
DifyでHyDEの実装をしてみる

HyDE(Hypothetical Document Embeddings)は、大規模言語モデル(LLM)を活用して検索性能を向上させる手法です。この手法の特徴は以下の通りです:
クエリ拡張:ユーザーの検索クエリを基に、LLMを使って仮回答を生成します。
エンベディング生成:生成された仮想文書からエンベディング(ベクトル表現)を作成します。
類似度検索:このエンベディングを用いて、実際の文書コレクションから類似度の高い文書を検索します。
例えばユーザーから「太陽光発電の効率を上げるには?」という質問がされた場合。まずLLMをつかって以下のような仮回答文章を生成します。
太陽光発電の効率を向上させるには、高効率パネルの使用、最適な設置角度の調整、追尾システムの導入、定期的な清掃、温度管理、エネルギー貯蔵システムの併用、高性能インバーターの採用など、複数の方法を組み合わせることが効果的です。
この仮回答文章をクエリとしてベクトル検索をすることで、知識モデルとの一致率が高まり回答精度が高まるというわけです。
DifyでHyDEを実装してみる
ワークフローは以下の通りです。
①ユーザーの質問をもとに仮回答を生成し、②仮回答文をクエリにセマンティック検索を行い、③取得した知識をもとに本回答を生成します。

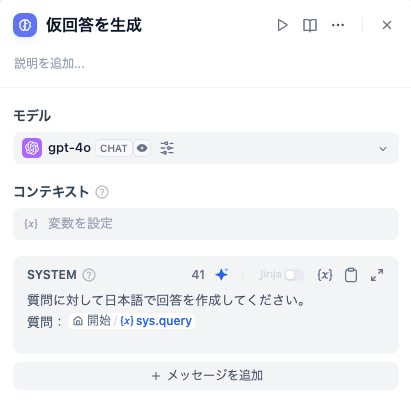
仮回答を生成するプロンプトは以下の通りです。
質問に対して日本語で回答を作成してください。
質問:{{#sys.query#}}
仮回答を知識取得のクエリ変数にわたします。

得られた知識をもとに本回答を生成します。
質問に対して、与えられた知識に基づいて回答を作成してください。
質問:{{#sys.query#}}
知識:{{#context#}}

以上です。
仮回答生成のモデルのファインチューニングをすると精度が上がりそう
社内の知識や法律などの専門分野の知識など、素のLLMでは回答できなためにRAGを活用するので、仮回答についても知識のない状態で生成することになります。
すると、RAGに含まれた知識とかなり乖離のある仮回答文章が生成される可能性が高く、一致率があまり高まらないことが予想できます。
そこで、仮回答を生成するLLMをRAGと同じ知識をつかってファインチューニングをしておくと、仮回答の精度がかなり高まるのではないかと思います。
Difyではファインチューニングをすることができませんので、以前こちらの記事で書いた手法の方が有効かもしれません。
知識は質問文と回答文をセットの形式で用意しておき、質問文をLLMで精緻化した上でクエリとして利用する方法です。
引き続き生成AI関連、いろいろと試していきます。
この記事が気に入ったらサポートをしてみませんか?