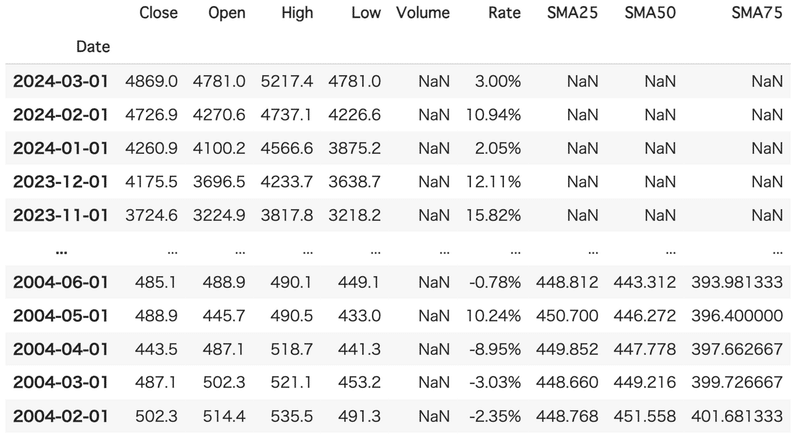
#5-2:予測範囲を出力(予測する営業月は12ヶ月で設定)
df.head(12)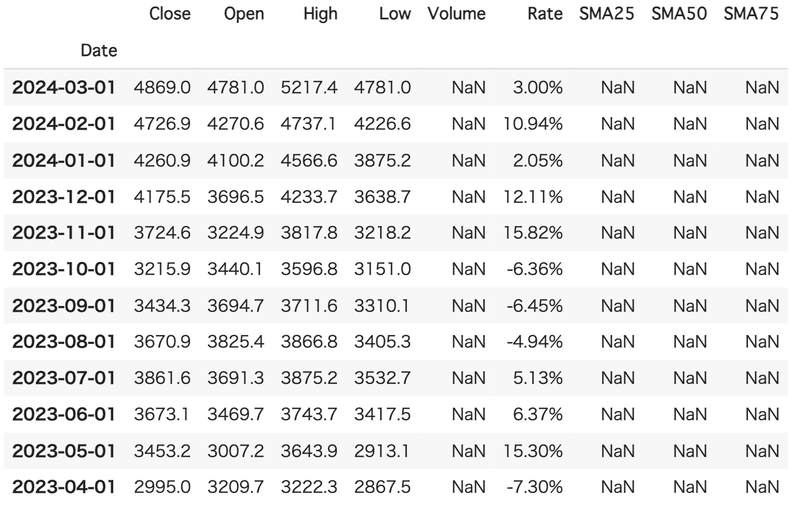
5-3: 終値でdfを作成
終値を基準として、dataframeを作成。
#5-3:終値でdfを作成
df['Close'].index5-4: 2023/03/01までの終値を整理
2023/04/01~2025/03/01を予測するための準備として、2023/03/01までのデータを整理するコードを作成した。
#4-4:2023/03/01までの終値を整理
# 終値で2023/03/01まで出力
stock_price_close = df['Close'].loc[:"2023-03-01"].copy().asfreq('MS')
stock_price_close.tail(12)5-5: SARIMAモデル導入の前段階
ここは、Aidemyの時系列予測の添削課題のコードを流用した。
周期パラメータについては、半導体需要の筆頭であるスマートフォンの更新周期を考慮して24ヶ月で設定した。
#5-4:SARIMAモデル導入の前段階
# orderの最適化関数(添削課題のコードを流用,アレンジ)
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]
# 周期パラメータはスマートフォンの更新周期を考慮して24ヶ月に設定
best_params = selectparameter(stock_price_close, 24)5-6: SARIMAモデルを導入,予測を実行, 実測値と予測値をグラフに反映
SARIMAモデルを使って予測を実行した。その上で、実測値(青線)と予測値(赤線)をグラフに反映し乖離について分析を行った。
#4-6:SARIMAモデルを導入,予測を実行, 実測値と予測値をグラフに反映
# SARIMAモデルを導入
SARIMA_model = sm.tsa.statespace.SARIMAX(stock_price_close, order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()
# 予測を実行
pred = SARIMA_model.predict('2023-04-01', '2025-03-01')
# 実測値と予測値をグラフに反映
plt.plot(stock_price_close)
plt.plot(df['Close'].loc["2023-03-01":], "b")
plt.plot(pred, "r")
plt.show()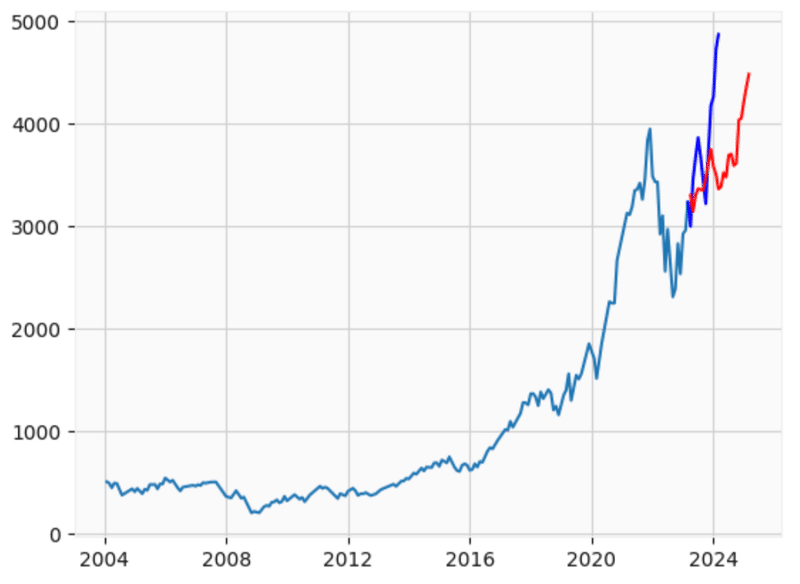

4.予測結果
ⅰ)予測では、2023/4以降の指数は2024/10まで3500円を中心に緩やかに上昇する傾向を描き、2024/11以降に4000円を突破したあとは急激に上昇する傾向を描くと予想された。
実測値と予測値とを比較すると、2023/11までは同じような傾向をたどるもの、2023/12以降は実測値が急激に上昇し、予測より11ヶ月早く4000円を突破するという結果になった。
⇒予測値と実測値の軌跡の形はほぼ同じだが、立ち上がり方に違いがあり、時期の乖離(時期ズレ)が認められた。
ⅱ)予測値と実測値が時期ズレとなった要因については、次節で説明を行う。
5.予測結果に対する考察
予測結果と実測値が時期ズレとなったことに対して考察します。
一般的に予実差が発生する要因は以下の項目が考えられます。
データの不足や品質:
予測モデルが適切なデータで訓練されていない場合、または使用されたデータに誤りがある場合、予測の精度が低下します。モデルの適切性:
SARIMAモデルは季節性やトレンドを考慮するものですが、使用されたパラメータ(季節性の周期、トレンド、ノイズのレベル)がSOX指数の実際の動きを正確に反映していない場合、予測誤差が大きくなります。外部影響因子:
経済状況、政治的な出来事、技術的な革新、市場の心理など、モデルに含まれていない外部因子が実測値に影響を与えた可能性があります。季節性とトレンドの変化:
グラフによると、予実差に一定の季節性やトレンドは見られませんが、期間によって異なる動きが見られるかもしれません。これは、市場の変動や特定の期間における独特の要因によるものかもしれません。
これらの要因が考えられますが、今回は3.外部影響因子ついて詳しく見ていくこととし、主に次の3つの要因による半導体需要の急拡大がSOX指数の急上昇に影響していると結論付けました。
5-1)生成AIの急拡大
5-2)グローバルでのEV普及
5-3)COVID19影響の正常化
5-1)生成AIの急拡大
生成AI技術の進展とその普及は、半導体業界における新たな需要を創出しました。特に高性能なAIチップやデータ処理半導体への需要増加が顕著です。この技術革新は、予測モデルにおいて十分に考慮されていなかった可能性があり、実測値が予測値を上回る一因となったと推察されます。
今後、生成AI関連の技術革新と市場動向をより詳細に分析し、予測モデルの精度を向上させる必要があります。
5-2)グローバルでのEV普及
電気自動車の市場拡大は、車載用半導体の需要を急速に高めました。特に、パワートレイン、バッテリー管理システム、運転支援システムなど、EV特有の要件に応じた半導体が重要となっています。
この動向は、予測モデルが過小評価していた要素の一つであり、実測値の予測値に対する超過を説明する要因となり得ます。
EV市場の成長予測をより正確に反映させることで、予測の精度を高めることが期待されます。
5-3)COVID19影響の正常化
COVID-19パンデミックは、半導体産業における需給バランスに大きな影響を与えました。初期の需給の乱れが解消され、市場が正常化したことは、予測モデルが捉え切れていなかった可能性があります。
在庫の正常化、供給網の安定、そして市場需要の回復は、SOX指数の実測値を予測値以上に押し上げる主要因となりました。
今後、外部ショックや市場の回復傾向をモデルに組み込むことが、より正確な予測につながります。
6.今後の課題
予測モデルと実測値との差異に関して、生成AIの急拡大、EV普及の拡大、およびCOVID-19パンデミックの影響の正常化という三つの重要な要因を考察しました。
これらの要因は、現行の予測モデルにおける未考慮の変動要素を示しており、今後のモデル更新時にはこれらの要素をより詳細に取り入れることが必要です。具体的には、技術進化の速度、市場動向の変化、および外部環境の変動を定期的にレビューし、予測モデルに反映させることで、予測の精度を向上させることができるものと考えます。
6-1)生成AIの影響について
技術の発展と市場適用の速度を評価し、これを半導体の需要予測に組み込むことが重要であると考えます。
6-2)EV市場について
新車の販売予測、電動化技術の進展、および政策的な支援の影響を定期的に分析し、これらの情報をモデルに統合することが必要だと考えます。
6-3)COVID-19パンデミックの影響について
サプライチェーンの回復状況、在庫レベルの変動、および消費者の行動変化を継続的に監視し、これらの要素が予測モデルに正確に反映されるようにする必要があると考えます。
これらの考察を通じて、予測モデルの継続的な改善と更新を行い、SOX指数のより正確な予測を目指すことが、業界の動向を理解し、投資戦略を立てる上で極めて重要であると言えます。
今後も定期的なデータの分析とモデルの調整を行うことで、市場の変化に迅速に対応し、予測の信頼性を高めていくことが求められます。
7.今後の活用
当初の結果では、過去1年の予測値と実測値がほぼ一致していて非常に違和感を感じていたのですが、修了期限も迫っているので違和感をもったまま強引に成果報告をまとめていました。
しかしながら、結果の考察を記述するにあたり、どうしてもその違和感を払拭することができず、独力でいろいろと調べた結果、訓練データの期間指定が適切ではないことがわかり、その期間を修正した結果、それらしい結果になりました。
個人的にも、この1年の半導体需要の動きは急回復してきた感覚をもっていましたので、その仮説の裏付けとなる結果が得られたので大変満足しています。この満足感はたまらん。
この快感を得るために、これまで学んできたように思います。
データ分析スキルとしては小さな一歩かもしれませんが、還暦を迎えた生涯現役を目指す私にとっては大変大きな一歩となりました。
今後は、「中小企業の”ものづくり現場”のDX化」を推進する立場で、今回学んだデータ分析スキルを活用していきたいと思います。
8.おわりに
課題の消化が遅れ、成果報告に取り掛かったのがつい3週間前。
一時は講座を修了することを断念することも頭によぎりましたが、青木様の励ましや遠藤(T)チューターの私の身の丈にあった的確なサポートにより、最後の成果報告まで辿り着けました。
お二人には本当に感謝しています。ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?