

ローカル環境のエミュレーターでFirebase Extensionsのfirestore-bigquery-exportを利用し、BigQueryにデータ連携してみた

はじめに
こんにちは、SHIFTの開発部門に所属している Katayama です。
Firebase Extensionsを利用すると、あらかじめパッケージ化された便利機能を簡単に自身のアプリ開発に組み込むことができる。
利用できる Extentions はExtensions Marketplace by Firebaseから探す事ができ、例えば以下のような Extentions がある。
Translate Text in Firestore
Cloud Firestore コレクションに書き込まれた文字列(テキストメッセージなど)を翻訳するStream Firestore to BigQuery
Cloud Firestore コレクション内のドキュメントを BigQuery にエクスポートする
今回は Cloud Firestore のコレクションデータを BigQuery に流す、Stream Firestore to BigQuery をFirebase Local Emulator Suiteと呼ばれるエミュレーターを利用して、ローカル環境で実行してみたいと思う。
また、データを連携する際、デフォルトではコレクションのデータは JSON 型で格納されるので、それをクエリしやすくするために BigQuery のビューを作成する、という事もおまけとしてやってみたいと思う。
※今回のデータ連携の全体を図示すると以下のようになる。

※今回、BigQueryについては本番のGCP上のBigQueryに接続するが、BigQueryのエミュレーターもあるのでそちらに接続するようにして検証することもできる。それについては、次回の記事で取り上げる。
Firebase CLI での Stream Firestore to BigQuery の初期設定
まずは、"firebase ext:install firebase/firestore-bigquery-export"コマンドで「Stream Firestore to BigQuery」(firebase プロジェクトでは firestore-bigquery-export という ID で識別される)の初期設定を行っていく。


上記のように CLI と対話していくと、firebase.json が更新され、extensions/firestore-bigquery-export.env が作成される。
{
...
"extensions": {
"firestore-bigquery-export": "firebase/firestore-bigquery-export@0.1.31"
}
}BACKUP_COLLECTION=users_bq_failed
BIGQUERY_PROJECT_ID={projectId}
COLLECTION_PATH=users
DATASET_ID=firestore_export
DATASET_LOCATION=asia-northeast1
LOCATION=asia-northeast1
TABLE_ID=users
TABLE_PARTITIONING=NONE
TIME_PARTITIONING_FIELD_TYPE=omit
USE_NEW_SNAPSHOT_QUERY_SYNTAX=yes
WILDCARD_IDS=false各設定の意味について少し補足する。
COLLECTION_PATH
BigQuery にデータ連携する Firestore のコレクションのパス
今回は特にワイルドカードを使っていないが、ワイルドカードを利用したパスも設定できる
DATASET_ID
テーブル・ビューなどへのアクセスを制御するための論理的な概念で、スキーマだと思って問題ないだろう
TABLE_ID データセット内のテーブルやビューに使用される識別用のプレフィックスで、今回は users にしているので、テーブルとして user_raw_changelog が作成され、user_raw_latest がビューとして作成される(実際に作成されるテーブル・ビューの詳細は後続の章で見ていく)
Firebase Local Emulator Suite(Firebase のエミュレーター)を起動し、ローカル環境から BigQuery にデータ連携する
エミュレーターの起動は過去の記事などでやった時と同じで、"firebase emulators:start"コマンドを実行するだけ。

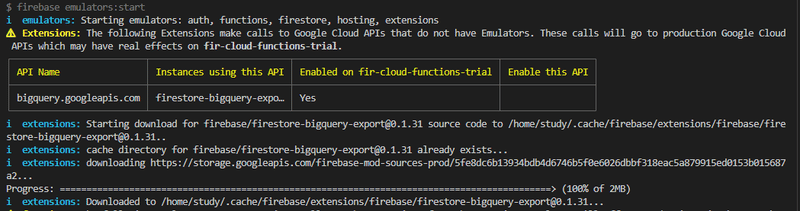
※一番最初にエミュレーターを起動すると、以下の画像のように、"~/.cache/firebase"以下に Extentions のソースコードがダウンロードされる(エミュレーターはこのコードを実行し、ローカル環境で Extentions を動かす)。
上記でエミュレーターが起動できると、以下のようにエミュレーターの UI で Extentions の設定やテストに関しての手順を確認できる。

では、実際に users コレクションにデータを追加してみて、それが BigQuery に連携されるか?を確認してみる。
Firebase エミュレーターの Firestore にユーザーデータを追加すると、以下のログの通り、BigQuery にデータが連携できている事が確認できる。


GCP のダッシュボードを確認してみると、データが期待通りに格納されている事が確認できる。


ちなみに、データの更新を行うと、データの更新毎にログのテーブルにデータが作成され、ビューでは最新の状態を取得できる。


※Stream Firestore to BigQuery では、コレクションごとに拡張機能のインストール・設定が必要になる。
複数のコレクションに対して拡張機能を利用も試してみたが、それについては「おまけ」の「複数の Stream Firestore to BigQuery を設定する」を参照。
おまけ
複数の Stream Firestore to BigQuery を設定する
初期設定は上記の「Firebase CLI での Stream Firestore to BigQuery の初期設定」の章でやった事を繰り返せばいい。
以下のように"firebase ext:install firebase/firestore-bigquery-export"コマンドを実行すると、以下のように別の ID を割り振ってくれるので、その ID で設定を進める。

後は CLI と対話しながら設定をしていくだけ。今回追加した 2 つ目の Stream Firestore to BigQuery の設定は以下のようにした。
BIGQUERY_PROJECT_ID={projectId}
COLLECTION_PATH=groups/{groupId}/member_users
DATASET_ID=firestore_export
DATASET_LOCATION=asia-northeast1
LOCATION=asia-northeast1
TABLE_ID=group_member_users
TABLE_PARTITIONING=NONE
TIME_PARTITIONING_FIELD_TYPE=omit
USE_NEW_SNAPSHOT_QUERY_SYNTAX=yes
WILDCARD_IDS=true今回は groups コレクションの中にある member_users というサブコレクションのデータを BigQuery に連携してみようと思う。
ローカルのエミュレーターの Firestore で groups コレクションとそのサブコレクション member_users を登録すると、以下のように BigQuery にデータが連携されている事が確認できる。

※設定で、WILDCARD_IDS=true をする事で、テーブル・ビューそれぞれに path_params というフィールドが追加され、ワイルドカードになっている部分の ID も BigQuery 側に連携される。


カスタムのビューを fs-bq-schema-views スクリプトで生成する
上記で Firestore→BigQuery のデータ連携をいくつか見てきたが、data というフィールドが JSON になっていた事に気づくだろう。
JSON 型ではクエリが容易ではなくなるというデメリットもある。
そこで、JSON をばらして各 JSON のキーをフィールドにしたビューを作ると便利。
Stream Firestore to BigQuery には、公式の schema-views スクリプトがあり、これは JSON のスキーマ設定ファイルに基づいて、BigQuery の組み込み関数である JSON 関数を使用して JSON 型で格納されているデータをJSONのキーごとにフィールドを作成し、クエリしやすいビューを作成できるツール。
以下では、fs-bq-schema-views を利用して、実際にカスタムのクエリしやすいビューを作成してみたいと思う。
fs-bq-schema-views スクリプトでビューを作成するためには、以下の手順が必要になるので、順にやっていく。
gcloud CLI のインストール
スキーマファイルの作成
credentials のセットアップ
スクリプトの実行
BigQuery でクエリ結果を確認
gcloud CLI をインストールする
gcloud CLI の最新バージョン(422.0.0)のインストールに書かれている手順で行っていく。
$ sudo tee -a /etc/yum.repos.d/google-cloud-sdk.repo << EOM
> [google-cloud-cli]
> name=Google Cloud CLI
> baseurl=https://packages.cloud.google.com/yum/repos/cloud-sdk-el7-x86_64
> enabled=1
> gpgcheck=1
> repo_gpgcheck=0
> gpgkey=https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
> EOM
[google-cloud-cli]
name=Google Cloud CLI
baseurl=https://packages.cloud.google.com/yum/repos/cloud-sdk-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
$ sudo yum install google-cloud-cli
...
$ gcloud --version
Google Cloud SDK 425.0.0
alpha 2023.03.31
beta 2023.03.31
bq 2.0.89
bundled-python3-unix 3.9.16
core 2023.03.31
gcloud-crc32c 1.0.0
gsutil 5.21上記で完了。
※私の環境は CentOS7 なので、el7 でインストールした。
$ cat /proc/version
Linux version 3.10.0-1160.76.1.el7.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) ) #1 SMP Wed Aug 10 16:21:17 UTC 2022スキーマファイルを作成する
今回は、以下のような users コレクションのデータが JSON で格納されている場合に、それをクエリしやすいビューになるようにスキーマを定義していく。

今回は検証なので、スキーマは以下のような簡易的なものにした(本来的には必要になるコレクションのドキュメントのフィールドは全て列挙すべき)。
test_schema.json{
"fields": [
{
"name": "email",
"type": "string"
},
{
"name": "last_name",
"type": "string"
},
{
"name": "first_name",
"type": "string"
}
]
}credentials をセットアップする
続いて GPC にアクセスするためのクレデンシャルを設定する。
fs-bq-schema-views スクリプトは ADC(Application Default Credentials)を利用して BigQuery とやり取りする、と書かれているので、以下のコマンドで ADC を設定する。
$ gcloud auth application-default login
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth?response_type=code&client_id=*****.apps.googleusercontent.com&redirect_uri=https%3A%2F%2Fsdk.cloud.google.com%2Fapplicationdefaultauthcode.html&scope=openid+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fuserinfo.email+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fcloud-platform+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fsqlservice.login+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Faccounts.reauth&state=qLucW7HKj1Y2TstebUXjBiTTw0ZFXz&prompt=consent&access_type=offline&code_challenge=*****&code_challenge_method=S256
Enter authorization code: *****
Credentials saved to file: [/home/study/.config/gcloud/application_default_credentials.json]
These credentials will be used by any library that requests Application Default Credentials (ADC).
WARNING:
Cannot find a quota project to add to ADC. You might receive a "quota exceeded" or "API not enabled" error. Run $ gcloud auth application-default set-quota-project to add a quota project.※上記の link をブラウザに張り付け、認証認可を行うと以下の画面にリダイレクトするので、黒く塗りつぶしている場所に書かれている authorization code を CLI に入力する。

※WARNING で quota project の設定がないのでエラーになる場合があると出ているが、今回のアプリケーション(fs-bq-schema-views スクリプト)では"--project"オプションで設定できるので問題ない。
※fs-bq-schema-views スクリプトのセットアップ手順には、サービスアカウントを利用した認証も紹介されているが、公式にも、「開発中にサービス アカウントを使用しない」事がベストプラクティスと書かれているので、開発中の認証は ADC(Application Default Credentials)を利用するべきだろう。
※fs-bq-schema-views スクリプトが ADC を利用している事はコードからも確認できる。
スクリプトを実行する
コマンドオプションで実行する事もできるし、CLI と対話して実行もできので好きな方でいいが、今回は CLI と対話してスクリプトを実行してみたいと思う。
study@localhost:~/workspace/firebase-cloud-functions-trial (main *)
$ npx @firebaseextensions/fs-bq-schema-views
{"severity":"WARNING","message":"Warning, FIREBASE_CONFIG and GCLOUD_PROJECT environment variables are missing. Initializing firebase-admin will fail"}
? What is your Firebase project ID? {projectId}
? What is the ID of the BigQuery dataset the raw changelog lives in? (The dataset and the raw changelog must already exist!) firestore_export
? What is the name of the Cloud Firestore collection for which you want to generate a schema view? users
? Where should this script look for schema definitions? (Enter a comma-separated list of, optionally globbed, paths to files or directories). ./test_schema.json
BigQuery creating schema view users_schema_test_schema_changelog:
Schema:
{"fields":[{"name":"email","type":"string","extractor":"email"},{"name":"last_name","type":"string","extractor":"last_name"},{"name":"first_name","type":"string","extractor":"first_name"}]}
Query:
SELECT
document_name,
document_id,
timestamp,
operation,
JSON_EXTRACT_SCALAR(data, '$.email') AS email,
JSON_EXTRACT_SCALAR(data, '$.last_name') AS last_name,
JSON_EXTRACT_SCALAR(data, '$.first_name') AS first_name
FROM
`{projectId}.firestore_export.users_raw_changelog`
BigQuery created schema view users_schema_test_schema_changelog
BigQuery creating schema view users_schema_test_schema_latest:
Schema:
{"fields":[{"name":"email","type":"string","extractor":"email"},{"name":"last_name","type":"string","extractor":"last_name"},{"name":"first_name","type":"string","extractor":"first_name"}]}
Query:
-- Given a user-defined schema over a raw JSON changelog, returns the
-- schema elements of the latest set of live documents in the collection.
-- timestamp: The Firestore timestamp at which the event took place.
-- operation: One of INSERT, UPDATE, DELETE, IMPORT.
-- event_id: The event that wrote this row.
-- <schema-fields>: This can be one, many, or no typed-columns
-- corresponding to fields defined in the schema.
SELECT
document_name,
document_id,
timestamp,
operation,
email,
last_name,
first_name
FROM
(
SELECT
document_name,
document_id,
FIRST_VALUE(timestamp) OVER(
PARTITION BY document_name
ORDER BY
timestamp DESC
) AS timestamp,
FIRST_VALUE(operation) OVER(
PARTITION BY document_name
ORDER BY
timestamp DESC
) AS operation,
FIRST_VALUE(operation) OVER(
PARTITION BY document_name
ORDER BY
timestamp DESC
) = "DELETE" AS is_deleted,
FIRST_VALUE(JSON_EXTRACT_SCALAR(data, '$.email')) OVER(
PARTITION BY document_name
ORDER BY
timestamp DESC
) AS email,
FIRST_VALUE(JSON_EXTRACT_SCALAR(data, '$.last_name')) OVER(
PARTITION BY document_name
ORDER BY
timestamp DESC
) AS last_name,
FIRST_VALUE(JSON_EXTRACT_SCALAR(data, '$.first_name')) OVER(
PARTITION BY document_name
ORDER BY
timestamp DESC
) AS first_name
FROM
`{projectId}.firestore_export.users_raw_latest`
)
WHERE
NOT is_deleted
GROUP BY
document_name,
document_id,
timestamp,
operation,
email,
last_name,
first_name
BigQuery created view users_schema_test_schema_latest
done.CLI から fs-bq-schema-views スクリプトに設定値を渡すと、BigQuery のスキーマを自動で作成してくれる。スキーマの定義はログに出ている SQL から確認できる。
GCP の BigQuery のダッシュボードからも以下のようにスキーマが作成されている事が確認できる。


クエリ結果を確認してみる
上記で作成されたビューに対してクエリを実行してみると、以下のように JSON ではなく、各フィールドに JSON のキーがマッピングされてクエリできている事が確認できる。
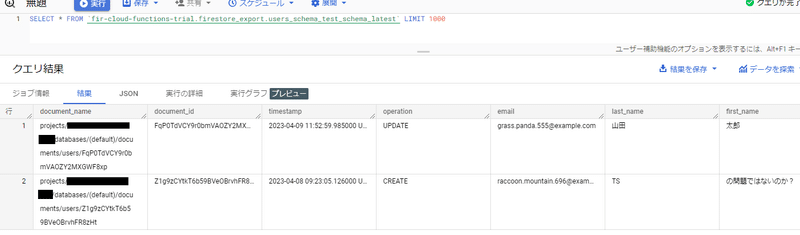
以下は、where 句を追加してクエリした結果。

※ちなみに、CLI からもクエリを実行してみたが、以下のようにデータが取得できる事が確認できた。

※gcloud の CLI の認証と、アプリケーションの認証は別物なので ADC でデフォルトのクレデンシャルを設定しても、gcloud のコマンド(BigQuery なので bq コマンド)は以下のようにエラーになる(以下、公式からの引用)。

この認証情報は gcloud CLI では使用されません。
そのため、公式に書かれている方法で、認証を行う必要がある。
"gcloud auth login"コマンドで認証を行うと、以下のように CLI で BigQuery にアクセスできるようになるコマンド実行時に project_id を指定するのではなく、"gcloud config set project PROJECT_ID"で設定する事もできる)。


《この公式ブロガーの記事一覧》
執筆者プロフィール:Katayama Yuta
認証認可(SHIFTアカウント)や課金決済のプラットフォーム開発に従事。リードエンジニア。
経歴としては、SaaS ERPパッケージベンダーにて開発を2年経験。
SHIFTでは、GUIテストの自動化やUnitテストの実装などテスト関係の案件に従事したり、DevOpsの一環でCICD導入支援をする案件にも従事。その後現在のプラットフォーム開発に参画。
お問合せはお気軽に
https://service.shiftinc.jp/contact/
SHIFTについて(コーポレートサイト)
https://www.shiftinc.jp/
SHIFTのサービスについて(サービスサイト)
https://service.shiftinc.jp/
SHIFTの導入事例
https://service.shiftinc.jp/case/
お役立ち資料はこちら
https://service.shiftinc.jp/resources/
SHIFTの採用情報はこちら
https://recruit.shiftinc.jp/career/